
week6
week6
- 简述DDL,DML,DCL,DQL,并且说明mysql各个关键字查询时候的先后顺序
- 自行设计10个sql查询语句,需要用到关键字[GROUP BY/HAVING/ORDER BY/LIMIT],至少同时用到两个。
- xtrabackup备份和还原数据库练习
- 实现mysql主从复制,主主复制和半同步复制
- 用mycat实现mysql的读写分离
- 实现openvpn部署,并且测试通过,输出博客或者自己的文档存档。
1.简述DDL,DML,DCL,DQL,并且说明mysql各个关键字查询时候的先后顺序
DDL:数据定义语句
常用于创建库、表、索引等内容
--创建操作
create database hellodb;
create table student;
create index tid_index on hellodb.stu;
create view view_stu as select * from teachers; ##创建一个select * teacher表的视图
create procedure sp_testlog() ##创建存储过程
--删除操作
drop database hellodb;
drop table student;
drop index tid_index;
--创建表,提前定义属性,一般来说都是以.sql的脚本来执行
--创建一个学生表
id字段tinyint0-256数字,非负,非空,主键,自增长auto-increment
##名字:char字符4个,非空
##性别:male or female,6个字符
##年龄:0-256,非空
create table student (
id tinyint unsigned primary key auto_increment,
name char(4) not null,
sex char(6) not null,
age tinyint unsigned
);
DML:数据修改语句
常用于对表的修改操作,一般来说都要匹配好表的字段以及字段的属性,delete from,update等语句可以加上where条件判断
insert into table_name() values(); ##插入表,新增数据
delete from table_name where id=1; ##删除表内的数据
update table_name set age=22 where tid=1; ##修改表内数据
--查看teachers表的结构
desc teachers;
show create teachers;
--操作teachers表,name对应
insert into teachers(name,age,gender) values('catyer',11,'F');
delete from teachers where tid=1;
update teachers set name='mary' where tid=1;
DCL:数据控制语句
可以看到某个用户的权限情况,并且授权给某个用户使用
可以指定给某个用户授权某个库的权限
--给同步复制用户授权对所有库授权all的权限,刷新权限
create user sync@'%' identified by '123';
grant all on *.* to sync@'%';
flush privileges;
show grants for sync@'%';
+----------------------------------------------+
| Grants for sync@% |
+----------------------------------------------+
| GRANT REPLICATION SLAVE ON *.* TO `sync`@`%` |
+----------------------------------------------+
##回收权限revoke,回收所有权限,回收插入、删除、更新等权限
revoke all on *.* from sync@'%';
revoke insert,delete,update on *.* from sync@'%';
flush privileges;
DQL:数据查询语句
一般使用的是select语句,单表查询,可以加where表示条件判断,group by表示分组,order by表示以顺序来排序,limit表示显示从第几个记录开始显示几行
##查询对应的列(域field)
select Name,Age from students;
##给输出的字段加别名,可以不这么用
select name from students where id=1;
##查询表内一共有多少条记录:count(*),有25条,只显示有值的,如果为NULL则没有
select count(*) from students;
##查询user表内的user,host
[(none)]>select user,host from mysql.user;
+------------------+-----------+
| user | host |
+------------------+-----------+
| root | % |
| sync | % |
| wp | % |
| catyer | 10.0.0.% |
##查询学生表倒序的年龄顺序,从第三个开始显示,一共显示5条记录
select * from hellodb.stu order by age desc limit 3,5;
+-------+--------------+-----+--------+
| StuID | Name | Age | Gender |
+-------+--------------+-----+--------+
| 13 | Tian Boguang | 33 | M |
| 4 | Ding Dian | 32 | M |
| 24 | Xu Xian | 27 | M |
| 5 | Yu Yutong | 26 | M |
| 17 | Lin Chong | 25 | M |
+-------+--------------+-----+--------+
MySQL查询语句各关键字的执行顺序
书写SQL语句的顺序:select--->from--->where--->group by--->having--->order by
SQL语句的执行顺序:from--->where--->group by--->having--->select--->order by
--教师表
select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | catyer | 16 | M |
| 7 | teach | 20 | M |
| 8 | teach | 22 | M |
| 9 | teach9 | 20 | M |
| 10 | a | 22 | M |
| 11 | a | 22 | M |
| 12 | a | 22 | M |
+-----+---------------+-----+--------+
--查询teachers表中男老师和女老师的平均年龄
select gender,avg(age) from teachers group by gender;
+--------+----------+
| gender | avg(age) |
+--------+----------+
| M | 31.4444 |
| F | 85.0000 |
+--------+----------+
--查询teachers表中女老师的平均年龄
select gender,avg(age) from teachers where gender='F' group by gender;
+--------+----------+
| gender | avg(age) |
+--------+----------+
| F | 85.0000 |
+--------+----------+
--查询teachers表中女老师的最小年龄
select gender,min(age) from teachers where gender='F' group by gender;
--
select * from teachers order by age desc;
2.自行设计10个sql查询语句,需要用到关键字[GROUP BY/HAVING/ORDER BY/LIMIT],至少同时用到两个。
以teacher表,stu学生表作为例子
group by+having编写规范:前面的select字段必须是group by的条件字段,或者是聚合函数(count,max,min,avg,sum);一旦group by,select语句必须跟分组字段+聚合函数
前面select name,gender,后面的group by必须是name,gender其中的一个
----查询teachers表中女老师的平均年龄
[hellodb]>select gender,avg(age) from teachers where gender='F' group by gender;
+--------+----------+
| gender | avg(age) |
+--------+----------+
| F | 41.1667 |
+--------+----------+
----查询teachers表中男老师的最大年龄
[hellodb]>select gender,max(age) from teachers group by gender having gender='M';
+--------+----------+
| gender | max(age) |
+--------+----------+
| M | 132 |
+--------+----------+
--查询女老师中年龄最大的两位
[hellodb]>select name,gender,age from teachers where gender='F' order by age desc limit 2;
+---------------+--------+-----+
| name | gender | age |
+---------------+--------+-----+
| Lin Chaoying | F | 93 |
| Miejue Shitai | F | 77 |
+---------------+--------+-----+
--查询男老师中年龄最小的3位
[hellodb]>select name,gender,age from teachers where gender='M' order by age limit 3;
+--------+--------+-----+
| name | gender | age |
+--------+--------+-----+
| catyer | M | 16 |
| teach9 | M | 20 |
| teach | M | 32 |
+--------+--------+-----+
--统计年龄大于30岁小于70岁的女教师
select name,gender,age from teachers where age between 30 and 70;
--统计男女老师的人数,按照性别来分组
[hellodb]>select gender,count(*) from teachers group by gender;
+--------+----------+
| gender | count(*) |
+--------+----------+
| M | 8 |
| F | 6 |
+--------+----------+
3.xtrabackup备份和还原数据库练习
xtrabackup备份工具
专业级别的MySQL备份工具,由percona公司打造的,默认MySQL上没有这个工具,专业级别的备份工具
一般使用8.0版本---->对应8.0 MySQL库--->只有一个执行脚本
2.4版本--->对应老版本MySQL
https://www.percona.com/software/mysql-database/percona-xtrabackup
xtrabackup执行过程:备份redo_log,事务日志
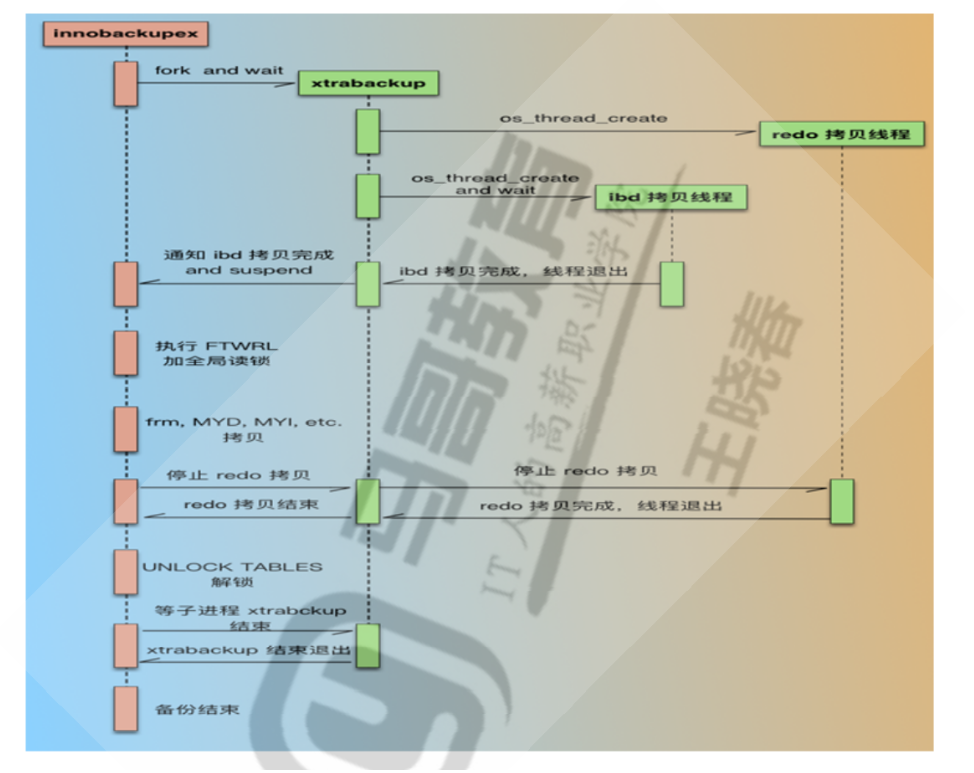

下载xtrabackup版本,下载xtrabackup 8.0的版本
https://www.percona.com/downloads/Percona-XtraBackup-LATEST
wget https://downloads.percona.com/downloads/Percona-XtraBackup-8.0/Percona-XtraBackup-8.0.29-22/binary/redhat/8/x86_64/percona-xtrabackup-80-8.0.29-22.1.el8.x86_64.rpm
yum -y install percona-xtrabackup-80-8.0.29-22.1.el8.x86_64.rpm
xtrabackup --help
xtrabackup的常用功能:能够实现全量备份、增量备份等
xtrabackup备份事务:因为事务具有原子性,必须是完整的,要么就是未执行,要么就是已经commit提交,可以实现回滚不完整的事务
xtrabackup常用选项
xtrabackup:是直接备份整个/data/mysql的目录,需要覆盖原来的目录/data/mysql才能实现恢复;MySQL服务需要停服才行
--backup:备份
--perpare:还原,回滚不完整的事务
mkdir -p /data/xtrabackup
xtrabackup -uroot -p123 --backup --target-dir=/data/xtrabackup
xtrabackup -uroot -p123 --perpare --target-dir=/data/xtrabackup
--拷贝到数据库的数据目录
xtrabackup -uroot -p123 --copy-back --target-dir=/data/xtrabackup
--修改新的数据库目录
chown -R mysql.mysql /data/xtrabackup
4.实现mysql主从复制,主主复制和半同步复制
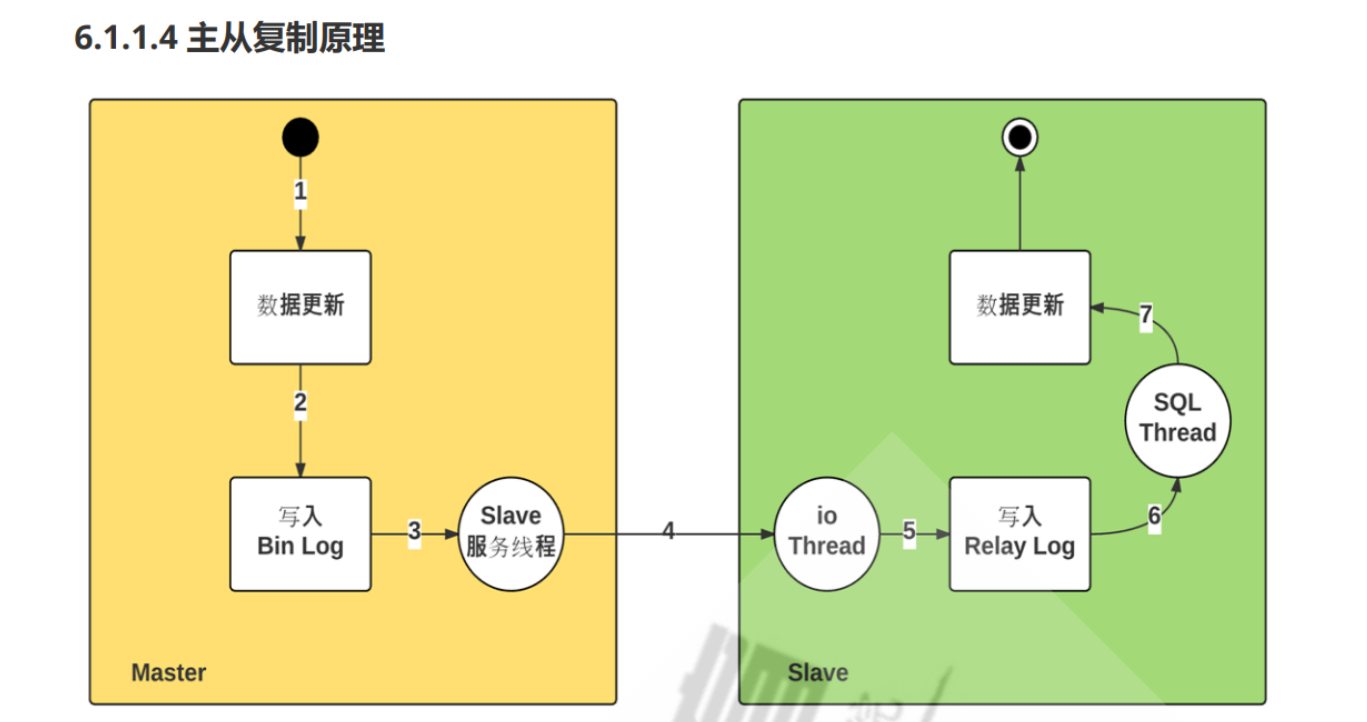
MySQL主从复制原理:
1.主节点数据更新
2.写入到主节点的binlog,更新pos
3.根据主从复制的关系,show processlist,自动复制到从节点的slave_io_thead线程
4.从节点写入relay_log
5.通过从节点的sql_io_thread写入到数据,实现同步
搭建MySQL主从同步环境
环境:主master 10.0.0.132,基本步骤,注意:主从复制关系在机器服务重启后仍然保持同步状态;从节点关机后,在开机后马上可以同步过来,如果数据量大存在一定的延迟
从slave:10.0.0.128
version:mysql 8.0.30
1.主节点
1) 二进制日志
2) server_id=
3) 创建用户,replication slave 权限
4) 全备份 --master-data=1,--master-data=2,binlog的pos加上注释
2.从节点
1) server_id=
2) source /data/full.sql 导入备份
3) CHANGE MASTER TO 修改主节点信息
MASTER_HOST='10.0.0.8',
MASTER_USER='repluser',
MASTER_PASSWORD='123456',
MASTER_PORT=3306,
MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=30489887,
MASTER_CONNECT_RETRY=5;
4) start slave;
stop slave;
reset slave all; ##重置从节点
master status:执行DML语句后的pos开始复制
start slave;
3.主主架构
1.开启binlog
如果是8.0及以下得版本,则需要手动开启binlog
##8.0默认开启binlog
show variables like "%log_bin%";
show variables like "%sql_log_bin%";
set global sql_log_bin=1;
vim /etc/my.cnf
log_bin=/data/mysql/binlog/matser-bin --->指定Binlog日志文件的前缀
systemctl restart mysqld
flush logs; --更新日志文件,更新Binlog
2.配置主从节点基本信息
##主节点,修改hostname
hostnamectl set-hostname master
##修改mysqld配置文件中的server-id,可以配置为1,每个节点的server-id一定要不一样,不然无法区分
可以配置为IP地址最后一位
vim /etc/my.cnf
[mysqld]
server-id=132
##查看主节点的二进制文件信息,不用指定任何库,直接复制所有新增写入的数据,从这个binlog的pos开始复制,--start-position=157
[(none)]>show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| rocky-bin.000019 | 157 | | | |
+------------------+----------+--------------+------------------+-------------------+
3.主节点创建同步账号,授权
revoke回收权限
##查看catyer这个用户的权限
show grants for 'catyer'@'10.0.0.%';
+-----------------------------------------------------------+
| Grants for catyer@10.0.0.% |
+-----------------------------------------------------------+
| GRANT USAGE ON *.* TO `catyer`@`10.0.0.%` |
| GRANT ALL PRIVILEGES ON `zabbix`.* TO `catyer`@`10.0.0.%` |
+-----------------------------------------------------------+
##回收删除权限
revoke delete on hellodb.* from catyer@'10.0.0.%';
flush privileges;
##回收所有权限
revoke all on hellodb.* from catyer@'10.0.0.%';
flush privileges;
各版本之间的差异,一定要执行grant,不然会出现无法生成master节点的dump线程
##早期版本5.7左右,授权+创建账号
grant replication slave on *.* to sync@'%‘ identified by '123';
--MySQL 8.0版本
create user xxx@'%' identified by '123';
show grants for sync@'%';
##回收权限,刷新权限,赋予复制权限
revoke all on *.* from sync@'%';
grant replication slave on *.* to sync@'%';
flush privileges;
[(none)]>show grants for sync@'%';
+----------------------------------------------+
| Grants for sync@% |
+----------------------------------------------+
| GRANT REPLICATION SLAVE ON *.* TO `sync`@`%` |
+----------------------------------------------+
1 row in set (0.01 sec)
这一条是failed,证明sync用户没有replication的权限

4.主节点做一份全备,导入到备节点,确保初始数据一致
可以考虑将所有都备份导出一次,形成不同的.sql文件,然后使用存储过程批量导入.sql数据,写成脚本或者是MySQL的存储过程--->可以查一下,直接或者写成事务,批量化执行,最好是脚本
因为从库可能是新库,初始数据不一致,如果直接同步的话那就只有新数据,没有老数据了
单库备份
#!/bin/bash
TIME=`date +%Y-%m-%d_%H-%M-%S`
DIR=/data/backup
DB="hellodb"
PASS=123
HOST=10.0.0.128
##-B表示选择
[ -d $DIR ] && echo "dir exist" || mkdir -p $DIR
mysqldump -uroot -p$PASS --single-transaction --source-data=2 -B $DB -F | gzip > ${DIR}/${DB}.${TIME}.sql.gz
#mysqldump -usync -p$PASS -h$HOST --single-transaction --source-data=2 -A | gzip > /data/backup/backup.sql.gz
scp ${DIR}/${DB}.${TIME}.sql.gz $HOST:/data/backup
多库备份,除去系统库+expect ssh交互
#!/bin/bash
TIME=`date +%F_%T`
DIR=/data/backup
DB="hellodb"
PASS=123
##批量化复制主机
HOST=(10.0.0.128
10.0.0.129)
[ -d $DIR ] && echo "dir exist" || mkdir -p $DIR
mysqldump -uroot -p$PASS --single-transaction --source-data=2 -A -F > ${DIR}/${DB}_${TIME}_all.sql
#mysqldump -usync -p$PASS -h$HOST --single-transaction --source-data=2 -A | gzip > /data/backup/backup.sql.gz
for IP in ${HOST[*]};do
#免交互复制ssh-keygen到目的主机
expect <<EOF
spawn ssh-copy-id root@$IP
expect {
"yes/no" {send "yes\n";exp_continue}
"password" {send "123\n"}
}
expect eof
EOF
scp ${DIR}/${DB}_${TIME}_all.sql $IP:/data/backup
echo "$IP copy success"
done
完全备份-A,直接source就行,不用选库
##-A完全备份,-F刷新日志
##!/bin/bash
TIME=`date +%Y-%m-%d_%H-%M-%S`
DIR=/data/backup
DB="hellodb"
PASS=123
HOST=10.0.0.128
[ -d $DIR ] && echo "dir exist" || mkdir -p $DIR
mysqldump -uroot -p$PASS --single-transaction --source-data=2 -A -F > ${DIR}/${DB}_${TIME}_all.sql
#mysqldump -usync -p$PASS -h$HOST --single-transaction --source-data=2 -A | gzip > /data/backup/backup.sql.gz
scp ${DIR}/${DB}_${TIME}_all.sql $HOST:/data/backup
[zabbix]>source /data/backup/hellodb_2022-09-11_09-15-11_all.sql
主节点看一下dump线程,在运行的线程
show processlist;
[(none)]>show processlist;
+----+-----------------+-----------+------+---------+------+------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------+------+---------+------+------------------------+------------------+
| 5 | event_scheduler | localhost | NULL | Daemon | 7920 | Waiting on empty queue | NULL |
| 52 | root | localhost | NULL | Query | 0 | init | show processlist |
+----+-----------------+-----------+------+---------+------+------------------------+------------------+
单表备份:直接备份一个库内的一个表
也可以备份多张表
##假如不小心清空从库表的数据
truncate table stu;
[hellodb]>select * from stu;
Empty set (0.00 sec)
##导出单表,还原
mysqldump -uroot -p123 hellodb stu > /data/stu.sql
scp /data/stu.sql 10.0.0.128:/data/
source /data/stu.sql
[hellodb]>select * from stu where stuid=25;
+-------+-------------+-----+--------+
| StuID | Name | Age | Gender |
+-------+-------------+-----+--------+
| 25 | Sun Dasheng | 100 | M |
+-------+-------------+-----+--------+
##备份多张表
mysqldump -uroot -p123 hellodb stu teachers job > /data/stu.sql
5.从节点配置文件以及导入备份,基于线程来复制
可以先导入文件,再show master status记录下binlog的pos和名字,再执行change master
vim /etc/my.cnf
read-only ##只读,防止普通用户修改数据,不能防止root
CHANGE MASTER TO
MASTER_HOST='10.0.0.132',
MASTER_USER='sync',
MASTER_PASSWORD='123',
MASTER_PORT=3306,
MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=30489887,
MASTER_CONNECT_RETRY=5;
##取消掉注释,复制过去,从节点加上binlog选项
CHANGE MASTER TO
MASTER_HOST='10.0.0.132',
MASTER_USER='sync',
MASTER_PASSWORD='123',
MASTER_PORT=3306,
MASTER_LOG_FILE='rocky-bin.000783', MASTER_LOG_POS=197;

关闭二进制,再导入,查看从节点的信息,发生生成了中继日志,即master的binlog写过来的日志存放文件relay_log,SLAVE_IO还是not running,开启复制线程
set sql_log_bin=0;
source /data/backup/hellodb_2022-09-11_10-48-26_all.sql
show slave status\G;
[zabbix]>show slave status\G;
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 10.0.0.132
Master_User: sync
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: rocky-bin.000021
Read_Master_Log_Pos: 157
Relay_Log_File: master-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: rocky-bin.000021
Slave_IO_Running: No
Slave_SQL_Running: No
start slave;
show processlist;
IO线程+SQL线程,IO线程是从主节点接收同步信息,通过SQL thread写入到从库的数据中,Query thread,显示waiting for updates
主节点:binlog dump线程


6.测试主从环境
主写新,看从有无,可以执行存储过程
测试执行存储过程,从节点直接SQL thread断掉了
[hellodb]>select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | catyer | 16 | M |
| 6 | catyer2 | 17 | M |
+-----+---------------+-----+--------+
##主节点写入新数据,删除数据,没了
[hellodb]>delete from teachers where tid=6;
Query OK, 1 row affected (0.00 sec)
[hellodb]>select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | catyer | 16 | M |
+-----+---------------+-----+--------+
5 rows in set (0.00 sec)
##测试执行存储过程
insert into teachers(name,age,gender) values('a',22,'M');
select * from teachers;
出现Slave_IO_Running: NO的解决办法:可能是用户没权限
##复制账号没权限,从节点查看
[(none)]>show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 10.0.0.132
Master_User: sync
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: rocky-bin.000022
Read_Master_Log_Pos: 60979553
Relay_Log_File: master-relay-bin.000002
Relay_Log_Pos: 326
Relay_Master_Log_File: rocky-bin.000022
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
##授权
grant replication slave on *.* to sync@'%';
flush privileges;
[(none)]>show grants for sync@'%';
+----------------------------------------------+
| Grants for sync@% |
+----------------------------------------------+
| GRANT REPLICATION SLAVE ON *.* TO `sync`@`%` |
+----------------------------------------------+
1 row in set (0.01 sec)
出现Slave_SQL_Running:No的解决办法
重新执行一下slave的change master语句,记录下master的binlog pos,修改执行
可以查看日志,错误日志:mysql-error.log,可以自定义一下错误日志的位置
##从停止slave
stop slave;
##主查看binlog日志的pos
show master status;
[hellodb]>show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| rocky-bin.000022 | 60979553 | | | |
+------------------+----------+--------------+------------------+-------------------+
##从手动修改Pos,执行
CHANGE MASTER TO
MASTER_HOST='10.0.0.132',
MASTER_USER='sync',
MASTER_PASSWORD='123',
MASTER_PORT=3306,
MASTER_LOG_FILE='rocky-bin.000784', MASTER_LOG_POS=197;
##启动slave
start slave
##可能是表结构不一致,需要修改表结构字段
2022-09-11T03:39:17.143632Z 28 [Warning] [MY-010584] [Repl] Slave SQL for channel '': ... The slave coordinator and worker threads are stopped, possibly leaving data in inconsistent state. A restart should restore consistency automatically, although using non-transactional storage for data or info tables or DDL queries could lead to problems. In such cases you have to examine your data (see documentation for details). Error_code: MY-001756
desc testlog;
show create table testlog;
执行一个存储过程后SQL_running=NO的解决,通过show master status的报错查看
https://www.cnblogs.com/Knight7971/p/9970807.html
主要是看errorlog来拍错,让我们看一下error log或者是performance_schema.replication_applier_status_by_worker,这个表来查看有什么原因导致的
在同步前,新的数据要是master节点存在,slave节点不存在的,就算是空表也不行
##先看错误现象,SQL_RUNNING为NO,让看看错误日志
[hellodb]>show slave status \G;
Seconds_Behind_Master: 21
Slave_SQL_Running: No
Last_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction 'ANONYMOUS' at master log rocky-bin.000023, end_log_pos 444.
See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any.
##查看错误日志,好像是表的什么问题,再看下一个表
tail -f mysql.log
2022-09-11T03:34:59.334704Z 23 [ERROR] [MY-013146] [Repl] Slave SQL for channel '': Worker 1 failed executing transaction 'ANONYMOUS' at master log rocky-bin.000022, end_log_pos 60979827; Column 1 of table 'hellodb.testlog' cannot be converted from type 'char(30(bytes))' to type 'char(40(bytes) utf8mb4)', Error_code: MY-013146
##查出原因了,这个testlog表已经存在了,不能往里面写数据,在同步前,新的数据
[hellodb]>select * from performance_schema.replication_applier_status_by_worker\G;
LAST_ERROR_MESSAGE: Worker 1 failed executing transaction 'ANONYMOUS' at master log rocky-bin.000023, end_log_pos 444;
Error 'Table 'testlog' already exists' on query. Default database: 'hellodb'. Query: 'create table testlog (id int auto_increment primary key,name char(30),salary int default 20) character set utf8mb4'
##删除掉表,停止slave,启动slave,修改MASTER信息
drop table testlog;
stop slave;
##从手动修改Pos,执行
CHANGE MASTER TO
MASTER_HOST='10.0.0.132',
MASTER_USER='sync',
MASTER_PASSWORD='123',
MASTER_PORT=3306,
MASTER_LOG_FILE='rocky-bin.000024', MASTER_LOG_POS=157;
start slave
##再次执行存储过程,在源端加点东西,先创建表
use hellodb;
create table testlog (id int auto_increment primary key,name char(30),salary int default 20) character set utf8mb4;
delimiter $$
create procedure sp_testlog()
begin
declare i int;
set i = 1;
while i <= 100000
do insert into testlog(name,salary) values (concat('wang',FLOOR(RAND() * 100000)),FLOOR(RAND() * 1000000));
set i = i +1;
end while;
end$$
delimiter ;
source /root/testlog.sql
call sp_testlog();
##从节点有21s的复制同步延迟,已经优化很多了
show slave status \G;
[hellodb]>select count(*) from testlog;
+----------+
| count(*) |
+----------+
| 36626 |
+----------+
Seconds_Behind_Master: 21
##完成执行存储过程的同步
[hellodb]>select count(*) from testlog;
+----------+
| count(*) |
+----------+
| 100000 |
+----------+
show processlist;
49 | sync | 10.0.0.128:60752 | NULL | Binlog Dump | 1475 | Source has sent all binlog to replica; waiting for more updates | NULL
wait for events
ss -nt:查看已经建立的TCP连接,ESTABLISHED,10.0.0.128:业务端口已建立


7.同步堵塞(blocked),序号冲突,跳过错误
跳过指定事件,跳过错误数量
show variables like '%sql_slave_skip_counter%';
##跳过N个错误
set global sql_slave_skip_counter=N
有时候,从节点没有设置为read-only只读,然后在从节点新增了记录,比如id=9,而主节点又新增记录,序号也为9,那么这个9和从节点的9就不是同一个问题,导致冲突,造成复制堵塞(blocked),entity的记录冲突了
show slave status \G;
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
##从节点写入一条记录,8号记录
insert into teachers(name,age,gender) values('tea',11,'M');
[hellodb]>select * from teachers where tid=8;
+-----+------+-----+--------+
| TID | Name | Age | Gender |
+-----+------+-----+--------+
| 8 | tea | 11 | M |
+-----+------+-----+--------+
##主节点插入一条记录
insert into teachers(name,age,gender) values('teach',20,'M');
##两边的tid-8的记录不一样了,查看一下错误
[hellodb]>select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | catyer | 16 | M |
| 7 | teach | 20 | M |
| 8 | teach | 22 | M |
+-----+---------------+-----+--------+
7 rows in set (0.00 sec)
[hellodb]>select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
| 5 | catyer | 16 | M |
| 7 | uuu | 11 | M |
| 8 | tea | 11 | M |
+-----+---------------+-----+--------+
7 rows in set (0.00 sec)
##查出是entity 7序号7直接堵塞掉了,第七条出问题,导致后面的记录都无法复制过去了
##其实是7号和8号都冲突了,需要跳过两个错误
show slave status \G;
[hellodb]>select * from performance_schema.replication_applier_status_by_worker\G;
LAST_ERROR_MESSAGE: Worker 1 failed executing transaction 'ANONYMOUS' at master log rocky-bin.000024, end_log_pos 30689864; Could not execute Write_rows event on table hellodb.teachers;
Duplicate entry '7' for key 'teachers.PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log rocky-bin.000024, end_log_pos 30689864
临时解决方案:跳过这个错误
stop slave;
##跳过2个错误
set global sql_slave_skip_counter=2;
select @@sql_slave_skip_counter;
start slave;
show slave status \G;
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
##主节点插入,有了
[hellodb]>insert into teachers(name,age,gender) values('teach9',20,'M');
[hellodb]>select * from teachers where tid=9;
+-----+--------+-----+--------+
| TID | Name | Age | Gender |
+-----+--------+-----+--------+
| 9 | teach9 | 20 | M |
+-----+--------+-----+--------+
##错误解决办法,手动改,多行记录的话,手动改多行记录就行
update xxx set where
双主架构实现:互为主节点
将主节点也执行change master,使其变为从节点的从节点,容易造成数据冲突,不建议使用,双向同步,假如说用户无意间写到两个不同的主,而不是一份数据双写
最好还是写一份数据,安全,不会冲突
环境:主master 10.0.0.132,从slave 10.0.0.128,现在132也是128的从
1.从节点上查看MySQL的binlog,记录binlog日志pos
show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| slave-bin.000004 | 157 | | | |
+------------------+----------+--------------+------------------+-------------------+
2.修改change master
CHANGE MASTER TO
MASTER_HOST='10.0.0.128',
MASTER_USER='sync',
MASTER_PASSWORD='123',
MASTER_PORT=3306,
MASTER_LOG_FILE='slave-bin.000004', MASTER_LOG_POS=157;
##启动slave
start slave
##重置
reset slave all
半同步机制(重点):同步到一个从或者超过延迟时间就返回成功,加快事务的返回--->用于主从(主备架构)
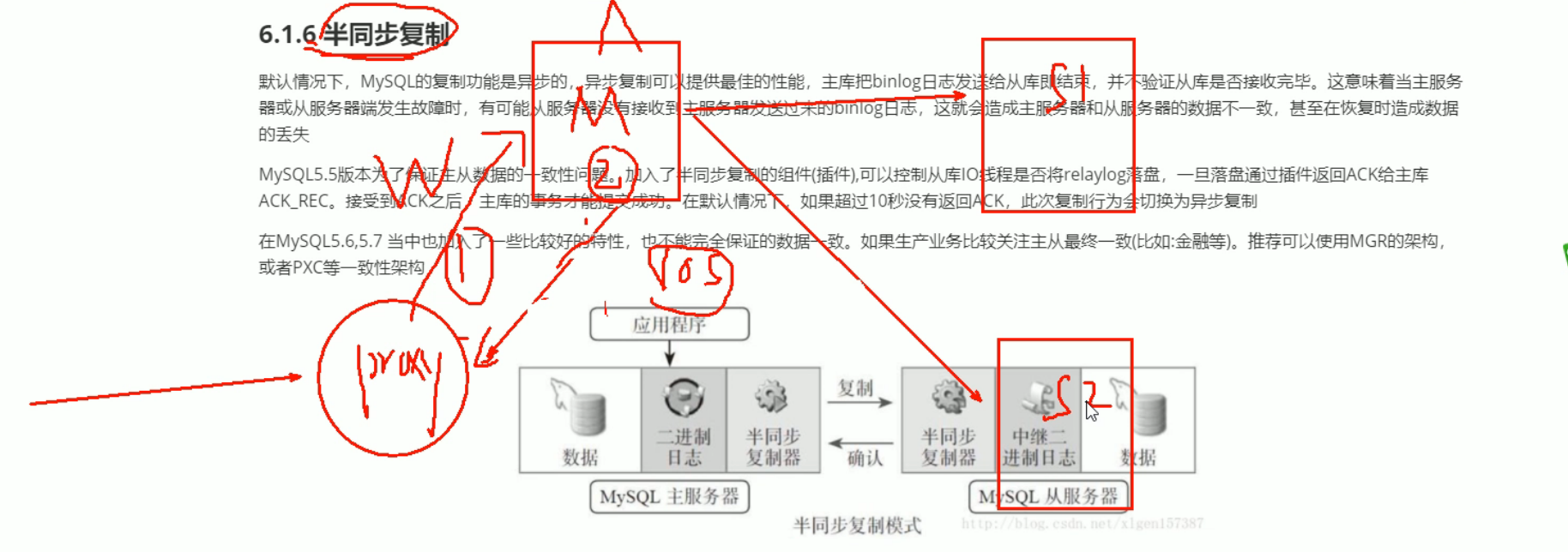
异步复制的优点:返回结果快,写入到主库了后就返回写入成功了,SQL query set
异步复制的缺陷:如果在同步的过程中,master dump thread挂了,则无法同步,从节点的数据也不是最新的;而且在slave库还需要完成SQL thread写入到磁盘,这段如果没完成也是导致数据不是最新的情况
半同步机制:加入了检查从库是否数据落盘的插件,只有主库---从库,从库的事务commit后,写入磁盘了,主库这边才返回写入成功;或者是超过了同步延时时间,也会返回写成功
基本过程(增强型半同步复制):优点,先检查是否同步,解决了主库返回成功后,访问从库(可能是只读库)没有数据,没同步到位的问题
1.用户提交事务(DML),执行SQL语句;客户端可能是本地socket,也可能是远端用户
2.写二进制日志
3.先等slave dump完成复制到slave
4.提交事务,写入磁盘
5.返回写成功
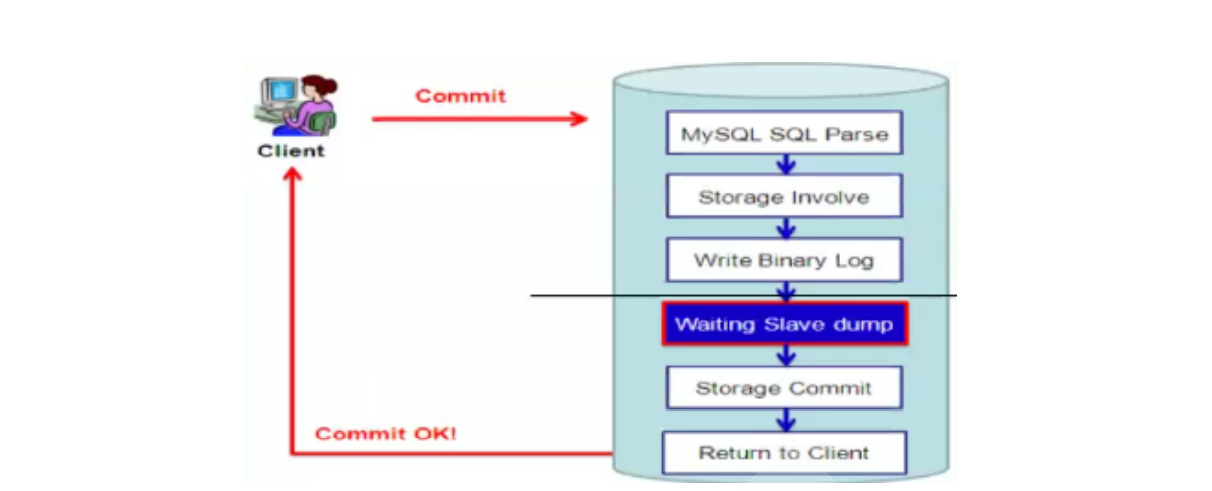
模拟环境搭建一主两从:rpl_semi_sync_master_enabled
主:132 ,从1:128,从2:131
插件:rpl_semi_sync_master_enabled,show plugins
1.同步主从数据,开启slave
##Master节点操作配置
show variables like '%rpl_semi_sync_master_enabled%';
vim /etc/my.cnf
rpl_semi_sync_master_enabled=on
rpl_semi_sync_master_timeout=
##查看系统自带的插件,安装插件
1.binlog、密码插件认证、守护进程,存储引擎等
[(none)]>show plugins;
+---------------------------------+----------+--------------------+---------+---------+
| Name | Status | Type | Library | License |
+---------------------------------+----------+--------------------+---------+---------+
| binlog | ACTIVE | STORAGE ENGINE | NULL | GPL |
| mysql_native_password | ACTIVE | AUTHENTICATION | NULL | GPL |
| sha256_password | ACTIVE | AUTHENTICATION | NULL | GPL |
| caching_sha2_password | ACTIVE | AUTHENTICATION | NULL | GPL |
| sha2_cache_cleaner | ACTIVE | AUDIT | NULL | GPL |
| daemon_keyring_proxy_plugin | ACTIVE | DAEMON | NULL | GPL |
| CSV | ACTIVE | STORAGE ENGINE | NULL | GPL |
2.安装半同步插件rpl_semi_sync_master --主从节点都要安装
install plugin rpl_semi_sync_master soname 'semisync_master.so';
Query OK, 0 rows affected, 1 warning (0.07 sec)
show plugins;
rpl_semi_sync_master | ACTIVE | REPLICATION | semisync_master.so | GPL
3.修改配置文件
vim /etc/my.cnf
rpl_semi_sync_master_enabled=on ##开启半同步功能
rpl_semi_sync_master_timeout=10000 ##默认超时时间:10s,以毫秒为单位,默认10s
[(none)]>select @@rpl_semi_sync_master_timeout;
+--------------------------------+
| @@rpl_semi_sync_master_timeout |
+--------------------------------+
| 10000 |
+--------------------------------+
systemctl restart mysqld
4.查看插件状态
[(none)]>select @@rpl_semi_sync_master_enabled;
+--------------------------------+
| @@rpl_semi_sync_master_enabled |
+--------------------------------+
| 1 |
+--------------------------------+
5.完全备份到从库,确认log-bin的pos,##master和slave1都执行,scp到从库
grep -i "change master" hellodb_2022-09-12_11:45:11_all.sql
show master status;
-- CHANGE MASTER TO MASTER_LOG_FILE='rocky-bin.000030', MASTER_LOG_POS=157;
stop slave;
source /data/backup/hellodb_2022-09-12_11:45:11_all.sql
CHANGE MASTER TO
MASTER_HOST='10.0.0.132',
MASTER_USER='sync',
MASTER_PASSWORD='123',
MASTER_PORT=3306,
MASTER_LOG_FILE='rocky-bin.000030', MASTER_LOG_POS=157;
start slave;
show slave status \G;
##确认sql_io和slave_io都启动
##如果遇到以下问题,slave同步问题
stop slave;
reset slave all;
start slave;
2.从节点安装插件
完成两边的半同步插件安装,现在没有配置timeout,都是10s
##安装插件和卸载插件,主节点master
install plugin rpl_semi_sync_master soname 'semisync_master.so';
uninstall plugin rpl_semi_sync_master;
##从节点安装slave
install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
select @@rpl_semi_sync_master_enabled;
+--------------------------------+
| @@rpl_semi_sync_master_enabled |
+--------------------------------+
| 0 |
+--------------------------------+
1.动态设置变量
set global rpl_semi_sync_master_enabled=ON;
set global rpl_semi_sync_slave_enabled=ON;
show plugins;
[(none)]>select @@rpl_semi_sync_master_enabled;
+--------------------------------+
| @@rpl_semi_sync_master_enabled |
+--------------------------------+
| 1 |
+--------------------------------+
2.主写入配置文件,从写入配置文件
vim /etc/my.cnf
[mysqld]
rpl_semi_sync_master_enabled
systemctl restart mysqld
#从写入配置文件
[mysqld]
rpl_semi_sync_slave_enabled
systemctl restart mysqld
##主节点测试查看,clients=2才是正确的
[hellodb]>show status like '%semi%';
+--------------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------------+-------+
| Rpl_semi_sync_master_clients | 2 |
| Rpl_semi_sync_master_net_avg_wait_time | 0 |
| Rpl_semi_sync_master_net_wait_time | 0 |
| Rpl_semi_sync_master_net_waits | 0 |
| Rpl_semi_sync_master_no_times | 0 |
| Rpl_semi_sync_master_no_tx | 0 |
| Rpl_semi_sync_master_status | ON |
| Rpl_semi_sync_master_timefunc_failures | 0 |
| Rpl_semi_sync_master_tx_avg_wait_time | 0 |
| Rpl_semi_sync_master_tx_wait_time | 0 |
| Rpl_semi_sync_master_tx_waits | 0 |
| Rpl_semi_sync_master_wait_pos_backtraverse | 0 |
| Rpl_semi_sync_master_wait_sessions | 0 |
| Rpl_semi_sync_master_yes_tx | 0 |
+--------------------------------------------+-------+
14 rows in set (0.00 sec)
3.测试10s的延迟,如果过了10s没有slave响应,则返回成功
可以修改全局变量超时时间,单位是ms毫秒
停掉两个slave的同步看看
stop slave;
[hellodb]>select @@rpl_semi_sync_master_timeout;
+--------------------------------+
| @@rpl_semi_sync_master_timeout |
+--------------------------------+
| 10000 |
+--------------------------------+
##修改全局变量
set global rpl_semi_sync_master_timeout=2000;
Query OK, 0 rows affected (0.00 sec)
##无slave响应,需要10s返回成功,timeout值可以设置
[hellodb]>insert into teachers(name,age,gender) values('a',22,'M');
Query OK, 1 row affected (10.00 sec)
##有slave响应,秒回,证明半同步复制是成功的
start slave;
[hellodb]>insert into teachers(name,age,gender) values('a',22,'M');
Query OK, 1 row affected (0.02 sec)
##MySQL默认配置,在同步后才提交
[hellodb]>show variables like 'Rpl_semi_sync_master_wait_point';
+---------------------------------+------------+
| Variable_name | Value |
+---------------------------------+------------+
| rpl_semi_sync_master_wait_point | AFTER_SYNC |
+---------------------------------+------------+
5.用mycat实现mysql的读写分离
5.mycat:数据库proxy的实现
proxy服务器:用于写好逻辑,如果写请求,就到主节点;如果是读请求,就到从节点(更新机、查询机等)
垂直拆分:分库分表,关系不大的表可以拆分,如果是例如stu表和teacher表的话,那就是不太方便的;分库的话,可以和开发协商好;根据不同的业务类型进行拆分
水平拆分,放在不同的服务器中,以便解放性能瓶颈,或者读写分离等
--->通过proxy代理来区分数据需要放在什么节点上,proxy代理节点也要冗余双节点,以免出现单点故障的问题
主要功能:实现一个MySQL代理proxy的功能,通过proxy与后端多个MySQL服务器相连,实现大规模的MySQL服务器集群功能
mycat核心协议:JDBC,与多个主流数据库相连,mycat是对数据库层面的抽象
工作原理:前端(HA-proxy)负载均衡---mycat proxy代理集群(冗余节点)---转发请求到后端1-N个MySQL服务器节点(冗余节点),类似K8s集群中,我们需要两个nginx节点做转发一样,万一一个pod挂了,还有另一个nginx pod作为转发请求
mycat实现读写分离:
1.接收写操作请求:转发到后端主节点,更新机
2.接收读请求:转发到后端查询机,读节点
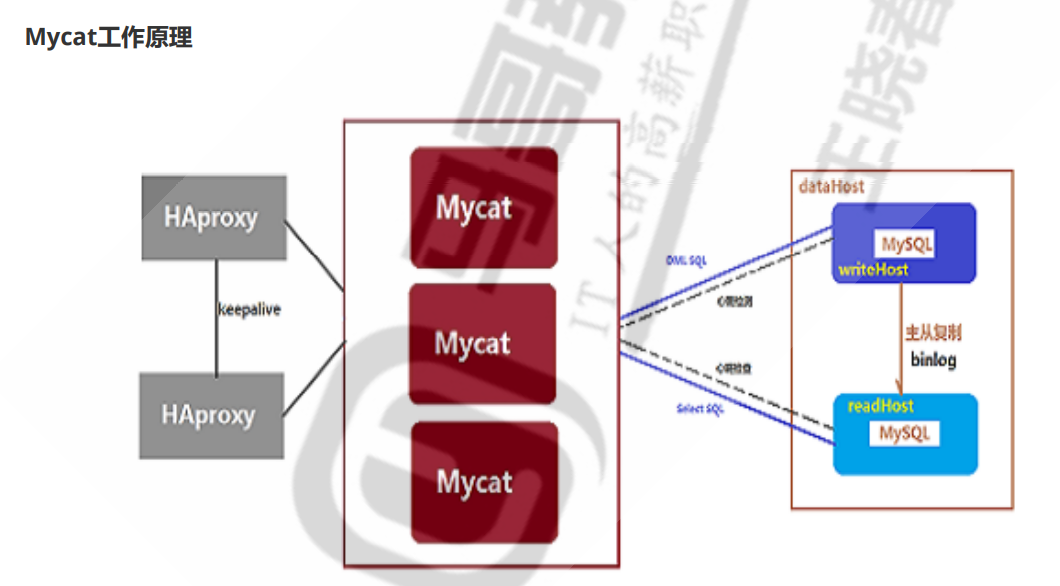
mycat实现读写分离
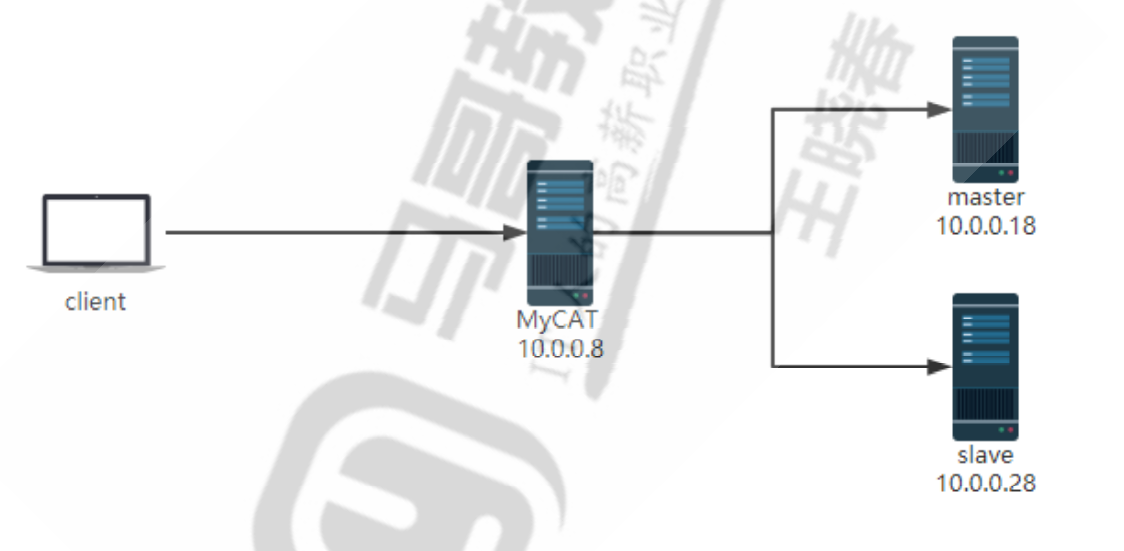
环境:客户端ubuntu 10.0.0.131
mycat节点:10.0.0.130
主节点:10.0.0.132
从节点:10.0.0.128
1.下载包,解压缩到指定目录,配置执行的环境变量,这个可用于其他的服务,例如nginx编译安装
适用于所有编译安装的服务,可以将路径写到环境变量里面去,就不用人为进入到bin目录下了,类似tomcat也一样的,nginx等很多服务
需要先下载mycat的包
tar xf Mycat-server-1.6.7.4-release-20200105164103-linux.tar.gz -C /mycat
##查看包内的内容,已经编译好的东西,可以直接使用
tar -tvf Mycat-server-1.6.7.4-release-20200105164103-linux.tar.gz
bin catlet conf lib logs version.txt
##修改执行文件的path路径,让他能够直接执行,不需要加上执行文件路径,类似nginx的路径
原路径:/apps/mycat/bin/mycat
vim /etc/profile.d/mycat.sh,让系统执行mycat指令的时候,直接去调用环境变量的PATH
PATH=/apps/mycat/bin:$PATH
##让环境变量生效
. /etc/profile.d/mycat.sh / source /etc/profile.d/mycat.sh
mycat
Usage: /apps/mycat/bin/mycat { console | start | stop | restart | status | dump }
2.安装java编译环境,修改mycat默认端口
升配一下mycat节点的内存,java进程比较吃内存
yum -y install java
##java 8版本
java -version
openjdk version "1.8.0_342"
OpenJDK Runtime Environment (build 1.8.0_342-b07)
OpenJDK 64-Bit Server VM (build 25.342-b07, mixed mode)
启动mycat,监听的是8066和9066两个端口,对外暴露的,默认两个对外端口,可以修改的
对外暴露的端口默认是3306的
mycat start
ss -ntl | grep 8066
LISTEN 0 100 :::8066 :::*
##ss -ntlp:表示显示是哪个进程协议服务占用了这个端口,仅显示TCP连接,显示users,这个端口的进程
netstat -ntlp
[11:15:41 root@proxy ~]#ss -ntlp | grep 8066
LISTEN 0 100 :::8066 :::* users:(("java",pid=11766,fd=86))
[11:15:51 root@proxy ~]#ss -ntlp | grep 9066
LISTEN 0 100 :::9066 :::* users:(("java",pid=11766,fd=82))
##查看mycat的日志,/logs/wrapper.log
[11:18:26 root@proxy logs]#tail -f wrapper.log
STATUS | wrapper | 2022/09/17 11:14:07 | --> Wrapper Started as Daemon
STATUS | wrapper | 2022/09/17 11:14:07 | Launching a JVM...
INFO | jvm 1 | 2022/09/17 11:14:08 | Wrapper (Version 3.2.3) http://wrapper.tanukisoftware.org
INFO | jvm 1 | 2022/09/17 11:14:08 | Copyright 1999-2006 Tanuki Software, Inc. All Rights Reserved.
INFO | jvm 1 | 2022/09/17 11:14:08 |
INFO | jvm 1 | 2022/09/17 11:14:09 | MyCAT Server startup successfully. see logs in logs/mycat.log
修改mycat端口,默认这一段是注释掉的,需要复制新的,并且修改默认客户端端口号;对外暴露端口:3306,管理端口:9066
mycat默认连接用户:root,默认密码:123456,修改为123
/conf/server.xml
/serverport,/user
<!-- <property name="serverPort">8066</property> <property name="managerPort">9066</property> -->
<property name="serverPort">3306</property>
<property name="managerPort">9066</property>
<user name="root" defaultAccount="true">
<property name="password">123</property>
<property name="schemas">TESTDB</property>
<property name="defaultSchema">TESTDB</property>
3.在后端MySQL上创建mycat连接用户
授权给到hellodb库的权限,读写权限,因为访问到proxy可以进行这个库的读写分离,mycat用户可以操作这个库,也可以操作所有的库
[hellodb]>create user mycat@'%' identified by '123';
Query OK, 0 rows affected (0.01 sec)
[hellodb]>grant all on hellodb.* to mycat@'%';
Query OK, 0 rows affected (0.00 sec)
[hellodb]>flush privileges;
Query OK, 0 rows affected (0.01 sec)
4.在schema.xml上实现读写分离的效果
修改schema.xml文件,修改readhost和writehost,修改后短的节点
schema name:在mycat代理上显示给客户端看的DB名字
/apps/mycat/conf/schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="localhost1" database="hellodb" /> <!-- 后端DB名字 -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="host1" url="10.0.0.132:3306" user="mycat" password="123"> <!-- 后端DB1的IP -->
<readHost host="host2" url="10.0.0.128:3306" user="mycat" password="123" /> <!-- 后端DB2的IP -->
</writeHost>
</dataHost>
</mycat:schema>
验证修改server和schema后的结果
##重启服务
mycat restart
##查看日志,jvm1,证明是java编译的东西
tail -f /apps/mycat/logs/wrappers.log
INFO | jvm 1 | 2022/09/17 14:15:46 | MyCAT Server startup successfully. see logs in logs/mycat.log
##查看机器的监听端口是不是修改成3306了
ss -ntlp | grep 3306
LISTEN 0 100 :::3306 :::* users:(("java",pid=50461,fd=86))
##客户端连接到mycat代理,随便找个网络通的,查询发现就是hellodb的内容,可直接进行读写操作
mysql -uroot -p123 -h 10.0.0.130
mysql> show databases;;
+----------+
| DATABASE |
+----------+
| TESTDB |
+----------+
1 row in set (0.00 sec)
mysql> show tables;
+-------------------+
| Tables_in_hellodb |
+-------------------+
| classes |
| coc |
| courses |
| scores |
| stu |
| teachers |
| testlog |
| toc |
+-------------------+
8 rows in set (0.01 sec)
5.验证mycat读写分离到server1和2的效果,使用general_log通用日志实现
##开启server1和server2的general_log日志
[hellodb]>select @@general_log;
+---------------+
| @@general_log |
+---------------+
| 0 |
+---------------+
set global general_log=1;
show variables like '%general_log%';
[hellodb]>show variables like '%general_log%';
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| general_log | ON |
| general_log_file | /data/mysql/rocky.log |
+------------------+-----------------------+
[(none)]>show variables like '%general_log%';
+------------------+------------------------+
| Variable_name | Value |
+------------------+------------------------+
| general_log | ON |
| general_log_file | /data/mysql/master.log |
+------------------+------------------------+
bash上开启
tail -f /data/mysql/rocky.log
tail -f /data/mysql/master.log
由ubuntu客户端向mycat进行写入
insert into teachers(name,age,gender) values('mycat',11,'M');
##位于132主节点,日志有记录,从节点上只有一个同步的事务记录下来了
2022-09-17T06:40:37.211746Z 112 Query insert into teachers(name,age,gender) values('mycat',11,'M')
2022-09-17T06:40:37.215598Z 7 Query BEGIN
2022-09-17T06:40:37.216535Z 7 Query COMMIT /* implicit, from Xid_log_event */
##查询一下查询的操作,是哪个server,看server id,查询的是128从节点
select @@server_id;
mysql> select @@server_id;
+-------------+
| @@server_id |
+-------------+
| 128 |
+-------------+
##更新操作试试,已经修改为serverid,正是132的id,证明读写分离是OK的
mysql> update teachers set age=@@server_id where tid=13;
Query OK, 1 row affected (0.01 sec)
mysql> select *from teachers where tid=13;;
+-----+-------+-----+--------+
| TID | Name | Age | Gender |
+-----+-------+-----+--------+
| 13 | mycat | 132 | M |
+-----+-------+-----+--------+
heartbeat() select user()用途
用于后端MySQL服务器的心跳检测,mycat服务器周期性的向后端MySQL机器发送健康检查的指令,=select一下用户,如果又返回结果,则证明可以MySQL服务是存活的
tail -f /apps/mycat/logs/wrappers.log
2022-09-17T06:33:46.730245Z 20 Query select user()
2022-09-17T06:33:56.730453Z 16 Query select user()
2022-09-17T06:34:06.731198Z 18 Query select user()
mycat暂时性的痛点
1.本身的proxy节点就存在单点故障的问题
2.无法保证后端主节点挂掉后,从节点可以替换上来,可以使用MHA高可用来实现
重点:MySQL主从复制的实现,主从数据的同步,binlog的pos记录,配置,可以在5.7后的版本开启gtid自动记录binlog的pos,可以比较简便的实现主从复制的binlog pos
6.实现openvpn部署,并且测试通过,输出博客或者自己的文档存档。
openVPN
软件VPN产品
VPN常见的方式:点对点,点对多点,点对多点:客户端---企业内部的网络
软件端:分为服务器端和客户端软件
环境:华为云机器---公网机器,模拟OPENVPN连接到华为云的内网环境
1.准备软件包,准备/openvpn目录
记得要修改vars.example--->vars,不然无法识别vars文件
openvpn机器需要关闭防火墙等:systemctl disable --now firewalld
1.安装openvpn和证书颁发软件easy-rsa--->EPEL源
yum list | grep openven
openvpn.x86_64
yum -y install openvpn
yum list | grep easy-rsa
yum -y install easy-rsa
2.查看对应的路径
ls /usr/share/easy-rsa/3
easyrsa openssl-easyrsa.cnf x509-types
easyrsa就是一个执行脚本,专门用于生成证书的,需要将它放到自建的目录下
mkdir /openvpn ; cp -r /usr/share/easy-rsa/3/* /openvpn
拷贝模板文件
/usr/share/doc/easy-rsa-3.0.8/vars.example
cp -r /usr/share/doc/easy-rsa-3.0.8/vars.example /openvpn
easy-rsa介绍:./easyrsa
3.修改证书的颁发有效期,申请CA的证书,自建CA机构
修改模板文件
vim /CA /CERT
set_var EASYRSA_CA_EXPIRE 3650 --->CA颁发的证书,默认10年 3650天
set_var EASYRSA_CERT_EXPIRE 825 --->用户颁发的CERT证书,默认825天,可以随时调整,但是不对一般发的证书有效;服务器的证书有效期
set_var EASYRSA_CA_EXPIRE 36500 ##100年
set_var EASYRSA_CERT_EXPIRE 3650 ##10年
2.准备初始文件,搭建CA证书、服务器证书
执行指令,生成新的pki文件
1.初始化
./easyrsa init-pki
init-pki complete; you may now create a CA or requests.
Your newly created PKI dir is: /openvpn/pki
2.生成CA的私钥以及自己的证书,##nopass表示没有密码,生产中建议配置密码,以后从自己的CA颁发证书给到用户的时候,需要知道类似管理员密码才能进行颁发
./easyrsa build-ca nopass
Common Name (eg: your user, host, or server name) [Easy-RSA CA]:
CA creation complete and you may now import and sign cert requests.
Your new CA certificate file for publishing is at:
/openvpn/pki/ca.crt
--->颁发给CA的证书
##已经有了ca.crt和ca.key,证书和私钥
tree /openvpn
3.服务器端创见证书申请,使用.crt来申请,申请一般是.pem证书申请
./easyrsa gen-req server nopass
多了服务器的私钥
private
│ │ ├── ca.key
│ │ └── server.key
4.创建服务端证书,可以拿到windows端看一下时间,标注是生成服务端的证书
./easyrsa sign server server
issued
│ │ └── server.crt
yum provides sz
lrzsz-0.12.20-36.el7.x86_64 : The lrz and lsz modem communications programs
Repo : @base
Matched from:
Filename : /usr/bin/sz
yum -y install lrzsz
sz pki/issued/server.crt
5.生成DH秘钥交换文件
./easyrsa gen-dh
ll pki/dh.pem
-rw------- 1 root root 424 Sep 25 09:24 pki/dh.pem
DH parameters of size 2048 created at /openvpn/pki/dh.pem
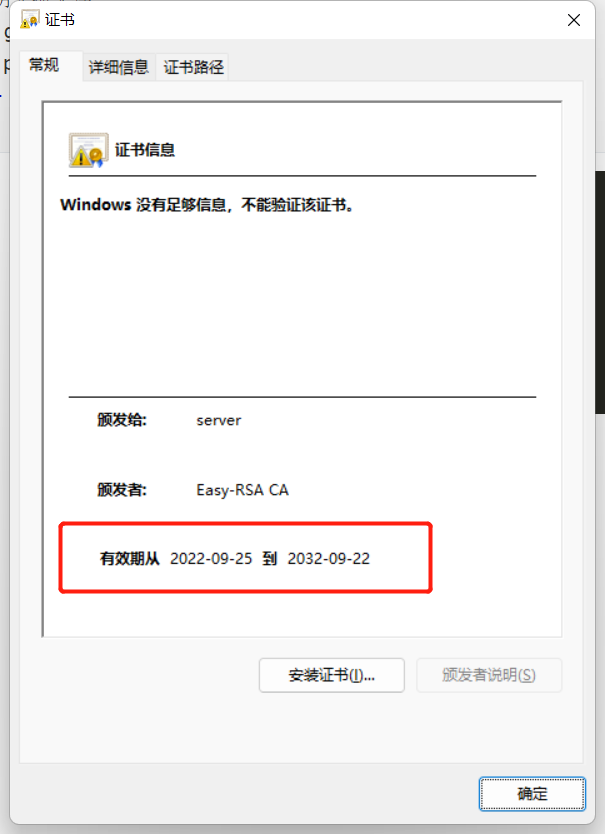
时间和上面的vars时间吻合,颁发给服务端的证书有效期是10年,同理,颁发给客户端的也是10年
3.颁发客户端的证书
[root@ecs-b679 openvpn]# ./easyrsa gen-req catyer nopass
##包含请求文件和私钥,都是基于私钥和请求来生成证书的.crt
req: /openvpn/pki/reqs/catyer.req
key: /openvpn/pki/private/catyer.key
│?? ├── reqs
│?? │?? ├── catyer.req
│?? │?? └── server.req
由于客户端和服务端在CA机构下都属于客户端,所以需要修改一下CERT文件配置,修改有效期
[root@ecs-b679 openvpn]# ls
3 easyrsa openssl-easyrsa.cnf pki vars x509-types
#set_var EASYRSA_CERT_EXPIRE 3650 ##服务端10年 --->server端已经颁发过了,所以这里的修改不会对已有的证书生效
set_var EASYRSA_CERT_EXPIRE 730 ##客户端2年
##基于这个req请求文件来申请的
reqs
│ │ ├── catyer.req
[root@ecs-b679 openvpn]# ./easyrsa sign client catyer
yes
Write out database with 1 new entries
Data Base Updated
Certificate created at: /openvpn/pki/issued/catyer.crt
tree
issued
│ │ ├── catyer.crt
--->两年的有效期
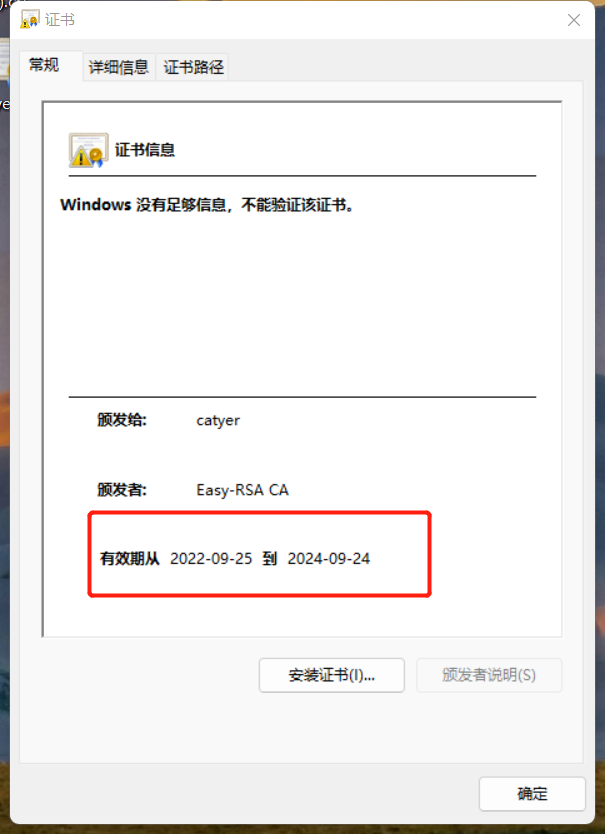
4.整理CA证书和客户端证书
CA和服务端放一起,属于服务端的东西
##检查openvpn的安装情况
rpm -ql openvpn | grep certs
##需要将几个文件先放到/server目录下
/etc/openvpn
/etc/openvpn/client
/etc/openvpn/server
mkdir -p /etc/openvpn/certs/
cp pki/ca.crt pki/dh.pem pki/issued/server.crt pki/private/server.key /etc/openvpn/certs/
ll /etc/openvpn/certs/
total 20
-rw------- 1 root root 1176 Sep 25 10:50 ca.crt
-rw------- 1 root root 424 Sep 25 10:50 dh.pem
-rw------- 1 root root 4547 Sep 25 10:50 server.crt
-rw------- 1 root root 1704 Sep 25 10:50 server.key
客户端创建目录,拷贝CA证书,客户端的私钥和证书
mkdir -p /etc/openvpn/client/catyer
cp pki/ca.crt pki/issued/catyer.crt pki/private/catyer.key /etc/openvpn/client/catyer
ll /etc/openvpn/client/catyer
total 16
-rw------- 1 root root 1176 Sep 25 10:55 ca.crt
-rw------- 1 root root 4432 Sep 25 10:55 catyer.crt
-rw------- 1 root root 1704 Sep 25 10:55 catyer.key
5.配置openvpn服务端
复制服务端的模板文件,路径
cd /usr/share/doc/openvpn-2.4.12/sample/sample-config-files/server.conf /etc/openvpn/
[root@ecs-b679 openvpn]# ls
certs client server server.conf
mkdir -p /var/log/openvpn
chown -R openvpn.openvpn /var/log/openvpn
vim server.conf
port 1194 ##端口
proto tcp
dev tun
ca /etc/openvpn/certs/ca.crt ##默认的CA证书
cert /etc/openvpn/certs/server.crt ##默认的服务端证书
key /etc/openvpn/certs/server.key # This file should be kept secret ,服务端私钥
dh /etc/openvpn/certs/dh.pem ##DH秘钥交换文件
server 10.8.0.0 255.255.255.0 ##连上VPN后,给客户端分配的地址
push "route 192.168.0.0 255.255.255.0" ##路由修改为云上机器的子网网段
keepalive 10 120 ##心跳
cipher AES-256-CBC
compress lz4-v2
push "compress lz4-v2"
max-clients 2048
user openvpn ##安装VPN服务的时候默认创建的用户
group openvpn
status /var/log/openvpn/openvpn-status.log ##创建日志路径
log-append /var/log/openvpn/openvpn.log
verb 3
mute 20
##这一堆暂时注释掉
#duplicate-cn
#client-to-client
#crl-verify /etc/openvpn/certs/crl.pem
#script-security 3
#auth-user-pass-verify /etc/openvpn/checkpsw.sh via-env
#username-as-common-name
systemctl enable --now openvpn@server
ss -ntl | grep 1194
ss -ntl | grep 1194
LISTEN 0 32 *:1194 *:*
配置客户端链接文件
vim /etc/openvpn/client/catyer
vim client.ovpn
client
dev tun
proto tcp
remote openvpn.cwjcloudtest.cn 1194 ##公网IP地址+端口,华为云上的公网域名解析
resolv-retry infinite
nobind
#persist-key
#persist-tun
ca ca.crt
cert catyer.crt
key catyer.key
remote-cert-tls server
#tls-auth ta.key 1
cipher AES-256-CBC
verb 3
compress lz4-v2
6.安装openvpn GUI软件
##将catyer这个目录打包放到config目录下
[root@ecs-b679 catyer]# tar czf catyer.tar.gz .
[root@ecs-b679 catyer]# ls
ca.crt catyer.crt catyer.key catyer.tar.gz client.ovpn
[root@ecs-b679 catyer]# sz catyer.tar.gz
放到windows的/openvpn/config下面
尝试连接,一直是连接中
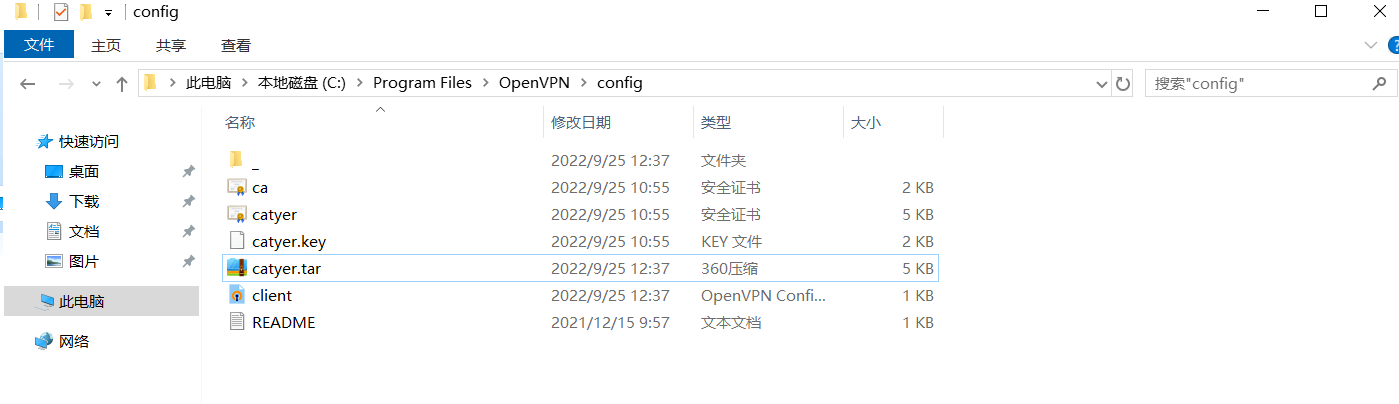
7.测试联通到云上的web服务器
建立成功
##线下机器ping,ssh
云上机器抓包看看:tcpdump -i eth0 -nn icmp
云上机器需要加路由指向192.168.0.68
route -n看下网关
ip route add 192.168.0.68/24 via 192.168.0.253 dev eth0
##删除路由
ip route del xxx
##使用iptables规则来放通,SNAT转换,使线下机器能够访问到192.168.0.63网段,认为是openvpn服务访问到内网的机器,可以的
##所有源为10.8.0.0的请求(因为添加了openvpn server端服务,openvpn机器自动起了一个网卡,IP为inet 10.8.0.1 peer 10.8.0.2/32 scope global tun0),所以SNAT源为10.8.0.0,包括线下所有客户端+这个网卡,目的为除了10.8.0.0,,转换成192.168.0.63,这个eth0网卡的IP地址
iptables -t nat -I POSTROUTING -s 10.8.0.0/24 ! -d 10.8.0.0/24 -j SNAT --to-source 192.168.0.63
DNAT写法:貌似还不需要
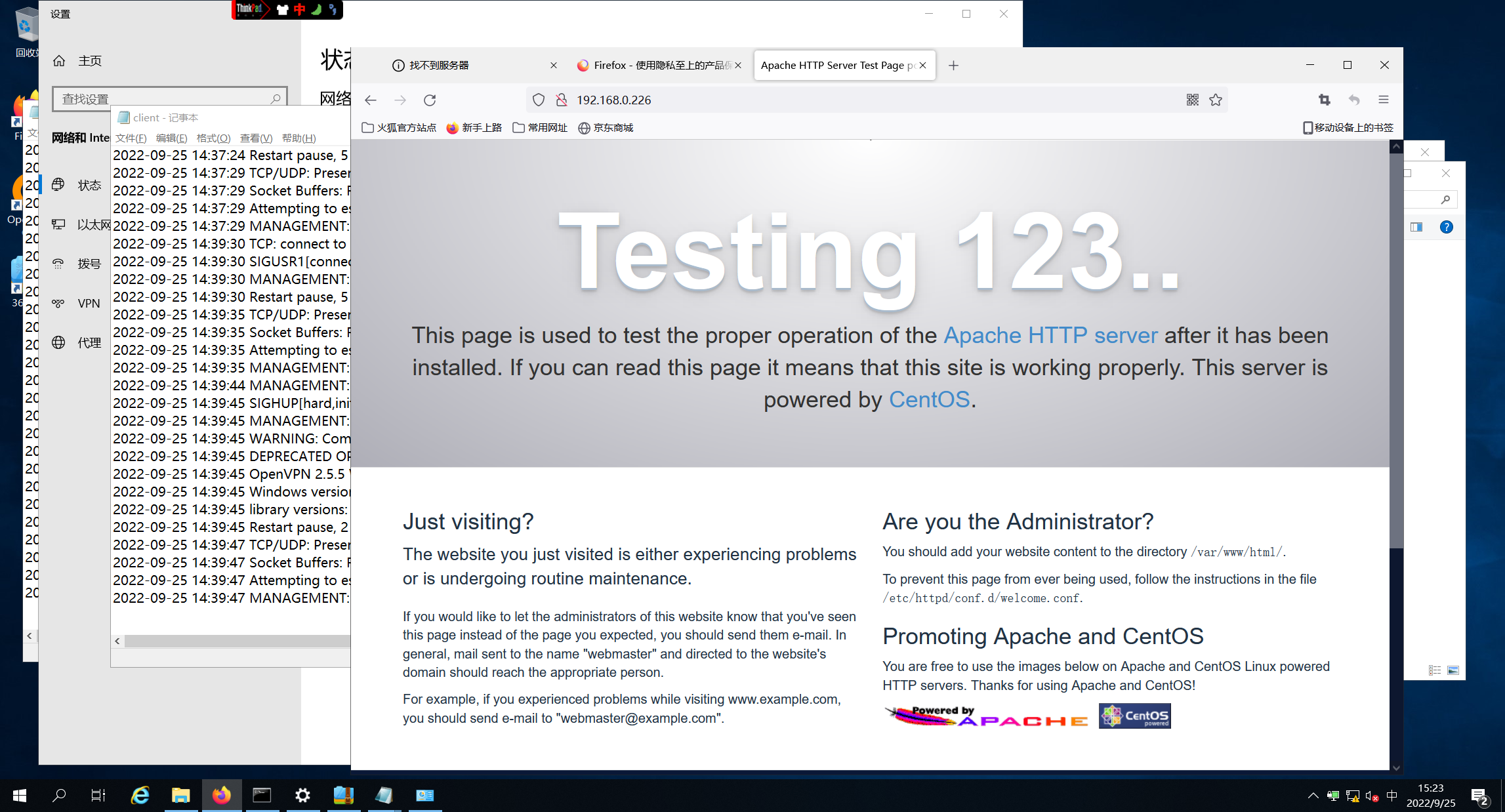
##可以搭建nginx站点访问测试
192.168.0.100:80

 浙公网安备 33010602011771号
浙公网安备 33010602011771号