mapreduce过程
reduce端:
过程分析:
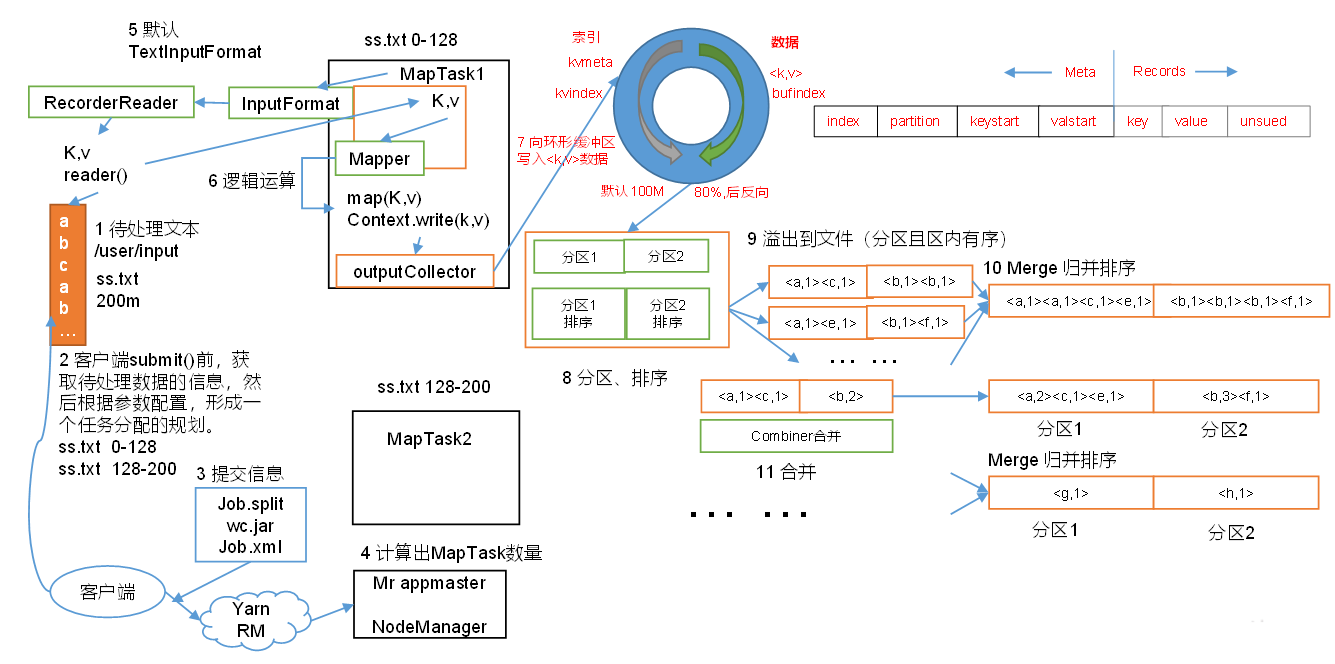
1.准备好待处理的文本,比如图中准备的文件是200M
2.客户端在进行submit之前,获取待处理的数据的信息,然后根据参数配置形成一个任务分配的规划。比如ss.txt文本有200M,读取的时候进行切分,按照128M进行切分,分成0-128,,128-200,两个数据块切分好后,会提交到集群yarn的resourcemanager上
3.集群向yarn集群提出请求创建MapReduce APPmaster 并提交切片等相关信息:job.split(job的切片信息)、wc.jar(计算程序jar包)、job.xml(包含application id等参数)
4.yarn调用resourcemanager 来创建MapReduce APPmaster,而MapReduce APPmaster则根据切片的个数来创建几个map task,启动相应的map task。map task 开始工作
5.maptask 它会去调用一个默认的TextInputFormat方法,这个Textinputformat方法,它会调用InputFormat方法,InputFormat方法会调用RecordReader这个读取的方法,然后调用read方法,将数据一行一行读取,它调用RecordReade的方法将数据抽成一行一行的key,value的形式,key就是行首字母的偏移量,这个value就是一行数据,然后加载到map方法里面去,每一行都会过滤map方法
6.在mapper中调用map()方法来对每行数据进行相关的业务上的逻辑运算处理。
7.在用户编写map函数中,当数据处理完成后,一般会调用outputCollector.collect()输出结果。而在该函数内部,它会将生成key/value分区(调用partition),并写入一个环形内存缓冲区(环形缓冲区默认大小是100M,数据处理的特点:左侧写索引或者元数据信息,右侧写数据,写满80%后溢写到磁盘,然后反向开始写,如此反复)。自数据进入环形缓冲区后,shuffle过程正式开始。
8.在进行环形缓冲区之后,在溢写之前会对数据进行一次排序。排序的方式是,按照分区编号partition进行排序,然后按照key进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序。
9.排完序后就溢出到文件(分区且区有序),整个过程会多次溢出到多个文件
10.在所有数据都溢出到文件后,开始merge归并排序(对同一个分区内溢出的多个有序的结果文件合并成一个大的溢出文件并完成归并排序)
-
之后的combiner合并为可选流程:分区内合并和压缩。之后,写入磁盘。至此,map task的执行过程基结束。
-
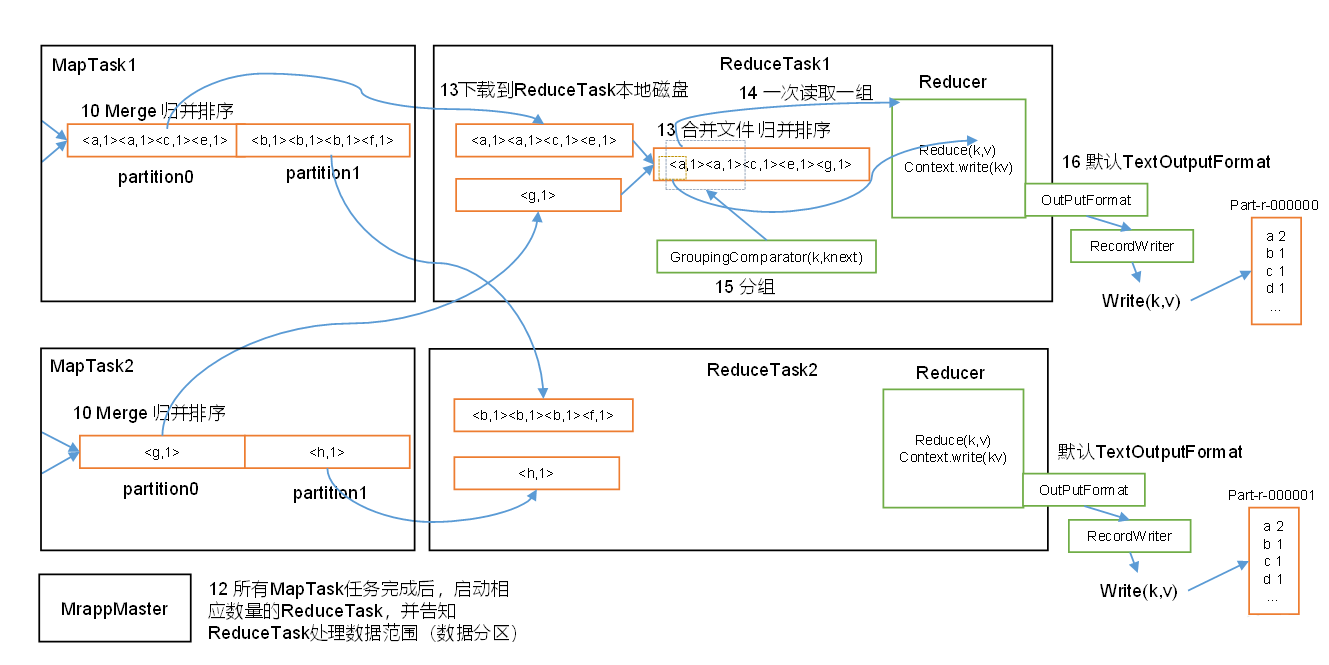
在所有map task任务都完成之后,根据分区的数量量来启动相应数量的reduce task,并告知reduce task处理数据范围(数据分区) (有几个分区就启动几个reduce task,每个reduce task专门处理同一个分区的数据,比如处理maptask1中的partition0和Map taks2中的partition0的数据)
-
ReduceTask根据自己的分区号,去各个maptask机器上拷贝相应分区内的数据到本地内存缓冲区,缓冲区不够的话就溢写到磁盘。待所有数据拷贝完毕后,reduceTask会将这些文件再进行归并排序。
-
排好序后之后按照相同的key分组。至此shuffle过程基本结束。
-
在分组后一次读取一组数据到Reducer,调用reduce方法进行聚合处理
-
之后通过context.write默认以TextOutputFormat格式经RecordWriter下入到文件。最后,ReduceTask 过程结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号