
week4
week4
完成作业:
1.自定义写出10个定时任务的示例:
比如每周三凌晨三点执行data命令
要求尽量的覆盖各种场景
2.图文并茂说明Linux进程和内存概念
3.图文并茂说明Linux启动流程
4.自定义一个systemd服务定时去其他服务器上检查/tmp/下文件的个数,如果发现数量有变化就记录变化情况到文件中。
5.写Linux内核编译安装博客
6.总结5个自我觉得比较有用的awk的使用场景,比如在什么情况下用awk处理文本效率最高,发散题,至少写1个。
1.定时任务
##启用定时任务服务
systemctl status crond
systemctl enable --now crond
##crontab -e
* * * * 7 /bin/bash /script/mysqlbk.sh ##每周日执行MySQL的hellodb全备,并且记录日志
* * * * 1 /bin/bash /script/mysqlbk/mysqltar.sh ##每周1定时打包1周mysql.sql文件到指定备份目录
30 23 * * * ##每天23点30分备份当天的nginx的access.log目录
30 23 * * * /usr/sbin shutdown -h now ##每天23点30分定时关机测试机
30 1 * * 1-5 /bin/bash /script/nginxbk.sh ##工作日周一到周五1点30备份nginx日志到指定目录
* */2 * * * /bin/bash /srcipt/memrecord.sh ##每隔2小时输出/proc/meminfo Mem内存信息到指定文件
/20 * * * * /bin/bash /srcipt/disk_check.sh ##每隔20min检查所有/dev/分区的磁盘,如果超过了80,则报警发送邮件到指定邮箱
* * * * * sleep 30; /scripts/script.sh ##每隔30s执行一次命令,先sleep 30s先
@reboot /scripts/script.sh ##系统重启后自动执行该脚本
date使用
1、获取今天日期
$ date -d now +%Y-%m-%d 或者
$ date +%F
2、获取明天日期
$ date -d next-day +%Y-%m-%d
$ date -d tomorrow +%Y-%m-%d
3、获取昨天日期
$ date -d yesterday +%Y-%m-%d 或者
$ date -d last-day +%Y-%m-%d 或者
$ date -d "1 days ago" +%Y-%m-%d
##"n days ago" 表示n天前的那一天
4、获取取30天前的日期
$ date -d "30 days ago" +%Y-%m-%d
对应shell脚本
##mysqlbk.sh,数据库备份脚本
#备份mysql库
##每次需要用户手动输入用户名+密码
user=$1
passwd=$2
dbname="hellodb"
date=$(date +%Y-%m-%d_%H-%M-%S)
path=/backup/mysql
if [ -d /backup/mysql ];then
echo "dir created"
else
mkdir -p /backup/mysql
fi
mysqldump -u${user} -p${passwd} ${dbname} > $path/"$dbname".${date}.sql
#cd $path
#tar -czf log-${dbname}-$date.tar.gz "$dbname"-${date}.sql
echo "${date}-${dbname}.sql backup successfully" >> $path/backup.log
##定时备份脚本:nginxbk.sh
date=`date -d yesterday +%Y-%m-%d' '%H-%M-%S`
echo $date
if [ -d /test/backup ];then
echo "dir exist"
else
mkdir -p /test/backup
fi
tar -czf nginx-${date}.tar.gz /var/log/nginx/access.log
mv nginx-${date}.tar.gz /backup/
##输出内存信息到这里:memrecord.sh
#!/bin/bash
date=`date -d now +%Y-%m-%d' '%H`
echo $date >> /test/week4/meminfo.txt
echo `cat /proc/meminfo | grep "^Mem"` >> /test/week4/meminfo.txt
##磁盘检查disk_check.sh
##date:date实现
date=`date +%Y-%m-%d' '%H-%M-%S`
#disk_id=`df -h | grep '^/dev/' | awk '{print $1}'`
disk=`df -h | grep '^/dev/' | awk '{print $5}' | tr -d %`
if [ $disk -ge 80 ];then
echo "时间:${date},磁盘${disk_id}使用率超过80,告警" | mail -s "disk safe"root@qq.com
else
echo "时间:${date},磁盘${disk_id}使用率未超过80,安全" | mail -s "warning" root@qq.com
fi
2.图文并茂说明Linux进程和内存概念
Linux进程
其实是Linux系统运行时的一份副本,一个进程(process)其实就是Linux系统内的一个目录,目录位于/proc下
每个进程都有一个ID号,称为PID,每个PID都有一个目录
每个服务程序在运行的时候,都会产生一个进程,进程会加载到内存里,作为程序运行的临时空间;如果从内存中杀死进程,则这个程序的运行就终止了

一个进程会单独占用一块内存空间(估计不大)
进程内又会有线程,表示这个进程在系统内的多个线程(员工),用于生产
一个进程里,至少有一个线程,线程就是工作的实体
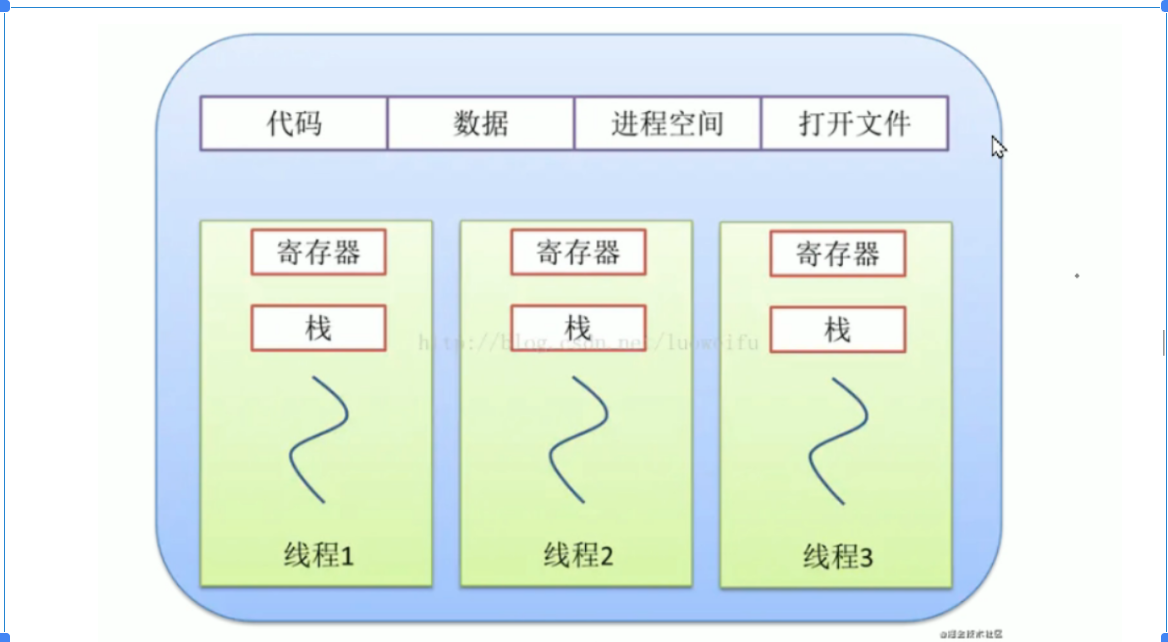
常见进程管理命令:
pstree -p ##列出所有父进程以及子进程,看是否是多线程工作
ps -A ##列出所有的进程
ps -aux ##显示所有包含其他使用者的进程,显示较详细的资讯,比ps -ef要多一些
ps -ef ##所有用户+所有进程的列表
ps aux | grep mysqld
ps aux | grep docker
线程是程序执行的最小单位,一个进程由多个线程组成
pstree -p查看mysqld服务的线程:5639的Pid为整个mysqld服务的父进程,下面都是线程
mysqld(5639)上一级是systemd,证明systemd是所有服务、程序的父进程,系统启动的时候第一个启动systemd进程

进程使用内存问题
内存泄漏,内存超限(溢出),内存不足(OOM)
内存使用空间分为:用户态和内核态,用户空间+内核空间
一部分空间给到内核使用(例如4G的内存,1/4给到内核使用),一部分给到用户的应用程序使用

内存泄漏:malloc分配了一定空间的内容,比如10M,但是没去占用,又不释放
内存溢出:分配了10M的空间,但是你的进程占用超过了10M,则会占用其他人的内容空间
内存不足:OOM,out of memory
java程序:占用程序内存过多
磁盘内的文件需要被访问:一定要加载到内存中才能被访问
比如说我这个执行命令/usr/sbin/php-fpm,当我执行的时候,就在进程内看到了

父进程654,就是所有php以及其子进程都是依赖systemd(1)-php-fpm(654)

相当于这个就是存在磁盘内的文件,现在被加载到内容中运行了,PID为654

Linux内存
内存是服务器内的重要的一个硬件指标,一般来说,一个程序或者服务在运行的时候,会生成一个或者多个进程,而进程就是运行在内存中的。
内存的特点是读写速度快,缺点是不会持久化保存,也是和磁盘等持久化存储的一个很大的差别
还有内存的购买费用较高,企业内部一些运行的服务(丽日数据库)非常消耗内存,所以在上新系统系统/观察老系统运行情况时,内存都是一个非常重要的指标
查看内存的读写情况:vmstat,包括物理内存的使用量,swap交换分区的使用量,buffers(写缓存)和cache(读缓存)的使用量;写和读缓存主要是加速磁盘内容的读写
磁盘内的文件需要读的时候,一定要加载到内存内进行读写的操作
[root@master week4]#vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 2094996 2256 597756 0 0 92 15 102 164 0 0 98 2 0
[root@master week4]#free -h
total used free shared buff/cache available
Mem: 3.7G 1.1G 2.0G 12M 585M 2.3G
Swap: 0B 0B 0B
3.图文并茂说明Linux启动流程
Cent OS 6启动流程
1.POST加电自检,加载BIOS信息,获取第一个启动设备,post加电自检
2.读取一个启动设备的MBR分区信息
grub1:加载MBR分区前446个字节
grub1.5:扇区,找到MBR分区的文件系统,因为grub2的/boot/grub2这个目录是在文件系统上的,所以要找到加载文件系统,文件系统加载驱动
grub2:进入到/boot/grub2里面,找到grub.cfg,从grub.cfg的配置信息内,而找到内核文件(根据配置文件)
3.加载内核文件,加载根分区,系统初始化
4.运行init进程,确认init级别,可以随时切换init进程的运行级别(/sbin/init读取)---/etc/inittab,确定是init 3模式的启动方式,init执行对应级别的脚本,init执行/etc/rc.d/rc.local自启动文件/脚本,不同的init级别存放的脚本不同
5.启动各自的脚本
6.建立访问终端tty,比如root登录就是tty0
7.用户登录

BootLoader:操作系统引导的,引导启动到哪个OS
BootLoader分类:分为windows和Linux的BootLoader
Cent OS 7
1.POST自检,选择启动的设备
2.引导系统启动BootLoader--->grub2,Cent OS 7后使用grub2版本
grub 1:前446字节
grub 1.5:找到扇区,加载文件系统驱动,能读取文件系统上的文件grub.cfg
grub 2:进入到/boot/grub2内找到grub.cfg,从而找到内核文件,启动
3.加载驱动,加载内核
4.内核初始化,使用systemd代替之前的init,systemd的pid为1
5.执行.target的所有单元unit,加载单元unit
6.执行默认target级别,默认是multi-user级别(level3)
7.启动multi-user下的所有服务,执行/etc/rc.local(需要+x执行权限)
8.登录到终端
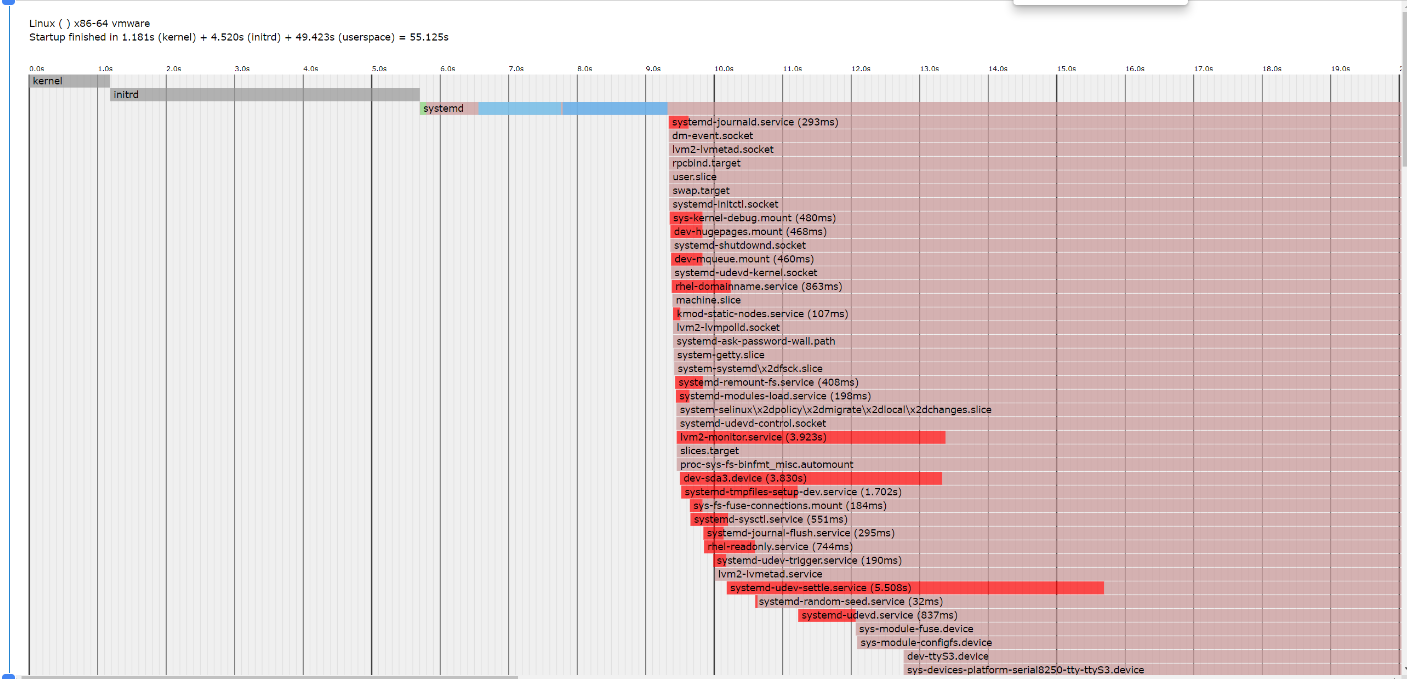
##生成系统启动的文件boot.html
systemd-analyze plot > boot.html
systemd特点:并行启动服务,不需要启动依赖再启动,启动花了25s
4.自定义systemd服务,检查/tmp文件个数
自定义一个systemd服务定时去其他服务器上检查/tmp/下文件的个数,如果发现数量有变化就记录变化情况到文件中。
systemd服务基本格式
[Unit]
Description=hello test
[Service]
TimeoutStartSec=0
ExecStart=/bin/sh /script/dir_check.sh
#ExecStop=/bin/kill sh
KillSignal=SIGQUIT
TimeoutStopSec=5
KillMode=process
PrivateTmp=true
[Install]
WantedBy=multi-user.target
##采用同一个目录下间隔时间作为比较,比较文件的数量
path1=/tmp
diff1=`ls -l $path1 | grep "^-" | wc -l`
sleep 30
path2=/tmp
diff2=`ls -l $path2 | grep "^-" | wc -l`
echo "1:$diff1,2:$diff2"
diff3=`echo $diff1-$diff2 | bc`
date=`date +%H-%M-%S`
##取绝对值
num=`expr 0 - $diff3`
if [ $diff2 -lt $diff1 ];then
echo "路径${path1}减少了文件,数量为$num,时间:$date" >> /tmp/record.log
elif [ $diff2 -gt $diff1 ];then
echo "路径${path1}增加了文件,数量为$num,时间:$date" >> /tmp/record.log
else
echo "无变化,时间:$date"
fi
find week4 -printf "%P\n" | sort > file1
find week3 -printf "%P\n" | sort | diff file1 >diff.txt
5.写Linux内核编译安装博客
Linux机器在某个发行版上编译安装指定的版本用途:为了适配不同应用的需求,需要应对使用更高的内核版本需要执行操作
1.下载内核文件(stable版本),自选内核版本,目前使用centos 7.9的内核版本:uname -r
3.10.0-1160.15.2.el7.x86_64
2.安装编译内核文件必要的依赖库
3.配置内核编译参数
4.编译内核
5.安装内核
6.修改默认启动的内核,centos7:/boot/grub2/grub.cfg
7.重启机器,验证版本变更:uname -r
6.总结5个自我觉得比较有用的awk的使用场景(持续更新)
比如在什么情况下用awk处理文本效率最高,发散题,至少写1个。
awk常见格式:NR表示行,NF表示最后一列,$NF代表最后一列,$(NF-1)代表倒数第二列
awk处理文本能力很强,常用的场景
1.有指定分隔符的场景,可以使用awk直接分割,awk -F'=',直接输出域; awk分隔符还可以分隔空格之类的,awk '[ .]'
2.没有指定分隔符的场景,默认一些场景是空格,awk直接默认压缩了,不需要使用tr在进行一次压缩
3.awk支持正则表达式筛选,可以直接套用输出,awk '/netmask/{print $1}'
##常见案例
1.awk处理nginx服务日志,列出访问最多的5个IP源IP地址,查看访问量
awk '{print $1}' /var/log/nginx/access.log | sort | uniq -c | sort -nr | hrad -n 5
nginx日志取访问的IP地址+访问时间:cat /var/log/nginx/access.log | awk -F "[[ ]" '{print $1,$5}' | head -n 5
2.awk利用数组统计所有TCP连接的状态,并且排序(包括LISTEN,ESTABLISHED等)
netstat -ant | awk '{state[$NF]++} END {for (i in state) print i,state[i]}'
3.awk处理系统用户和登录bash
awk -F':' '/\/bin\/bash/{print $1 "," $7}' /etc/passwd
4.docker删除在运行的容器,或者是跑容器
docker rm -f `docker ps | grep nginx | awk '{print $1}'`
docker run --name matomo --link mysql:mysql -p 8003:80 -v /test/matomo:/var/www/html -d `docker images | grep matomo | awk '{print $3}'`
5.查看目录下所有.sh文件的大小,其他类型的文件类似
ls -al *.jpg | awk '{sum+=$5} END {print sum}'
6.取IP地址
ifconfig eth0 | awk '/netmask/{print $2}'
7.取磁盘固定分区的使用率
df -h | grep "^/dev" | awk '{print $5}' | tr -d %
df -h | awk '/\/dev\//{print $5}' | tr -d %
8.awk正则表达式:去除掉空行(^$)或者是注释的行(^#),非空行或者是注释行
awk '!/^#|^$/' /etc/fstab
只取注释行
awk '/^#/' /etc/fstab
9.awk实现while循环,bash命令行完成
awk 'BEGIN{i=1;sum=0;while(i<=100){sum+=i;i++};{print sum}}' --->5050

 浙公网安备 33010602011771号
浙公网安备 33010602011771号