
daily
daily study
为什么要在服务名称后面+d
chronyd服务:一般的服务为什么后面要加d---其实就是daemon守护进程的意思,类似Cent OS 7后面改版使用systemd作为启动的第一个进城,然后其余的service服务逐次启动(并行启动)
加d的服务:sshd,httpd,chronyd,mysqld等等
不加d的服务:nginx,Apache(httpd),redis,tomcat等
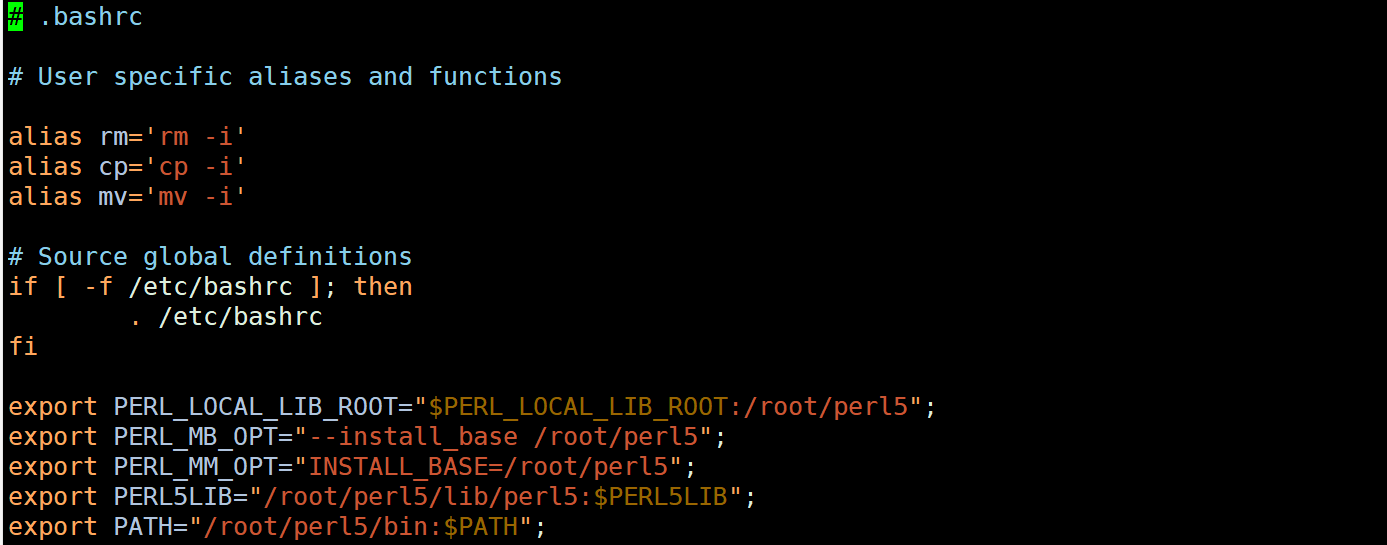
系统别名alias配置文件:.bashrc
vim .bashrc可配置系统内的命令别名,属于系统配置文件中的一个
配置一下iptables -nl的alias别名
alias iptables -nl='iptables -nl --line-numbers'
alias ipnum='iptables -nL --line-numbers'
source .bashrc
使用这个别名alias
SLB负载均衡
阿里云SLB特点:无论前端做什么监听,后端都只会转发到80端口(业务端口)
前端监听:可以是http/https,用户访问过来是加密的;后续转发请求到后端服务器,就是80端口了,这个和tcp转发是类似的,只不过变成了web应用的转发
可以拿华为云试一下,或者直接搭建nginx的upstream来实现这个负载均衡效果,nginx也可以写转发,匹配到443或者是80的访问就转发到80的端口(server)
SLB健康检查:可以用url的根目录(web站点)的根目录进行检查
SLB的负载算法:加权轮询算法,平均算法,IP HASH算法
IP HASH算法:指的是每一个IP有唯一的HASH值,通过HASH值来指定哪个后端服务器提供服务
加权轮询算法:每个后端服务器加上权重,权重一般为100(生效),就访问权重为100的机器轮询;权重为0则不生效
用户访问域名:
1.会先找本地host解析,不走公网解析;windows和Linux都有hosts文件(system32/drivers/etc/hosts),/etc/hosts
2.找本地的DNS服务器,Linux上面的/etc/resolv.conf
3.根DNS服务器,返回到本地
4.缓存DNS记录
k8s运维开发/devops运维开发
要学好go语言,go语言是k8s架构的基础,基于go语言,可以写一些定制化的工具脚本帮助企业更好的去管理维护k8s,甚至是监控k8s资源
先去了解基础的k8s组件是如何去使用的,所谓的flannel等组件都是基于go语言写的
可以从shell python开始学起
基于开发的运维才是水平高的运维,当然监控,资源调度,也不能丢,传统艺能+K8s/docker+1/2种开发语言
CTFmall整体IT架构
一般的大型企业访问架构访问方式:
1.WAF(业务),在WAF上接入防护域名,添加好源站IP地址,配置好协议;如果是阿里云,则添加CNAME(WAF)上;如果是腾讯云,则是添加A记录
在DNS上需要添加CNAME的解析(阿里云)和A记录的解析(腾讯云)
2.SLB(负载均衡),一般来说,WAF的源站IP(回源IP)为SLB的公网IP,因为访问到WAF后会回源到SLB,SLB添加好后端节点,也可以添加为多个代理节点
3.nginx反向代理节点,反向代理多个业务模块,可以代理pod的IP,代理ECS的业务机器IP等
4.实际的业务节点(端口),SLB后端的TCP业务端口,SLB前端的http/https的访问(绑定前端的话是使用公网的IP资源)
SLB前端需要绑定访问的域名(腾讯云),腾讯云是分的
SLB(阿里云):直接添加业务端口就行了,不分的前端http/https和后端tcp/udp

CPU负载和使用率的区别
CPU负载指的是在运行的进程,有多少占用CPU负载的,如果运行的进程多,但是每个进程占用CPU的资源都不多,会造成CPU负载高,CPU使用率中等的情况
如果是单个进程占用CPU使用率高,则会造成CPU负载低,CPU使用率高
终究还是看运行进程的数量,以及运行进程占用具体CPU的使用率
查看cpu的平均负载:uptime

很多时候负载到1,也不是问题,因为有更多内核使用,具体还是看CPU的内核数
cat /proc/cpuinfo | grep core查看核心,单核

vmstat:显示系统CPU占用率的情况
vmstat 3 4:每隔3s显示一次使用率(负载率),一共显示4次
us:运行非内核代码的时间
sy:运行内核代码的时间
id:空闲时间(空闲率),如果id的值小,则CPU非常繁忙,需要注意一下调整,这个vmstat可以作为一个标准输出到指定的文档

标准输出到文档内,可以配置成定时任务执行

可以使用脚本来计算CPU的使用率
echo "CPU Usage: "$[100-$(vmstat 1 2|tail -1|awk '{print $15}')]"%"

top -bn1(显示一次) | grep Cpu
-b:非用户交互模式,-n:显示的次数

设置邮件服务器
进入到/etc/mail.rc,记得获取邮件授权吗

发送邮件
echo "disk alarm" | mail -s alarm 1119412685@qq.com
Ubuntu系统操作
Ubuntu是作为一个Debian系列的操作系统,广泛应用于互联网环境
修改主机名:hostnamectl set-hostname master
Ubuntu软件管理
Ubuntu特点:安装一个web服务器后会自动拉起这个服务,如果端口被占用则会提示端口占用,服务无法启动
apt-get:16版本以前的安装,现在已经不用了
apt:现版本常用
ubuntu属于Debian类的操作系统,所以这些操作都是Debian类的
dpkg:类似Cent OS的rpm,单个包,但是不支持依赖包
apt install:类似yum安装,常用
ubuntu自带apt源的包很少,一般都要到互联网上面去下载
| yum | apt | 作 用 |
|---|---|---|
| yum -y install | apt -y installapt -y install nginx | 安装软件 |
| yum -y remove | apt -y removeapt -y pruge(这个删除的更干净) | 删除程序软件 |
| yum update | apt update | 更新软件(更新软件库,存储库索引),Ubuntu经常更新 |
| yum search | apt search | 搜索对应的软件包 |
| .rpm | .deb(debian系) | 安装包的后缀 |
| yum list | apt list | 查询这个程序软件是否有这个包 |
yum命令使用
yum clean all:清除yum的缓存
yum makecache:一般来说不执行这个,在安装软件的时候会自动安装上
yum repolist:列出yum源仓库
yum provides xxx(文件名):查询这个文件来自哪个包
yum history:yum安装的历史
yum list:查看yum源内有无这个软件包
os版本查看:
红帽系:cat /etc/redhat-release或者cat /etc/os-release
Debian系:cat /etc/os-release
Ubuntu的apt源:在/etc/apt/source.list文件内,云厂商的ubuntu主机已经配置好了云厂商的apt源了,可以直接使用
【查看source.list文件内得apt源写法,忽略掉#开头注释和空行】
grep -Ev '^#|^$' /etc/apt/source.list
grep -v '^#\|^$' /etc.apt/source.list
sed '/^#\|^$/d' /etc/apt/sources.list:加转义

Cent OS系统修改优化配置
1.先给/etc/rc.local赋予执行权限
chmod +x rc.local
进入到rc.local文件,把可执行文件的路径写进入,比如nginx,tomcat等
/usr/local/nginx/sbin/nginx
/usr/local/tomcat/bin/startup.sh
系统在启动的时候会优先查找rc.local下面的自启动程序
2.使用systemd服务
systemd服务不仅仅是可以执行自启动,还可以纳管后台服务的开始(start)、结束(stop)、状态查询(status)、重新装载(reload)等
所有的服务在目录下都是nginx.service结尾的,目录为/etc/systemd/system
3.使用crontab
@reboot /shell/linux.sh,重启自动运行
4.VMware本地化安装Cent OS关闭图形化界面启动
systemctl set-default multi-user.target
init 3:以命令行界面运行,节省内存
Linux系统启动流程
Cent OS 6启动流程
1.POST加电自检,加载BIOS信息,获取第一个启动设备,post加电自检
2.读取一个启动设备的MBR分区信息
grub1:加载MBR分区前446个字节
grub1.5:扇区,找到MBR分区的文件系统,因为grub2的/boot/grub2这个目录是在文件系统上的,所以要找到加载文件系统,文件系统加载驱动
grub2:进入到/boot/grub2里面,找到grub.cfg,从grub.cfg的配置信息内,而找到内核文件(根据配置文件)
3.加载内核文件,加载根分区,系统初始化
4.运行init进程,确认init级别,可以随时切换init进程的运行级别(/sbin/init读取)---/etc/inittab,确定是init 3模式的启动方式,init执行对应级别的脚本,init执行/etc/rc.d/rc.local自启动文件/脚本,不同的init级别存放的脚本不同
5.启动各自的脚本
6.建立访问终端tty,比如root登录就是tty0
7.用户登录
BootLoader:操作系统引导的,引导启动到哪个OS
BootLoader分类:分为windows和Linux的BootLoader
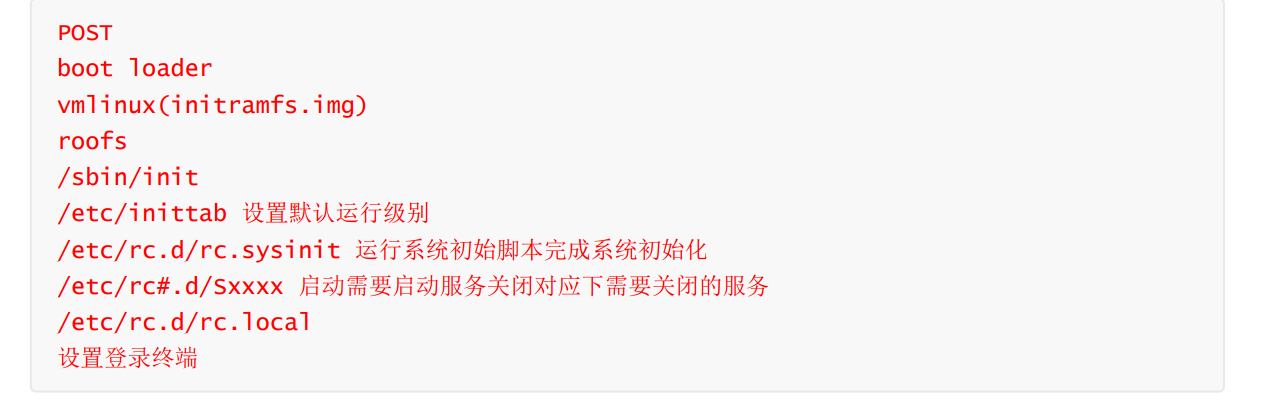
Cent OS 7启动流程
第一个启动的进程:从init变成systemd进程,init的link文件指向systemd,所以原来的init启动就指向了systemd进程(PID号:1)

systemd启动机制:并行启动服务
sshd---network有依赖关系,本来的机制应该是network起来后,sshd才能启动(centos 6)
现在启动sshd可以直接启动network服务
可以实现:启动端口而不启动服务,即socket(端口)和service(服务)的分离
systemd可以做到:在某个端口启动后,唤醒对应的服务
nfs-util服务和rpmbind服务:rpmbind服务依赖于nfs-util服务,启动nfs服务会自动将rpmbind拉起
socket套接字:IP地址+端口号,中间这些就是一个个socket(套接字)

ss -ntlp:显示监听的进程
Linux的BootLoader:grub2
主要是grub,Cent OS 7以后是grub2,可以在/boot下面看到

grub启动流程
- 1ststage:加载MBR分区前446个字节,grub需要加载文件系统
- 1.5 stage:找到MBR分区后面的扇区,需要找到文件系统,能识别MBR分区上面的文件系统
- 2 stage:进入到/boot/grub2
grub.cfg:grub配置文件,写了如何去找内核文件
选中这个菜单,证明选中了内核文件(CORE)

查看Linux的内核文件:/boot/vmlinuz-3.10,在boot目录下
大小大概为10M以下:vmlinuz
现在的内核版本号:3.10

系统每个init模式对应每个不同的目录,比如说是init3模式启动的,则会加载3模式下的目录对应的服务 
查看终端目前谁在登录:who或者是w
who am i 
系统自启动服务配置文件:/etc/rc.d/rc.local
可以自定义配置脚本,可执行文件等,开机自动加载java环境等,自动启动tomcat服务等,nginx服务,自动执行这个脚本

Cent OS 6和Cent OS 7的启动区别
Cent OS 6:根据init的启动级别来启动对应的服务,且服务有依赖关系,不能并行
Cent OS 7:systemd包揽所有,服务可以并行启动不受影响,所有服务都是基于systemd来启动的
Linux系统问题
Ubuntu允许root用户登录到系统:修改/etc/ssh/sshd_config的permitlogin,修改为yes,重启SSH服务
Ubuntu系统默认不允许root进行远程登录,和Cent OS不太一样
看自己在远程登陆的时候,在哪个终端:tty,who查看登录到系统上的用户
确定自己的身份:who am i
查看系统有谁在SSH连接:who,会显示对应的tty
登录到服务器,ifconfig看不到网卡IP怎么办?
进入到/etc/sysconfig/network-scripts/ifcfg-ens33,把网卡的onboot改为yes
查看系统时间:date
查看系统时区:timedatectl,中国应该是东八区,可以通过配置ntpserver服务器来校准时间,这样也行
timedatectl set-timezone Asia/Shanghai

可以用阿里云的ntp服务器或者用华为云的ntp服务器
ntpdate ntp.aliyun.com
ntpdate ntp.myhuaweicloud.com

Linux关闭图形化界面(本地VMware)
init 3
前后对比可以得知,大概减少300M的内存占用,还是可以的

设置主机名
hostname
hostnamectl set-hostname master
重新远程连接生效
临时设置为什么是临时设置?---因为她修改的是内存内的数据,永久的话,需要修改在磁盘内的数据,写入到磁盘内(落盘)
主机名存放位置:/etc/hostname---Cent OS 7
/etc/sysconfig/network---Cent OS 6的文件
安装软件:
Cent OS:yum
ubuntu:apt -y install xxx
查看命令是否为内部命令/外部命令:type + 命令名称
如果是外部命令,则会在/usr/bin下面有一个固定的命令文件夹;
如果是内部命令,则会直接显示为in命令

区别:内部命令的执行速度远远快于外部命令
大概外部命令:10ms,内部命令:1ms
配置bash的颜色变化
在/etc/profile配置文件内配置PS1的bash环境
vim /etc/profile
source /etc/profile
PS1="[[\e[1;33m]\u[\e[35m]@\h[\e[1;31m] \W[\e[1;32m]][\e[0m]\$"

多个命令放在一行内执行,使用;分号隔开
比如ifconfig ens33,然后再查看系统登录人who

查看命令的用法(帮助)
xxx --help:显示一些基本的用法,参数
man xxx:以整体文本的形式显示出来
k8s的官方支持文档:kubernetes.io
常见系统变量
| 命令 | 说明 |
|---|---|
| $PATH | 环境变量,用于显示Linux系统外部命令的执行路径echo $PATH/usr/local/tomcat/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/java/jdk1.8.0_241/bin:/root/bin |
| $SHELL | 表示现在的shell环境echo $SHELL/bin/bash |
| $HOME | 当前用户的家目录,比如root就是/root,如果是用户的话,比如catyer,家目录就是/home/catyerecho $HOME |
常见bash系统快捷键
| 命令 | 说明 |
|---|---|
| ctrl+a | 光标到行首(bash) |
| ctrl+e | 光标到行尾 |
| ctrl+d | 光标处删除 |
| ctrl+<或者是ctrl+> | 代表在bash下移动到空格的单词处,以空格隔开的单词 |
history修改命令显示格式(相当于修改系统变量)
修改类似history命令的执行格式
先查看一下这个HISTTIMEFORMAT的格式
echo $HISTTIMEFORMAT

直接在bash上修改
HISTTIMEFORMAT=‘%F %T’
完成后history查看一下命令的执行效果

永久修改history的格式,进入到~根目录下,修改.bash_profile命令
vim .bash_profile
添加如下的行:HISTTIMEFORMAT='%F %T'
保存,执行profile文件:source .bash_profile

其实这个功能是类似于date时间记录的功能,把这个功能添加到history上面,以后如果是Linux主机遭到入侵,可以查看历史执行命令的时间点,日期等
%F代表日期: %F full date; same as %Y-%m-%d
%T代表时秒分的时间:%T time; same as %H:%M:%S

在脚本内是这样写的,这个可以当做以后定义变量,而不用去写年月日+时分秒

但是黑客貌似可以删除历史记录
history -c:删除当前系统的历史记录
让程序(进程)在后台运行
安装screen软件,即使断开SSH界面,程序(进程)依然在跑,常用于生产中的备份等等操作,当然备份也可以创建定时任务备份MySQL的库
yum -y install screen

安装完毕后运行这个软件就行:screen
bash下批量化的创建文件
在bash下,需要输出连续的数字,可以:
echo {1..10},代表输出1-10,连续输出
echo {1..10..2},代表输出1-10,但是是每隔2位数输出

后续在写shell脚本的时候,可以结合这个批量化的创建文件、目录等
touch file{1..10}.log,创建file1-10.log的文件
rm -rf file{1..10}.log,删除以上文件

可以用于for循环
for i in {1..10};do
用于探测内网内的IP地址是否存活
ping -c 2 -w 0.2 192.168.$i.0 & > /dev/null
if [ $? -eq 0 ];then
echo "访问成功"等等
mkdir /data/mysql/{1..10}.log,貌似好像不能这样床文件
Linux常见文件管理

根目录:/
bin/sbin:放置用户/管理员的执行程序,比如说我要定时关机,写的定时任务就是:
时间+/sbin/shutdown -h,在sbin下面可以看到这个,是一个链接文件

/boot:系统启动相关,包括计算机内核kernal
/dev:硬盘,比如/dev/sda1,/dev/sdb等,新的硬盘上来也是这样命名
/etc:存放各种配置文件,yum安装的程序都在里面
/home /root:管理员目录,用户目录
/run:存放一些目前系统内正在运行的程序的文件,一旦停止运行(结束进程),run内的文件就会删除
/tmp:临时文件
/var:会经常性变化的文件,典型代表:log,/var/log,包括访问日志,错误日志等
/lib /lib64:库,调用对应的程序功能,一个32位,一个64位
/mnt /media:外部硬盘挂载目录,比如说是/mnt/mount挂载点
文件管理command
一共有7种文件类型
ls -alF:显示目录下的所有文件,并且显示它们的作用(使用文件对应的)
-:一般文件
d:目录
p:管道pipe,类似| grep
s:socket套接字
l:链接文件,ln -s软连接,快捷方式
c:字符文件character
b:块设备

cd -:回到刚刚访问的目录
-atime:access time访问时间
-mtime:modify time修改时间
-ctime:元数据修改时间
stat xxx:显示单个文件的所有状态(atime、mtime、ctime)
列出文件的元数据metadata

查看文件的类型:file xxx
第一个:shell脚本,第二个:sql文件,第三个:gzip的压缩文件

文件在磁盘中的存放(元数据+指针+数据块)
文件:1.sh分为两部分
一个是元数据(文件属性:包括权限、大小、时间),一个是存放在硬盘的位置,寻找文件的时候,先找到文件的元数据--->在找到文件的位置
元数据--->(指针)--->指向这个磁盘的位置,类似索引,会有一个索引表来放置这一些链接
指针会指向一个数据块(block),一个数据块的大小为4K

Linux的文件系统元数据+指针访问(以ext4作为例子)
使用df -Th可以查看系统内硬盘的文件系统

一般来说,一个元数据(文件编号)+指针是12个数据块,1个数据块大小为4K,12个就是48K的数据块=48K
一个指针不够,就加指针
1个指针表内可以放1024个指针,1个表也是4K,1个指针大小为4bit,同样,一个指针指向4K的数据,4K*1024=4MB的数据
再往上加指针表,每次都是1024级别的扩大,4G,40GB等等,都是一个文件所占用的数据块空间

查看文件的编号:ll -i
这个就是在元数据块(表)内的编号,每个挂载点有不同的编号;创建会赋予新的编号,删除会回收对应的编号

df -i:查看磁盘已经使用的inodes编号,以及总的,剩余的inodes编号
可以看到/dev/sda1的各项数据

所以说,文件删除了,可能可以恢复,也可能恢复不了,因为编号会被其他文件所占用
使用du -h可以查看这个文件占用了多少个数据块(这里不是文件的实际大小)

你要查看文件(目录)的实际大小,可以使用du -h+深度,比如du -h --max-depth=1

basename和dirname(可用于编写shell脚本)
basename:取路径下的文件名
dirname:取路径下的目录

也可以取网络路径的文件名(例如http://)
比如说我在gitee上面的.git仓库,可以直接取最后的文件名,比较方便

文件通配符(正则)
| 命令 | 说明 |
|---|---|
| ls *.sh | *:表示任意的字符,比如要查找目录下所有.sh的文件 |
| ls ???.conf | ?:表示单个字符,不指定,比如ls .?.sh,表示列出单个字符文件名的.sh文件 |
| [a-z] [A-Z][^a-c]:列出除了abc | 匹配字母,表示匹配到任意一个字母都输出文件结果,比如ls [a-c]  |
| [1-9][^1-3]:列出除了1-3 | 匹配数字,表示匹配到任意一个字母都输出文件结果,比如ls [1-3].txt,则会显示匹配1,2,3的txt文件   |
硬链接和软连接ln -s
硬链接:给文件取一个别名,实质上是同一个文件
ln filename linkname
软连接:快捷方式,可以对目录创建软连接
一定是前面是原文件名(路径),后面是链接的目录+文件名
ln -s filename linkname
ln -s /usr/local/nginx/sbin/nginx /root/nginx.link

主要的区别:
1.本质
硬链接是同一个文件,软连接不是,软连接是链接文件(link)
2.iNode
硬链接:同一个,软连接:不是,因为都是另一个文件了
3.目录
硬链接不支持目录创建,软连接支持
4.删除
硬链接删除不影响,软连接会删除掉原目录下的数据,也可以不删除
软连接删除的要点
需要删除软连接的时候,是rm -rf link
而不是rm -rf link/,因为link/会删除目录下的所有文件,慎用!
bash下的重定向(输入与输出)
| 命令 | 说明 |
|---|---|
| > 1.txt | 标准输出 |
| 2> 1.txt | 标准错误输出 |
| &> 1.txt 或者 2>&1 | 合并标准输出和标准错误输出 |
| cmd 1 < 1.txt | 标准输入,例如计算: |
| cmd1 | cmd 2 | 管道,将cmd1的输出结果赋予cmd2管道计算:seq -s+ 100 | bcecho 234*5 | bc |
| cat << EOFEOF | 将多行的文本内容重定向到指定的位置,如果是计算的话,则每行计算; |
| cat << EOFEOF | tee 1.txt | 将多行的文本内容重定向到指定的位置,并且在屏幕上和1.txt文件中打印出来 |
| tr(标准输入) | 可用于字符转化输出,比如计算1-100的加结果echo {1..100} | tr ' ' + | bc |
ls > 1.txt:一般重定向(会清空这个文件),将ls命令的结果输出到1.txt这个文件(正确结果输出)
一般代表的是正确的结果,如果是错误的,则执行ls的命令都会报错
ls >> 1.txt:将这个ls命令输出的内容追加到1.txt内

ls 2> 1.txt:错误结果重定向
如果说当前目录下不存在这个文件,那证明ls xxx.txt输出的是错误的结果,无法访问到xxx.txt,那正常的重定向自然也无法把内容输出到xxx.txt上 
错误重定向:ls xxx.txt 2> 1.txt,将这个no such file的结果输出到1.txt内了 
&>:and>,表示无论结果输出如何,都输出到指定文本中(正确+错误结果)
现在我要查询的文件中,A文件存在,B文件不存在,则会出现A正常,B报错 
还有一种类似的写法,这个代表错误结果也输出到1上面,而1已经重定向到1.txt内了,所以2(错误)也输出到1.txt上面
ls xxx.txt 1.sh > 1.txt 2>&1

我要将两个结果都输出,类似之后在shell使用
ls xxx.txt 1.sh &> 1.txt 
或者是将正确/错误的结果追加输出:ls xxx.txt 1.sh &> 1.txt
类似我要测试该网段内的主机存活(192.168.0.0段),/dev/null代表一个黑洞,是无限收缩的,可以吧所有的结果都输出到这个null中
for ((i=128;i<=132;i++))
do
ping -c 2 -i 0.2 192.168.244.$i &> /dev/null
if [ $? -eq 0 ];then
echo "server $i ping success" >> ping.txt
else
echo "server $i ping fail" >> ping.txt
fi
done
标准输入:将文本内的内容给到命令处理
例如我想计算234,利用bash环境进行计算,直接使用管道计算,衔接命令
[root@master ~]#echo 234 > 1.txt
echo 234 | bc
[root@master ~]#seq -s+ 100 | bc
5050
seq 100代表从1-100列出来
使用tr来替换空格:将1-100输出中间的空格替换成+号,并且使用bc计算
echo {1..100} | tr ' ' + | bc
5050
sum=0
for i in `seq 100`
for ((i=1;i<=100;i++))
do
((sum=sum+i))
done
echo $sum
发送邮件:mail -s 邮件标题 发送的用户
cat 1.txt | mail -s test root
mail 查看邮件

rm删除在生产环境的使用
在生产中切记:rm命令不能随便用,最好是移除这个rm命令的使用
移除方法1.设置别名,设置为空
alias rm=' '
这样rm就无法执行了

2.将/bin下面的rm修改为另一个文件名,那就无法执行了
mv /bin/rm /bin/rm_bak
去除别名:unalias rm
Linux安全模型&用户&用户组
3A认证:
authentication:认证
authorization:授权
account:审计
认证成功后会授予一个token,登陆成功
用户ID:uid,可以在/etc/passwd看 / id -u +catyer
root:0
系统用户(服务):1-999,给服务用的账号,比如我创建一个MySQL,会有一个MySQL账号;创建一个nginx,会有一个nginx的账号
用户UID(用户账号):1000+

id + 账号名:查看用户的属性
uid,gid,组,附加组(多组)

用户组:一组相似权限用户的集合,group id
查看组的ID:id -g
windows内:无法创建用户和组同名的
Linux:可以允许同名
其实Linux内的root组,没有什么实际权限
groupadd g1 g2:创建某个组
usermod -G g1 catyer:将catyer账号切换到(添加到)g1组内
用户切换
su catyer:临时环境切换,但是环境还是root,适用于还在这个目录下操作,但是需要换账号
su - catyer:完全切换,用户环境切换到catyer这个用户下

切换完成后,记得使用exit切换回去
换个身份执行命令
su - catyer -c command
su - catyer -c 'touch catyer.txt'

批量式修改密码(标准输入)
密码查看:/etc/shadow
常规用法:只有root用户可以操作这个
echo 123 | passwd --stdin catyer

脚本实现批量化创建用户并且赋予密码
前提准备:
1.用户列表:user.txt(stu01 02 03)
2.密码表(可选):passwd.txt(123 456 789)
逻辑:先创建用户,在通过标准输入赋予密码;用户和密码都可以遍历txt文件
for i in `cat stu.txt`
do
useradd $i
echo "$i用户创建完成"
for j in `cat pass.txt`
do
echo "$j" | passwd --stdin $i
done
done
文件权限管理
chown:修改文件属主(owner)
chgrp:修改文件属组(group)
chmod:修改文件权限(属主+属组+others)
批量化修改属主+属组
chown catyer:catyer 1.txt
chown -R / chmod -R:递归修改目录下及所有子目录的文件权限(危险性高)
-rw-r-xrw-:文件,属主(读写)+属组(读执行)+others(读写)
模式法:
chmod +rwx file
chmod who opt per file
who:u,g,o,a(all)
opt:+(添加),-(减少),=(相等)
per:r,w,x
chmod o+x file:修改file下others的执行权限(添加)
chmod u+r,g+w,p+rwx file1:同时修改三个的权限
chmod a+rwx file1:直接把三个权限都加上rwx
数字法:
chmod +777 file
判断一个文件是否能删除(写入)等:是看他上级目录的权限
先把这个文件的权限修改为全0

将文件的上级目录(/home)修改为othersrwx

进入到目录下,还是可以删除这个文件,证明文件是否能被删除,取决于上级目录的权限(或者是执行,读写等)
比如之前修改wordpress目录的文件权限:也是修改/usr/share/nginx/html这个目录的权限,或者是下级目录wp的权限
chmod -R 777 wp(递归修改权限)
新建文件:没有执行权限x
新建文件夹:有执行权限


/bin/cp cp命令需要x权限(命令执行,必须)
/etc需要x(复制,权限随上级目录),/etc/issue需要r(貌似不需要,跟随上级目录的x)
/data需要x权限
/dir需要r和x(查看+执行)
文件编辑vim
扩展指令
:r 将领一个文件的内容读到当前文件来
:w 将目前的文件内容写到另一个文件中
:X 加密

扩展命令模式
:r! ls:将ls的命令立即读到vim命令下
:r! cat /etc/passwd | grep bash

vim的地址定界(批量处理行数)
全局命令模式下
:3,6d:多行删除
:3,4y:多行复制
:.,$y(yanked):当前行到最后一行复制,.代表当前行,$代表最后一行
:.,$d:当前行到最后删除
:.,$-1:当前行到倒数第二行,$-1代表倒数第二行
:%d:全文删除
:%y:全文复制
v选中+d:剪切
v选中+y:复制
u:撤销
批量化替换:这里支持例如/,@,#
:%s/this/that:只处理每一行第一个匹配到的this,成为懒惰模式,第一个%代表全文,可以加上的,这样和外面的sed是一样的,但是你sed进入不了vim内
:%s/this/that/g:全部替换(常用),/g代表一个附加的符号
vim内指定行文本替换
可以在vim内先看需要替换哪些行
:set nu
:33,35s/centos/epel:替换

如果是涉及到例如想把/dev/sda替换成/test/sdb这样的本身带有/的,可以使用#代替
:%s#/dev/sda#/test/sdb#,这样的写法就可以
:set nu(number) 显示行号
:set nonu 取消显示行号
vim界面内常用快捷键
查找:/+字符,从行首开始找
$+字符,从行尾开始找
多行选中:
v:小写v,代表选中字符(以字符为单位)
V:大写V,代表选中一行(整行)
ctrl+v:整块选中
文本处理工具
cat:查看文本
cat -n:输出带行号的文本内容
more:分页显示,到底退出
less:分页显示,到底不退出(常用)
可以跟管道使用,支持查看多行多页的文本内容
ifconfig | less:分页查看ifconfig输出内容
head -n 5:显示头5行
head显示前面的
head -n +5:显示从正数第五行开始显示前面的
head -n -5:显示从倒数第五行开始显示前面的
tail -n 5:显示最后五行
tail -n +5:显示从第5行开始显示后面的行,一般会使用这个
tail -n -5:显示从倒数第5行开始开始后面的行
tail -f /tomcat/log/catalina.sh:持续打印日志,查看运行状态
操作系统的日志:/var/log/message,tail -f /var/log/message
需要区分好+-的用法

sed -n "6p" 1.sh:看文件第六行
查看文件前3行:cat 1.sh | head -n 5
查看文件从第5行开始往后显示(tail代表往后显示):cat 1.sh | tail -n +5
查看文件从第6行开始往前显示(head代表往前显示):cat 1.sh | head -n +6
从第5行开始显示20行(显示第5行到25行):cat 1.sh | tail -n +5 | head -n 20
cut:单用于输出列
比如输出/etc/passwd的1,3,6,7列,前提和awk类似,需要先看好文件的列序号
cut -d: -f 1,3,6,7 /etc/passwd

案例:我要取磁盘利用率中的数字,思路
先df -h看到,use%在第5列,filesystem在第1列

df -h | awk '{print $5}' | tail -n +2 | tr -d %
先输出第五列,再从第二行开始显示+2,再将%百分号删除掉
tr -d:干掉某个字符,去掉某个字符(最好是独一无二的字符)

[root@master ~]#df -h | tail -n +2 | tr -s ' ' % | cut -d% -f5
[root@master ~]#df -h | tail -n +2 | tr -s ' ' % | cut -d% -f5 | sort -nr---也可以进行倒序排序
将这么多列的空格压缩替换成一个百分号%,再以%为分隔符输出第5列
tr -s :将某个字符(所有的字符)替换成某个字符输出

以空格为分隔符的写法:
cut -d " " -f 1
awk -F " " '{print $1}'
wc用法:统计行数
wc -l /var/log/nginx/access.log:等于是统计整个日志的访问次数(一次为一行,虽然一行放不下)
cut -d " " -f 1 | wc -l

sort排序:默认字母的顺序排序
sort -n:数字排序
sort -r:倒序排序(由大到小)
sort -R:随机排序
seq 50 | sort -R | head -n 1

uniq/sort -u:去除重复的行(重点理解)
uniq -c:去除重复的行,并且在重复的行前面显示统计这个行的行数,但是这个一定要重复的行在间隔
sort -u:去除重复的行,但是这个不能取出间隔开的行数(这个才是去除重复行的),sort -u可用于统计重复行的个数,输出独立行
【案例】查看日志中访问的IP统计,并输出最多的前五个
先sort保证在uniq的时候,重复行是间隔的
cut -d " " -f 1 /var/log/nginx/access.log | sort | uniq -c | sort -nr | head -n 5
【案例】查看日志中一共有多少IP地址访问,sort -u取所有重复行的独立行,并且统计个数
cut -d " " -f 1 /var/log/nginx/access.log | sort -u | wc -l
【案例】并发连接最多的远程主机IP
为什么不用netstat?因为ss比较netstat更为轻量级
目标是取peer address远程连接IP并且统计,然后输出个数
ss -nt | tail -n +2 | tr -s ' ' : | cut -d : -f 6 | sort | uniq -c | sort -nr |head -n 2

uniq -d:取相同的行
uniq -u:去不同的行
cat test1.txt test2.txt | sort | uniq -d(取相同的行)

正则表达式
正则:一般使用grep匹配,一般来说是以[ ]中括号的形式使用
[xxx]:匹配单个字符,比如[abc],[0-9],[a-z]小写,[A-Z]大写,多选一,表示包含a/b/c三个单独的字符
[xxx]:匹配非这个的字符,比如[abc],除abc外的其他字符
*:任意字符
.:匹配单个字符
.:匹配任意字符串,比如grep 'g.gle' test1.txt,表示找出在g..gle中间包含任意字符的行
可以在每个命令下查看特定的用法,比如在ls的帮助下查看有关大小(size的)
ls --help | grep size
可以使用ls -lh来查看文件(目录)的具体大小

【案例】在/etc下找rc.0-6的文件
注意:.在[ ]中括号内代表.,比如1[.txt]代表1.txt
ls /etc | grep ‘rc[.0-6]’

匹配次数:都在grep 'gxxgle'里面写的
比如:匹配所有,'g.*gle'
匹配至少一次,'g+gle'
可有可无:'g?gle'

排除文本中包含#或者;的行
grep -v "[#;]" /etc/test
匹配字符位置锚点
grep ^xxx:以xxx开头的字符
grep xxx$:以xxx结尾的字符
grep -m 3:表示看前三行
grep -c:统计出现的次数
grep -v:反向查找
grep -v "grep":除去grep里面的所有
grep -v "#" :出去带#的行,常用于不看注释的行
grep -w:单词
【案例】找到ifconfig中所有的ipv4地址
ifconfig | grep -w inet | awk '{print $2}'

grep '^$':找出空行,行首行尾连在一块就叫空行
grep -v '^$':排除掉空行
grep '^s' /etc/profile:只找文件内的空行
grep -e "xxx" -e "yyy":多个选项都匹配,或的用法
grep xxx /etc/passwd | grep yyy:都的用法,包含在同一行内
grep -f:把a文件的文件内容作为b文件的过滤条件
【案例】查看两个文件相同的行
grep -f a.txt b.txt
cat a.txt b.txt | sort | uniq -d
【案例】查找出java进程并且终止掉Java进程
ps -aux | grep java | grep -v grep
ps -ef | grep java | grep -v grep,找到java进程的pid($2)
ps -ef | grep java | grep -v grep | tr -s ' ' : | cut -d : -f 1,2

然后kill -9 +pid终止掉进程
【案例】查看CPU的核数
cat /proc/cpuinfo | grep 'pro' | wc -l

【案例】排除掉/etc/profile的空行和注释行,同样的写法(注意:中括号表示的是匹配到的)
grep -v '^$' /etc/profile | grep -v '^#':最老土的方法
grep '[#]' /etc/profile:这个要注意没有-v,指的是以单字符开头的行(除去空行和#),常用与文本处理
[1]:中括号内必须有一个字符,但是又不能是#号(#已排除),证明在[#]内肯定不是空行了。[]代表排除的意思,[$]代表排除$的行而不是^$代表空行
grep -v '#|$',这个表示或者的意思,|表示或,排除掉#开头或者是空行(^$代表空行)

|写法:
a|b:a或者b
C|cat:C或者cat
egrep:代表扩展表达式,一般还是用常用grep
普通正则表达式练习

1.grep 'S|s' /proc/meminfo:同时匹配S开头或者是s开头
2.grep -v '/bin/bash' /etc/passwd
3.cat /etc/passwd | grep rpc | awk -F: '{print $7}'
4.[0-9][0-9]|...
5.netstat -ant | grep 'LISTEN[.*\s$]',\s代表空白字符
6.netstat -ant
7.cat /etc/passwd | awk -F : '$3<1000{print $3,$1}' | sort -n
8.cat /etc/passwd | awk -F : '$3<1000{print $3,$1}' | sort -n
9.df -h | tail -n +2 | tr -s ' ' : | awk -F: '{print $5,$1}' | tr -d % | sort -nr

扩展正则表达式练习

1.cat /etc/passwd | grep 'root|mysql|^catyer' | cut -d: -f1,3,7:grep上查找root/mysql/catyer开头的行
5.last | tr -s ' ' : | grep 'root' | awk -F: '{print $3,$1}' | grep [0-9] | sort | uniq -c | sort -nr:注意需要只筛选数字的,先sort排序再uniq -c
7.ifconfig | grep -w 'inet' :使用grep -w取出固定单词,而不是取包括inet的行
文本处理三剑客:grep,sed,awk
grep常见格式
grep -n:显示行号
grep -v:除去匹配字段显示,反选显示
grep -i:忽略大小写,比如说要搜个root,grep -i无论是Root还是root都输出
grep -c:显示匹配的行数
grep -c 'bash' /etc/passwd--->显示3行
grep -e:显示多个选项,grep -e 'abc' -e 'efg'
grep -E=egrep,一般来说可以用-E来代替egrep
##【案例】查看TCP连接的所有状态统计
ss -ntl:找到tcp连接的所有,反向查看除了state开头的所有,取第一列,统计次数uniq -c,listen只监听listen状态的
ss -ntl |grep -v ^State | cut -d ' ' -f 1 | sort | uniq -c

ss -ntl | grep LISTEN | cut -d ' ' -f 1
直接grep LISTEN得了
tr常见格式
tr基本用法
tr -s:缩减连续字符成指定单个字符
tr -d:删除某个字符输出
tr -c:反选指定字符
##案例
##tr -s ' ' +:把多个空格缩减成+号
##xargs:传参
1.txt,求abc的和
a=10
b=20
c=30
[root@ecs-web01 2use]#cat 1.txt | cut -d '=' -f2 | xargs | tr -s ' ' + | bc
80
##输出16个随机字符(仅包括大小写字母/数字)
##将所有除了大小写字母、数字(反选)的字符全部替换成大小写字母、数字
[root@ecs-web01 2use]#cat /dev/urandom | tr -dc '[a-z][A-Z][0-9]' | head -c 16
fb8GCHDT[g29qw7S
sed常见格式
sed处理数据的格式:逐行处理,只处理行的数据,与单纯列(cut)的文本处理不一样,默认输出到bash为全文
sed核心:可以对文件进行修改
sed ' ':输出全文,=cat
sed -e:多点编辑
sed 's/xxx/yyy/g' xxx.txt:将xxx替换成yyy,并且在bash上面输出,规则跟随正则,/g实现全局替换
##基本
sed -n:不自动打印,如果不加n的话,就是全文打印,不会匹配你需要打印的内容**
#从现在的行到第五行
sed -n '.,5p':
#到结尾,末行
sed -n '.,$p'
sed -n '2,$p'
##从第二行开始往下20行
sed -n '2,+20p'
##输出的时候不要某些行,不要2-5行
sed -n '2,5d' 1.txt
和在vim内编辑不同的是,不涉及当前行,因为不在编辑文件,想输出第一行到最后一行
sed -n '1,$p' 1.txt
/pat1/,/pat2/:输出从匹配到pat1的行到匹配pat2的行
#,/pat/:行号---匹配到pat1的
sed -n '/b/,/s/' /etc/passwd:找出b开头的行到s开头的行
sed -n '/root/p' /etc/passwd:找到在/etc/passwd内包含root的行
sed -i替换文本内容
sed -i s//g:替换掉文本内容,在文本外面修改替换
在文本内,可以使用vim进行替换,:%s/xxx/yyy/g,/g全局模式
【案例】修改关闭SELINUX
[root@master ~]#sed -i 's/SELINUX=disable/SELINUX=disabled/g' /etc/selinux/config
在xx行后面追加内容,但是不写进文件内
sed '2,3r /etc/issue' 1.txt
grep -i:忽略大小写

把sed找到的行写入到/etc/issue(>重定向完全覆盖)
cat 1.txt | sed '2,3w /etc/issue'
awk常见格式
其实是一种编程语言awk,目前使用的是GNU awk--->gawk

awk:常见的文本处理,输出格式化的文本报表
awk -F:分隔符,类似cut -d那样可以指定,默认为连续几个空白符,awk的话就不用压缩了,默认就是空白的字符作为分隔符
awk输出的每一列:称为域
awk还可以进行运算
如果有多个action,则用;隔开,比如awk '{print $1;print $2}'
##awk基本格式
awk 'pattern{action}'=awk 'program'
awk '/netmask/{print $2}'
[root@ecs-web01 2use]#ifconfig eth0 | awk '/netmask/{print $2}'
192.168.0.3
##执行顺序
BEGIN....END....
##打印磁盘的使用率,用awk再取以“%”作为分隔符的第一列
[root@ecs-web01 2use]#df -h | awk '{print $1,$5}'
[root@ecs-web01 2use]#df -h | awk '{print $1,$5}' | awk -F "%" '{print $1}'
Filesystem Use
devtmpfs 0
tmpfs 0
tmpfs 11
tmpfs 0
/dev/vda1 26
tmpfs 0
##输出的列与列之间使用不同的分隔符,$1与$3之间可以使用" "来作为连接
[root@ecs-web01 2use]#awk -F: '{print $1"++"$3}' /etc/passwd
root++0
bin++1
daemon++2
##输出目前已经建立的连接,tail -n +2表示从第二行开始往后
[root@ecs-web01 2use]# ss -ant | awk '{print $1}' | tail -n +2 | sort | uniq -c | sort -nr
10 LISTEN
3 ESTAB
awk实现正则表达式的使用
-F:可以添加多个分隔符,比如awk -F " +|%",表示空格或者是%作为分隔符
+表示一个以上," +"表示一个以上的空格
##显示硬盘的使用量(正数)
[root@ecs-web01 2use]#df -h | awk -F " +|%" '{print $1,$5}'
Filesystem Use
devtmpfs 0
tmpfs 0
tmpfs 11
tmpfs 0
/dev/vda1 26
tmpfs 0
##显示硬盘的使用量(倒数NF),显示目前的dev设备
[root@ecs-web01 2use]#df -h | grep '^/dev/' | awk -F " +|%" '{print $(NF-2)}'
26
取nginx日志内的IP地址以及访问时间
awk -F"[ ]":代表可以写多个分隔符,这里的awk -F "[[ ]"代表[单边中括号和" " 空格都参与作为分隔符,正则表达式内,[代表多个选1个]
IP在第一列,时间在$5
[root@ecs-web01 2use]#cat /var/log/nginx/access.log | awk -F "[[ ]" '{print $1,$5}' | head -n 5
34.78.6.216 02/Jul/2022:03:28:49
185.196.220.81 02/Jul/2022:03:34:51
183.240.111.153 02/Jul/2022:03:41:40
194.233.164.61 02/Jul/2022:03:42:49
183.240.111.153 02/Jul/2022:03:48:17
取主机名,追加到源文件
[root@ecs-web01 2use]#awk -F "[. ]" '{print $2}' 1.txt >> 1.txt
[root@ecs-web01 2use]#cat 1.txt
1 www.111.com
2 444.111.com
3 catyer.111.com
www
444
catyer
awk常用变量/定义变量NF、NR
内置变量
FS:字段分隔符,FS变量可以嵌入到输出的列中作为分隔符
-v:定义变量
##使用变量输出passwd
[root@ecs-web01 2use]#awk -v FS=":" '{print $1FS$3}' /etc/passwd
root:0
bin:1
daemon:2
adm:3
lp:4
sync:5
$NF:统计每一行多少列(或者统计有多少个字段)
其实NF就是最后一列,可以直接输出$NF代表最后一列
[root@ecs-web01 2use]#awk -F: '{print NF}' /etc/passwd
7
7
[root@ecs-web01 2use]#awk -F: '{print $NF}' /etc/passwd
/bin/bash
/sbin/nologin
[root@ecs-web01 2use]#ps aux | awk '{print $NF}' | head
COMMAND
22
[kthreadd]
[ksoftirqd/0]
##倒数第一列、第二列
[root@ecs-web01 2use]#netstat -ant | tail -n +3 | awk '{print $(NF-1)}'
0.0.0.0:*
0.0.0.0:*
0.0.0.0:*
##看有哪些远程主机在连接这台机器(注意:一定是已经建立连接的ESTABLISHED)
##netstat -nt,因为-l是显示LISTEN的状态,-a又是列出所有
[root@ecs-web01 2use]#netstat -nt | tail -n +3 |awk '{print $(NF-1)}'
113.88.213.117:51140
100.125.4.14:443
113.88.213.117:51497
netstat -ntl:列出tcp连接,在LISTEN的
netstat -ant:列出tcp连接,无论是什么STAT
netstat -nt:列出tcp连接,只列出建立的tcp连接(重要)
NR:表示行
NR==1:表示第一行
NR!=1:表示除了第一行外的所有行
##输出除了第一行外的所有
[root@ecs-web01 2use]#df -h | awk 'NR!=1{print }'
devtmpfs 486M 0 486M 0% /dev
tmpfs 496M 0 496M 0% /dev/shm
tmpfs 496M 51M 446M 11% /run
tmpfs 496M 0 496M 0% /sys/fs/cgroup
/dev/vda1 40G 9.5G 28G 26% /
tmpfs 100M 0 100M 0% /run/user/0
##输出第二行
df -h | awk 'NR==1'
##打印第二行第一列
df -h | awk 'NR==2{print $1}'
awk的打印printf
printf:格式化打印,但是不主动换行
print:主动换行
awk -F: '{printf "format",$1}' xxxfile.txt
format表示格式,后面要加,分隔开,$1表示输出第一列
基本常用参数格式:
%s:显示字符串,比如%-10s,代表会输出10个字符串,前面是format
%d:整数
%f:浮点数
%c:显示字符
修饰符
#[.#]:第一个#表示数字显示的宽度;第二个表示显示的精度,如
%3.1f,表示宽度为3,输出小数点后1位的浮点数
##所有格式默认右对齐
-:实现左对齐,比如%-10s,表示左对齐10个字符;%10s默认右对齐
+:实现+-号
##输出1位的浮点数
[root@ecs-web01 2use]#awk -F"=" '{printf "%s %5.1f\n",$1,$2}' 1.txt
a 1.2
b 5.9
c 7.5
format格式对齐:
需要找到输出打印的字符串需要对齐的字符数,以达到良好的对齐效果
注意:在" "内,一个%代表一个格式,且一个%对应一列的格式,比如%-20s对应了$1的格式
##输出第一列的字符串(user),printf "\n"表示输出换行符,printf本身不带换行符
[root@ecs-web01 2use]#awk -F: '{printf "%s\n",$1}' /etc/passwd
root
bin
daemon
adm
##user列20个字符左对齐,userid列5个字符左对齐
[root@ecs-web01 2use]#awk -F: '{printf "%-20s %-4s\n",$1,$3}' /etc/passwd
root 0
bin 1
daemon 2
##前面加修饰的文本,比如username
[root@ecs-web01 2use]#awk -F: '{printf "username:%-15s uid:%-4s\n",$1,$3}' /etc/passwd
username:root uid:0
username:bin uid:1
username:daemon uid:2
username:adm uid:3
awk的pattern判断
只有符合pattern判断的才会执行下面的步骤,表示判断匹配
awk '$3>1000{print $1,$3}':UID大于1000的user用户和UID
算数命题
##awk支持很多种加减法算法等
[root@ecs-web01 2use]#awk 'BEGIN{i=0;print i++,i}'
0 1
[root@ecs-web01 2use]#awk 'BEGIN{i=0;print ++i,i}'
1 1
awk内的条件判断:可以指定某一些判断,类似于if字符串的匹配
==等于,!=不等于,>大于,>=大于等于,<小于,<=小于等于
##输出第二行,NR==2
[root@ecs-web01 2use]#awk 'NR==2' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
##输出UID>3的行,其实是判断第三列(以:隔开的第三列)的数值是否大于1000(UID),大于1000就属于是服务用户,小于1000是系统用户
[root@ecs-web01 2use]#awk -F: '$3>1000{print $1,$3}' /etc/passwd
user1:x:1001:1001::/home/user1:/bin/bash
user2:x:1002:1002::/home/user2:/bin/bash
user3:x:1003:1003::/home/user3:/bin/bash
##如果UID>3,则输出$1和$3
[root@ecs-web01 ~]#awk -F: '$3>1000{print $1,$3}' /etc/passwd
user1 1001
user2 1002
user3 1003
##如果第一列有=user1的行,输出user1
[root@ecs-web01 ~]#awk -F: '$1=="user1"{print $1}' /etc/passwd
user1
##或者直接grep grep -w都可以
[root@ecs-web01 ~]#grep 'user1' /etc/passwd
user1:x:1001:1001::/home/user1:/bin/bash
awk+pattern正则表达式(默认扩展)&逻辑运算符
在program前面可以写判断或者是正则表达式来判断输出的语句
awk '/###/{print $1}':包含###的所有行
##判断以user1开头的
[root@ecs-web01 2use]#awk -F: '/^user1/{print $1,$3}' /etc/passwd
user1 1001
##取出IP地址,取掩码的字段netmask,可以取特殊的字段作为条件匹配式
[root@ecs-web01 2use]#ifconfig eth0 | awk '/netmask/{print $2}'
192.168.0.3
取磁盘使用率为/dev/开头的磁盘
awk '//dev//':注意,转义字符是在字符前,而不是字符后,关于sed的转义也是在特殊字符的前面转义的,转义斜杠,因为//dev//
第二行往下的行,过滤第一行:awk 'NR>1'或者是awk 'NR>=2'
多行匹配:
##注意点:在系统识别不要的特殊字符,例如//斜线,*,#等,都需要在字符前加转义,而不是字符后
[root@ecs-web01 2use]#df -h | awk -F " +|%" '/^\/dev\//{print $5}'
26
[root@ecs-web01 2use]#df -h | awk -F " +|%" '/^\/dev\//{print $(NF-2)}' --->可以用(NF-2)
26
##grep好像是不用使用转义,或者直接用扩展正则,多条指令组合
[root@ecs-web01 2use]#df -h | grep '^/dev/' | awk '{print $(NF-1)}' | tr -d %
26
df -h | sed -n '/^\/dev\//p' ##sed -n需要加\转义,grep '/\/^dev\//'
/dev/vda1 40G 9.5G 28G 26% /
##取从第二行开始往下的行,条件判断
[root@ecs-web01 2use]#df -h | awk 'NR>1' 或者是 awk 'NR>=2'
[root@ecs-web01 2use]#df -h | tail -n +2
df -h | awk 'NR>=2{print $1}'
devtmpfs 486M 0 486M 0% /dev
tmpfs 496M 0 496M 0% /dev/shm
tmpfs 496M 51M 446M 11% /run
tmpfs 496M 0 496M 0% /sys/fs/cgroup
/dev/vda1 40G 9.5G 28G 26% /
tmpfs 100M 0 100M 0% /run/user/0
##取root行到adm行,这个正则是不支持数字的
##中间记得加,好
[root@ecs-web01 2use]#cat /etc/passwd | awk '/^root/,/^adm/'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
逻辑处理符号
逻辑与&&
逻辑或||
逻辑非:!,取反
##与判断,大于1的行和小于7的行
[root@ecs-web01 2use]#df -h | awk 'NR>1 && NR<7'
devtmpfs 486M 0 486M 0% /dev
tmpfs 496M 0 496M 0% /dev/shm
tmpfs 496M 51M 446M 11% /run
tmpfs 496M 0 496M 0% /sys/fs/cgroup
/dev/vda1 40G 9.5G 28G 26% /
正则表达式去除#注释行和空行,写法类似sed和grep,只不过现在搬到awk上
#代表#开头的行,$代表空行,前面!代表非
[root@ecs-web01 2use]#awk '!/^#|^$/' /etc/fstab
UUID=1cf0b662-ebd1-44a2-bbd2-0a6e58aec5fa / ext4 defaults 1 1
##只想取#开头的行
[root@ecs-web01 2use]#awk '/^#/' /etc/fstab
#
# /etc/fstab
# Created by anaconda on Fri Feb 26 08:09:31 2021
awk的条件判断if..else,while
if-else判断,注意格式,实现和shell内的if一样的判断
ctrl+a:光标到行首
ctrl+e:光标到行尾
##简单的if判断分数,定义Num变量的值
[root@ecs-web01 2use]#awk 'BEGIN{num=90;if(num>=80){print "good"}else if(num>=60){print "pass"}else {print "no pass"}}'
good
[root@ecs-web01 2use]#awk 'BEGIN{num=40;if(num>=80){print "good"}else if(num>=60){print "pass"}else {print "no pass"}}'
no pass
判断一个文件的分数是否达标
使用BEGIN和不使用BEGIN的区别:看看是否需要处理文件,如果awk后有文件,则不需要加BEGIN,BEGIN一般都是处理数据的
[root@ecs-web01 2use]#cat 1.txt
name score
tom 100
mary 50
tim 90
catyer 70
##判断这个文件内的分数是否达标;输出除了标题往下的行:awk 'NR>=2{print $0}'
##把awk内的变量给到表内的列赋值,num=$2第二列
[root@ecs-web01 2use]#awk 'NR>=2{num=$2;if(num>=80){print $1,"good"}else if(num>=60){print $1,"pass"}else {print $1,"no pass"}}' 1.txt
tom good
mary no pass
tim good
catyer pass
while循环实现1+100(awk)
##注意点:一个判断+一个输出才需要; 或者是变量赋值一条语句才需要;
##在while(i<=100){xxx},这中间不需要;
[root@ecs-web01 2use]#awk 'BEGIN{i=1;sum=0;while(i<=100){sum+=i;i++};{print sum}}'
5050
awk数组(去重思想)
awk内的数组都是关联数组,即每个元素的下标都是定义好的,而不是array[0],array[1],自定义下标
而是array[name]=tom
array[sex]=male这类的数组下标
数组从文件内去重(打印去重)
意义:$0代表第一行,数组下标为$0表示第一行,这时候第一行array[a]=' ',没有赋值,所以为空;数组前面取!(反),则为1;现在的array[a]=1(真)
同理,出现过的a c v 1都代表了1,array[1]=1
再出现的a,由于array[a]=1了,这时候取反就=0,就不会输出空行
[root@ecs-web01 2use]#cat 1.txt
1
a
c
v
5
1
a
c
v
[root@ecs-web01 2use]#awk '!array[$0]++' 1.txt
1
a
c
v
5
awk的for循环:遍历数组下标,然后输出数组下标以及下标对应的元素的值
##遍历数组下标
##i是数组下标的值a b c,array[i]是元素的值
awk 'BEGIN {stat["a"]="a1";stat["b"]="b1";stat["c"]="c1";for (i in stat){print i,stat[i]}}'
a a1
b b1
c c1
使用awk数组统计nginx的access.log IP地址的数量
先定义一个数组,因为$1第一列都是IP地址,所以IP地址作为数组array的下标,遇到一个IP就++;从0开始++,有遇到相同的IP就++;比如
192、172、10三个IP,数组应该为array[192]=3,array[172]=4,array[10]=2
输出i in array表示i是IP地址(i是数组下标),array[i]则是他们输出的次数,从而统计出日志IP的访问数量
##END表示先执行完遍历的操作,再输出次数和IP
awk '{array[$1]++}END{for (a in array) print array[a],a}' /var/log/httpd/access_log | sort -nr
awk脚本文件.awk
用awk语言写的东西可以写进a.awk文件内
vim awk.awk
awk -f调用awk脚本
【面】生成random密码的几种方式
1.安装expect生成mkpasswd,使用mkpasswd生成,只能生成9位的密码
组成:大小写、数字、特殊字符
[root@ecs-web01 ~]#mkpasswd
0lN6qf&Ns
[root@ecs-web01 ~]#mkpasswd
hw0bm8LX[
[root@ecs-web01 ~]#mkpasswd
Zr*o1Ow8h
2.用urandom设备生成,转换,生成任意长度的字符
urandom块设备中断输出,截取指定位数的字符head -c
优点:可以转换成任意你想要的字符密码并且输出,可以结合创建用户密码标准输入
加上 | xargs代表换行
[root@ecs-web01 ~]#cat /dev/urandom | tr -dc [:alnum:] | head -c 10 | xargs--->字母+数字
9ouLPuXaZe
[root@ecs-web01 ~]#cat /dev/urandom | tr -dc [:upper:] | head -c 10 --->纯大写字母
MYLMOTXQGY
[root@ecs-web01 ~]#cat /dev/urandom | tr -dc [:lower:] | head -c 10 --->纯小写字母
wbkzacqgwp
##也可以使用标准输入
[root@ecs-web01 ~]#tr -dc '[:alnum:]' < /dev/urandom | head -c 10 | xargs
x5PSlm3W9m
##实现user的密码标准输入
passwd=`xxx`
echo passwd | stdin --passwd $user
3.openssl生成
效果和/dev/urandom块设备生成类似
[root@ecs-web01 ~]#openssl rand -base64 9 | head -c 10
4DDS3odTxw
[root@ecs-web01 ~]#openssl rand -base64 9 | head -c 10
Nr4a9aETwI
[root@ecs-web01 ~]#openssl rand -base64 9 | head -c 10
59a02XwQUM
【面】打印出1-100相加的结果
awk的用法效率高,而且简单
time:测试命令的执行速度,time()
##awk写法,定义变量,主要还是格式问题,还是awk+while方便,while(i<=100){sum+},中间不需要;
##这里不是shell,不需要加do
awk 'BEGIN{i=1;sum=0;while(i<=100){sum+=i;i++};{print sum}}'
awk 'BEGIN{for(i=1;i<=100;i++){sum+=i};{print sum}}'
##for循环
sum=0;for((i=1;i<=100;i++));do ((sum+=i));done;echo $sum
5050
##seq
seq -s+ 100 |bc
##统计执行时间,1+到1000000,awk工具的效率最快
awk时间:0.769s
for时间:5.651s
[root@ecs-web01 ~]#time(awk 'BEGIN{i=1;sum=0;while(i<=1000000){sum+=i;i++};{print sum}}')
500000500000
real 0m0.075s
[root@ecs-web01 ~]#time(sum=0;for((i=1;i<=1000000;i++));do ((sum+=i));done;echo $sum)
500000500000
real 0m5.651s
【面】add.txt文件内有1-10 10个数字,相加的和
##
[root@ecs-web01 2use]#cat 1.txt
1 2 3 4 100 11111
[root@ecs-web01 2use]#cat 1.txt | tr ' ' + | bc
11221
【面】输出nginx日志内访问的最多的IP(client IP)
##传统写法,先sort来排一下序列,取第一列进行排序
[root@ecs-web01 2use]#cat /var/log/nginx/access.log | awk '{print $1}' | sort | uniq -c | sort -nr | head -n 5
39 209.182.103.18
34 183.240.111.153
18 8.219.71.118
6 167.94.146.57
4 85.119.151.251
##awk数组写法,array[$1]代表第一列,++代表遍历所有第一列的元素(这里的元素就是IP地址); i in array表示i是下标,打印出元素+数组下标
##下标是IP地址,次数array[i]这个整体
awk '{array[$1]++}END{for (i in array){print array[i],i}}' /var/log/nginx/access.log | sort -nr | head -n 5
39 209.182.103.18
34 183.240.111.153
18 8.219.71.118
6 167.94.146.57
4 85.119.151.251
【面】文本处理--ipv4地址
取私网IP地址可以直接hostname -I
##案例
hostname -I:直接输出IP地址(内网IPV4)
##文本取法
ifconfig eth0 | awk 'NR==2{print $2}'
ifconfig eth0 | sed -n '2p' | awk '{print $2}'
ifconfig eth0 | awk '/netmask/{print $2}' #awk取匹配字段
ifconfig eth0 | grep -w inet | awk '{print $2}' #直接取inet那一行
##取服务器的公网IP
curl -s icanhazip.com
curl cip.cc
【面】输出硬盘的使用率
空格%+,代表[[:space:]],也是正则内空格表达式的一种,最好还是用awk
df -h | awk -F"[ %]+" '{print $5}'
df -h | awk -F"[ %]+" '{print $(NF-2)}'
df -h | awk -F" +|%" '{print $5}' --->常用
df -h | tail -n +2 | tr -s ' ' : | cut -d: -f 5 | tr -d %
【面】输出/etc/profile内的非空行和非注释行
sed '/xxx/d;':输出除去xxx的行,';'分号专门用于分离,一般的sed命令格式是'/script/d;/xxxx/d'
sed '2,5d':输出的内容内除去2到5行,sed基本都是根据行来处理的
sed -n '/xxx/d;/$/d' /etc/profile:实现两个script,d排除掉注释行和空行,这个需要写在' '单引号里面
grep内可以使用[ ]中括号,比如'[#]',sed内是/^#/来排除
用法归纳:不匹配正则的话,就要加\反斜杠转义
##p是打印,d是删除
##sed方法
sed '/^#/d;/^$/d' /etc/profile
sed '/^#\|^$/d' /etc/profile #删除掉^#或者是空行输出
sed '/^#\|^$/p' /etc/profile #只打印空行/#开头,转义匹配
##grep用法,可使用扩展正则
grep -v '^#\|^$' /etc/profile
grep -Ev '^#|^$' /etc/profile,扩展正则
##awk用法,非匹配这些,即不输出带^#或者空行,反过来就是匹配输出^#或者^$;默认输出'{print $0}'
awk '!/^#|^$/' /etc/profile
awk '/^#|^$/' /etc/profile
【面】统计目前连接tcp的状态,并且输出统计的次数
处理文本,处理第一列

ss -ant | awk '{print $1}' | tail -n +2 | sort | uniq -c
ss -ant | awk '{print $1}' | sed -n '2,$p' | sort | uniq -c | sort -nr | head -n 2
【面】ECS上两个主机的网络不通,如何排查
1.先看主机是否有开机,主机内是否配置网卡,网卡是否配置IP
2.是否是同一个VPC(网段),在同一个VPC内子网间是否配置了ACL策略进行拒绝访问,白名单等问题
3.安全组内是否有放通ICMP或者是特定的服务端口
4.防火墙是否关闭/防火墙是否有开启放通对应端口
【面】现在主机卡顿,如何找出占用CPU/内存最大的进程,并且找到他的磁盘文件?(病毒)--现在找不到路径
1.先用以下命令查看cpu和内存占用最大的进程以及进程的pid
ps aox pid,%cpu,%mem,cmd -k -%cpu
ps aox pid,%cpu,%mem,cmd --sort -%mem
##使用ps aux 查看占用内存和CPU最多的进程
ps aux --sort -%mem
ps aux --sort -%cpu
##主要是查看进程号
2.到/proc目录下找到该进程的目录,看是否真的存在
ls /proc | grep pid
3.进入到pid目录下,ll查看exe文件是否是某个磁盘文件的连接文件
4.备份恢复/杀死进程/删除掉磁盘文件rm -rf /*,或者杀死进程 kill -9 pid号
killall -0
文件查找与压缩
locate:查找文件,已经预先建立好了索引数据库文件,会遍历整个系统的文件,消耗资源
优点:适合找一些已经确定的配置文件,系统文件,速度极快
缺点:不能真实,实时的反馈这个文件的位置,需要及时更新数据库文件.db

find命令常用格式
find查找:一行一行找
find:直接列出当前目录下所有子目录的文件
find /etc/ -maxdepth 1:表示查找一级目录下的所有文件,类似这样

find /etc -name "*.conf":找名字,注意要加双引号,实现通配符
find /home -user catyer:找user是catyer的文件
find /home -user catyer -ls:表示找到这些文件显示在bash下后直接ls -l(挺好用)
find /etc -type f -empty:找到/etc目录下的空文件
find /etc -type d -empty:找到/etc目录下的空目录,目录空的为6个字节,文件为0个字节
find -size [+|-] K/M/G(注意要大写):查找指定文件大小区间
find /etc -size +20K -type f:查找20K以上的文件,不包含20K
-20M:20M以下的文件,不包含20M,所有SIZE都是不包含
find -atime/-mtime/-ctime [+|-]day:访问文件时间/修改文件时间/修改权限时间chmod
+10表示:10天以上(距离今天),find /etc -atime +10
-10表示:0-10天,访问文件10天以下(距离今天)
10表示:10天到11天(一般用于访问刚好10天的)
[+|-]amin/mmin/cmin:访问文件分钟数/修改文件分钟数/修改权限分钟数
3天内(-atime -3)访问的文件,确实只有这么多。3天(-atime +3)以上访问的就多了

find -perm [/]-]MODE:查找固定权限的文件
find -perm 755:文件/目录权限正好是755的
find后加的处理动作(命令)---{}
-print:直接打印,没什么别的
-ls:显示找到文件的具体信息,包括权限,文件属主组,文件大小等等,还显示inde节点编号

-delete:直接接删除,不询问(慎用)
-ok:表示在find找到对应文件后,需要再进一步操作的时候询问一下
find -type f -atime 3(3天) -ok(询问) cp {}(之前find找到的结果) {}.bak ;(最后需要加;代表结束)
这个{}相当于是代表前面的结果,然后复制到这个结果的.bak(备份文件)
cp -b:复制过去的时候顺便进行备份

-exec:不询问,用法同上,-exec后面可以加command命令操作之前的{}变量(非常常用)
cp复制,mv移动(重命名),rm -rf删除等等command都可以用


找到目录下所有具有写权限的文件,并且删除他们的写权限
find -perm 002 -type f -exec chmod o-w {} ;
-exec:一般用于对出来的文件进行操作才需要(rename,mv,cp等)
xargs:支持标准输入,--stdin(常用),xargs也可以使用{}作为传参
xargs:作为处理find命令结果的传参作用,相当于有一些命令不直接支持执行
比如我想ls -l一下find命令的结果文件列表,我执行
find -name "*.txt" ls -l会报错

find -name "*.txt" | xargs ls -l
这个才执行成功,需要将前面的find结果作为“参数”传递给后面的ls -l命令,因为ls -l不直接支持标准输入
ls -l | xargs rm:删除掉当前目录下的文件(不询问,直接传参)

批量化的创建文件
echo file{1..3}.log | xargs touch:传参file1-3给到touch,其实就是前面是结果,后面是操作

结合多个find条件,默认是与,-a,如果要实现或-o或者是非!,可以加上参数
-a:表示与
-o:或
!:非

find练习

1.find /var -user root -group mail -type f
2.find /var ! -user root ! -user lp ! -user gdm -type f
3.find /var -mtime -7 ! -user root ! -user postfix -type f
4.find .
5.find /etc -size +1M -type f
6.find /etc ! -perm a=w -type f:非all=w,即没有w写权限
7.find /etc ! -perm a=w -type f
find重点:-exec和| xargs的区别
-exec:常用于操作前面的参数,比如重命名,移动,做备份,复制等,需要进行改变操作的,格式记得在最后写上;
比如
find -name "*.txt" -exec cp {} {}.bak ;
find -name "*.txt" -exec mv {} /tmp ;

xargs:用于接显示、删除等命令,不涉及对变量的
find -name "*.txt" | xargs ls -l:查看find出来的文件属性,ls -Sl,-S代表从大到小排序
find -name "*.txt" | xargs rm -rf:删除掉
可以用于其他命令,比如批量化创建文件,或者批量化创建用户
echo file{1..100}.log | xargs touch,创建文件就不用
echo user0{1..100} | xargs -n1 useradd:批量化创建用户,注意:一定要加n1,表示一行一行创建
注意:密码重置只能在一个user上使用,用户可以批量化创建
echo "123" | passwd --stdin user1/root等,可用于shell脚本
【案例】统计系统内一共的C语言文件代码行数
统计一个文件内的文本行数:wc -l messages

找到所有的C语言文件
find -name "*.c" | wc -l
可以使用先找到所有的c文件,然后把这个当做一个cmmand,用cat来显示所有,代表我在cat所有的文件的行数,再wc -l统计
cat find -name "*.c" | wc -l

压缩指令
gzip和unzip:对应的是.gz的后缀
gzip -c:压缩
gzip -d:解压缩
zcat查看.gz文件内的内容
zip和unzip:对应.zip后缀
最常用:tar
-z:涉及gzip压缩,压缩
-c:压缩新的备份文件,只打包不压缩,-cz打包压缩(可以直接操作目录)
-x:从备份文件中还原文件,常用与解压缩
-v:显示压缩/解压缩路径
-f:指定备份文件
-t:查看压缩文件内的内容
tar xxx.tar/gz -C /opt:-C代表解压到另一个目录下
一般来说只涉及压缩和解压缩
tar -zxvf xxx.tar.gz
tar -czvf xxx.tar.gz xxx(file name)

tar xf xxx.tar.gz.xz等:可以直接自动解压,不需要人为去写后缀,常用的command
压缩有时候可以用于备份备份,相当于是一份备份存在硬盘
tar -tvf xxx.tar.gz:查看压缩文件内的内容,也可以显示文件的属主,名称,权限等

磁盘的存储管理
fdisk -l:磁盘管理
分区类型:
MBR分区:一种磁盘的分区类型,最大支持2T的空间,32位的分区方式
主分区:最大支持划分4个主分区,因为分区表最大为64b,而每16b就是一个主分区,所以最多4个,主分区内不能再划分分区了
扩展分区:里面还可以继续划分逻辑分区,扩展分区最多1个
分区表最多支持64字节的空间大小

分区结构:主引导程序+若干个分区表(MBR分区4个主分区),一个分区表大小为16字节(bytes)

GPT分区:64位的分区方式,最多128个分区,最大空间:8Z
GPT分区模式:全部都是主分区,没有所谓的扩展分区和逻辑分区
现在都是采用GPT较多
云服务器的硬盘:一般都是MBR分区
创建一个2T以上的盘,看是不是GPT分区
lsblk:查看硬盘分区情况,一个盘,分了一个主分区

交换分区swap
用于在内存不足的情况下,临时使用硬盘的一个swap交换分区,用硬盘模拟内存使用
优点:能够临时性的满足内存的不足
缺点:硬盘的读取速度比内存慢很多
在生产中,一般很少用swap交换分区的东西,云服务器(本身就没有交换分区的说法),直接扩容内存就行,内存+CPU直接影响程序的运行情况

关闭交换分区:swapoff -a
交换分区所在的目录:/proc/swap
管理硬盘分区命令fdisk/gdisk/parted
parted:选择后会立即执行,慎用!
fdisk:管理MBR分区,也可以管理GPT
gdisk:管理GPT分区(一般不常用)
parted基本命令:
parted /dev/vdb
mkpart primary 1 200M:创建一个主分区,200M,默认的单位是200M
mklabel:改变磁盘的分区类型,可以选择gpt,清空磁盘
parted /dev/vdb rm 1:删除1分区
print:打印出分区情况
fdisk基本操作:
n:新分区
p:打印分区表
w:磁盘变更写入到磁盘
d+分区号:删除分区
t:改变分区类型(type),L查看代码,可以修改成LVM逻辑卷(TYPE:8e)
partprobe:同步分区表,内存上的分区表和硬盘上的分区表同步
查看Linux主机的硬盘分区格式:fdisk -l
dos就是MBR分区,因为这个虚拟机是创建在SATA硬盘上面的,SATA硬盘是MBR分区

fdisk查看分区的总大小,扇区数量(sectors)
大小=扇区数(sectors)*512bytes
现在/dev/vda1是默认的系统盘,所以已经占满了vda这个盘了,end到6079,最多就6080,所以在原始的系统盘中,无法继续分区,需要扩容才可以

起始扇区:默认是2048
结束扇区:可以指定扇区或者是size(大小),一般填M或者G,这里填+10G
完成分配

一步步创建,会发现MBR最多只支持4个分区,包括3个主分区(primary)和1个扩展分区(extended),其中扩展分区用完了剩余的容量
在扩展分区内,可以继续分逻辑分区(logical),在扩展分区下面的都是逻辑分区

GPT分区:****管理大于2T的硬盘
当我们创建了大于2T的硬盘的时候,因为MBR分区最大支持2T的分区,所以如果在原始3T的硬盘上创建大于2T的分区,就会报错,而且最多支持4个分区
一开始的3T硬盘都是dos(MBR分区类型)

需要进行以下磁盘分区类型的转化,使用parted进行分区类型的转化
parted /dev/vdc

mklabel /dev/vdc:输入新的分区类型type---gpt分区格式,然后清除整个盘的数据,格式化成GPT分区(类似windows)
q退出

再用fdisk /dev/vdc来创建gpt硬盘内新的分区,可以创建最多128个主分区

现在可以创建一个2.5T的分区了,可以创建文件系统ext4并且挂载到指定的目录

mkfs.ext4 /dev/vdc1
mount /dev/vdc1 /mnt/vdc

文件系统filesystem
有了文件系统,才能使用、创建文件
挂载:
一个设备可以挂载到多个挂载点,多个挂载点内的东西都可以归属于这个盘(设备)
一个挂载点不能挂载多个设备
mount:挂载文件系统
umount:卸载文件系统
fuser -v /mnt/mount:查看这个目录(文件系统)谁在使用,会出现一个PID(进程ID)
查看进程:ps -aux
显示所有包含其他使用者的进程,显示的较详细,包括PID之类的

ps aux与ps ef的区别:
1.都可以显示进程id和执行的cmd(执行的程序所需要的cmd)
2.ps aux可以显示这个进程占用的CPU和MEM
3.都可以显示TTY(哪个用户在用)---whoami
一般来说,用ps aux会比较频繁一点
永久挂载,开机启动:/etc/fstab
一般写0就行,这里的数字表示开机的时候是否需要监测修复文件系统
0表示不检测,1表示检测分区1,2表示检测完分区1在检测分区2

mount -a:重新装载/etc/fstab里面的所有配置
注意:如果是/etc/fstab文件的磁盘UUID写错了,会造成机器无法重启的现象,需要进入到emergency mode(紧急模式),写好fstab或者注释掉那个磁盘,才可以正常使用
ext4:最常用的文件系统,功能丰富,成熟的技术
xfs:存放的文件答,最大8EB
df -Th可以查看分区的文件系统

创建文件系统:mkfs.ext4 /dev/vdb
mkfs -t ext4 /dev/vdb
查看分区的文件系统:blkid
UUID其实是硬盘的ID号

文件系统的块大小:1024字节,即使是一个文件(小文件)也要分配那么大的磁盘空间,1k的磁盘空间
一般常用:4k的块
du -h:查看目录占用的块大小(占用磁盘的),查看目录大小
du -h --max-depth=1:目录深度为1

ls -lh:查看文件/目录的实际大小,不包括子目录

df -h:查看磁盘大小,文件系统大小
df -Th:显示文件系统类型type
**dd:生成大文件,全0文件
/dev/mem:内存设备
基本格式:
dd if=/dev/zero(输入文件名) of=/tmp/file(输出文件名) bs:输入/输出的块大小,一个快
count:拷贝blocks的个数 seek:跳过N个块后开始复制
dd if=/dev/zero of=/tmp/file bs=1M count=10 seek=1024---》复制10M的文件
if=输入源 of=输出源
可用于拷贝整个硬盘的数据到某个文件上
dd if=/dev/vda of=/root/backup
磁盘对磁盘拷贝
dd if=/dev/vda of=/dev/vdb
将文件恢复到指定盘,这个backup应该是个磁盘备份文件
dd if=/root/backup of=/dev/vda
/dev/zero:全0的空设备,也属于设备/dev文件,可用于初始化设备/文件
/dev/null:无底洞,可用于吸收标准输入(1或者2)
模拟写满数据:直接爆满,修复分区(文件系统)
写1M的0数据
dd if=/dev/zero of=/dev/vdb bs=1M count=1

没得写文件了

修复顺序:
1.卸载磁盘:umount /dev/vdb1
2.e2fsck修复磁盘:e2fsck /dev/vdb1 -y(全部yes)
如果出现target is busy咋办?
退出目录,重新卸载

一直yes,完成修复

xfs文件系统:xfs_repair
dd写入具体文件大小,测试硬盘读写速度
一个块大小是1M,一共生成700个块,也就是700M的空数据文件(全0)
dd if=/dev/zero of=/mnt/mount/test.txt bs=1M count=700

可以用于磁盘性能写入测试,高IO的盘,写入的性能约为172MB/S,简单测试写入性能

在文件正在被访问的时候,去删除这个大文件无法立即释放磁盘空间,需要退出文件编辑后,才释放磁盘空间
du -h:查看目录的大小
df -h:查看硬盘的大小
ls -lh:查看目录下文件+目录的大小
RAID类型
冗余磁盘阵列,有时候物理服务器上有物理的RAID卡
RAID 0:一起处理读写请求,读写速度快,但没有冗余,数据分别写到两个盘中,至少1块盘
RAID 1:有冗余容灾,但是写请求比RAID 0差一点,读性能比较好,磁盘利用率低(一份数据双写),一般用于系统盘(冗余),至少两块盘
磁盘利用率:50%
只可以预防机器层面的磁盘损坏,不能预防认为的磁盘损坏
RAID 5:生产中用的比较普遍,一般用于数据盘,有冗余能力,至少3块盘,有校验位,大概可用空间为n-1/n,即多少快盘,就-1就是利用率
3/4,2/3等
RAID 10:读写能力强,有冗余能力,但是成本比较高,至少4块盘,磁盘利用率:50%
LVM逻辑卷
Cent OS 7需要安装lvm2安装包,
一般分为几个概念:
1.Linux的卷设备,可以是盘内普通的分区,也可以是不同的盘组成
2.多个设备组成物理卷
3.物理卷创建卷组
4.从卷组中划分出LVM逻辑卷,逻辑卷内可以创建文件系统使用,格式化等

创建步骤:
1.已有硬盘,创建好若干个主分区,有容量
2.fdisk /dev/vdb,t转换分区类型,8e(LVM逻辑卷类型),输入分区号(3和4),w保存写入

3.创建物理卷:pvcreate /dev/vdb{3,4}
pvs:查看物理卷

4.创建卷组:vgcreate vdb_vg /dev/vdb{3,4}

vgs:查看vg卷组的情况,vdb3是3G,vdb4是11G,加起来14G,最大不能超过14G

5.创建逻辑卷
lvcreate -L:大小
-n:逻辑卷名
vdb_vg:卷组名
lvcreate -L 1G -n vdb_lvm1 vdb_vg

在lsblk中可以看到这个lvm卷,大小为1G

一个lvm卷的完整路径:/dev/卷组名/LVM名
/dev/vdb_vg/vdb_lvm1
mkfs.ext4 /dev/vdb_vg/vdb_lvm1:给这个LVM创建文件系统
写入到自启动硬盘
blkid查看UUID
vim /etc/fstab,编辑UUID
创建目录:mkdir /mnt/lvm1
挂载:mount -a
可用907M

LVM卷的扩容
在加好新磁盘后,可以执行scandisk来查看磁盘,不过云服务器加完后,都是默认加好的
scandisk:扫描,发现新硬盘
需要看所在的卷组还有空间没:vgs,如果卷组没空间的话,可以加入新的硬盘设备(分区)来扩容卷组
先将设备创建新分区,转换为LVM格式(t),创建pv(pvcreate /dev/sdb2)
vgextend vdb_vg /dev/sdb2
卷组有空间就可以继续扩容逻辑卷了
lvextend -r -L +1G /dev/vdb_vg/vdb_lvm1
-r表示:resize2fs,重置文件系统的空间,专门用于ext4的扩容,扩容硬盘也是一样的道理,最后也需要执行resize2fs
-L:扩容的磁盘空间大小+1G,后面跟卷名(完整路径)
LVM卷的缩容(一般不用),云服务器不可以缩容,只能扩容。因为硬盘已经写了数据块了,再缩容会破坏数据
lvreduce -L 5G -r /dev/vdb_vg/vdb_lvm1
xfs的逻辑卷不支持缩容
LVM逻辑卷的快照:能够保留快找对象最原始的数据(修改之前)
lvconvert可以将快照卷恢复到原有的卷
LVM卷数据的复制与备份
场景:现在有一个磁盘上面的LVM卷,但是这个磁盘差不多坏了,需要转移数据怎么办?
卷组:10G,LVM卷8G,数据存在于LVM卷上
步骤:
1.新加一块磁盘(分区)到该vg中,确保这个卷组至少有10G的空闲空间来存放这个需要移除的硬盘
scandisk:扫描硬盘,发现硬盘
创建分区,转化(t),创建pv,将这个pv(10G)加入到该卷组中
2.pvmove(移动) /dev/sdc(被移除的pv),将这个sdc的空间移动到其他空间上面去(/dev/sdd)
3.在卷组中删除这个pv:vgreduce vdb_vg /dev/sdc
4.删除这个pv:pvremove /dev/sdc,删除这个分区了
倒序操作删除LVM逻辑卷
lvremove /dev/vdb_vg/vdb_lvm1:删除逻辑卷
vgremove vdb_vg:删除卷组
pvremove /dev/vdb{3,4}:删除pv
Cent OS/Ubuntu软件管理
不同类型的操作系统,使用程序二进制不一样
API:指的是一组功能的应用程序,提供标准的接口进行调用,例如图形处理、加密算法、地图等功能,开放API接口,例如美团等APP就可以调用例如地图的API,直接使用
直接调用开发好的程序功能
application progranmming interface:程序接口
POSIX:可移植的接口,代码可以直接移植
Linux中的lib库:用于给到命令/指令/程序去调用对应的功能
lib库都是共享的,每个程序/命令都可以调用,lib库一般不能删除,删除后会损失lib库依赖,损失依赖库

gcc:c语言编译器,后续安装nginx需要用到gcc编译器
rpm包:系统帮你编译好的安装包,直接安装即可,rpm包其实是一个打包好的文件
redhat package manager:红帽的包管理软件
公共依赖库:/var/lib/rpm
EPEL:红帽的第三方组织,EPEL源,根据不同的Linux内核版本获取不同的EPEL包
可以去第三方的EPEL源下载rpm包
EL7、EL8、EL9代表不同的Linux内核版本
rpm管理和yum安装
自己制作RPM包:rpmbuild
安装rpm包:rpm -ivh xxx.rpm,一般来说都是这么安装rpm包
rpm -i:install安装
-v:output install,显示安装过程,显示更多细节,其实rpm -i就完事了
-h:显示安装过程
终归的安装rpm包,yum安装的方式也是安装的rpm包
为什么不用rpm直接安装?因为rpm安装的话装不上依赖包
rpm -qa:显示所有安装好的rpm包
rpm -q httpd:查询httpd包是否安装
yum -y install httpd:安装这个程序,首先需要安装rpm包,其实这个是安装对应的rpm包,yum的功能

我用yum list | grep httpd这个其实也是查看可安装的rpm包,在配置好的yum源内查看可安装的rpm包。

rpm -Uvh:更新rpm包
rpm -qa --last | head -n 5:最近安装的前10个包,--last
rpm -e:卸载,rpm -e+rpm包名,卸载一个rpm包
rpm -q:显示这个包是否被安装了
rpm -qi:显示这个包的详细信息
rpm -ql:显示这个包内的文件
yum provides mkpasswd:查看mkpasswd这个安装命令是从哪来的
rpm -e lvm2release-rpm包
像一些release的rpm包,一般指的是rpm包的合集,里面包括很多个rpm包
rpm -e mysql-5.6-release-rpm:卸载MySQL的安装包
wget https://hcie-lab-2020.obs.cn-north-4.myhuaweicloud.com/mysql-community-release-el7-5.noarch.rpm
像我在华为云拉的mysql-release-rpm包,这个rpm包内包括以下几个rpm包,所以说release包是合集

yum/dnf安装:是C/S的模式,S就是本地的yum源或者是yum仓库
yum仓库内:已经安装好了各种的rpm包+rpm包的元数据(metadata)
yum仓库:其实就是.repo后缀的文件,yum源,一个repo就是一个yum仓库

路径:/etc/yum.repos.d/xxx.repo
yum.repo:yum源文件路径

name=yum源的名称,描述
baseurl:一般来源于本地或者是网络,华为云/阿里云的机器一般来源于云上的yum源(Cent OS),支持file://,http/https路径
阿里云/腾讯云baseurl:
https://mirrors.aliyun.com/centos/$releasever/Everything/$basearch
https://repo.huaweicloud.com/centos/$releasever/Everything/$basearch
https://mirrors.cloud.tencent.com/centos/$releasever/Everything/$basearch
enabled:不写默认1,启用仓库,enabled=0表示禁用仓库
gpgcheck:检查包是否合法,=1表示检查,也可以写成0代表不检查;之前在安装php还是什么时候,他检查安装包是否合法,可以关掉,类似windows检查合法性
gpgkey=file路径,需要和gpgcheck配合使用,这里的file:///etc/pki/rpm-gpg/RPM-GPG-KEY-Cent OS 7其实是下载好到本地的,如果是用网路上的,就用https就行
找到镜像源,找到这个gpgkey的文件(对应Cent OS版本)---基本都是这个校验,无论是base还是epel
fill://:表示本地硬盘路径
https://mirrors.aliyun.com/epel/RPM-GPG-KEY-EPEL-7
$releasever:当前OS发行的版本,如8,7,6,mysql5.6-release.rpm估计也是这个意思
$basearch:系统基础架构,一般都是x86_64的架构
自己写的一个简单的epel源(扩展包)
分为基础包(base)和扩展包(epel),gpgkey一般是本地的
最主要就是baseurl的来源
[BaseOS]
name=centos repo
baseurl=https://mirrors.aliyun.com/centos/$releasever/os/$basearch
https://repo.huaweicloud.com/centos/$releasever/os/$basearch
https://mirrors.cloud.tencent.com/centos/$releasever/os/$basearch
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
[epel]
name=epel repo
baseurl=https://mirrors.aliyun.com/epel/$releasever/$basearch
https://repo.huaweicloud.com/epel/$releasever/$basearch
https://mirrors.cloud.tencent.com/epel/$releasever/$basearch
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
最简单的yum源模式
[yum源名字]
1.baseurl
2.gpgcheck=0:不检查
Cent OS 7最简单的:base仓库,写个baseurl就完事
配epel仓库,也是在云上找yum源
重要的yum源文件有:
1.Cent OS-Base.repo:基础yum源文件
2.epel.repo:扩展rpm包的yum仓库EPEL
3.其他软件的yum源,可以自行安装
列出系统所有的yum源:repolist
yum安装程序的时候,会在这里自动找到包

yum安装软件失败以及解决办法
yum repolist:查看已经配置好了的yum源,status有显示才算有
yum list xxx:查看xxx软件的安装包是否存在(在yum源里面找)
yum源配置错误:
1.yum源配置文件写错,检查配置文件
2.元数据过旧了,需要清理一下缓存,yum clean all;构建新的缓存:yum makecached---从你的baseurl上下载新的缓存
3.yum源有问题,网络有问题,无法访问到公网,可以先下载好rpm包传过去
yum history:查看yum安装的历史
netstat与ss的区别:netstat能够显示命令,服务名称+端口号
ss -ntl更加轻量级,更容易使用,消耗资源更少
搭建yum私有仓库(7版本、8版本)
Cent OS 7版本的base yum源:BaseOS
Cent OS 8版本的base yun源:BaseOS、Appstream
1.在yum服务器上面搭建httpd服务,启动http服务,测试访问
yum -y install httpd
systemctl enabled httpd
systemctl start httpd
2.配置好yum服务器的yum源,看需要哪些yum源,BaseOS/epel/extras,测试yum源配置
yum clean all
yum repolist
[extras]
name=Extras
baseurl=https://repo.huaweicloud.com/centos/$releasever/extras/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
3.从网络yum源上拉取对应的rpm包到/var/www/html目录下,需要加上--download-metadata来实现拉取元数据,没有元数据rpm包是无法安装的
##Cent OS7搭建方法
reposync --repoid=extras --download-metadata -p /var/www/html/extras
##Cent OS8配置方法
yum reposync --repoid=extras --download-metadata -p /var/www/html/extras
4.配置客户端的yum源,指向yum服务器的rpm包路径
注意:repoid和baseurl的名字一定要写对,不然找不到的
[extras]
name=extra
baseurl=http://192.168.244.128/extras
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
5.从yum客户端安装一个来自extras的包,安装完成
WALinuxAgent这个包就是来自我现在的extras源,这个源的yum服务器就是192.168.244.128这个服务器的http分享,因为http服务器默认的路径就是/var/www/html,所以只需要在后面加yum源的目录就行

源码编译
以编译安装nginx源码为例
1.下载nginx软件包:wget -P /app/nginx https://xxx/nginx.1.18.0.tar.gz
2.解压Nginx包:tar xf nginx.tar.gz
3.进入到nginx目录,编译选项:./configure --prefix=安装路径(/usr/local)--ssl=enable(开启ssl加密模式)
4.make && make install安装
5.启动Nginx:cd /usr/local/nginx/sbin/nginx,加入到自启动
**
expect自动化交互式命令
mkpasswd随机生成密码(可指定位数)
yum -y install expect
mkpasswd:生成随机9位字符,可用于生成随机密码(包括字符,下划线,数字,大小写字母等)

yum provides mkpasswd:查看这个指令的来源
来源于expect这个包

mkpasswd -l 20:指定随机文本为20位
[root@ecs-web01 2use]#mkpasswd -l 20
dwj7hqlf6grMIxgxh}cl
-c:指定小写字母位数
-C:指定大写字母位数
mkpasswd -l 20 -c 5 -C 5

和这个随机密码有点类似,但不一样
这个是将除了大小写字母/数字的其他字符全部转换成这些,并且输出前16个字符(随机)
cat /dev/urandom | tr -dc [:alnum:] | head -c 16
[root@ecs-web01 2use] cat /dev/urandom | tr -dc [:alnum:] | head -c 16
ZwMw6nDgUaWlmdSi
expect基础指令
【要点】ssh和scp的区别,加端口号的参数不同
ssh -p 1258
scp -P 1258
expect脚本语言:是一种独立于shell的脚本语言,解释器为#!/usr/bin/expectj
expect:交互式指令
spawn:启动新的进程,通常都是command命令,这个命令执行就会产生一个新的进程
expect:从进程中获取字符串,如果匹配到需要匹配的字符串,则输出对应的字符串
send:如果expect接收匹配到指令,则send某一段字符串(yes/no password)
interact:允许用户交互
exp_continue:匹配多个字符串后执行命令
【案例】自动复制,自动交互(输入yes+password)
其实这个可以直接复ssh凭证到目的主机,就不用交互了
ssh-keygen
ssh-copy-id -P 1258 root@139.9.57.240,确认ssh凭证就行了
##前面写好解释器
#!/usr/bin/expect
spawn scp -P 1258 /etc/redhat-release root@139.9.57.240:/root
expect {
"yes/no" { send "yes\n"; exp_continue }
"password" { send "Caiwj@1258!\n" }
}
【案例】在shell内调用expect,实现远程登录到某一台主机并且创建用户
一般的expect格式如下
#!/bin/bash
pass="123"
cd /root
for i in {132..133};do
expect <<EOF
spawn scp -r .ssh root@192.168.244.$i:/root
expect {
"yes/no" { send "yes\n"; exp_continue }
"password" { send "$pass\n" }
}
expect eof
EOF
if [ $? -eq 0 ];then
echo "host 192.168.244.$i send success"
fi
done
将crontab修改为vim风格
进程与内存
进程ID:会产生一个唯一的PID,是临时分配的,进程结束后就会回收
还会产生UID(user ID),GIP(group ID),对文件系统的读取
/proc:进程目录,里面存的都是进程的相关文件属性,包含各个进程的ID,一个ID代表一个目录文件夹

进程的产生:包括父进程
pstree -p:查看父进程和子进程包括更下一级的进程

进程与线程
一个进程会单独占用一块内存空间(估计不大)
进程内又会有线程,表示这个进程在系统内的多个线程(员工),用于生产
一个进程里,至少有一个线程,线程就是工作的实体

多线程处理任务(常见)
【面】查看某个程序在运行的时候是否是多线程工作?
pstree -p

java这个代表子进程下有多线程在工作,不一定直接是父进程,java的父进程就是wrapper
{括号内}的就是多线程

【面】如何看某个进程来自哪里(执行命令CMD)
/proc下每个进程ID对应有目录,比如我进到1的目录下,有这么多文件,其中exe文件就是代表运行的执行程序

查看exe这个执行程序是什么CMD:是个l(链接文件),负责某个命令的连接,链接到类似/usr/bin下面的某个执行文件CMD

像我现在查看pstree -p,php-fpm这个程序(php的进程管理程序管理cgi的)进程ID为654,在/proc下找到这个exe,对应就是sbin的php-fpm

有病毒的话,就删除掉这个目录下的执行文件,复制一个新的过来,或者定期找备份恢复(最好是定期备份),不然生产数据很麻烦的
并行与并发
并行:指的是CPU处理任务的时候,并行执行这个任务,有多个时间片
--->跟CPU的核数有关
并发:指的是网站再同一个时间有多少并发(请求量),都是作为一个服务器系统的性能指标,一般指CPU和内存、带宽的承受量
也是压测的基本指标之一
在1s内有多少外部请求过来--->并发性能
多线程多进程访问这个程序:需要加锁lock
分配给一个程序:至少是4K的块大小(block)
查看某个进程的利用率:top或者是ps aux都可以
ps -ef一般显示的就是UID
ps -aux显示的是USER,其实差不多,但是ps -aux还可以显示出CPU和内存的占用率,比较好用,包括所有ps -ef的信息


内存使用与占用
内存使用空间分为:用户态和内核态,用户空间+内核空间
一部分空间给到内核使用(例如4G的内存,1/4给到内核使用),一部分给到用户的应用程序使用

内存泄漏:malloc分配了一定空间的内容,比如10M,但是没去占用,又不释放
内存溢出:分配了10M的空间,但是你的进程占用超过了10M,则会占用其他人的内容空间
内存不足:OOM,out of memory
java程序:占用程序内存过多
磁盘内的文件需要被访问:一定要加载到内存中才能被访问
比如说我这个执行命令/usr/sbin/php-fpm,当我执行的时候,就在进程内看到了

父进程654,就是所有php以及其子进程都是依赖systemd(1)-php-fpm(654)

相当于这个就是存在磁盘内的文件,现在被加载到内容中运行了,PID为654

内存进程状态STAT
运行:running
就绪:ready
睡眠:interruptable(可打断),uninterrupt(不可打断),可被唤醒
停止:stopped,停止了不可被唤醒,除非手动启动调度
僵尸态:zombie,父进程结束前,子进程不关闭,会出现Z状态(解决办法:杀掉父进程)
pstree -p | grep sshd
sshd1330是父进程,证明现在这台机器正在被sshd远程连接,下面的都是子进程

机器内其实大部分的进程都是SS(sleeping),可被唤醒的;正常在RUNNING的进程还是看CPU的核数和线程数的
Running也就一个,比如正在执行的命令command
ps -aux | awk -F" " '{print $8}' | sort | uniq -c | sort -nr

【案例:处理Z僵尸态】
原理:父进程结束被杀死前(可以是停止),子进程如果结束了,就会出现Z状态(即子进程虽然被杀死了,仍然是Z状态存在)
目前我在ssh上执行tail -f /var/log/message,一直在输出日志,tail子进程的父进程是bash16602

目前状态是S(sleep可被唤醒)

停止父进程,看子进程tail状态stat
kill -19 16602,父进程状态变为T(STOP)了

杀死子进程,变为僵尸态了
kill -9 13790

恢复办法:continue父进程bash,会彻底结束掉子进程(结束掉Z状态),子进程tail没了
kill -18 16602

显示被kill掉了,现在才是真的被杀死了

kill -L:查看处理进程的信号
一般常用的有
kill -9 PID:杀死这个进程,SIGKILL
kill -19 PID:停止这个进程
kill -18 PID:continue继续这个进程

终止进程相关:
kill -15 PID:普通终止进程,不危险,-15是默认参数,可以不写
kill -9:危险参数,强制结束进程
kill -1 +pid:重新加载配置文件(非常常用)
需要找到对应服务的主进程
重新加载配置文件,比如说写好了nginx的配置文件nginx.conf文件,为了不让服务重启从而影响业务,可以使用kill -1 nginx.pid来实现
ps aux | grep nginx:查看nginx进程的pid

nginx监听端口为8080,我现在修改nginx.conf文件为8081

Nginx的服务端口修改为8081了

访问web页面也成功了

kill -0+pid/killall -0 +服务:监控程序/进程的运行状态(常用监控服务脚本)
kill -0 +pid:监控某个进程的健康,如果不健康,则$?返回1,健康返回0
killall -1 +服务名称:监控服务是否正常,是否处于error状态,无异常返回0,有异常返回1
比如我要监控nginx进程(程序)状态是否健康
killall -0 nginx
echo $? --->0,无返回信息,表示健康
killall -0 nginx
nginx:no such process--->有返回信息,表示没有此进程/服务
echo $? --->1

重启服务就好了
##可以配置到定时任务,比如每5min执行一次
svc=nginx
killall -0 $svc &> /dev/null
if [ $? -eq 0 ];then
echo "$svc正常"
else
systemctl restart $svc
echo "$svc重启成功"
systemctl status $svc
fi
缓存算法:LRU算法
新加入的数据,会挤掉旧数据;经常被访问的数据,会放在内存的前面(缓存的地方),每个机器都会有缓存cache


共享内存:有一个或者多个APP共享这一块内存

socket:套接字,IP地址+端口号
消息队列:实现不同进程之间的互相访问
rabbit MQ,kafka,activeMQ
消息缓冲区,服务器系统一下子接受不了这么大的访问请求,需要进入缓冲区,一个个处理,而不是直接上到系统中,那系统会直接崩溃
日志系统ELK,帮助缓存日志消息
查看服务器性能工具
pstree -p:查看进程+线程,查看父进程以及进程PID
查看PID,两个都行
凡是top命令,都是查看进程(有哪个进程在交互),包括iftop(网卡交互),iotop(磁盘IO占用进程),top(CPU、内存)占用
凡是stat命令:都是看状态的,没有top系列显示的那么全,vmstat(显示内存的交互in/out),iostat(显示磁盘的io,可以显示每一块磁盘)
ps:查看进程状态|axo(不是aox),aux常用
其实aux是另一种风格的ps使用方法
a:显示所有在终端上的进程
u:显示所有者
x:包括不链接终端的
ps aux

-e:相当于-a,显示所有
-f:显示完整的程序信息
ps -ef看起来比较简单,没有CPU+MEM的占用率

ps axo pid.cmd.%cpu,%mem:显示指定的列,0表示指定列,这里是显示pid,cmd(命令)
,cpu利用率,内存利用率

按照cpu/内存的占用率正序/倒序排序
##倒序排序
ps axo pid,%cpu,%mem,stat,cmd --sort -%mem
##正序排序
ps axo pid,%cpu,%mem,stat,cmd --sort %mem

##按照cpu的占用大小倒序排序(常用)
ps axo pid,%cpu,%mem,cmd k -%cpu
##按照cpu的占用大小正序排序(常用)
ps axo pid,%cpu,%mem,cmd k %cpu

写脚本最好是加#!/bin/bash蛇棒机制,不然会看不到pid进程编号的
pidof java
uptime:查看系统启动时间+负载情况(面)
w命令:包含uptime命令
uptime
load average:每1min,5min,15min(面试常考),CPU的负载情况

负载如果超过5,就会变得很慢很卡
无论是1min还是5min还是15min都一样,无论多少核的CPU,都是一样的,查看CPU的负载

top:实时显示资源的利用率,负载等
top命令的第一行:也是uptime负载情况,系统时间,登陆的user,updays,1min 5min 15min内的负载情况
tasks:显示进程的状态,total数量,running数量,sleep(休眠建成永恒)数量,停止的数量(stopped),zombie(僵尸态)
%cpu:us(user用户空间),sy(内核空间占比),id(空闲cpu占比)进程优先级等,磁盘iowait(iowait越高,磁盘等待越久,性能越差)
KiB MEM:物理内存总数(total),free(剩余),used(已使用),cache(缓存)
交换分区swap
然后就是ps aux的显示,还显示每个进程的状态STAT,VIRT(申请的虚拟内存),RES(实际物理内存)

快捷键
P:按CPU占用大小排序
M:按内存占用大小排序
1:按照每一颗CPU来显示,会分CPU0,CPU1等等
free -h:查看内存
普通的
缓存cache:用于程序(磁盘文件)在执行的时候先放入缓存,如果调用则直接调用缓存,提高效率
存放的都是打开的文件,所以一般都不清除缓存,因为能够提高效率,先写到缓存区,方便读取,cache非常有用!
我用dd生成了一个300MB的文件写入到磁盘内,缓存空间瞬间占用了300M,证明下次系统还调用该文件的时候,会直接从缓存中调用

删除掉这个文件后,缓存空间又回来了,证明文件不存在,也从缓存空间中清除了

buff:缓冲区,指的是文件修改,落盘的操作,多个落盘操作合成一个(多人过马路),提高磁盘IO效率---写缓存
cache:缓存区,文件放在cache内,被访问时候不用去磁盘调用,系统调效率提高(相反作用)---读缓存
buff/cache:一共占用的空间
vmstat:显示内存的状态为主

procs:进程,running2个
内存占用信息
交换分区
磁盘IO
vmstat 1:1s显示一次状态,实时变化,用于监控各项指标(内存,进程,交换分区---一般是禁用,cpu内核空间,用户占用,空闲时间等)
表示swap分区的进出(写进内存,出内存),磁盘io的进出(写进内存、写出内存---出)
内存不够用的时候才会写进swap内,一般来说swap都是不起用(云服务器)

写入磁盘例子
dd if=/dev/zero of=/tmp/fi.png bs=1M count=3000
现在的bi是很低的,试试写入到磁盘,写入磁盘的状态是bo(out),证明是从内存中往磁盘写,以内存作为基准,磁盘生成文件的时候先写入到内存,内存到落盘就代表出内存

##读取磁盘文件内容到null下,直接全部为0
dd if=/dev/vda of=/dev/null
这个证明了从磁盘中读写进内存,是in内存的动作,所以是bi in的动作,以内存作为判断基准

iostat:显示CPU和硬盘状态为主
显示内核,系统日期,系统架构,核数
CPU的状态:用户程序占用,内核占用,磁盘的iowait,cpu空闲率
显示硬盘的读写(实时读写状态)

iostat 1: 1s显示一次,同样可以用上面两条命令来测试,这次就是真的针对硬盘的读写了
##写一个全0的空文件到/tmp目录下,3G的文件
dd if=/dev/zero of=/tmp/fi.png bs=1M count=3000
##读取磁盘文件内容到null下,直接全部为0
dd if=/dev/vda of=/dev/null
写速度大幅增加,约为107M/s

##查看全0文件
cat /tmp/f1.png

iotop:查看进程占用的磁盘IO
先要安装iotop包
yum -y install iotop
显示实时的磁盘read和write,类似top

##写一个全0的空文件到/tmp目录下,3G的文件
dd if=/dev/zero of=/tmp/fi.png bs=1M count=3000
发现是dd这个命令---这个进程占用的磁盘写速度最大,达到了182M/s

iftop:查看网卡的流量交互(与主机)
100.125开头的是华为云的DNS,和DNS服务器交互比较多,目前没有什么外部流量
查看网卡的吞吐量

##ping包直接拉满
ping -f -s 65507 192.168.0.3
nload:查看实时的网络吞吐收到网络攻击的时候,会实时显示现在的网络(吞吐量),显示最大值和平均值,包括inbound和outbound(进方向)和出方向
一旦停止ping,就会降低很多

lsof:查看某个文件/端口是哪个指令打开的(CMD)
关键参数:
-i + :1258:显示1258端口是哪个程序打开的,显示的是SSH端口打开的,并且是从113.88.214.1这个IP访问过来的

执行tail -f /var/log/messages
lsof /var/log/messages:可以看到这个文件正在被哪个命令所访问,目前在被tail -f命令访问,表示命令行内持续更新新的日志

pidof:看目前进程中的pid
pidof nginx:查看nginx服务的所有pid号

--color:自动着色的,不用管
真正看还得是ps aux | grep nginx

并行任务与后台任务{}&
有时候一些任务的执行(.sh脚本)会消耗比较多的时间,比如我要批量ping局域网内存活的主机(后续可能不止1个254的网段,可能是成千上万个主机的up/down)
可以借助{}&,并行执行命令
local NET=192.168.0
for i in {1..254};do
##ping1次,等待1s,没回应就下一个
##这里加个{}&,表示并行执行该任务
{
if [ ping -c 1 -w 1 $NET.$i &> /dev/null ];then
echo "$NET.$i is success"
else
echo "$NET.$i is down"
fi
}&
done
##这里表示结束ping状态,不然会退出不了
wait
定时任务crontab
最细致:分钟级别
时间的基本写法:5个点的时间关系--->并行的关系,且必须满足每个点的要求,有不匹配的话,按照匹配的那个条目来执行
##每周1 3 5 ##每周周末
* * * * 1,3,5 * * * * 0,7
##每个月1,15,30号执行,而且或者是周末(周六和周日)
* * 1,15,30 * * 0,6 xxx/bin.sh
##前面的分+时就是并行的关系,每天的2点,每隔5min执行一次这个脚本
*/5 2 * * *
##这里不用括号,小时的0分,6-12点的每2小时
0 *6-12/2 * 11 * /app/bin/test.sh

如果想要实现秒级的任务,可以在脚本内写sleep加入循环,比如sleep 5,每5s执行一次,再加到crontab -e内表示在1min内每5s执行一次
依赖于服务crond,一般默认都是启动up running的

这里显示的是enabled的服务,表示服务是开启自启动的

crontab -e:编辑系统内现有的计划任务
crontab -l:显示目前系统内的计划任务

查看计划任务日志:cat /var/log/cron这个日志文件
还可以过滤一下执行的计划任务名称,目前只有一个mysql的定时备份任务

配置EDITOR变量使用vim编辑crontab
进入/etc/profile配置文件内添加EDITOR变量的值=vim
cat >> /etc/profile <<EOF
EDITOR=vim
export EDITOR
EOF
source /etc/profile:使配置文件生效
vim的风格:才能看到任务是否有被注释掉

cron定时任务日志:/var/log/cron
在crontab -e中加上;分号,代表执行多个命令,如果要执行.sh的脚本,记得加上/bin/sh的解释器

查看cron的日志:cat /var/log/cron,可以看到确实是有在执行;如果不写输出的话,就自动发送邮件

可以使用tail -f持续查看cron的日志输出信息,类似查看tomcat的控制台信息catalina.sh
tail -f /var/log/cron

输入mail命令查看,下面有很多每天15点执行的mysqlbk.sh的脚本,定时执行的备份脚本

crontab内的脚本/bash指令执行路径PATH
$PATH变量是bash内的一个执行路径,这个PATH可以写进crontab定时任务的文本里,以后执行脚本就不用

在crontab内写好PATH后,直接写/tmp/test.sh就好了,会自己执行
* * * * * /tmp/test.sh


Cent OS 7的systemd&启动顺序
systemd是Cent OS 7包括8之后的启动pid为1的进程,替代了5、6代的init进程
优势:能够并行的启动服务,唤醒关联的服务,有无依赖关系都可以启动,加快启动速度
systemctl工具:基于systemd原理来实现的,systemd上面每一个模块叫unit,管理不同的资源
systemctl -t --help:查看systemd支持的模块有哪些
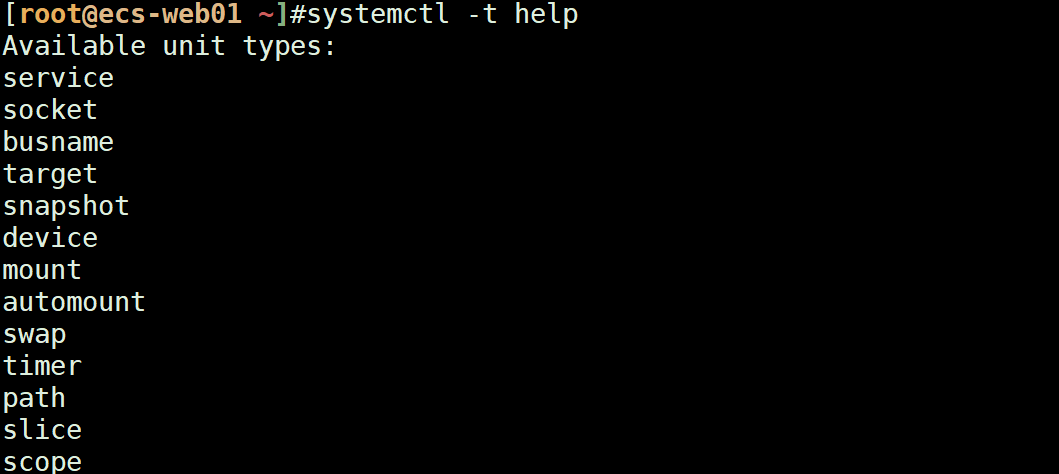
service:服务
socket:IP+端口号
target:0-6的runlevel,执行级别
管理systemd的资源
systemctl status sshd--->全称nginx.service
任何的使用yum安装的服务,都是从/usr/lib/systemd/system内的对应服务.service加载的
写一个service服务,可以写成/lib/systemd这个路径的,反正都是link

/usr/lib/systemd/system ##系统服务管理
/lib/systemd/system ##其实lib是/usr/lib的软连接,最好还是输入,两个路径都ok
/lib/systemd/system ##其实lib是/usr/lib的软连接,最好还是输入,Ubuntu上也是这个路径path
##但是ubuntu

##常见的systemd用法
##操作服务
systemctl start/stop/enbale/restart servcie
##查看服务的service文件:路径/lib/systemd/system/
systemctl cat sshd

unit.service文件格式:服务脚本
unit就是代表了Cent OS 7上面的服务
###写的路径,也可以写在/lib,/lib就是/usr/lib的link
# /usr/lib/systemd/system/nginx.service
[Unit]
Description=The nginx HTTP and reverse proxy server ##服务说明
After=network-online.target remote-fs.target nss-lookup.target ##依赖关系:有网络network,remote远程主机;需要先启动这些服务
Wants=network-online.target ##必须依赖:网络服务
[Service]
Type=forking
PIDFile=/run/nginx.pid
# Nginx will fail to start if /run/nginx.pid already exists but has the wrong
# SELinux context. This might happen when running `nginx -t` from the cmdline.
# https://bugzilla.redhat.com/show_bug.cgi?id=1268621
ExecStartPre=/usr/bin/rm -f /run/nginx.pid ##启动进程,启动前需要做什么--->先删除掉原有的nginx.pid进程
ExecStartPre=/usr/sbin/nginx -t ##检查nginx的配置文件是否有问题:nginx -t--->检查的是nginx.conf,检查语法错误
ExecStart=/usr/sbin/nginx ##执行systemctl start xxx的时候,执行的就/usr/sbin/nginx这个可执行文件,后续如果是源码编译安装想放到systemd执行,可以写成例如/usr/local/nginx/sbin/nginx或者/usr/local/tomcat/bin/startup.sh
ExecReload=/usr/sbin/nginx -s reload ##执行reload,nginx执行文件就是 nginx -s reload
KillSignal=SIGQUIT
TimeoutStopSec=5
KillMode=process
PrivateTmp=true
[Install]
WantedBy=multi-user.target
其实reload和kill -1 服务名类似
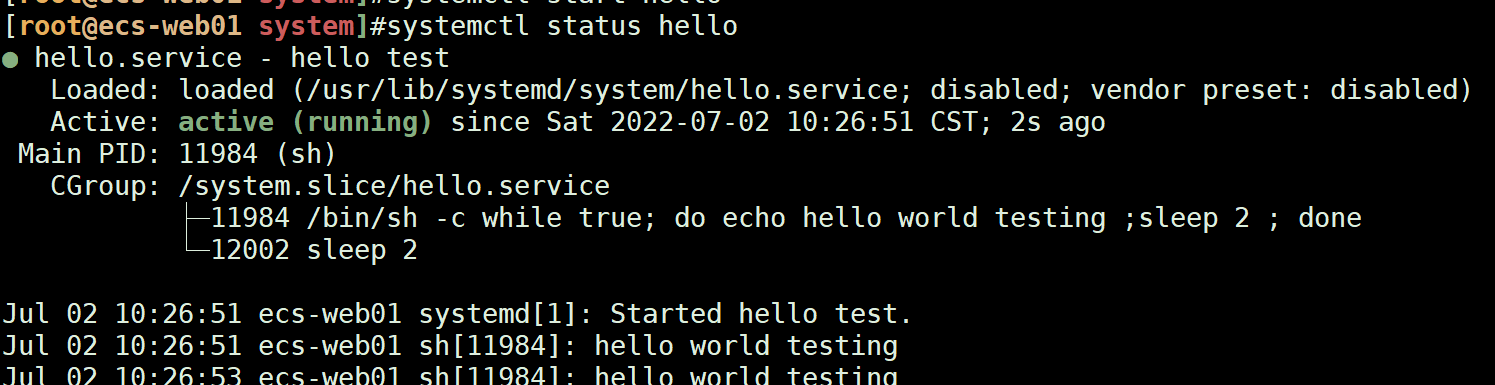
自己写的第一个hello.service
###写的路径,也可以写在/lib,/lib就是/usr/lib的link
# /usr/lib/systemd/system/hello.service
[Unit]
Description=hello test ##描述
[Service]
TimeoutStartSec=0
ExecStart=/bin/sh -c "while true; do echo hello world testing ;sleep 2 ; done" ##死循环执行hello循环
ExecStop=/bin/kill sh
[Install]
WantedBy=multi-user.target
systemctl daemon-reload ##重新装载service服务
systemctl start/status/stop hello
##下面跟着了输出信息,hello world test
指定服务用户执行某个服务:useradd -r -s /sbin/nologin -g group mysql
很多服务都需要指定服务用户执行
##添加一个系统账号,不允许登录(服务账号)
useradd -r -s /sbin/nologin hello
##useradd参数:
-r:建立系统账号,系统账号,系统账号uid是1-999,用户账号是从1000-65530
-s:设置账号不能登录系统,专门是服务账号
[root@ecs-web01 system]#id hello
uid=996(hello) gid=994(hello) groups=994(hello)
##添加到service配置文件内,指定一下服务的运行账户
User=hello
Group=hello
systemctl daemon-reload

是以hello用户再执行的
开机服务自启动:/etc/rc.local
其实/etc/rc.local就是/etc/rc.d/rc.local的link文件,所以直接编辑/etc/rc.local
注意需要给/etc/rc.local写上执行权限:chmod +x /etc/rc.local
touch /var/lock/subsys/local
date + `%F_%T` >> /data/boot.log
target文件:代表和以前一样的init级别,不同级别下执行不同的脚本
一般来说,service文件都是执行在multi-user(多用户)
[Install]
WantedBy=multi-user.target
##默认都是在mutti-user多用户模式
[root@ecs-web01 ~]#systemctl get-default
multi-user.target

Cent OS 7的启动顺序
1.POST自检,选择启动的设备
2.引导系统启动BootLoader--->grub2,Cent OS 7后使用grub2版本
grub 1:前446字节
grub 1.5:找到扇区,加载文件系统驱动,能读取文件系统上的文件grub.cfg
grub 2:进入到/boot/grub2内找到grub.cfg,从而找到内核文件,启动
3.加载驱动,加载内核
4.内核初始化,使用systemd代替之前的init,systemd的pid为1
5.执行.target的所有单元unit,加载单元unit
6.执行默认target级别,默认是multi-user级别(level3)
7.启动multi-user下的所有服务,执行/etc/rc.local(需要+x执行权限)
8.登录到终端
##生成系统启动的文件boot.html
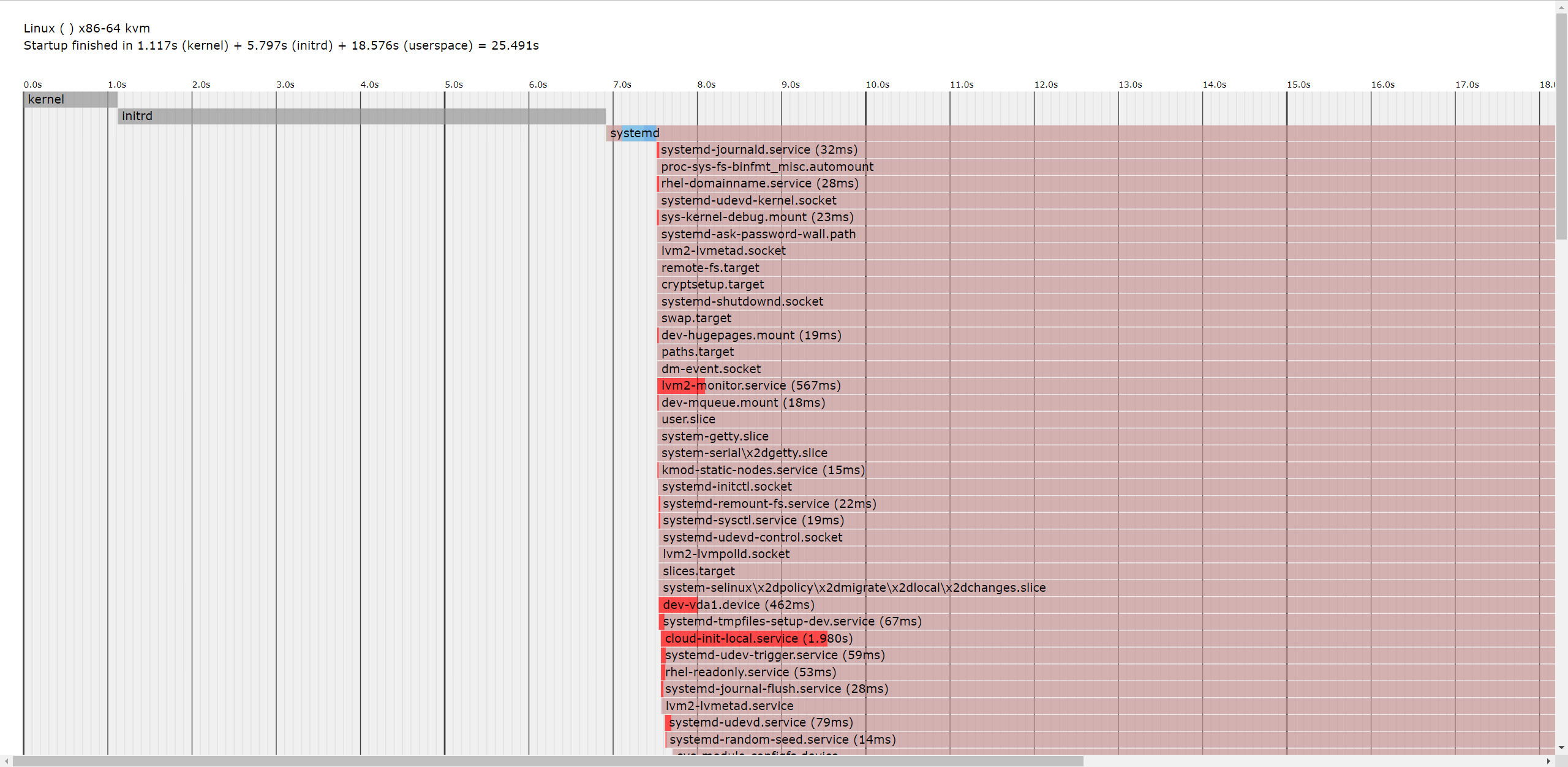
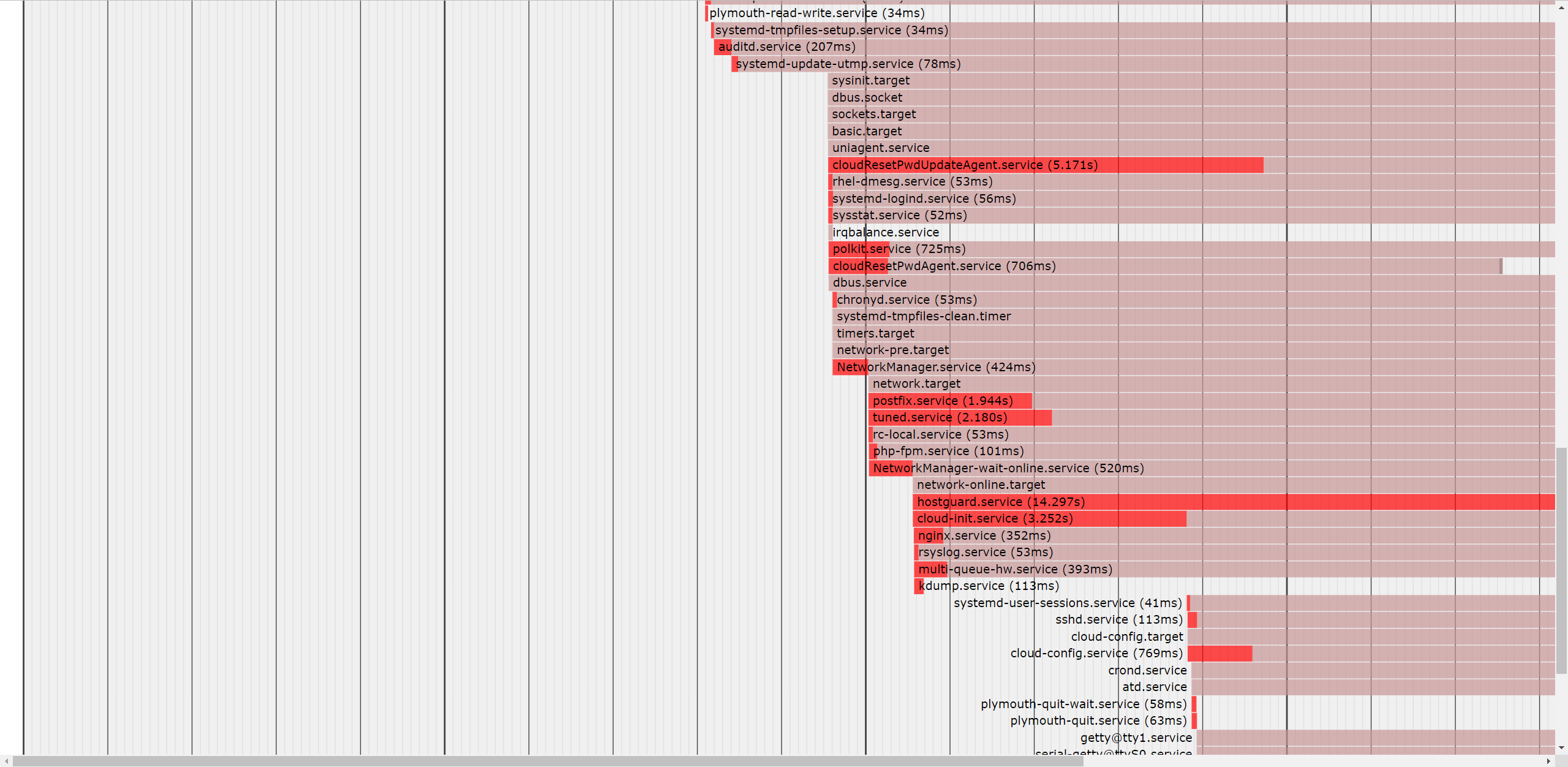
systemd-analyze plot > boot.html
systemd特点:并行启动服务,不需要启动依赖再启动,启动花了25s
Cent OS 7内的grub2.cfg
都是不允许修改这个file,这个是系统的BootLoader引导系统启动的东西,不能修改
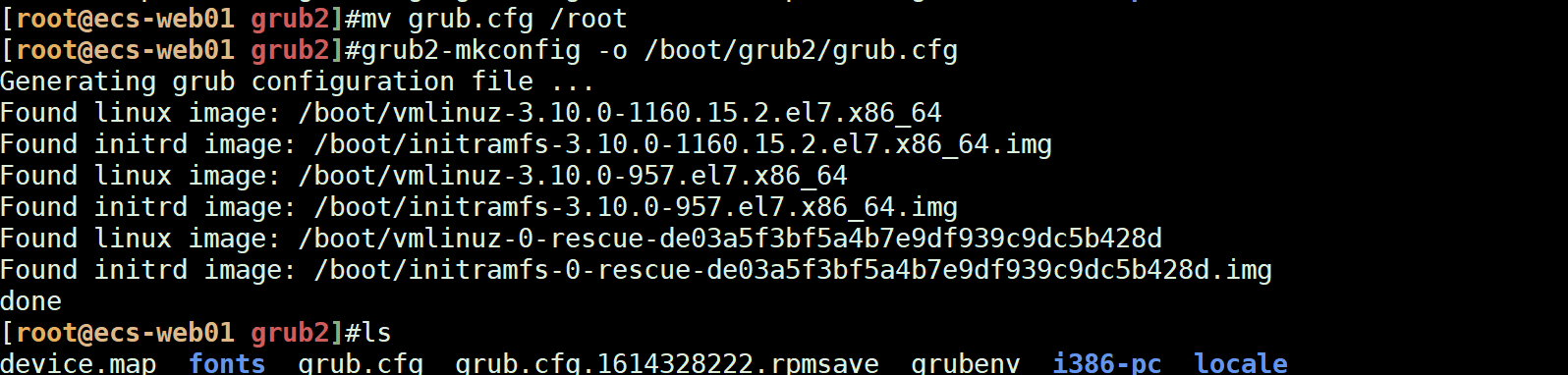
##自动生成grub2.cfg文件
##如果误删除了grub2文件,可以使用mkconfig重新生成gurb.cfg文件
grub2-mkconfig > /boot/grub2/grub.cfg
grub2 -o /boot/grub2/grub.cfg
重新生成grub.cfg编辑文件
常见面试题

bit(小b)和byte(B)的关系:
8位的bit才等于1个B,所以说,计算网速的时候,都是给的100mbps的速度,换算成真实网速(算上网络波动)
100mbps/8=12.5MB/S的速度
网络波动的话,就是100mbps/10=10MB/S的网速,一般能跑到这个网速
操作系统:Cent OS为主,Redhat企业版rhel,Cent OS就是开源版本的Redhat红帽
rocky:也是Redhat的开源版(企业版的开源版)
Linux的原则(哲学思想)
1.一切皆文件(文件存储)
2.使用bash(shell)进行程序的处理
3.命令行界面,处理问题、错误定位快,比windows快很多
运维工程师能力:
1.学习能力强,适应环境能力强,持续不断的学习新的技术和体系、架构
2.谨慎稳定的处理事情能力,逻辑思维思路清晰,分析问题能力
3.与其他岗位的工程师交流能力,共同协助协作能力
Linux文件类型
一共有7种文件类型
ls -alF:显示目录下的所有文件,并且显示它们的作用(使用文件对应的)
-:一般文件
d:目录
p:管道pipe,类似| grep
s:socket套接字
l:链接文件,ln -s软连接,快捷方式
c:字符文件character
b:块设备
批量化修改文件名
rename txt(要改的) txt-test(修改后的) *.txt(目标文件或者多个文件)
rename txt txt-test *.txt

for i in {1..5}
do
mv $i.txt-test $i.txt
echo "$i文件修改完成"
done
shell脚本习题

shell脚本一些小工具
生产案例(面试)
文件与硬盘空间面试题

1.因为该挂载点(该硬盘)的iNodes被占用,占满了。每一个文件(目录)创建的时候都会分配一个iNode(编号),小文件多,意味着inode编号占满了,但是磁盘空间还有很多,导致出现这种情况
解决办法:在挂载点下查看对应的文件,删除文件回收inode编号
2.在rm -f删除无用的文件时,如果文件正在被访问(正在执行),那执行rm -rf xxx.img,不会立即释放掉空间(进程被占用)
方法一:让这个文件停止访问,比如关闭掉SSH窗口,或者正在编辑的话,就:wq退出
方法二:清空文件内容,cat /dev/null > xxx.img,再来删除就可以了
> xxx.img就行
重定向面试题:如何将错误输出和正确输出在一个文件?
&> 1.txt:合并输出
> 1.txt 2>&1:错误的输出到1上,这个不可调换顺序,凋魂顺序就变成先执行错误输出到1,而1在屏幕上显示,所以无法输出到文件中
面试题:取日志文件的格式

追加到文件中,直接查出来追加,连续持续处理
cat 1.txt | awk '{print $2}' | awk -F "." '{print $1}' >> 1.txt
API定义
国际的API规范:POSTX
API定义:指的是这个某一些功能的接口,比如像高德地图提供地图的API,像美团外卖,抖音等APP可以去调用高德地图的API从而实现定位功能,当然调用需要收取一定的费用(版权费)
然后一并集成到自己的APP上,从而实现自己所需要的功能,通过API去调用对应的库

这些叫做网络的开发库
像类似java,python等,你在java、python文件的前面需要什么功能,就import什么功能,调用什么库就可以了
要调用库的时候,需要遵守API的规则

磁盘调优
列出当前目录下所有1级子目录的文件大小(包括隐藏目录.ssh等)
du -h --max-depth=1

也可以以固定的格式输出(单位)
以MB或者KB的格式输出,由此可以看到,最大的目录是根目录,其次是jeesns目录,都有前面输出的大小
du -xB M --max-depth=1 | sort -nr | head -n 5

列出当前文件或者目录最大的10个
du -s * | sort -n | tail

sort -hr:不需要指定固定的输出单位,直接根据GB/MB/KB等单位输出大小
列出jeesns目录的所有子目录以及其大小,并且排序
其中sort -h是按照标准的文件大小输出格式来输出,在排序的时候按照du -h输出的文件大小来排序,而不用切换成统一的单位,便于阅读
du -h jeesns/ | sort -hr

比如说有GB/MB/KB的场景
du -h --max-depth=1 | sort -rh | head -n 5

find找到固定的文件名并且删除
xargs将前面的结果传递到后面去,并且删除,类似管道命令
find . -type f -name "test1" | xargs rm -rf

每个磁盘的使用量排序(可以筛选已经挂载的磁盘)
筛选在磁盘列表内的磁盘,因为安装了docker和k8s,所以有overlay的磁盘(这个后续再来看)
也可以grep -v反向查询得出除去docker(overlay)的磁盘
输出第四列和第一列(磁盘名),并且对第一列的磁盘大小进行排序,注意:sort命令只能对第一列的东西进行排序,如果第一列是字母的话,那只能sort按照字母排序了
df -h | grep /dev/ | awk '{print $4,$1}' | sort -rh

hdparm:测试磁盘的读写速度
在Cent OS上安装hdparm的工具,测试磁盘的读写速度(IOPS)
yum -y install hdparm
hdparm -t /dev/sdb
可以在一定的大小上面测试出该盘的读写速度,这里在300-400MB左右的大小上,大概是120MB/sec的读写速度,和高IO的盘说明差不多的读写速度


iostat:查看系统资源的负载
会先显示Linux机器的内核版本数,以及系统的情况,CPU情况,默认的iostat命令就是显示所有的资源负载情况
iostat -m:以MB的形式显示
-d:显示磁盘的使用情况,可以在-d后面加上磁盘的名称,比如/dev/sdb1,sda1等
-c:显示CPU使用情况
iostat -m -d -c

iostat -c 1 2:查看CPU的负载,每1s显示一次,显示3个
用户处在user的时间百分比、带NICE的百分比、系统模式的百分比、等待输出输入的百分比、CPU空闲时间的百分比等

如果iowait参数过高,证明CPU在处理的时候等待时间过长,证明CPU的负载达到一定的瓶颈了,需要扩容或者是升级
如果idle的参数高,证明就是比较空闲,不需要过多的关心


 浙公网安备 33010602011771号
浙公网安备 33010602011771号