机器学习-无监督机器学习-主成分分析PCA-23
1. 降维的方式
对于维度灾难、数据冗余,这些在数据处理中常见的场景,我们不得不进一步处理,得到更精简更有价值的特征信息,所用的的各种方法的统称就是降维
特征抽取:叫做特征映射更合适。因为它的思想即把高维空间的数据映射到低维空间。各种方法包括:
Principal Component Analysis (PCA)
Linear Discriminant Analysis (LDA)
特征选择:试图找到原始特征集合的子集,也就是只选取部分特征
什么是卡方检验Chi-Square test [kai]
用于检测数据集里面的最佳特征,测定哪些特征是输出类别最依赖的, 
值越高,输出标签越依赖这个特征,并且这个特征有更高的重要性来决定输出值。
假设:有m个特征值并且有k个输出标签
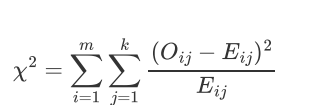
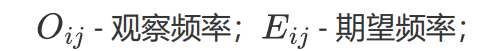
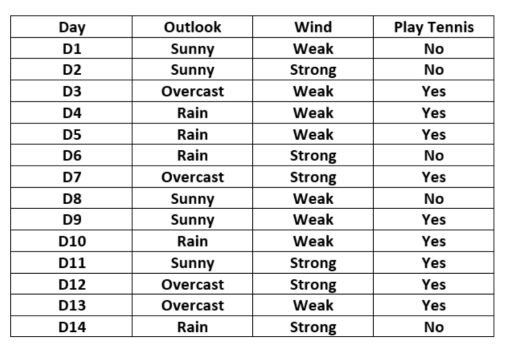
outlook wind两个维度 决定是否play tennis
对于"Outlook"特征可以构建下表:
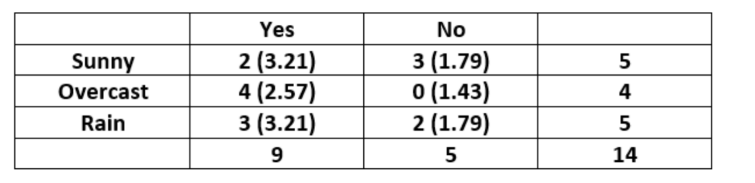
单元格(Sunny,Yes)的期望值计算: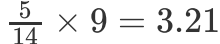
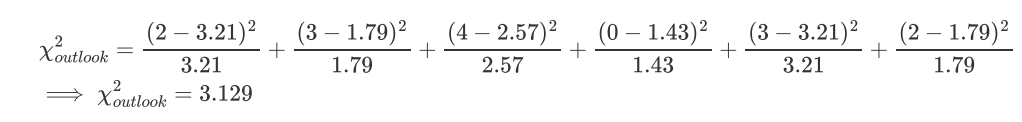
对于"Wind"特征可以构建下表:
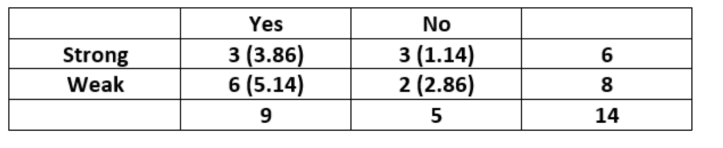

"Wind"是更重要的特征去决定输出值
2. PCA的一般步骤
常用的线性方法是主成分分析PCA。它的思想就是将数据从高维空间映射到低维空间,同时在低维空间里数据的方差被最大化。维度下降 但是最大的保持信息量

留下来少量的特征向量,所以或许这个过程有一些数据丢失。但是最重要的方差应该被保留在了这些特征向量中。
用2维降到1维来举例,
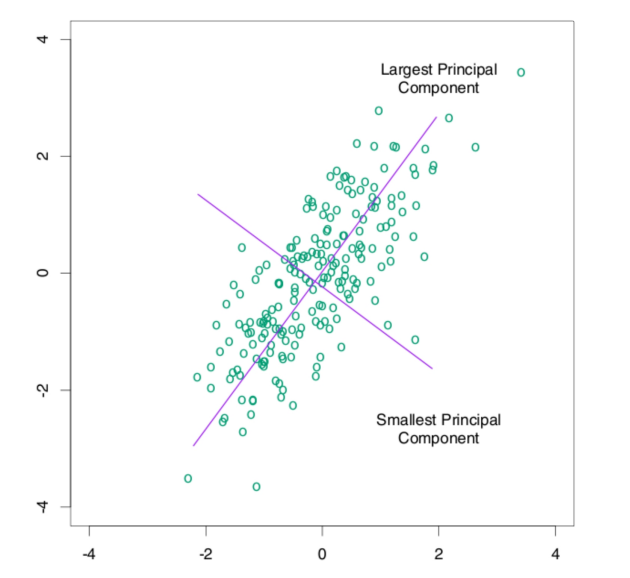
将到1维后 肯定选择方差更大的维度去记录特征 对于变化不大的特征 信息量就少
数据进行降维 本质上观测的对象是不会变化的 只是换一个不同的角度 用新的维度去描述被观察的对象
样本点投影到新的坐标轴

W是变换矩阵
x是所有的样本集
把所有的样本点投影到w1方向 使得投影后的点方差最大,
新坐标系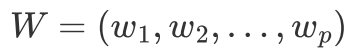
p个维度,设置成标准正交基:
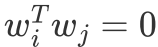
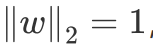
方差的计算:
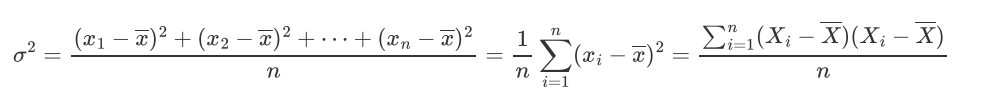
投影之后:
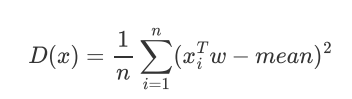
注意点:
PCA会对未投影前的原始数据进行标准归一化,均值归一化也叫中心化:好处是上式中的mean也会为0,推导如下;
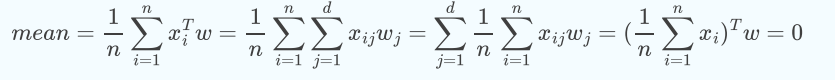
也就是PCA之前 样本数据已经全部移到了(0,0)原点
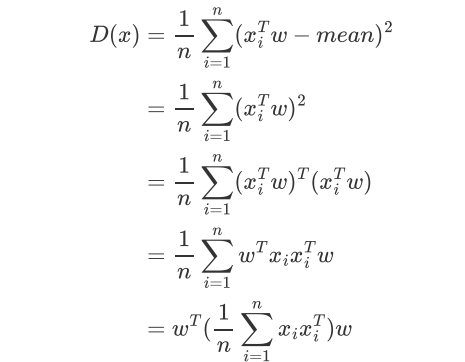
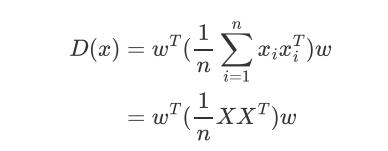
协方差公式:
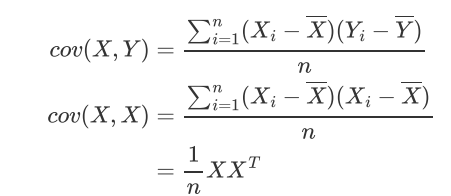
协方差矩阵用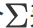 表示
表示
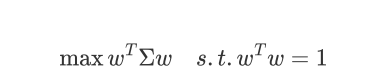
拉格朗日函数:

对w求导
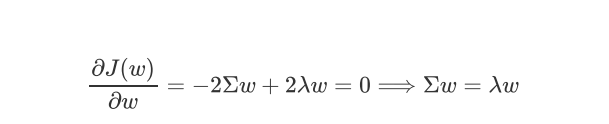
w是sigma的特征向量,lamda是对应的特征值

我们要去寻找的第一主成分,就是使得投影方差最大的坐标轴就是最大特征值对应的特征向量
最终想要保留下来几个维度,我们就选取前几个最大的特征值对应的特征向量,然后把原始的数据在这些轴上面进行投影即可
比如取前 个大的特征值对应的特征向量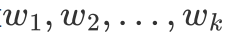
通过以下映射将d维样本映射到k维
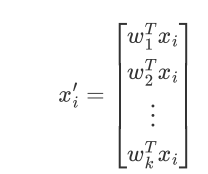
降维后的信息占比:
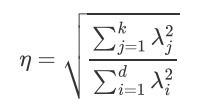
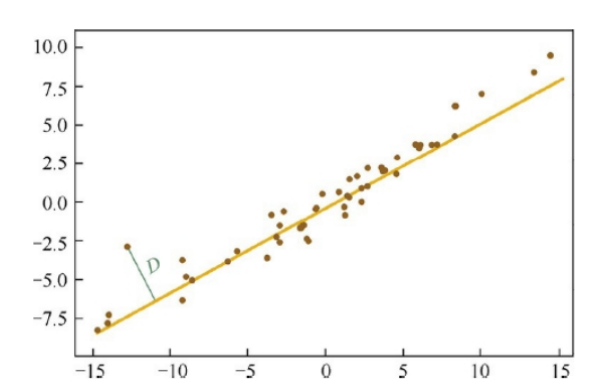
3. 思想2 最小化投影距离
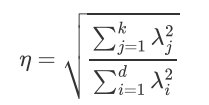
但是这个和线性回归还是有区别 线性回归 y-y_hat 最小,这里是求距离
wi 与xk 都是d维的向量
xk在各个维度投影后加和得到 投影后的点位置:
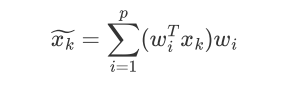
目标转换成:
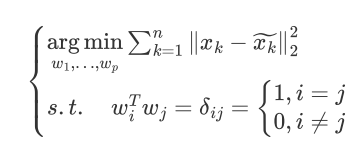
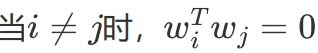
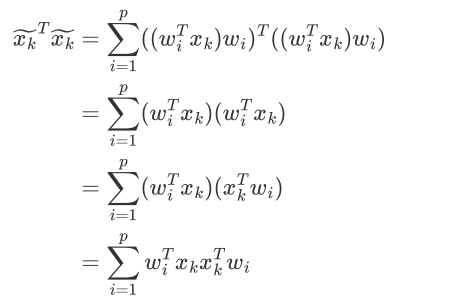

再使用同样的步骤就可以求得最终的投影空间,最佳投影方向就是最大特征值所对应的特征向量。
4. Kernelized PCA
有时我们的数据并不是可以投影到线性超平面的,这时候就不能直接进行PCA降维
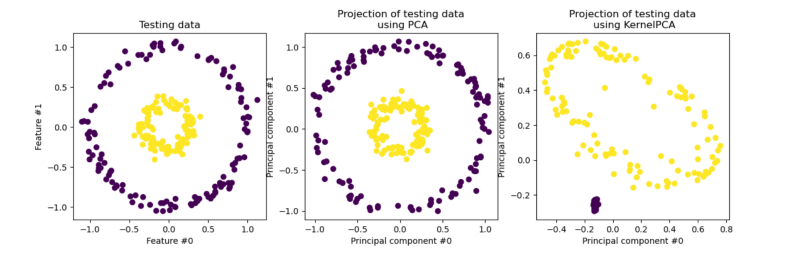
先把数据从n维映射到线性可分的高维N>n,然后再从N维降维到一个低维度n',这里的维度之间满足n' < n < N
映射函数φ将n维映射到N维:
N维:
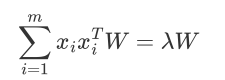
映射为:
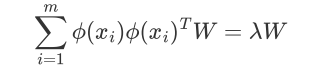
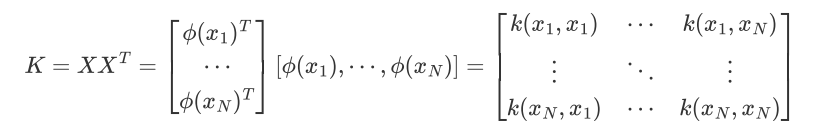

 浙公网安备 33010602011771号
浙公网安备 33010602011771号