N8、图解Transformer
📌 本周任务:
- 了解Transformer
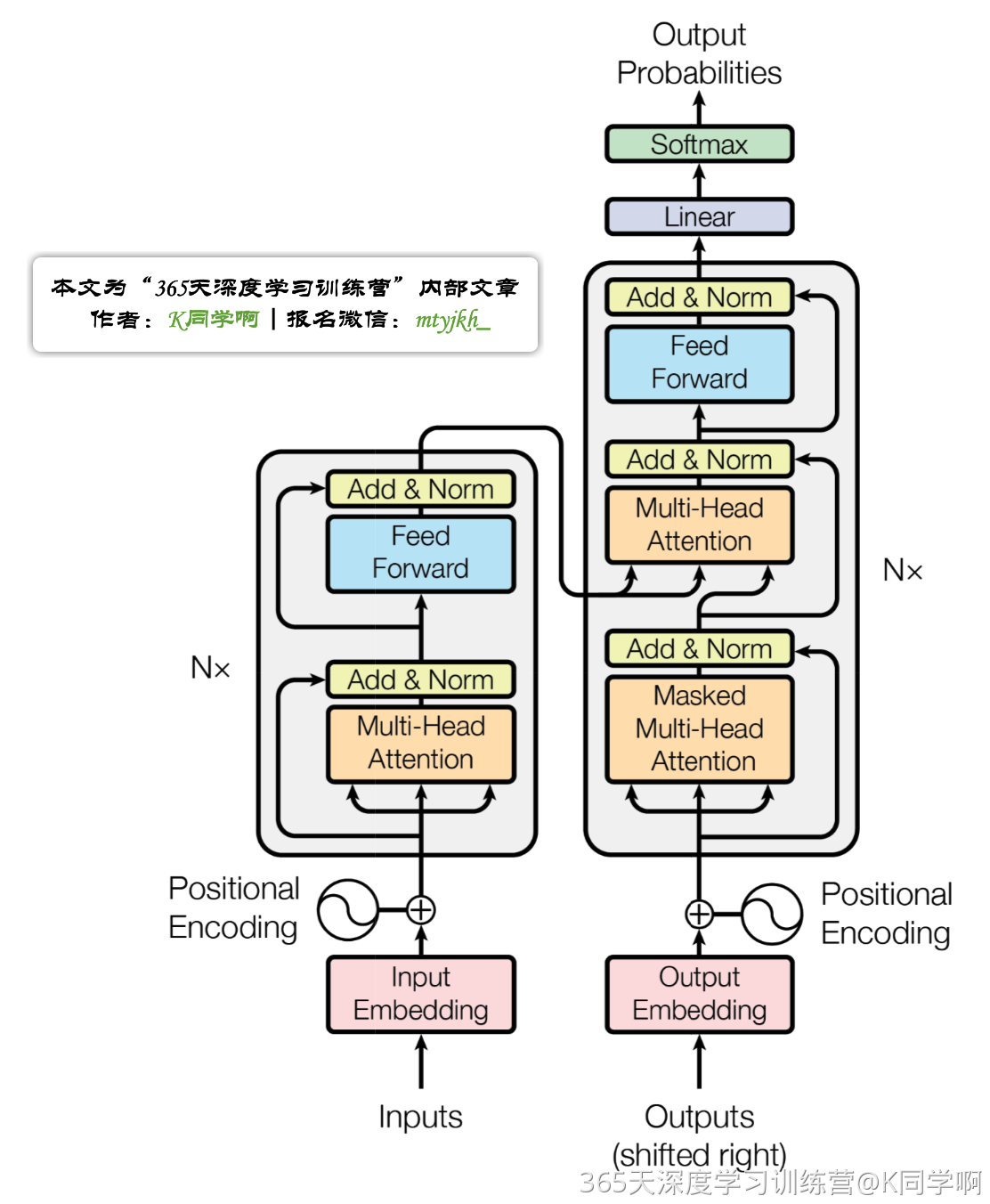
一、Transformer宏观结构¶
编码部分(encoders)由多层编码器(Encoder)组成。解码部分(decoders)也是由多层的解码器(Decoder)组成。每层编码器、解码器网络结构是一样的,但是不同层编码器、解码器网络结构不共享参数。
单层encoder主要由以下两部分组成
- Self-Attention Layer:Self-Attention层处理一个词向量的时候,不仅会使用这个词本身的信息,也会使用句子中其他词的信息(你可以类比为:当我们翻译一个词的时候,不仅会只关注当前的词,也会关注这个词的上下文的其他词的信息)
- Feed Forward Neural Network(前馈神经网络,缩写为 FFNN)
decoder在encoder的self-attention和FFNN中间多了一个Encoder-Decoder Attention层,这个层帮助解码器聚焦于输入序列最相关的部分。
总的来说,Transformer由编码部分和解码部分组成,而编码部分和解码部分又由多个网络结构相同的编码层和解码层组成。每个编码层由self-attention和FFNN组成,每个解码层由self-attention、FFN和encoder-decoder attention组成。
二、Transformer结构细节¶
1、输入¶
- 词向量:会使用词嵌入算法(embedding algorithm),将输入文本序列的每个词转换为一个词向量。
- 位置向量:Transformer模型对每个输入的词向量都加上了一个位置向量。这些向量有助于确定每个单词的位置特征,或者句子中不同单词之间的距离特征。
2、编码器encoder¶
编码部分的输入文本序列经过输入处理之后得到了一个向量序列,这个向量序列将被送入第1层编码器,第1层编码器输出的同样是一个向量序列,再接着送入下一层编码器:第1层编码器的输入是融合位置向量的词向量,更上层编码器的输入则是上一层编码器的输出。
算机制:向量线性变换得到“分数”,利用向量点积、均一化、乘以Value向量、排序、相加 算矩阵:把上面的计算结果组成矩阵计算(组合成一步更快)
多头注意力机制:进一步完善了 Self-Attention¶
- 关注不同位置的能力
- 赋予Attention层多个“子表示空间”
残差连接和标准化¶
编码器的每个子层(Self-Attention 层和 FFNN)都有一个残差连接和层标准化(layer-normalization) 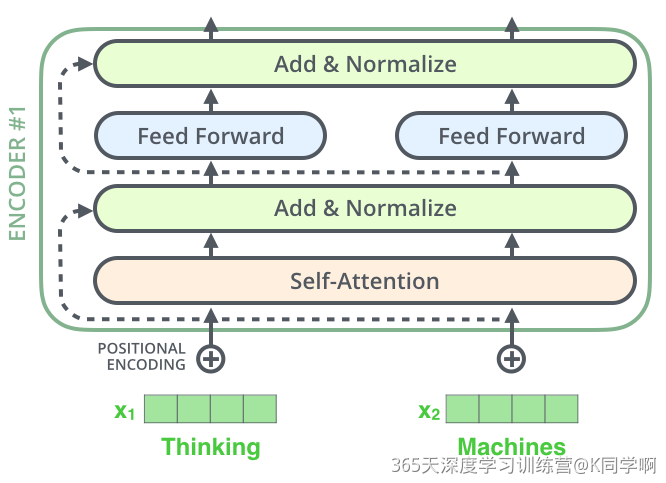
3、解码器decoder¶
编码器一般有多层,第一个编码器的输入是一个序列文本,最后一个编码器输出是一组序列向量,这组序列向量会作为解码器的K、V输入,其中K=V=解码器输出的序列向量表示。这些注意力向量将会输入到每个解码器的Encoder-Decoder Attention层,这有助于解码器把注意力集中到输入序列的合适位置
解码阶段的每一个时间步都输出一个翻译后的单词(这里的例子是英语翻译),解码器当前时间步的输出又重新作为输入Q和编码器的输出K、V共同作为下一个时间步解码器的输入。然后重复这个过程,直到输出一个结束符。
解码器中的 Self-Attention 层,和编码器中的 Self-Attention 层的区别:
- 在解码器里,Self-Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self-Attention 分数经过 Softmax 层之前,屏蔽当前位置之后的那些位置(将Attention Score设置成-inf)。
- 解码器 Attention层是使用前一层的输出来构造Query 矩阵,而Key矩阵和 Value矩阵来自于编码器最终的输出。
4、线性层和softmax¶
Decoder 最终的输出是一个向量,其中每个元素是浮点数。通过线性层和 softmax 这个向量转换为单词。
5、损失函数¶
用两组概率向量的的空间距离作为loss,当然也可以使用交叉熵(cross-entropy)和 KL散度(Kullback–Leibler divergence)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号