第三章:PyTorch的主要组成模块
1、深度学习与机器学习的关联:
(1)相似处:
- 流程相似
我们在完成一项机器学习任务时的步骤,首先需要对数据进行预处理,其中重要的步骤包括数据格式的统一和必要的数据变换,同时划分训练集和测试集。接下来选择模型,并设定损失函数和优化方法,以及对应的超参数(当然可以使用sklearn这样的机器学习库中模型自带的损失函数和优化器)。最后用模型去拟合训练集数据,并在验证集/测试集上计算模型表现。

- 损失函数和优化器的设定类似:但由于深度学习模型设定的灵活性,因此损失函数和优化器要能够保证反向传播能够在用户自行定义的模型结构上实现。
(2)差异处
- 代码实现的差异:由于深度学习所需的样本量很大,一次加载全部数据运行可能会超出内存容量而无法实现;同时还有批(batch)训练等提高模型表现的策略,需要每次训练读取固定数量的样本送入模型中训练,因此深度学习在数据加载上需要有专门的设计。
- 模型实现上:由于深度神经网络层数往往较多,同时会有一些用于实现特定功能的层(如卷积层、池化层、批正则化层、LSTM层等),因此深度神经网络往往需要“逐层”搭建,或者预先定义好可以实现特定功能的模块,再把这些模块组装起来。这种“定制化”的模型构建方式能够充分保证模型的灵活性,也对代码实现提出了新的要求。
2、深度学习的特点:
读入数据是按批的,每次读入一个批次的数据,放入GPU中训练,然后将损失函数反向传播回网络最前面的层,同时使用优化器调整网络参数。这里会涉及到各个模块配合的问题。训练/验证后还需要根据设定好的指标计算模型表现。
2、GPU的设置
# 方案一:使用os.environ,这种情况如果使用GPU不需要设置
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
3、数据读入
(1)机器模型学习的五大模块
分别是数据,模型,损失函数,优化器,迭代训练

(2)数据读取机制
PyTorch的数据读取机制,是位于数据模块的一个小分支

数据模块中,又可以大致分为上面不同的子模块。Pytorch的数据读取主要包含三个类:Dataset、DataLoader、DataLoaderIter。这三者大致是一个依次封装的关系: Dataset被装进DataLoader, DataLoader被装进DataLoaderIter
(3)深度学习训练流程
一般来说PyTorch中深度学习训练的流程是这样的:
- 创建Dateset
- Dataset传递给DataLoader
- DataLoader迭代产生训练数据提供给模型
对应的一般都会有这三部分代码
# 创建Dateset(可以自定义)
dataset = face_dataset # Dataset部分自定义过的face_dataset
# Dataset传递给DataLoader
dataloader = torch.utils.data.DataLoader(dataset,batch_size=64,shuffle=False,num_workers=8)
# DataLoader迭代产生训练数据提供给模型
for i in range(epoch):
for index,(img,label) in enumerate(dataloader):
pass
如上我们可以知悉PyTorch的数据集和数据传递机制。Dataset负责建立索引到样本的映射,DataLoader负责以特定的方式从数据集中迭代的产生 一个个batch的样本集合。在enumerate过程中实际上是dataloader按照其参数sampler规定的策略调用了其dataset的getitem方法。
(4)DataLoader
torch.utils.data.DataLoader(): 构建可迭代的数据装载器, 我们在训练的时候,每一个for循环,每一次iteration,就是从DataLoader中获取一个batch_size大小的数据的。
(5)DataLoader参数介绍
DataLoader(dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=None,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None
multiprocessing_context=None)
dataset (Dataset):定义好的Map式或者Iterable式数据集。
batch_size (python:int, optional):一个batch含有多少样本 (default: 1)。
shuffle (bool, optional):每一个epoch的batch样本是相同还是随机 (default: False)。
sampler (Sampler, optional):决定数据集中采样的方法. 如果有,则shuffle参数必须为False。
batch_sampler (Sampler, optional):和 sampler 类似,但是一次返回的是一个batch内所有样本的index。和 batch_size, shuffle, sampler, drop_last 四个参数互斥。
num_workers (python:int, optional):多少个子程序同时工作来获取数据,多线程。 (default: 0)
collate_fn (callable, optional):合并样本列表以形成小批量。
pin_memory (bool, optional):如果为True,数据加载器在返回前将张量复制到CUDA固定内存中。
drop_last (bool, optional):如果数据集大小不能被batch_size整除,设置为True可删除最后一个不完整的批处理。如果设为False并且数据集的大小不能被batch_size整除,则最后一个batch将更小。(default: False)
timeout (numeric, optional):如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。 (default: 0)
worker_init_fn (callable, optional*):每个worker初始化函数 (default: None)
理解Epoch, Iteration和Batchsize的概念:
Epoch: 所有训练样本都已输入到模型中,称为一个Epoch
Iteration: 一批样本输入到模型中,称为一个Iteration
Batchsize: 一批样本的大小, 决定一个Epoch有多少个Iteration
(6)Dataset
torch.utils.data.Dataset(): Dataset抽象类,所有自定义的Dataset都需要继承它,并且必须复写__getitem__()这个类方法。

__getitem__方法的是Dataset的核心,作用是接收一个索引, 返回一个样本, 看上面的函数,参数里面接收index,然后我们需要编写究竟如何根据这个索引去读取我们的数据部分。
(7)数据读取机制的使用:以人民币二分类任务为例
我们首先要带着关于数据读取的三个问题来看:
- 读哪些数据? 我们每一次迭代要去读取一个batch_size大小的样本,那么读哪些样本呢?
- 从哪读数据? 也就是在硬盘当中该怎么去找数据,在哪设置这个参数。
- 怎么读数据?
我们的数据集是1块的图片100张,100的图片100张,我们的任务就是训练一个模型,来帮助我们对这两类图片进行分类。 这个说清楚了之后, 我们下面就带着上面的三个问题,来看我们这个任务的数据读取部分。

# 数据的路径:回答了第二个问题,从哪读数据
split_dir = os.path.join('data', 'rmb_split')
train_dir = os.path.join(split_dir, 'train')
valid_dir = os.path.join(split_dir, 'valid')
## transforms模块,进行数据预处理
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
## 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoader
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# print(train_loader)
从train_data = RMBDataset(data_dir=train_dir, transform=train_transform)开始, 这一句话里面的核心就是RMBDataset,这个是我们自己写的一个类,继承了上面的抽象类Dataset,并且重写了__getitem__()方法, 这个类的目的就是传入数据的路径,和预处理部分(看参数),然后给我们返回数据,下面看它是怎么实现的(Pycharm里面按住控制键,然后点击这个类就进入具体实现)
而代码train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)实现了获取batch_size张图片的目的。DataLoader这个类,接收的参数就是上面的RMBDataset,我们知道参数dataset是返回一个样本的张量和标签,然后参数batch_size又跟了一个BATCH_SIZE, 这个就是说一个batch里面有多少个样本。 如果有了一个batch的样本数量,有了样本总数,就能得到总共有多少个batch了。 后面的参数shuffle,这个是说我取图片的时候,把顺序打乱一下。
其实DataLoader的任务就在我们只要指定了Batch_SIZE, 比如指定10个, 我们总共是有100个训练样本,那么就可以计算出批数是10, 那么DataLoader就把样本分成10批顺序打乱的数据,每一个Batch_size里面有10个样本且都是张量和标签的形式。
我们可以先看看这个train_loader到底是个啥,打印了一下,是这样的一个东西:<torch.utils.data.dataloader.DataLoader object at 0x000001D8C284DBC8>, 看了这是一个DataLoader对象了, 也没法进行研究了,现在只知道这个东西能够返回那10批数据,每批里面有Batch_size个数据,赋值给了train_loader, 显然这是一个可迭代的对象。 那么很容易就可以想到,如果下面我们具体训练的时候,肯定是要遍历这个train_loader, 然后每一次取一批数据进行训练。
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
这段代码里面重点就是__getitem__()这个方法的实现,我们说过从这里面,我们要拿到我们的训练样本,那么怎么拿呢? 这个函数的第一行,会看到有个data_info[index], 我们只要给定了index, 那么就是通过这句代码进行获取样本的,因为这个方法后面的都比较好理解,无非就是拿到图片,然后处理,然后返回的一个逻辑。
所以上面的重点落在了data_info[index]上面,往上看这个类的初始化部分__init__,我们可以看到这个data_info是RMBDataset这个类的成员,我们会看到self.data_info = self.get_img_info(data_dir)这句代码, 找到了data_info的来源,但是这个又调用了get_img_info(data_dir)方法, 这个才是最终的根源。 所以我们又得看这个函数get_img_info(data_dir)做了什么? 我们会发现这个函数的参数是data_dir, 也就是数据在的路径,那么如果想想的话,这个函数应该是要根据这个路径去找数据的, 果然,我们把目光聚焦到这个函数发现,这个函数写了这么多代码,其实就干了一件事,根据我们给定的路径去找数据,然后返回这个数据的位置和标签。 返回的是一个list, 而list的每个元素是元组,格式就是[(样本1_loc, label_1), (样本2_loc, label_2), ....(样本n_loc, label_n)]。这个其实就是data_info拿到的一个list。 有了这个list,然后又给了data_info一个index,那么取数据不就很容易了吗? data_info[index] 不就取出了某个(样本i_loc, label_i)。
这样再回到__getitem__()这个方法, 是不是很容易理解了, 第一行我们拿到了一个样本的图片路径和标签。然后第二行就是去找到图片,然后转成RGB数值。 第三行就是做了图片的数据预处理,最后返回了这张图片的张量形式和它的标签。 注意,这里是一个样本的张量形式和标签。 这就是RMBDataset这个类做的事情。
训练部分的核心
两层循环,外循环表示的迭代Epoch,也就是全部的训练样本喂入模型一次, 内循环表示的批次的循环,每一个Epoch中,都是一批批的喂入, 那么数据读取具体使用的核心就是for i, data in enumerate(train_loader)这句话了
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# Compute loss
optimizer.zero_grad()
loss = criterion(outputs, labels)
# backward
loss.backward()
# updata weights
optimizer.step()
对于开始三个问题的回答
- 读哪些数据? 这个我们是根据Sampler输出的index决定的
- 从哪读数据? 这个是Dataset的data_dir设置数据的路径,然后去读
- 怎么读数据? 这个是Dataset的getitem方法,可以帮助我们获取一个样本
(8)DataLoader读取数据的流程图

通过这个流程图,可以将DataLoader读取数据的逻辑关系把握住,这样才能把握宏观过程。同样我们也能够清晰的看出DataLoader和Dataset的关系。 根据前面介绍,DataLoader的作用就是构建一个数据装载器, 根据我们提供的batch_size的大小, 将数据样本分成一个个的batch去训练模型,而这个分的过程中需要把数据取到,这个就是借助Dataset的getitem方法。
(9)读取数据的最终梳理
如果我们想使用Pytorch读取数据的话,首先应该自己写一个MyDataset,这个要继承Dataset类并且实现里面的__getitem__方法,在这里面告诉机器怎么去读数据。 当然这里还有个细节,就是还要覆盖里面的__len__方法,这个是告诉机器一共有多少个样本数据。 要不然机器没法去根据batch_size的个数去确定有多少批数据。这个写起来也很简单,返回总的样本的个数即可。
def __len__(self):
return len(self.data_info)
这样, 机器就可以根据Dataset去硬盘中读取数据,接下来就是用DataLoader构建一个可迭代的数据装载器,传入如何读取数据的机制Dataset,传入batch_size, 就可以返回一批批的数据了。 当然这个装载器具体使用是在模型训练的时候。 当然,由于DataLoader是一个可迭代对象,当我们构建完毕之后,也可以简单的看下里面的数据到底长什么样, 大致代码是:
for x, y in train_loader:
print(x, y)
break
# 这样应该能看到一个批次的数据
4、模型构建
模型模块的具体内容

(1)LeNet模型的分析

LeNet的模型计算图由边和节点组成,节点就是表示每个数据,而边就是数据之间的运算。 我们可以发现,LeNet是一个很大的网络,接收输入,然后经过运算得到输出, 在LeNet的内部,又分为很多个子网络层进行拼接组成,这些子网络层之间连接配合,最终完成我们想要的运算。
(2)构建模型的两大要素
- 构建子模块:比如LeNet里面的卷积层,池化层,全连接层,是在自己建立的模型(继承nn.Module)的__init__()方法中
- 拼接子模块:把子模块按照一定的顺序,逻辑进行拼接起来得到最终的LeNet模型,是在模型的forward()方法中
(3)子模块的构建
-
以纸币二分类的任务去看看如何进行LeNet模型的构建,依然是使用代码调试。模型这一行打上断点,然后进行debug调试,看看这个LeNet是怎么搭建起来的:
 -
程序运行到断点,点击步入,就进入了lenet.py文件,在这里面有个LeNet类,继承了nn.Module。 并且我们发现在它的__init__方法里面实现了各个子模块的构建。所以构建模型的第一个要素——子模块的构建就是在这里。

(4)子模块的拼接
-
主程序的模型训练部分,我们在outputs=net(inputs)打上断点,因为这里开始是模型的训练部分, 而这一行代码正是前向传播
 -
步入,进入了module.py里面的一个__call__函数, 因为我们的LeNet是继承于Module的。在这里我们会发现有一行是调用了LeNet的forward方法。
 -
我们把鼠标放在这一行,然后运行到这里,再步入,就会发现果真是调用了LeNet的forward方法:

5、nn.Module类

torch.nn: 这是Pytorch的神经网络模块, 这里的Module就是它的子模块之一,另外还有几个与Module并列的子模块, 这些子模块协同工作,各司其职。torch.nn只支持小批量处理 (mini-batches)。整个 torch.nn 包只支持小批量样本的输入,不支持单个样本的输入。比如,nn.Conv2d 接受一个4维的张量,即nSamples x nChannels x Height x Width 如果是一个单独的样本,只需要使用input.unsqueeze(0) 来添加一个“假的”批大小维度。
(1)nn.Parameter
在Pytorch中,模型的参数是需要被优化器训练的,因此,通常要设置参数为 requires_grad = True 的张量。同时,在一个模型中,往往有许多的参数,要手动管理这些参数并不是一件容易的事情。Pytorch一般将参数用nn.Parameter来表示,并且用nn.Module来管理其结构下的所有参数。
## nn.Parameter 具有 requires_grad = True 属性
w = nn.Parameter(torch.randn(2,2))
print(w) # tensor([[ 0.3544, -1.1643],[ 1.2302, 1.3952]], requires_grad=True)
print(w.requires_grad) # True
## nn.ParameterList 可以将多个nn.Parameter组成一个列表
params_list = nn.ParameterList([nn.Parameter(torch.rand(8,i)) for i in range(1,3)])
print(params_list)
print(params_list[0].requires_grad)
## nn.ParameterDict 可以将多个nn.Parameter组成一个字典
params_dict = nn.ParameterDict({"a":nn.Parameter(torch.rand(2,2)),
"b":nn.Parameter(torch.zeros(2))})
print(params_dict)
print(params_dict["a"].requires_grad)
用Module管理参数
# module.parameters()返回一个生成器,包括其结构下的所有parameters
module = nn.Module()
module.w = w
module.params_list = params_list
module.params_dict = params_dict
num_param = 0
for param in module.parameters():
print(param,"\n")
num_param = num_param + 1
print("number of Parameters =",num_param)
继承nn.Module来构建模块类,并将所有含有需要学习的参数的部分放在构造函数中
#以下范例为Pytorch中nn.Linear的源码的简化版本
#可以看到它将需要学习的参数放在了__init__构造函数中,并在forward中调用F.linear函数来实现计算逻辑。
class Linear(nn.Module):
__constants__ = ['in_features', 'out_features']
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = nn.Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = nn.Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
def forward(self, input):
return F.linear(input, self.weight, self.bias)
(2)nn.functional
nn.functional(一般引入后改名为F)有各种功能组件的函数实现。 比如:
- 激活函数系列(F.relu, F.sigmoid, F.tanh, F.softmax)
- 模型层系列(F.linear, F.conv2d, F.max_pool2d, F.dropout2d, F.embedding)
- 损失函数系列(F.binary_cross_entropy, F.mse_loss, F.cross_entropy)
为了便于对参数进行管理, 一般通过继承nn.Module转换为类的实现形式, 并直接封装在nn模块下:
- 激活函数变成(nn.ReLu, nn.Sigmoid, nn.Tanh, nn.Softmax)
- 模型层(nn.Linear, nn.Conv2d, nn.MaxPool2d, nn.Embedding)
- 损失函数(nn.BCELoss, nn.MSELoss, nn.CrossEntorpyLoss)
所以我们表面上用nn建立的这些激活函数,层,损失函数,背后都在functional里面具体实现。nn.Module这个模块除了可以管理其引用的各种参数,还可以管理其引用的子模块。
(3)nn.Module
在nn.Module中,有8个重要的属性, 用于管理整个模型,他们都是以有序字典的形式存在着:

- _parameters: 存储管理属于nn.Parameter类的属性,例如权值,偏置这些参数
- _modules: 存储管理nn.Module类, 比如LeNet中,会构建子模块,卷积层,池化层,就会存储在_modules中
- _buffers: 存储管理缓冲属性, 如BN层中的running_mean, std等都会存在这里面
- ***_hooks: 存储管理钩子函数(5个与hooks有关的字典,这个先不用管)
(4)nn.Module构建属性
先有一个大的Module继承nn.Module这个基类, 比如LeNet,然后这个大的Module里面又可以有很多的子模块,这些子模块同样也是继承于nn.Module, 在这些Module的__init__方法中,会先通过调用父类的初始化方法进行8个属性的一个初始化。构建每个子模块分为两步,第一步是初始化,第二步使用_setattr_这个方法判断value的类型,将其保存到相应的属性字典里面,然后再进行赋值给相应的成员。 这样一个个的构建子模块,最终把整个大的Module构建完毕。
(5)nn.Module总结
- 一个module可以包含多个子module(LeNet包含卷积层,池化层,全连接层)
- 一个module相当于一个运算, 必须实现forward()函数(从计算图的角度去理解)
- 每个module都有8个字典管理它的属性(最常用的就是_parameters,_modules )。
- 一般情况下,我们很少直接使用 nn.Parameter来定义参数构建模型,而是通过拼装一些常用的模型层来构造模型。这些模型层也是继承自nn.Module的对象,本身也包括参数,属于我们要定义的模块的子模块。
(6)nn.Module管理子模块的方法
- children() 方法: 返回生成器,包括模块下的所有子模块。
- named_children()方法:返回一个生成器,包括模块下的所有子模块,以及它们的名字。
- modules()方法:返回一个生成器,包括模块下的所有各个层级的模块,包括模块本身。
- named_modules()方法:返回一个生成器,包括模块下的所有各个层级的模块以及它们的名字,包括模块本身。
例子
- 建立了一个神经网络,包含两个子模块,分别用的模型容器建立的(这个下面就会说)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.embedding = nn.Embedding(num_embeddings = 10000,embedding_dim = 3,padding_idx = 1)
self.conv = nn.Sequential()
self.conv.add_module("conv_1",nn.Conv1d(in_channels = 3,out_channels = 16,kernel_size = 5))
self.conv.add_module("pool_1",nn.MaxPool1d(kernel_size = 2))
self.conv.add_module("relu_1",nn.ReLU())
self.conv.add_module("conv_2",nn.Conv1d(in_channels = 16,out_channels = 128,kernel_size = 2))
self.conv.add_module("pool_2",nn.MaxPool1d(kernel_size = 2))
self.conv.add_module("relu_2",nn.ReLU())
self.dense = nn.Sequential()
self.dense.add_module("flatten",nn.Flatten())
self.dense.add_module("linear",nn.Linear(6144,1))
self.dense.add_module("sigmoid",nn.Sigmoid())
def forward(self,x):
x = self.embedding(x).transpose(1,2)
x = self.conv(x)
y = self.dense(x)
return y
net = Net()
- 这个网络的子模块访问
i = 0
for child in net.children():
i+=1
print(child,"\n")
print("child number",i)
6、神经网络
(1)神经网络的构建
- 首先构建一个MLP模型
import torch
from torch import nn
class MLP(nn.Module):
# 声明带有模型参数的层,这里声明了两个全连接层
def __init__(self, **kwargs):
# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Linear(784, 256)
self.act = nn.ReLU()
self.output = nn.Linear(256,10)
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
def forward(self, x):
o = self.act(self.hidden(x))
return self.output(o)
以上的 MLP 类中⽆须定义反向传播函数。系统将通过⾃动求梯度⽽自动⽣成反向传播所需的 backward 函数。
- 进行调用完成计算
实例化 MLP 类得到模型变量 net 。下⾯的代码初始化 net 并传入输⼊数据 X 做一次前向计算。其中, net(X) 会调用 MLP 继承⾃自 Module 类的 call 函数,这个函数将调⽤用 MLP 类定义的forward 函数来完成前向计算。
X = torch.rand(2,784)
net = MLP()
print(net)
net(X)
MLP(
(hidden): Linear(in_features=784, out_features=256, bias=True)
(act): ReLU()
(output): Linear(in_features=256, out_features=10, bias=True)
)
tensor([[ 0.0149, -0.2641, -0.0040, 0.0945, -0.1277, -0.0092, 0.0343, 0.0627,
-0.1742, 0.1866],
[ 0.0738, -0.1409, 0.0790, 0.0597, -0.1572, 0.0479, -0.0519, 0.0211,
-0.1435, 0.1958]], grad_fn=<AddmmBackward>)
(2)神经网络的层进行自定义
- 不含模型参数的层
import torch
from torch import nn
class MyLayer(nn.Module):
def __init__(self, **kwargs):
super(MyLayer, self).__init__(**kwargs)
def forward(self, x):
return x - x.mean()
layer = MyLayer()
layer(torch.tensor([1, 2, 3, 4, 5], dtype=torch.float))
tensor([-2., -1., 0., 1., 2.])
- 含模型参数的层
Parameter 类其实是 Tensor 的子类,如果一个 Tensor 是 Parameter,那么它会⾃动被添加到模型的参数列表里。所以在⾃定义含模型参数的层时,我们应该将参数定义成 Parameter
class MyListDense(nn.Module):
def __init__(self):
super(MyListDense, self).__init__()
self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)])
self.params.append(nn.Parameter(torch.randn(4, 1)))
def forward(self, x):
for i in range(len(self.params)):
x = torch.mm(x, self.params[i])
return x
net = MyListDense()
print(net)
除了直接定义成 Parameter 类外,还可以使⽤ ParameterList 和 ParameterDict 分别定义参数的列表和字典。
class MyDictDense(nn.Module):
def __init__(self):
super(MyDictDense, self).__init__()
self.params = nn.ParameterDict({
'linear1': nn.Parameter(torch.randn(4, 4)),
'linear2': nn.Parameter(torch.randn(4, 1))
})
self.params.update({'linear3': nn.Parameter(torch.randn(4, 2))}) # 新增
def forward(self, x, choice='linear1'):
return torch.mm(x, self.params[choice])
net = MyDictDense()
print(net)
(3)常见的神经网络层
- 卷积层:卷积窗口形状为\(p*q\)的卷积层称为\(p*q\)卷积层。同样,\(p*q\)卷积或\(p*q\)卷积核说明卷积核的高和宽分别为p和q。二维卷积层将输入和卷积核做互相关运算,并加上一个标量偏差来得到输出。卷积层的模型参数包括了卷积核和标量偏差。在训练模型的时候,通常我们先对卷积核随机初始化,然后不断迭代卷积核和偏差。
import torch
from torch import nn
# 卷积运算(二维互相关)
def corr2d(X, K):
h, w = K.shape
X, K = X.float(), K.float()
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
return Y
# 二维卷积层
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
- 填充(padding)是指在输⼊高和宽的两侧填充元素(通常是0元素)。
## 创建一个⾼和宽为3的二维卷积层,然后设输⼊高和宽两侧的填充数分别为1。给定一 个高和宽为8的输入,我们发现输出的高和宽也是8。
import torch
from torch import nn
# 定义一个函数来计算卷积层。它对输入和输出做相应的升维和降维
import torch
from torch import nn
# 定义一个函数来计算卷积层。它对输入和输出做相应的升维和降维
def comp_conv2d(conv2d, X):
# (1, 1)代表批量大小和通道数
X = X.view((1, 1) + X.shape)
Y = conv2d(X)
return Y.view(Y.shape[2:]) # 排除不关心的前两维:批量和通道
# 注意这里是两侧分别填充1⾏或列,所以在两侧一共填充2⾏或列
conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3,padding=1)
X = torch.rand(8, 8)
comp_conv2d(conv2d, X).shape
# 使用高为5、宽为3的卷积核。在⾼和宽两侧的填充数分别为2和1
conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(5, 3), padding=(2, 1))
comp_conv2d(conv2d, X).shape
- 步幅:在二维互相关运算中,卷积窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输⼊数组上滑动。将每次滑动的行数和列数称为步幅(stride)。
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
comp_conv2d(conv2d, X).shape
- 池化层
池化层每次对输入数据的一个固定形状窗口(⼜称池化窗口)中的元素计算输出。不同于卷积层里计算输⼊和核的互相关性,池化层直接计算池化窗口内元素的最大值或者平均值。该运算也 分别叫做最大池化或平均池化。在二维最⼤池化中,池化窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输⼊数组上滑动。当池化窗口滑动到某⼀位置时,窗口中的输入子数组的最大值即输出数组中相应位置的元素。
import torch
from torch import nn
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
(4)模型示例——LeNet
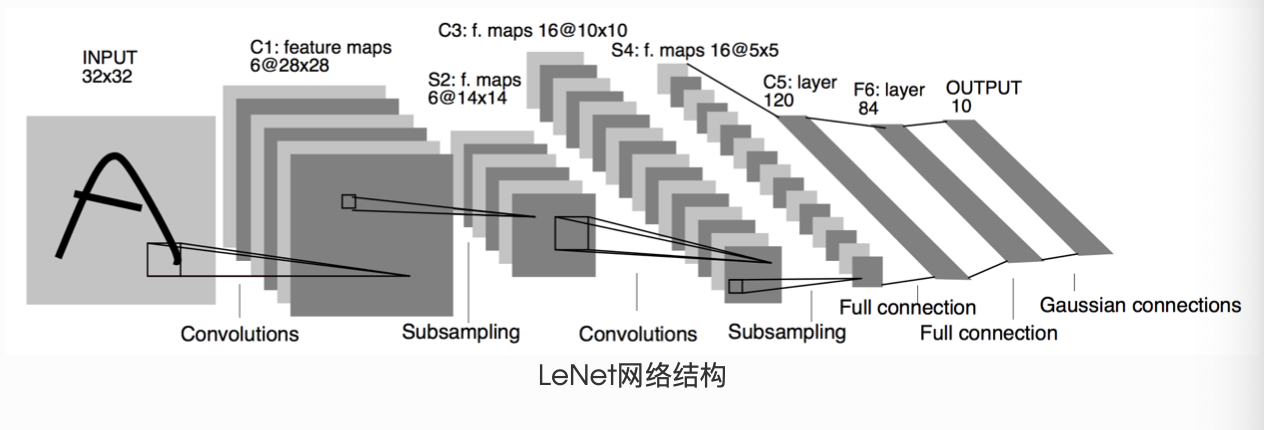
这是一个简单的前馈神经网络 (feed-forward network)(LeNet)。它接受一个输入,然后将它送入下一层,一层接一层的传递,最后给出输出。
(4)神经网络的典型训练过程
- 定义包含一些可学习参数(或者叫权重)的神经网络
- 在输入数据集上迭代
- 通过网络处理输入
- 计算 loss (输出和正确答案的距离)
- 将梯度反向传播给网络的参数
- 更新网络的权重,一般使用一个简单的规则:weight = weight - learning_rate * gradient
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 输入图像channel:1;输出channel:6;5x5卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 2x2 Max pooling
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 如果是方阵,则可以只使用一个数字进行定义
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 除去批处理维度的其他所有维度
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
Net(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
我们只需要定义 forward 函数,backward函数会在使用autograd时自动定义,backward函数用来计算导数。我们可以在 forward 函数中使用任何针对张量的操作和计算。
一个模型的可学习参数可以通过net.parameters()返回
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1的权重
10
torch.Size([6, 1, 5, 5])
7、[模型初始化](( https://www.cnblogs.com/MinPage/p/13993087.html#:~:text=初始化参数指的是在网络模型 训练之前 ,对各个节点的 权重 和 偏置 ,%E8%BF%9B%E8%A1%8C%20%E5%88%9D%E5%A7%8B%E5%8C%96%E8%B5%8B%E5%80%BC%20%E7%9A%84%E8%BF%87%E7%A8%8B%E3%80%82%20%E5%9C%A8%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%B8%AD%EF%BC%8C%20%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%E7%9A%84%E6%9D%83%E9%87%8D%E5%88%9D%E5%A7%8B%E5%8C%96%E6%96%B9%E6%B3%95%EF%BC%88weight%20initialization%EF%BC%89%E5%AF%B9%E6%A8%A1%E5%9E%8B%E7%9A%84%E6%94%B6%E6%95%9B%E9%80%9F%E5%BA%A6%E5%92%8C%E6%80%A7%E8%83%BD%E6%9C%89%E7%9D%80%E8%87%B3%E5%85%B3%E9%87%8D%E8%A6%81%E7%9A%84%E5%BD%B1%E5%93%8D%20%E3%80%82))

初始化参数指的是在网络模型训练之前,对各个节点的权重和偏置进行初始化赋值的过程。在深度学习中,神经网络的权重初始化方法(weight initialization)对模型的收敛速度和性能有着至关重要的影响。模型的训练,简而言之,就是对权重参数W的不停迭代更新,以期达到更好的性能。而随着网络深度(层数)的增加,训练中极易出现梯度消失或者梯度爆炸等问题。因此,对权重W的初始化显得至关重要,一个好的权重初始化虽然不能完全解决梯度消失或梯度爆炸的问题,但是对于处理这两个问题是有很大帮助的,并且十分有利于提升模型的收敛速度和性能表现。
(1)随机初始化模型参数的原因

我们知道神经网络层中会有激活函数,假设当前激活函数为sigmoid激活函数。当x的绝对值变大时,函数值越来越平滑,趋于饱和,这个时候函数的导数趋于0,例如,在x=2时,函数的导数约为1/10,而在x=10时,函数的导数已经变成约为1/22000,也就是说,激活函数的输入是10的时候比2的时候神经网络的学习速率要慢2200倍。(步长相同的情况下,越陡,下降的速度越快)。
为了让神经网络学习得快一些,我们希望激活函数sigmoid的导数较大。我们知道,一个神经元的输入是前一层神经元的输出的加权和。因此,我们可以通过控制权重参数初始值的范围,使得神经元的输入落在我们需要的范围内,以便梯度下降能够更快的进行。
(2)神经网络模型运算过程

由图可知,每一个层内部的组成主要有:
输入X/hi:来自原始样本XX的输入(i=0)或上一层(i−1层)的输出hi-1。
权重Wi:网络模型训练的主体对象,第i层的权重参数wi。
状态值zi:作为每一层激活函数f的输入,处于网络层的内部,所以称之为状态值。
激活值h:状态值zi经过了激活函数f后的输出,也就是第i层的最终输出hi;
数据在网络模型中流动的时候,则会有(这里默认没有偏置项B):$$\begin{align}z^i &= w^i \cdot h^{i - 1} \ h^i &= f(z^i)\end{align}$$
然后在反向传播的过程中,由于是复合函数的求导,根据链式法则,会有两组导数,一个是损失函数Cost对z的导数,一个是损失函数Cost对W的导数,(详细过程这里不推导),这里再引入两个概念:
1)损失函数Cost关于状态值z的梯度:即\(\frac{\partial Cost}{\partial z}\)
2)损失函数Cost关于权重参数W的梯度:即\(\frac{\partial Cost}{\partial W}\)
(3)参数初始化的两个基本条件
参数初始化的目的是为了让神经网络在训练过程中学习到有用的信息,这意味着参数梯度不应该为0。而我们知道在全连接的神经网络中,参数梯度和反向传播得到的状态梯度以及入激活值有关————激活值饱和会导致该层状态梯度信息为0,然后导致下面所有层的参数梯度为0;入激活值为0会导致对应参数梯度为0。所以如果要保证参数梯度不等于0,那么参数初始化应该使得各层激活值不会出现饱和现象且激活值不为0。我们把这两个条件总结为参数初始化条件:
- 初始化必要条件一:各层激活值不会出现饱和现象。
- 初始化必要条件二:各层激活值不为0。
参数初始化还有几点要求
1)参数不能全部初始化为0,也不能全部初始化同一个值,为什么,请参见“对称失效”;
2)最好保证参数初始化的均值为0,正负交错,正负参数大致上数量相等;
3)初始化参数不能太大或者是太小,参数太小会导致特征在每层间逐渐缩小而难以产生作用,参数太大会导致数据在逐层间传递时逐渐放大而导致梯度消失发散,不能训练
4)如果有可能满足Glorot条件也是不错的
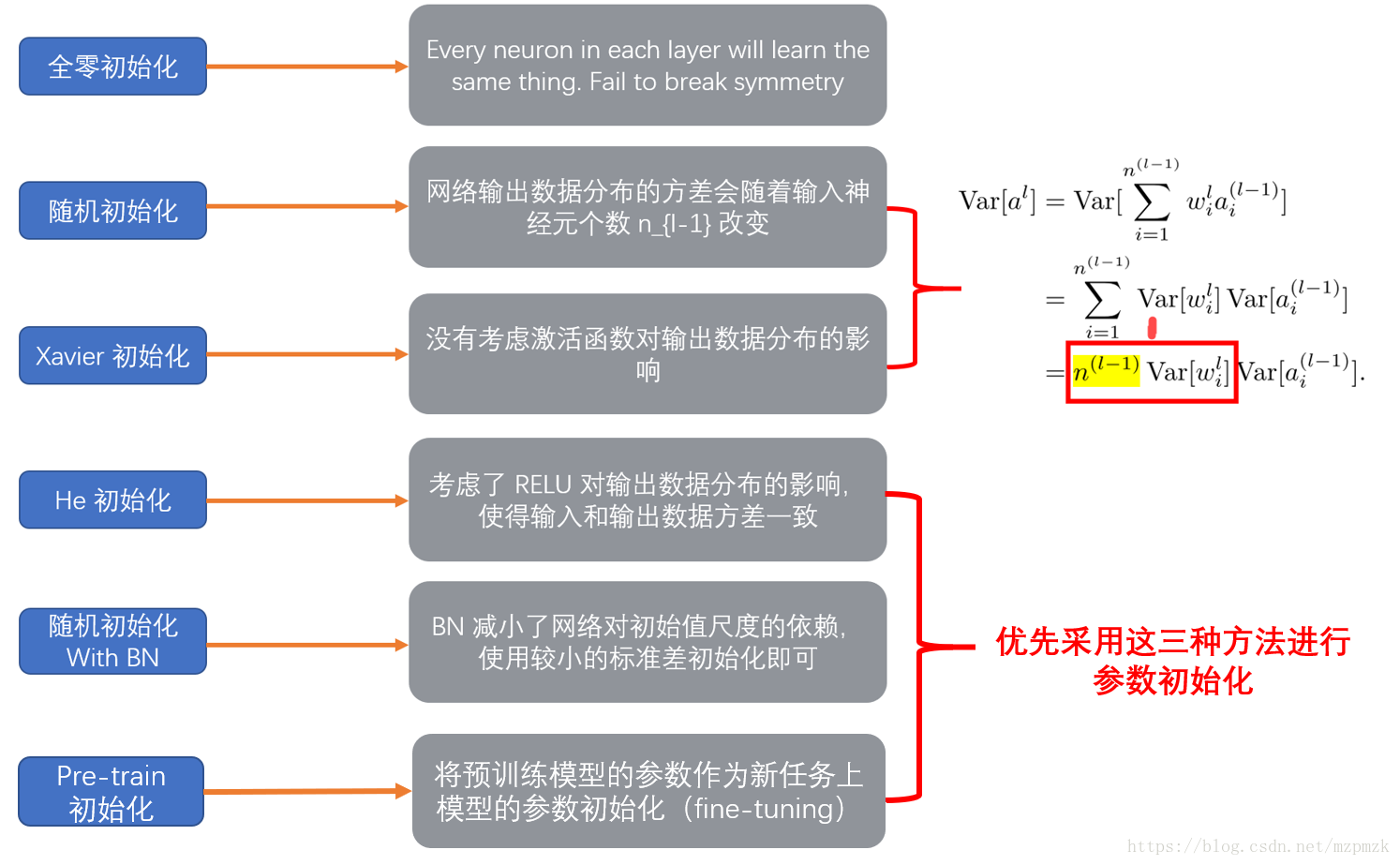
(4)常见的初始化方式
-
固定值初始化
固定初始化是指将模型参数初始化为一个固定的常数,这意味着所有单元具有相同的初始化状态,所有的神经元都具有相同的输出和更新梯度,并进行完全相同的更新,这种初始化方法使得神经元间不存在非对称性,从而使得模型效果大打折扣。 -
预训练初始化
预训练初始化是神经网络初始化的有效方式,比较早期的方法是使用 greedy layerwise auto-encoder 做无监督学习的预训练,经典代表为 Deep Belief Network;而现在更为常见的是有监督的预训练+模型微调。 -
随机初始化
随机初始化是指随机进行参数初始化,但如果不考虑随机初始化的分布则会导致梯度爆炸和梯度消失的问题。
(5)随机初始化方式——PyTorch
torch.nn.init.uniform_(tensor, a=0.0, b=1.0)
torch.nn.init.normal_(tensor, mean=0.0, std=1.0)
torch.nn.init.constant_(tensor, val)
torch.nn.init.ones_(tensor)
torch.nn.init.zeros_(tensor)
torch.nn.init.eye_(tensor)
torch.nn.init.dirac_(tensor, groups=1)
torch.nn.init.xavier_uniform_(tensor, gain=1.0)
torch.nn.init.xavier_normal_(tensor, gain=1.0)
torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan__in', nonlinearity='leaky_relu')
torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
torch.nn.init.orthogonal_(tensor, gain=1)
torch.nn.init.sparse_(tensor, sparsity, std=0.01)
torch.nn.init.calculate_gain(nonlinearity, param=None)
(6)参数初始化方法的总结
8、损失函数
它是数据输入到模型当中,产生的结果与真实标签的评价指标,我们的模型可以按照损失函数的目标来做出改进。
(1)基本概念
- 损失函数:计算一个样本的一个差异。\(Loss = f(y^{\wedge},y)\)
- 代价函数:计算整个训练集Loss的一个平均值。\(\cos t=\frac{1}{N} \sum_{i}^{N} f\left(y_{i}^{\wedge}, y_{i}\right)\)
- 目标函数:这是一个更广泛的概念,在机器学习模型训练中,这是最终的一个目标,过拟合和欠拟合之间进行一个权衡。\(Obj = \cos t + Regularization\)
(2)PyTorch中的损失函数

在PyTorch中,_Loss也是继承于Module,既然_Loss也是继承于这个类,那么肯定_Loss也有8个参数字典,这里面设置了一个reduction参数。
通过探究损失函数的初始化和使用方法的内部运行机制。我们发现了损失函数其实也是一个Module,既然是Module,那么初始化依然是有8个属性字典,使用的方法依然是定义在了forward函数中。
(3)交叉熵的推导
熵:是信息论之父香农从热力学借鉴来的名词,用来描述事件的不确定性,一个事物不确定性越大,熵就越大。比如明天会下雨这个熵就比明天太阳从东边升起这个熵要大。熵的公式如下:
也即,熵是自信息的一个期望。自信息公式如下:
也即,自信息就是一个事件发生的概率取对数再取反。也就是一个事件如果发生的概率越大,那么自信息就会少。所有事件发生的概率都很大,那么信息熵就会小,则事件的不确定性就小。如图:

这是一个两点分布的一个信息熵,可以看到,当概率是0.5的时候熵最大,也就是事件的不确定性最大,熵大约是0.69。 这个数是不是很熟悉?因为这个在二分类模型中经常会碰到,模型训练坏了的时候,或者刚训练的时候,我们就会发现Loss值也可能是0.69,这时候就说模型目前没有任何的判断能力。 这就是信息熵的概念。
相对熵:又称为KL散度,用来衡量两个分布之间的差异,也就是两个分布之间的距离,但是不是一个距离函数,因为距离函数有对称性,也就是p到q的距离等于q到p的距离。而这里的相对熵不具备这样的对称性, 如果看过我写的生成对抗原理推导那篇博客的话,那里面也有KL散度这个概念,并且可以通过组合这个得到一个既能够衡量分布差异也有对称性的一个概念叫做JS散度。
这里的P是数据的真实分布,Q是模型输出的分布,就是用Q的分布去逼近P的分布。所以这不具备对称性。
交叉熵=信息熵+相对熵
最终我们可以得到
在机器学习模型中,我们最小化交叉熵,其实就是最小化相对熵,因为我们训练集取出来之后就是固定的了,熵就是一个常数。
(4)交叉熵损失函数
交叉熵是衡量两个分布之间的距离
x是我们输出的概率值,class是某一个类别,在括号里面执行了一个softmax,将某个神经元的输出归一化成了概率取值,然后使用-log得到了交叉熵损失函数。
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
主要参数:
- weight:每个类别的loss设置权值。
- size_average:数据为bool,为True时,返回的loss为平均值;为False时,返回的各样本的loss之和。
- ignore_index:忽略某个类的损失函数。
- reduce:数据类型为bool,为True时,loss的返回是标量。
(5)损失函数的任务分类
- 分类问题
- 二分类单标签问题: nn.BCELoss, nn.BCEWithLogitsLoss, nn.SoftMarginLoss
- 二分类多标签问题:nn.MultiLabelSoftMarginLoss
- 多分类单标签问题: nn.CrossEntropyLoss, nn.NLLLoss, nn.MultiMarginLoss
- 多分类多标签问题: nn.MultiLabelMarginLoss,
- 不常用:nn.PoissonNLLLoss, nn.KLDivLoss
- 回归问题: nn.L1Loss, nn.MSELoss, nn.SmoothL1Loss
- 时序问题:nn.CTCLoss
- 人脸识别问题:nn.TripletMarginLoss
- 半监督Embedding问题(输入之间的相似性): nn.MarginRankingLoss, nn.HingeEmbeddingLoss, nn.CosineEmbeddingLoss
(6)思维导图

9、PyTorch训练和评估
完成了上述设定后就可以加载数据开始训练模型了。
(1)设置模型的状态
如果是训练状态,那么模型的参数应该支持反向传播的修改;如果是验证/测试状态,则不应该修改模型参数。在PyTorch中,模型的状态设置非常简便,如下的两个操作二选一即可:
model.train() # 训练状态
model.eval() # 验证/测试状态
(2)进行训练过程
用for循环读取DataLoader中的全部数据。
# 读取全部数据
for data, label in train_loader:
# 将数据放到GPU上用于后续计算,此处以.cuda()为例
data, label = data.cuda(), label.cuda()
# 用当前批次数据做训练时,将优化器的梯度置零:
optimizer.zero_grad()
# 将data送入模型中训练:
output = model(data)
# 根据预先定义的criterion计算损失函数:
loss = criterion(output, label)
# 将loss反向传播回网络:
loss.backward()
# 使用优化器更新模型参数:
optimizer.step()
(3)验证/测试的流程
流程基本与训练过程一致,不同点在于:
- 需要预先设置torch.no_grad,以及将model调至eval模式
- 不需要将优化器的梯度置零
- 不需要将loss反向回传到网络
- 不需要更新optimizer
(4)完整的图像分类训练过程
def train(epoch):# 训练过程
model.train()
train_loss = 0
for data, label in train_loader:
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(label, output)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val(epoch):# 验证过程
model.eval()
val_loss = 0
with torch.no_grad():
for data, label in val_loader:
data, label = data.cuda(), label.cuda()
output = model(data)
preds = torch.argmax(output, 1)
loss = criterion(output, label)
val_loss += loss.item()*data.size(0)
running_accu += torch.sum(preds == label.data)
val_loss = val_loss/len(val_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, val_loss))
10、可视化
对一些必要的内容进行可视化,比如分类的ROC曲线,卷积网络中的卷积核,以及训练/验证过程的损失函数曲线等等。
11、优化器
深度学习的目标是通过不断改变网络参数,使得参数能够对输入做各种非线性变换拟合输出,本质上就是一个函数去寻找最优解,只不过这个最优解是一个矩阵,而如何快速求得这个最优解是深度学习研究的一个重点
我们通过前向传播的过程,得到了模型输出与真实标签的差异,我们称之为损失, 有了损失,我们会进入反向传播过程得到参数的梯度,那么接下来就是优化器干活了,优化器要根据我们的这个梯度去更新参数,使得损失不断的降低。 那么优化器是怎么做到的呢? 下面我们从三部分进行展开,首先是优化器的概念,然后是优化器的属性和方法,最后是常用的优化器。
(1)什么是优化器:管理并更新模型中可学习参数的值,使得模型输出更接近真实标签
- 导数: 函数在指定坐标轴上的变化率
- 方向导数: 指定方向上的变化率
- 梯度: 一个向量, 方向为方向导数取得最大值的方向,也就是增长最快的方向。
- 梯度下降:沿着梯度的负方向去变化,这样函数的下降也是最快的。所以我们往往采用梯度下降的方式去更新权值,使得函数的下降尽量的快。
(2)Optimizer的基本属性和方法
基本属性

- defaults: 优化器超参数,里面会存储一些学习率, momentum的值,衰减系数等
{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}
- state: 参数的缓存, 如momentum的缓存(使用前几次梯度进行平均)
defaultdict(<class 'dict'>, {tensor([[ 0.3864, -0.0131],
[-0.1911, -0.4511]], requires_grad=True): {'momentum_buffer': tensor([[0.0052, 0.0052],
[0.0052, 0.0052]])}})
- param_groups: 管理的参数组, 这是个列表,每一个元素是一个字典,在字典中有key,key里面的值才是我们真正的参数(这个很重要, 进行参数管理)
[{'params': [tensor([[-0.1022, -1.6890],[-1.5116, -1.7846]], requires_grad=True)], 'lr': 1, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}]
- _step_count: 记录更新次数, 学习率调整中使用, 比如迭代100次之后更新学习率的时候,就得记录这里的100.
基本方法

- zero_grad(): 清空所管理参数的梯度, 这里注意Pytorch有一个特性就是张量梯度不自动清零,因此每次反向传播后都需要清空梯度。

def zero_grad(self, set_to_none: bool = False):
for group in self.param_groups:
for p in group['params']:
if p.grad is not None: #梯度不为空
if set_to_none:
p.grad = None
else:
if p.grad.grad_fn is not None:
p.grad.detach_()
else:
p.grad.requires_grad_(False)
p.grad.zero_()# 梯度设置为0
- step(): 执行一步梯度更新,参数更新

def step(self, closure):
raise NotImplementedError
- add_param_group(): 添加参数组, 我们知道优化器管理很多参数,这些参数是可以分组的,我们对不同组的参数可以设置不同的超参数, 比如模型finetune中,我们希望前面特征提取的那些层学习率小一些,而后面我们新加的层学习率大一些更新快一点,就可以用这个方法。

def add_param_group(self, param_group):
assert isinstance(param_group, dict), "param group must be a dict"
# 检查类型是否为tensor
params = param_group['params']
if isinstance(params, torch.Tensor):
param_group['params'] = [params]
elif isinstance(params, set):
raise TypeError('optimizer parameters need to be organized in ordered collections, but '
'the ordering of tensors in sets will change between runs. Please use a list instead.')
else:
param_group['params'] = list(params)
for param in param_group['params']:
if not isinstance(param, torch.Tensor):
raise TypeError("optimizer can only optimize Tensors, "
"but one of the params is " + torch.typename(param))
if not param.is_leaf:
raise ValueError("can't optimize a non-leaf Tensor")
for name, default in self.defaults.items():
if default is required and name not in param_group:
raise ValueError("parameter group didn't specify a value of required optimization parameter " +
name)
else:
param_group.setdefault(name, default)
params = param_group['params']
if len(params) != len(set(params)):
warnings.warn("optimizer contains a parameter group with duplicate parameters; "
"in future, this will cause an error; "
"see github.com/pytorch/pytorch/issues/40967 for more information", stacklevel=3)
# 上面好像都在进行一些类的检测,报Warning和Error
param_set = set()
for group in self.param_groups:
param_set.update(set(group['params']))
if not param_set.isdisjoint(set(param_group['params'])):
raise ValueError("some parameters appear in more than one parameter group")
# 添加参数
self.param_groups.append(param_group)
- state_dict():获取优化器当前状态信息字典

def state_dict(self):
r"""Returns the state of the optimizer as a :class:`dict`.
It contains two entries:
* state - a dict holding current optimization state. Its content
differs between optimizer classes.
* param_groups - a dict containing all parameter groups
"""
# Save order indices instead of Tensors
param_mappings = {}
start_index = 0
def pack_group(group):
......
param_groups = [pack_group(g) for g in self.param_groups]
# Remap state to use order indices as keys
packed_state = {(param_mappings[id(k)] if isinstance(k, torch.Tensor) else k): v
for k, v in self.state.items()}
return {
'state': packed_state,
'param_groups': param_groups,
}
- load_state_dict() :加载状态参数字典,与state_dict()均可用来进行模型的断点续训练,继续上次的参数进行训练。所以我们在模型训练的时候,一般多少个epoch之后就要保存当前的状态信息。
这两个方法用于保存和加载优化器的一个状态信息,通常用在断点的续训练, 比如我们训练一个模型,训练了10次停电了, 那么再来电的时候我们就得需要从头开始训练,但是如果有了这两个方法,我们就可以再训练的时候接着上次的次数继续, 所以这两个也非常实用。

def load_state_dict(self, state_dict):
r"""Loads the optimizer state.
Arguments:
state_dict (dict): optimizer state. Should be an object returned
from a call to :meth:`state_dict`.
"""
# deepcopy, to be consistent with module API
state_dict = deepcopy(state_dict)
# Validate the state_dict
groups = self.param_groups
saved_groups = state_dict['param_groups']
if len(groups) != len(saved_groups):
raise ValueError("loaded state dict has a different number of "
"parameter groups")
param_lens = (len(g['params']) for g in groups)
saved_lens = (len(g['params']) for g in saved_groups)
if any(p_len != s_len for p_len, s_len in zip(param_lens, saved_lens)):
raise ValueError("loaded state dict contains a parameter group "
"that doesn't match the size of optimizer's group")
# Update the state
id_map = {old_id: p for old_id, p in
zip(chain.from_iterable((g['params'] for g in saved_groups)),
chain.from_iterable((g['params'] for g in groups)))}
def cast(param, value):
r"""Make a deep copy of value, casting all tensors to device of param."""
.....
# Copy state assigned to params (and cast tensors to appropriate types).
# State that is not assigned to params is copied as is (needed for
# backward compatibility).
state = defaultdict(dict)
for k, v in state_dict['state'].items():
if k in id_map:
param = id_map[k]
state[param] = cast(param, v)
else:
state[k] = v
# Update parameter groups, setting their 'params' value
def update_group(group, new_group):
...
param_groups = [
update_group(g, ng) for g, ng in zip(groups, saved_groups)]
self.__setstate__({'state': state, 'param_groups': param_groups})
(3)学习率
在梯度下降过程中,学习率起到了控制参数更新的一个步伐的作用,参数更新公式如下
如果没有学习率LR的话,往往有可能由于梯度过大而错过我们的最优值,随着迭代次数的增加,越增越大。所以这时候我们想让他跨度小一些,就得需要一个参数来控制我们的这个跨度,这个就是学习率。

可以从下面图像中发现,loss是不断上升的,这说明我们的跨度是有问题的

我们尝试改小一点学习率,就可以发现区别:

当loss上升不降的时候,有可能是学习率的问题,所以我们一般会尝试一个小的学习率。 慢慢的去进行优化。学习率一般是我们需要调的一个非常重要的超参数, 我们一般是给定一个范围,然后画出loss的变化曲线,看看哪学习率比较好
(4)动量(Momentum)
结合当前梯度与上一次更新信息,用于当前更新
所谓的Momentum梯度下降, 基本的想法是计算梯度的指数加权平均数,并利用该梯度更新权重
这里的m mm就是momentum系数,vi表示更新量,g(wi)是wi的梯度。 这里的vi就是既考虑了当前的梯度,也考虑了上一次梯度的更新信息。这样,就可以发现,当前梯度的更新量会考虑到当前梯度, 上一时刻的梯度,前一时刻的梯度,这样一直往前,只不过越往前权重越小而已。
(5)常用优化器
- optim.SGD: 随机梯度下降法
- optim.Adagrad: 自适应学习率梯度下降法
- optim.RMSprop: Adagrad的改进
- optim.Adadelta: Adagrad的改进
- optim.Adam: RMSprop结合Momentum
- optim.Adamax: Adam增加学习率上限
- optim.SparseAdam: 稀疏版的Adam
- optim.ASGD: 随机平均梯度下降
- optim.Rprop: 弹性反向传播
- optim.LBFGS: BFGS的改进
(6)学习率调整策略
学习率是可以控制更新的步伐的。 我们在训练模型的时候,一般开始的时候学习率会比较大,这样可以以一个比较快的速度到达最优点的附近,然后再把学习率降下来, 缓慢的去收敛到最优值。

所以,在模型的训练过程中,调整学习率也是非常重要的,学习率前期要大,后期要小。Pytorch中提供了一个很好的学习率的调整方法
(7)Pytorch提供的六种学习率调整策略
- StepLR:等间隔调整学习率

step_size表示调整间隔数
gamma表示调整系数
调整方式就是lr = lr ∗ gamma,这里的gamma一般是0.1-0.5
用的时候就是我们指定step_size,比如50,那么就是50个epoch调整一次学习率,调整的方式就是lr = lr ∗ gamma
- MultiStepLR:按给定间隔调整学习率

milestones表示设定调整时刻数
gamma也是调整系数
调整方式是lr = lr ∗ gamma
和上面不同的是,这里的间隔我们可以自己调,构建一个list,比如[50, 125, 150], 放入到milestones中,那么就是50个epoch,125个epoch,150个epoch调整一次学习率
- ExponentialLR:按指数衰减调整学习率

gamma表示指数的底
调整方式:\(lr = lr * gamma^{epoch}\)
- CosineAnnealingLR:余弦周期调整学习率

T_max表示下降周期,只是往下的那一块
eta_min表示学习率下限
调整方式:
- ReduceLROnPlateau: 监控指标,当指标不再变化则调整,这个非常实用。可以监控loss或者准确率,当不在变化的时候,我们再去调整。

mode: min/max两种模式(min就是监控指标不下降就调整,比如loss,max是监控指标不上升就调整, 比如acc)
factor: 调整系数,类似上面的gamma
patience: “耐心”, 接受几次不变化, 这一定要是连续多少次不发生变化
cooldown: “冷却时间”, 停止监控一段时间
verbose: 是否打印日志, 也就是什么时候更新了我们的学习率
min_lr: 学习率下限
eps: 学习率衰减最小值
- ReduceLROnPlateau: 监控指标,当指标不再变化则调整,这个非常实用。可以监控loss或者准确率,当不在变化的时候,我们再去调整。
mode: min/max两种模式(min就是监控指标不下降就调整,比如loss,max是监控指标不上升就调整, 比如acc)
factor: 调整系数,类似上面的gamma
patience: “耐心”, 接受几次不变化, 这一定要是连续多少次不发生变化
cooldown: “冷却时间”, 停止监控一段时间
verbose: 是否打印日志, 也就是什么时候更新了我们的学习率
min_lr: 学习率下限
eps: 学习率衰减最小值
- LambdaLR:自定义调整策略,这个也比较实用,可以自定义我们的学习率更新策略,这个就是真的告诉程序我们想怎么改变学习率了。并且还可以对不同的参数组设置不同的学习率调整方法,所以在模型的finetune中非常实用。

这里的lr_lambda表示function或者是list
总结
有序调整: Step、MultiStep、 Exponential和CosineAnnealing,这些得事先知道学习率大体需要在多少个epoch之后调整的时候用
自适应调整: ReduceLROnPleateau,这个非常实用,可以监控某个参数,根据参数的变化情况自适应调整
自定义调整:Lambda,这个在模型的迁移中或者多个参数组不同学习策略的时候实用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号