感知机原理及实现
感知机的原理
感知机是二分类的线性模型,其输入是实例的特征向量,输出的是事例的类别,分别是+1和-1,属于判别模型。
假设训练数据集是线性可分的,感知机学习的目标是求得一个能够将训练数据集正实例点和负实例点完全正确分开的分离超平面。如果是非线性可分的数据,则最后无法获得超平面。感知机由Rosenblatt于1957年提出的,是神经网络和支持向量机的基础。
1: 感知机模型
定义.感知机:假设输入空间 ,输出空间
。输入
表示实例的特征向量,对应于输入空间的点;输出
表示实例的类别。由输入空间到输出空间的函数
称为感知机。其中, 和
为感知机模型参数,
叫做权值或权值向量,
叫偏置,
表示
和
的内积。
是符号函数,即
感知机是一种线性分类模型,属于判别模型。感知机模型的假设空间是定义在特征空间中的所有线性分类模型或线性分类器,即函数集合 。
线性方程
对应于特征空间 中的一个超平面
,其中
是超平面的法向量,
是超平面的截距。超平面
将特征空间划分为两部分,位于其中的点被分为正、负两类,超平面
称为分离超平面。

2: 感知机学习策略
2.1 数据集的线性可分
给定数据集
其中, ,如果存在某个超平面
能够将数据集的正实例和负实例完全正确地划分到超平面的两侧,即对所有 的实例
,有
,对所有
的实例
,有
,则称数据集
为线性可分数据集 linearly separable data set ;否则,称数据集
线性不可分。
2.2 感知机学习策略
输入空间 中的任一点
到超平面
的距离:
其中 是
的
范数。
对于误分类数据 ,当
时,
,当
时,
,有
误分类点 到分离超平面的距离:
假设超平面 的误分类点集合为
,则所有误分类点到超平面
的总距离:
给定训练数据集
其中, 。感知机
的损失函数定义为
其中, 为误分类点的集合。
注:对于这里损失函数少了 可以先这么理解:我们目的是要找个超平面
,可以增加一个特征:
,因此超平面可以简化为
,用向量表示为
,则所有误分类点到超平面
的总距离:
。这样可以发现,分子和分母都含有
,当分子的
扩大
倍时,分母的
范数也会扩大
倍。也就是说,分子和分母有固定的倍数关系。那么我们可以固定分子或者分母为1,然后求另一个即分子自己或者分母的倒数的最小化作为损失函数,这样可以简化我们的损失函数。在感知机模型中,我们采用的是保留分子,即最终感知机模型的损失函数简化为:
3: 感知机学习算法
3.1 感知机学习算法的原始形式
给定训练数据集
其中, 。求参数
和
,使其为以下损失函数极小化问题的解
其中, 为误分类点的集合。
感知机学习算法是误分类驱动的,采用随机梯度下降法 stochastic gradient descent。极小化过程中不是一次使用$M$中所有误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降。
假设误分类点集合 是固定的,则损失函数
的梯度
随机选取一个误分类点 ,对
进行更新:
其中, 是步长,称为学习率。
感知机算法(原始形式):
输入:训练数据集 ,其中
;学习率
。
输出: ;感知机模型
1. 选取初值
2. 在训练集中选取数据
3. 如果
4. 转至2,直至训练集中没有误分类点。
直观解释:当一个实例点被误分类,即位于分离超平面的错误一侧,则调整 的值,使分离超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直至超平面越过该分类点使其被分类正确。
例1
对于训练数据集,其中正例点是x1=(3,3)T,x2=(4,3)T,负例点为x3=(1,1)T,用感知机学习算法的原始形式求感知机模型f(x)=w·x+b。这里w=(w(1),w(2))T,x=(x(1),x(2))T
解:构建最优化问题:
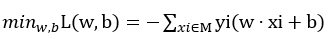
按照算法求解w, b。η=1
(1)取初值w0=0, b0=0
(2)对于(3,3):-(0+0)+0=0未被正确分类。更新w,b
w1=w0+1*y1·x1 = (0,0)T+1(3,3)T=(3,3)T
b1=b0+y1=1
得到线性模型w1x+b1 = 3x(1)+3x(2)+1
(3)返回(2)继续寻找yi(w·xi+b)≤0的点,更新w,b。直到对于所有的点yi(w·xi+b)>0,没有误分类点,损失函数达到最小。
分离超平面为x(1)+x(2)-3=0
感知机模型为 f(x)=sign(x(1)+x(2)-3)
在迭代过程中,出现w·xi+b=-2,此时,取任意一个点,都会是其小于0,不同的取值顺序会导致最终的结果不同,因此解并不是唯一的。为了得到唯一的超平面,需要对分离超平面增加约束条件,这就是支持向量机的想法。
__author__ = 'Administrator'
#! /usr/bin/python <br> # -*- coding:utf8 -*-
import numpy as np
class Perceptron(object):
"""
Perceptron classifier.
Parameters(参数)
------------
eta : float
Learning rate (between 0.0 and 1.0) 学习效率
n_iter : int
Passes over the training dataset(数据集).
Attributes(属性)
-----------
w_ : 1d-array
Weights after fitting.
errors_ : list
Number of misclassifications in every epoch(时间起点).
"""
def __init__(self, eta=0.01, n_iter=10):
self.eta = eta
self.n_iter = n_iter
def fit(self, X, y):
'''
Fit training data.
Parameters
----------
X : {array-like}, shape = [n_samples, n_features] X的形式是列矩阵
Training vectors, where n_samples is the number of samples
and n_features is the number of features.
y : array-like, shape = [n_samples]
Target values.
Returns
-------
self : object
'''
self.w_ = np.zeros(1 + X.shape[1])
# zeros()创建了一个 长度为 1+X.shape[1] = 1+n_features 的 0数组
#初始化权值为0
# self.w_ 权向量
self.errors_ = []
for _ in range(self.n_iter):
errors = 0
for xi, target in zip(X,y):
update = self.eta * (target - self.predict(xi))
self.w_[1:] += update * xi
self.w_[0] += update #更新权值,x0 =1
errors += int(update != 0.0)
self.errors_.append(errors) #每一步的累积误差
return self
def net_input(self, X):
"""Calculate net input"""
return (np.dot(X, self.w_[1:])+self.w_[0])
def predict(self, X):
"""return class label after unit step"""
return np.where(self.net_input(X) >= 0.0, 1, -1)
3.2 算法的收敛性
定理.Novikoff 设训练数据集 是线性可分的,其中,
,则:
(1)存在满足条件 的超平面
将训练数据集完整正确分开;并存在
,对所有
(2)令 ,则感知机算法在训练集上的误分类次数
满足不等式:
3.3 感机学习算法的对偶形式
上面的感知机模型的算法形式我们一般称为感知机模型的算法原始形式。对偶形式是对算法执行速度的优化。
通过上一节感知机模型的算法原始形式 可以看出,我们每次梯度的迭代都是选择的一个样本来更新
向量。最终经过若干次的迭代得到最终的结果。对于从来都没有误分类过的样本,他被选择参与
迭代的次数是0,对于被多次误分类而更新的样本
,它参与
迭代的次数我们设置为
。如果令
向量初始值为0向量,
修改n次,则
关于
的增量分别是
和
,其中
。
可表示为
其中,
感知机算法(对偶形式):
输入:训练数据集 ,其中
;学习率
。
输出: ;感知机模型
,其中
1.
2. 在训练集中选取数据
3. 如果
4. 转至2,直至训练集中没有误分类点。
4.3 原始形式和对偶形式的选择
- 在向量维数(特征数)过高时,计算内积非常耗时,应选择对偶形式算法加速。
- 在向量个数(样本数)过多时,每次计算累计和就没有必要,应选择原始算法
5. 训练过程
我们大概从下图看下感知机的训练过程。
线性可分的过程:
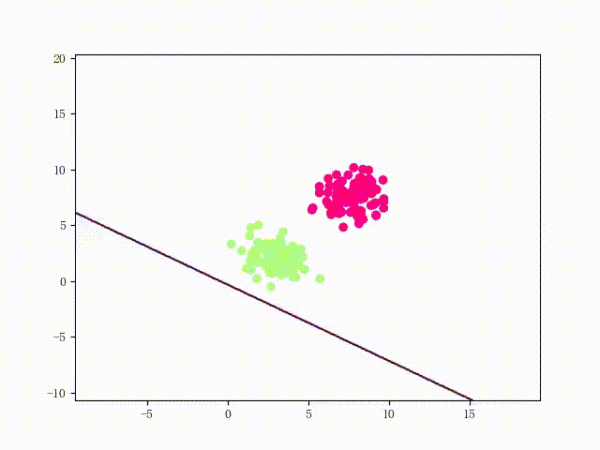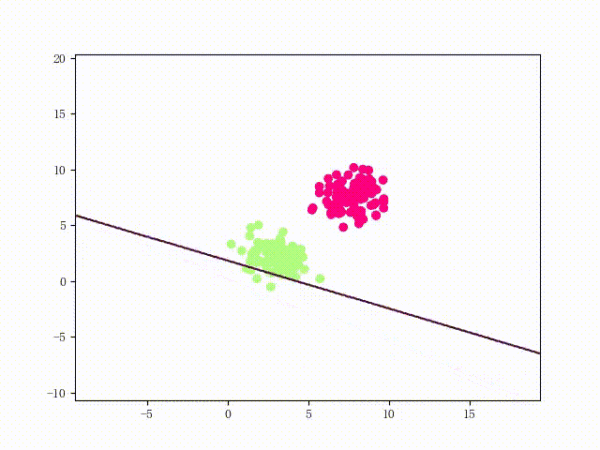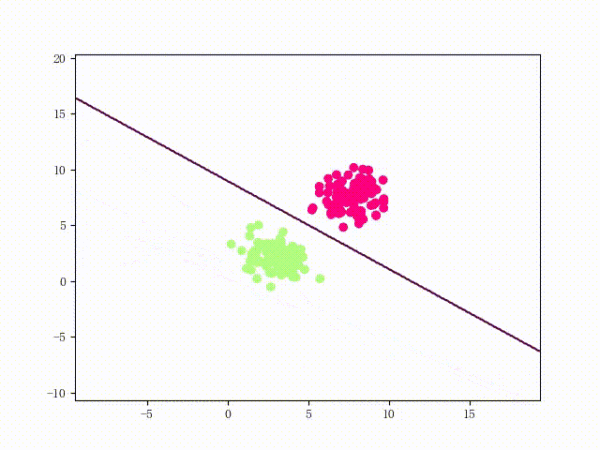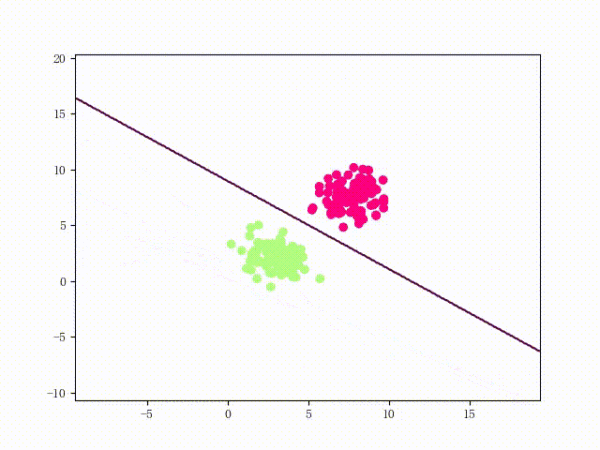
线性不可分

6. 小结
感知机算法是一个简单易懂的算法,自己编程实现也不太难。前面提到它是很多算法的鼻祖,比如支持向量机算法,神经网络与深度学习。因此虽然它现在已经不是一个在实践中广泛运用的算法,还是值得好好的去研究一下。感知机算法对偶形式为什么在实际运用中比原始形式快,也值得好好去体会。
参考文献:感知机原理小结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号