机器学习-概率图模型系列-最大熵模型-37
参考:https://www.cnblogs.com/pinard/p/6972299.html
最大熵模型(maximum entropy model, MaxEnt)也是很典型的分类算法了,它和逻辑回归类似,都是属于对数线性分类模型。在损失函数优化的过程中,使用了和支持向量机类似的凸优化技术。
1. 熵的定义
生命以负熵为生----薛定谔《生命是什么》
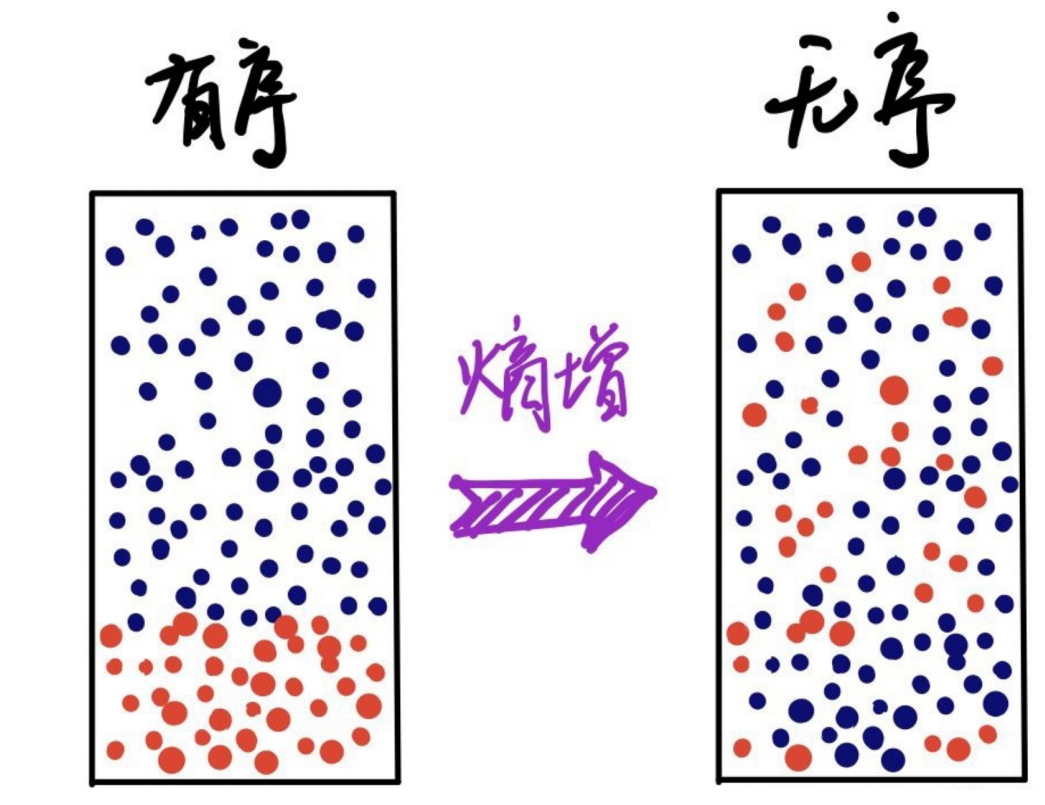
什么是信息熵?
信息是指人们对事物理解的不确定性的降低或消除,而熵就是不确定性的度量,熵越大,不确定性也就越大。
假设离散随机变量x的分布是p(x),则关于分布P的熵定义为:
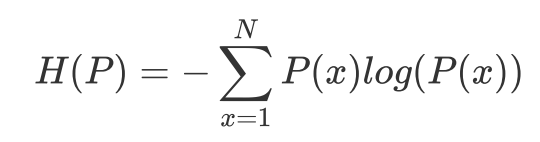
N代表x的N种不同离散取值,
当x服从均匀分布时对应的熵最大,也就是不确定性最高。
交叉熵:
y y_hat 真实值与预测值交叉求熵

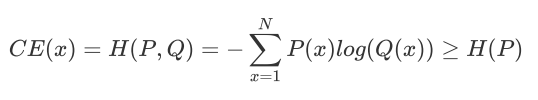
多分类的场景,使得Q(x)尽量逼近真实数据分布P(x)。通过最小化交叉熵可以使得模型朝着我们想要的方向进行优化。
出两个变量X和Y的联合熵表达式:
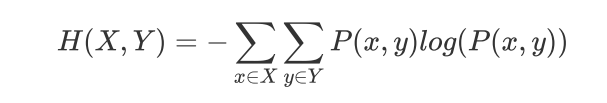
有了联合熵,又可以得到条件熵的定义:
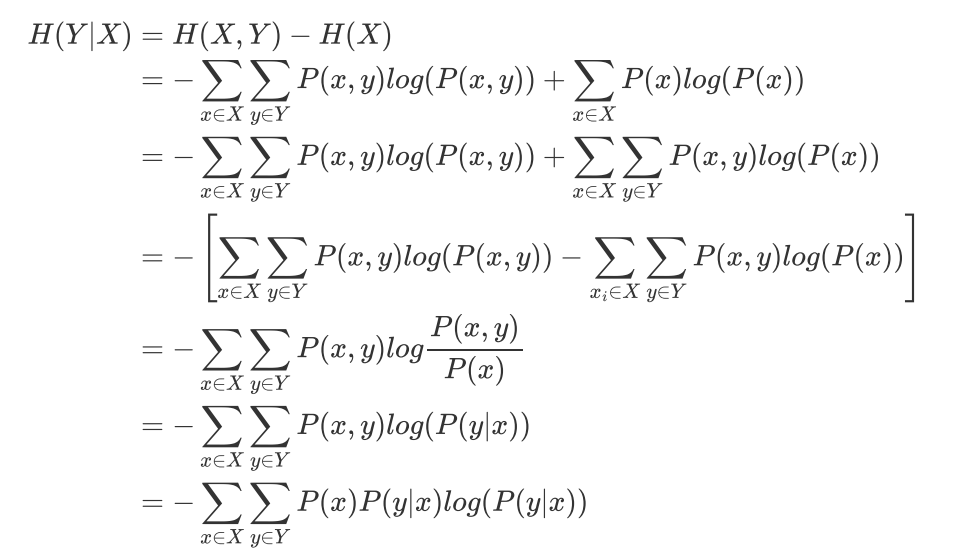
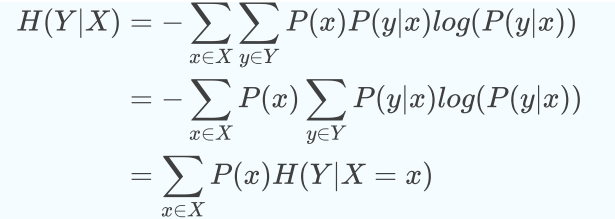
实条件熵就是“被特征分割以后的信息熵的加权平均”
Max Entropy 最大熵原则
"鸡蛋不要放在一个篮子里",最大熵原理是概率模型学习的一个准则,指导思想是在满足约束条件的模型集合中选取熵最大的模型,即不确定性最大的模型。
最大熵模型就是要学习到合适的分布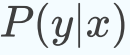 ,使得条件熵的取值最大。
,使得条件熵的取值最大。
在给定的训练集X条件下,对y作出预测,预测的结果是熵是最大的,损失是最小的。
条件熵计算举例:
样本人群中 有男性 也有女性 有结婚的有未婚的
这样可以计算出男性 女性的 分布的概率
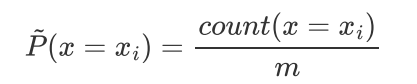
男性且结婚 女性且结婚 男性未婚 女性未婚的概率
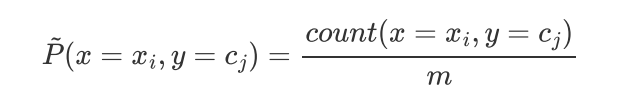
条件概率分布上的条件熵为:

2. 最大熵模型算法
训练集: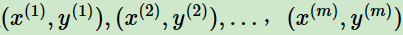
x为n维特征向量,y为类别输出,
统计得出:
总体联合分布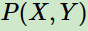 的经验分布
的经验分布 即为训练集中X,Y同时出现的次数除以样本总数m
即为训练集中X,Y同时出现的次数除以样本总数m
边缘分布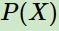 的经验分布
的经验分布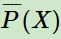 即为训练集中X出现的次数除以样本总数m
即为训练集中X出现的次数除以样本总数m
特征函数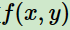 描述输入x和输出y之间的关系
描述输入x和输出y之间的关系
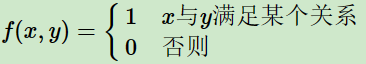
同一个训练样本可以有多个约束特征函数。
特征函数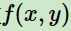 关于经验分布
关于经验分布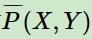 的期望值:
的期望值:
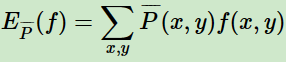
特征函数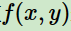 关于条件分布
关于条件分布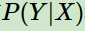 和经验分布
和经验分布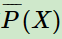 的期望值
的期望值
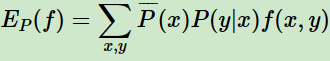
假设这两个期望相等:
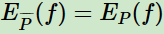
假设M个特征函数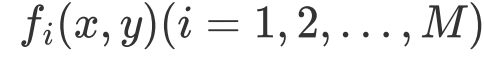
就有M个约束条件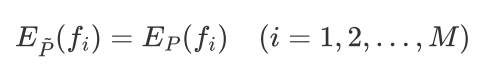
总结一下:
训练数据集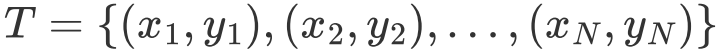
以及M个特征函数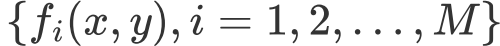
最大熵模型的学习等价于约束最优化问题
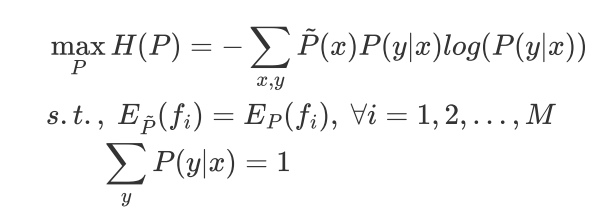
求解
带约束优化问题可以用拉格朗日函数将其转化为无约束优化函数:
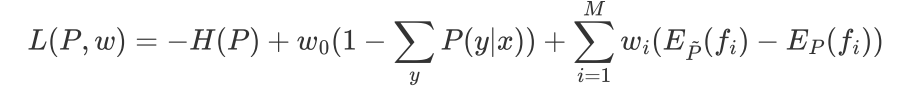
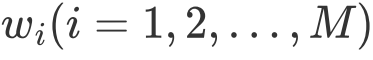 为拉格朗日乘子
为拉格朗日乘子
求解的过程与SVM类似
结果:
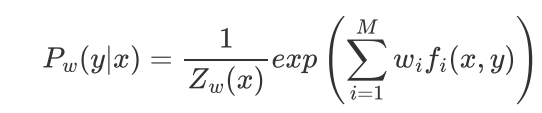
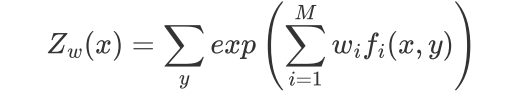
3. 逻辑回归 与 最大熵 之间的关系
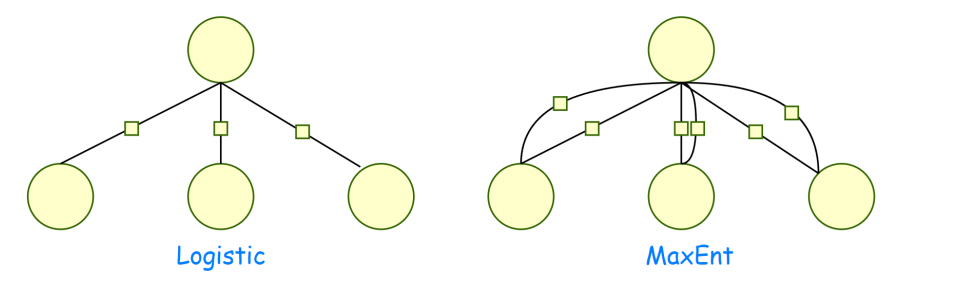
逻辑回归的本质是解决二分类问题,每个特征会对应一个权重再通过 sigmoid隐射到 0-1之间
n条样本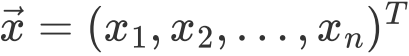 为n维变量
为n维变量
定义如下特征函数
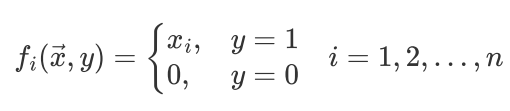
每条样本一个 特征函数
最大熵表达式:
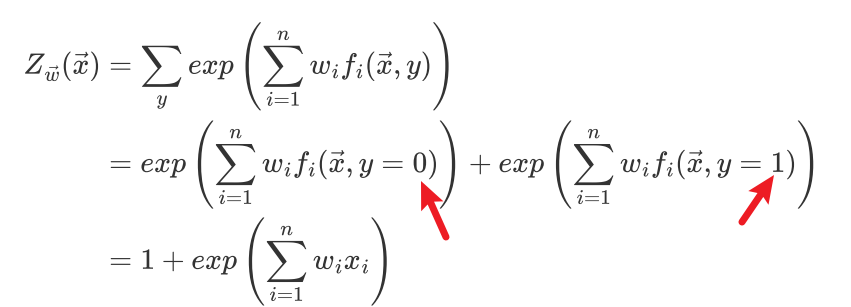
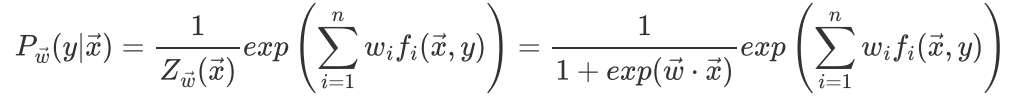
y=1
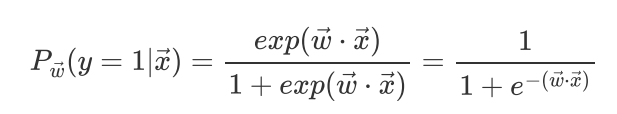
y=0
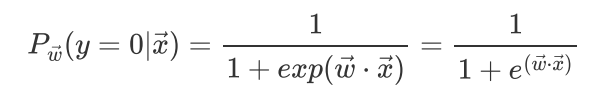
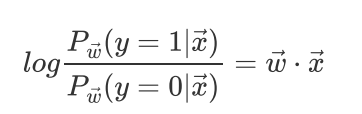
几率取对数成线性,逻辑回归是误译,叫对数几率回归更合适。
重新审视特征函数
逻辑回归是最大熵的特例,
逻辑回归算法面对某个数据集时,我们习惯了认为数据集有d个维度,逻辑回归就对应去学习d个权重参数。
feature engineering挖掘出来的特征,其实和最大熵里面设置更多的特征函数没区别,最大熵里面算出来的 和逻辑回归对应特征算出来的权重参数没区别。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通