
G2、人脸图像生成(DCGAN)
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
- 🚀 文章来源:K同学的学习圈子
本周任务: 📌 基础任务:
- 深度卷积对抗网络(DCGAN)的基本原理
- 学习本文DCGAN代码,并跑通代码
- 了解DCGAN与GAN的区别
🎈进阶任务:
- 调用训练好的模型生成新图像
一、理论基础¶
1、DCGAN原理¶
深度卷积对抗网络(Deep Convolutional Generative Adversarial Networks,简称DCGAN)是一种深度学习模型,由生成器(Generator)和判别器(Discriminator)两个神经网络组成。DCGAN结合了卷积神经网络(Convolutional Neural Networks,简称CNN)和生成对抗网络(Generative Adversarial Networks,简称GAN)的思想,用于生成逼真的图像。 它是GAN的一种模型改进,其将卷积运算的思想引入到生成式模型当中来做无监督的训练,利用卷积网络强大的特征提取能力来提高生成网络的学习效果。DCGAN模型有以下特点:
- 判别器模型使用卷积步长取代了空间池化,生成器模型中使用反卷积操作扩大数据维度。
- 除了生成器模型的输出层和判别器模型的输入层,在整个对抗网络的其它层上都使用了Batch Normalization,原因是Batch Normalization可以稳定学习,有助于优化初始化参数值不良而导致的训练问题。
- 整个网络去除了全连接层,直接使用卷积层连接生成器和判别器的输入层以及输出层。
- 在生成器的输出层使用Tanh激活函数以控制输出范围,而在其它层中均使用了ReLU激活函数;在判别器上使用Leaky ReLU激活函数。
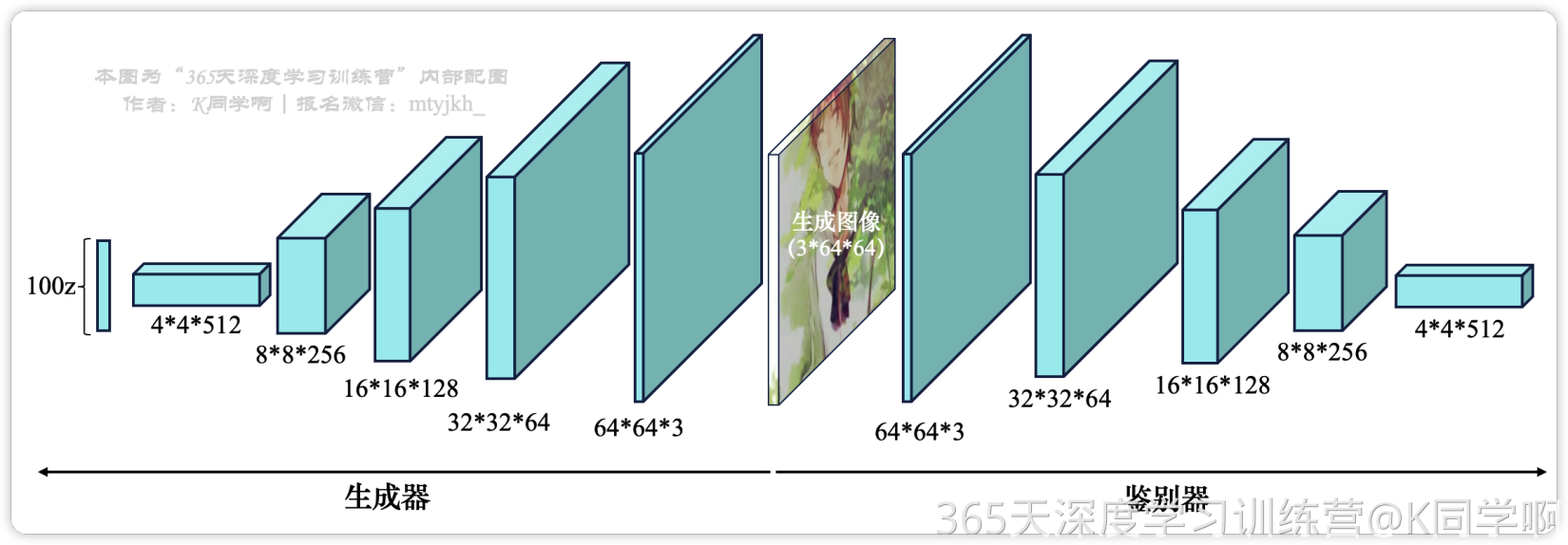
上图是一种常见的 DCGAN 结构
- 左边生成网络(Generator):四个转置卷积层(DeConv)和四个卷积层(Conv)
- 右边判别网络(Discriminator):四个转置卷积层(DeConv)和四个卷积层(Conv)
44512代表这一层共有512个大小为4*4的特征图 在卷积层之前和之后分别使用了批归一化和修正线性单元激活两种处理方法。Tanh 和 LeakyReLU 分别表示双切正切激活和弱修正线性激活。
2、训练原理¶
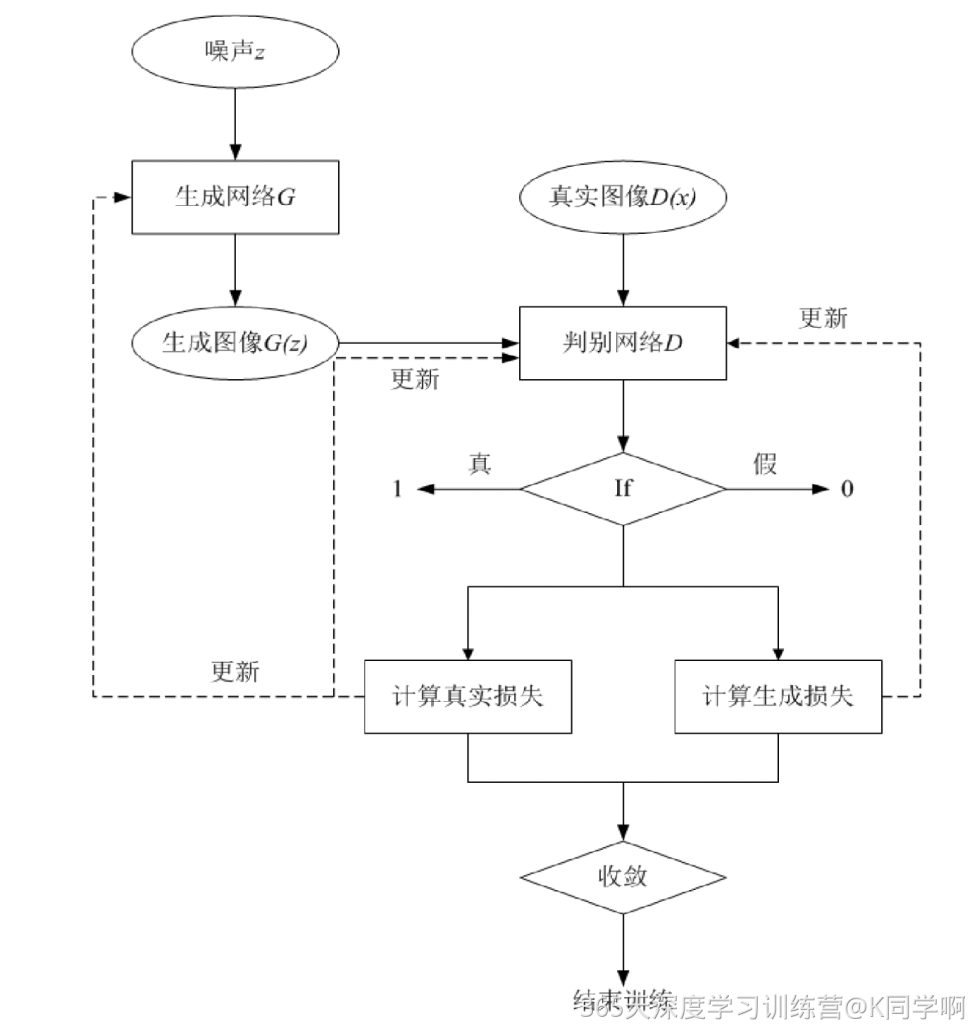 DCGAN 模型主要包括了一个生成网络 G 和一个判别网络 D,生成网络 G 负责生成图像,它接受一个随机的噪声z,通过该噪声生成图像,将生成的图像记为G(z),判别网络D负责判别一张图像是否为真实的,它的输入是x,代表一张图像,输出D(x)表示x为真实图像的概率。 实际上判别网络D是对数据的来源进行一个判别:究竟这个数据是来自真实的数据分布Pd(x)判别为“1”),还是来自于一个生成网络G所产生的一个数据分布Pg(z)(判别为“0”)。所以在整个训练过程中,生成网络G的目标是生成可以以假乱真的图像G(z),当判别网络D无法区分,即D(G(z))=0.5时,便得到了一个生成网络G用来生成图像扩充数据集。
DCGAN 模型主要包括了一个生成网络 G 和一个判别网络 D,生成网络 G 负责生成图像,它接受一个随机的噪声z,通过该噪声生成图像,将生成的图像记为G(z),判别网络D负责判别一张图像是否为真实的,它的输入是x,代表一张图像,输出D(x)表示x为真实图像的概率。 实际上判别网络D是对数据的来源进行一个判别:究竟这个数据是来自真实的数据分布Pd(x)判别为“1”),还是来自于一个生成网络G所产生的一个数据分布Pg(z)(判别为“0”)。所以在整个训练过程中,生成网络G的目标是生成可以以假乱真的图像G(z),当判别网络D无法区分,即D(G(z))=0.5时,便得到了一个生成网络G用来生成图像扩充数据集。
二、前期准备¶
1、导入第三方库¶
import torch, random, random, os
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
manualSeed = 42 # 随机种子
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
torch.use_deterministic_algorithms(True) # Needed for reproducible resultsRandom Seed: 422、设置超参数¶
dataroot = "./data/GAN-Data/" # 数据路径
batch_size = 128 # 训练过程中的批次大小
image_size = 64 # 图像的尺寸(宽度和高度)
nz = 100 # z潜在向量的大小(生成器输入的尺寸)
ngf = 64 # 生成器中的特征图大小
ndf = 64 # 判别器中的特征图大小
num_epochs = 5 # 训练的总轮数
lr = 0.0002 # 学习率
beta1 = 0.5 # Adam优化器的Beta1超参数3、导入数据¶
- 首先使用ImageFolder类创建一个数据集对象,该对象表示从文件夹中加载的图像数据集
- 然后,通过transforms.Compose组合了一系列图像变换操作来对图像进行预处理,包括调整大小、中心裁剪、转换为张量以及标准化
- 接着,使用DataLoader类创建一个数据加载器对象,该对象可以在训练过程中按批次加载数据,并可以选择是否打乱数据集以及使用多线程加载数据。代码还选择设备(GPU或CPU)来运行代码,并显示所选择的设备
- 最后,代码通过数据加载器获取一批训练图像,并使用Matplotlib库绘制这些图像
解决一个小问题,关于路径图像读取的,图像实际的目录为./data/GAN-Data/FaceSample,而将数据集路径定为上一级目录 "./data/GAN-Data",是因为PyTorch支持自动扫描指定目录下的所有子目录,以发现数据集文件。使用 torchvision.datasets.ImageFolder 类来读取数据集。此时,你只需要将数据集路径定为 "./data/GAN-Data" 即可,因为 ImageFolder 类会自动扫描该目录下的所有子目录,以发现数据集文件。如果目录下有多个不同的文件夹,ImageFolder 类会将每个文件夹名作为一个标签类别,并将文件夹中的所有图像文件都视为该类别下的样本。如果数据集目录 "./data/GAN-Data",其中包含三个子目录 "cats"、"dogs" 和 "pandas",每个子目录下都包含对应的图像文件。ImageFolder 类将读取 "./data/GAN-Data" 目录下的所有子目录,并将每个子目录名作为一个标签类别。
# 创建数据集
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size), # 调整图像大小
transforms.CenterCrop(image_size), # 中心裁剪图像
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.5, 0.5, 0.5), # 标准化图像张量
(0.5, 0.5, 0.5)),
]))
# 创建数据加载器
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=batch_size, # 批量大小
shuffle=True, # 是否打乱数据集
num_workers=5 # 使用多个线程加载数据的工作进程数
)
# 选择要在哪个设备上运行代码
device = torch.device("cuda:0" if (torch.cuda.is_available()) else "cpu")
print("使用的设备是:",device)
# 绘制一些训练图像
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:24],
padding=2,
normalize=True).cpu(),(1,2,0)))使用的设备是: cuda:0<matplotlib.image.AxesImage at 0x22a8b01e560>
# 自定义权重初始化函数,作用于netG和netD
def weights_init(m):
# 获取当前层的类名
classname = m.__class__.__name__
# 如果类名中包含'Conv',即当前层是卷积层
if classname.find('Conv') != -1:
# 使用正态分布初始化权重数据,均值为0,标准差为0.02
nn.init.normal_(m.weight.data, 0.0, 0.02)
# 如果类名中包含'BatchNorm',即当前层是批归一化层
elif classname.find('BatchNorm') != -1:
# 使用正态分布初始化权重数据,均值为1,标准差为0.02
nn.init.normal_(m.weight.data, 1.0, 0.02)
# 使用常数初始化偏置项数据,值为0
nn.init.constant_(m.bias.data, 0)2、定义生成器¶
main:序列模型,用于存储各个层的顺序,依次为
- 转置卷积层
- 批归一化层
- ReLU激活函数
重复4次,每次调整参数,将特征图的尺寸从4x4逐步放大到64x64,通道数从(ngf*8)逐步减少到ngf,最后经过转置卷积层,输出一个3通道的64x64的假图片。最后一层的输出经过Tanh激活函数的处理,将输出像素值缩放到[-1, 1]之间,使其符合真实图片的像素值分布。
前向传播函数forward():输入为噪声向量Z,输出为生成器生成的假图片。这里直接将输入传入main模型中进行前向传播
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
# 输入为Z,经过一个转置卷积层
nn.ConvTranspose2d(nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8), # 批归一化层,用于加速收敛和稳定训练过程
nn.ReLU(True), # ReLU激活函数
# 输出尺寸:(ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 输出尺寸:(ngf*4) x 8 x 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 输出尺寸:(ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 输出尺寸:(ngf) x 32 x 32
nn.ConvTranspose2d(ngf, 3, 4, 2, 1, bias=False),
nn.Tanh() # Tanh激活函数
# 输出尺寸:3 x 64 x 64
)
def forward(self, input):
return self.main(input)
# 创建生成器
netG = Generator().to(device)
# 使用 "weights_init" 函数对所有权重进行随机初始化,
# 平均值(mean)设置为0,标准差(stdev)设置为0.02。
netG.apply(weights_init)
# 打印生成器模型
print(netG)Generator(
(main): Sequential(
(0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(13): Tanh()
)
)3、定义鉴别器¶
main:序列模型,用于存储各个层的顺序,输入大小为3 x 64 x 64,经过一个卷积层,将输入的图片映射到(ndf) x 32 x 32的特征图。
- 卷积层对输入的图片进行特征提取,提取出一些低阶的特征,例如边缘、纹理等。
- LeakyReLU激活函数,将输出的特征图进行非线性处理,在特征图中加入非线性因素,增加网络的表达能力。
- 随后依次经过三个卷积层、三个批归一化层、三个LeakyReLU激活函数,将特征图的尺寸从32x32逐步减小到4x4,通道数从ndf逐步增加到ndf*8。
- 最后一个卷积层,将(ndf*8) x 4 x 4的特征图映射到一个标量输出,表示输入的图片是真实图片的概率。最后一层的输出通道数为1,卷积核大小为4,步长为1,填充为0。Sigmoid激活函数,将输出的概率值缩放到[0, 1]之间,表示输入的图片是真实图片的概率。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# 定义判别器的主要结构,使用Sequential容器将多个层按顺序组合在一起
self.main = nn.Sequential(
# 输入大小为3 x 64 x 64
nn.Conv2d(3, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 输出大小为(ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 输出大小为(ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 输出大小为(ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# 输出大小为(ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
# 将输入通过判别器的主要结构进行前向传播
return self.main(input)
# 创建判别器模型
netD = Discriminator().to(device)
# 应用 "weights_init" 函数来随机初始化所有权重
# 使用 mean=0, stdev=0.2 的方式进行初始化
netD.apply(weights_init)
# 打印模型
print(netD)Discriminator(
(main): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(12): Sigmoid()
)
)# 初始化“BCELoss”损失函数
criterion = nn.BCELoss()
# 创建用于可视化生成器进程的潜在向量批次
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
real_label = 1.
fake_label = 0.
# 为生成器(G)和判别器(D)设置Adam优化器
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))2、训练模型¶
下面的训练代码是一个典型的GAN训练循环。在训练过程中,首先更新判别器网络,然后更新生成器网络。在每个epoch的每个batch中,会进行以下操作:
-
更新判别器网络:通过训练真实图像样本和生成图像样本,最大化判别器的损失。具体步骤如下:
- 对于真实图像样本,计算判别器对真实图像样本的输出和真实标签之间的损失,然后进行反向传播计算梯度。
- 对于生成的图像样本,计算判别器对生成图像样本的输出和假标签之间的损失,然后进行反向传播计算梯度。
- 将真实图像样本的损失和生成图像样本的损失相加得到判别器的总损失,并更新判别器的参数。
-
更新生成器网络:通过最大化生成器的损失,迫使生成器产生更逼真的图像样本。具体步骤如下:
- 使用生成器生成一批假图像样本。
- 将生成图像样本输入判别器,计算判别器对生成图像样本的输出和真实标签之间的损失,并进行反向传播计算生成器的梯度。
- 更新生成器的参数。
-
输出训练统计信息:每隔一定的步数,输出当前训练的epoch、batch以及判别器和生成器的损失值等信息。
-
保存损失值:将生成器和判别器的损失值存储到相应的列表中,以便后续绘图和分析。
-
检查生成器的性能:每隔一定的步数或者在训练结束时,通过将固定的噪声输入生成器,生成一批图像样本,并保存到img_list列表中。这样可以观察生成器在训练过程中生成的图像质量的变化。
-
更新迭代次数:每完成一个batch的训练,将迭代次数iters加1。
总体来说,这段代码实现了GAN的训练过程,通过交替更新判别器和生成器的参数,目标是使生成器生成逼真的图像样本,同时判别器能够准确区分真实图像样本和生成图像样本。
img_list = [] # 用于存储生成的图像列表
G_losses = [] # 用于存储生成器的损失列表
D_losses = [] # 用于存储判别器的损失列表
iters = 0 # 迭代次数
print("Starting Training Loop...") # 输出训练开始的提示信息
# 对于每个epoch(训练周期)
for epoch in range(num_epochs):
# 对于dataloader中的每个batch
for i, data in enumerate(dataloader, 0):
############################
# (1) 更新判别器网络:最大化 log(D(x)) + log(1 - D(G(z)))
###########################
## 使用真实图像样本训练
netD.zero_grad() # 清除判别器网络的梯度
# 准备真实图像的数据
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, dtype=torch.float, device=device) # 创建一个全是真实标签的张量
# 将真实图像样本输入判别器,进行前向传播
output = netD(real_cpu).view(-1)
# 计算真实图像样本的损失
errD_real = criterion(output, label)
# 通过反向传播计算判别器的梯度
errD_real.backward()
D_x = output.mean().item() # 计算判别器对真实图像样本的输出的平均值
## 使用生成图像样本训练
# 生成一批潜在向量
noise = torch.randn(b_size, nz, 1, 1, device=device)
# 使用生成器生成一批假图像样本
fake = netG(noise)
label.fill_(fake_label) # 创建一个全是假标签的张量
# 将所有生成的图像样本输入判别器,进行前向传播
output = netD(fake.detach()).view(-1)
# 计算判别器对生成图像样本的损失
errD_fake = criterion(output, label)
# 通过反向传播计算判别器的梯度
errD_fake.backward()
D_G_z1 = output.mean().item() # 计算判别器对生成图像样本的输出的平均值
# 计算判别器的总损失,包括真实图像样本和生成图像样本的损失之和
errD = errD_real + errD_fake
# 更新判别器的参数
optimizerD.step()
############################
# (2) 更新生成器网络:最大化 log(D(G(z)))
###########################
netG.zero_grad() # 清除生成器网络的梯度
label.fill_(real_label) # 对于生成器成本而言,将假标签视为真实标签
# 由于刚刚更新了判别器,再次将所有生成的图像样本输入判别器,进行前向传播
output = netD(fake).view(-1)
# 根据判别器的输出计算生成器的损失
errG = criterion(output, label)
# 通过反向传播计算生成器的梯度
errG.backward()
D_G_z2 = output.mean().item() # 计算判别器对生成器输出的平均值
# 更新生成器的参数
optimizerG.step()
# 输出训练统计信息
if i % 400 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# 保存损失值以便后续绘图
G_losses.append(errG.item())
D_losses.append(errD.item())
# 通过保存生成器在固定噪声上的输出来检查生成器的性能
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1Starting Training Loop...
[0/5][0/36] Loss_D: 1.3912 Loss_G: 7.0328 D(x): 0.7949 D(G(z)): 0.6158 / 0.0015
[1/5][0/36] Loss_D: 0.0964 Loss_G: 12.4337 D(x): 0.9758 D(G(z)): 0.0000 / 0.0000
[2/5][0/36] Loss_D: 0.1421 Loss_G: 21.1729 D(x): 0.9483 D(G(z)): 0.0000 / 0.0000
[3/5][0/36] Loss_D: 1.4115 Loss_G: 3.4389 D(x): 0.5138 D(G(z)): 0.0038 / 0.0854
[4/5][0/36] Loss_D: 0.5744 Loss_G: 6.4573 D(x): 0.8492 D(G(z)): 0.2680 / 0.00353、可视化¶
- 训练过程loss可视化
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()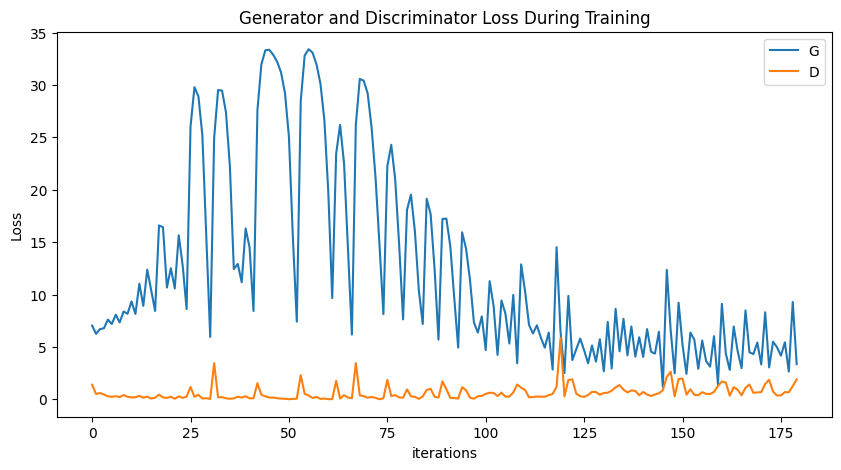
- GAN生成图像可视化
# 创建一个大小为8x8的图形对象
fig = plt.figure(figsize=(8, 8))
# 不显示坐标轴
plt.axis("off")
# 将图像列表img_list中的图像转置并创建一个包含每个图像的单个列表ims
ims = [[plt.imshow(np.transpose(i, (1, 2, 0)), animated=True)] for i in img_list]
# 使用图形对象、图像列表ims以及其他参数创建一个动画对象ani
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
# 将动画以HTML形式呈现
HTML(ani.to_jshtml())
# 从数据加载器中获取一批真实图像
real_batch = next(iter(dataloader))
# 绘制真实图像
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))
# 绘制上一个时期生成的假图像
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()

