
YOLT:将YOLO用于卫星图像目标检测
之前作者用滑动窗口和HOG来进行船体监测,在开放水域和港湾取得了不错的成绩,但是对于不一致的复杂背景,这个方法的性能会下降。为了解决这个缺点,作者使用YOLO作为物体检测的流水线,这个方法相比于HOG提高了对背景的辨别力,并且可以快速的在不同尺度和多样传感器上进行快速检测。
- Review
ImageNet上的目标检测和卫星图像上的检测有以下四个方面的不同:
1.卫星图像的目标检测通常都很小(~20像素),而输入图像通常很大。缺少用于训练的卫星图像。
2.卫星图像中所检测的物体的物理和像素大小通常是已知的。
3.观察角度的变化很小。
4.从数以百公里之外观察物体很容易被欺骗。
- HOG+sliding windows
为了检测HOG+滑动窗口的目标检测流水线局限性,作者把它应用于来自于不同传感器具有复杂背景信息的卫星图像。
DigitalGlobe:0.5米地面采样间距(GSD)
Planet:3m的GSD

上图是将HOG+滑动窗口用于不同于训练时所用卫星图像的传感器(DigitalGlobe)的传感器(Planet)产生的卫星图像。2015年12月的图像显示了中国南海的一个人造岛屿Mischief Reef。枚举并定位这张图像中的船只非常复杂,从陆地上的线性区域提取到很多错误的红色的False Positive。并且F1得分非常低。检测这个图像在CPU上花费了125秒。
- YOLO
YOLO使用简单的CNN来预测分类和bounding box。在训练和测试时输入整张图片,这样做提高了对背景的辨别力,因为模型可以为每个目标编码上下文信息。这个模型对于小图像的实时检测非常快搞得检测速度以及对背景信息进行有效提取使得YOLO在卫星图像目标检测上成为一个引人注目的方法。
一些读者可能会问,为什么在之前的HOG+Sliding Windows中不采用深度学习的分类器而是采用了HOG特征。一个CNN分类器和滑动窗口结合会产生很棒的结果,但是计算会很难处理。评估一个基于GoogLeNet分类器会比HOG慢上大概50倍。使用基于CNN的分类器评估上图中的卫星图像的时间会从2分钟变成100分钟。在一个GPU上评估一张60立方千米的DigitalGlobe图像并且不做任何预处理需要花费几天的时间(预筛选在复杂场景下并不是很有效)。滑动窗口的另一个缺点是每次只能看到图像很小的一部分,会丢弃掉有用的背景信息。YOLO模型会明确不同的的背景信息,并且在大数据集上规模要比CNN和滑动窗口的方法小。
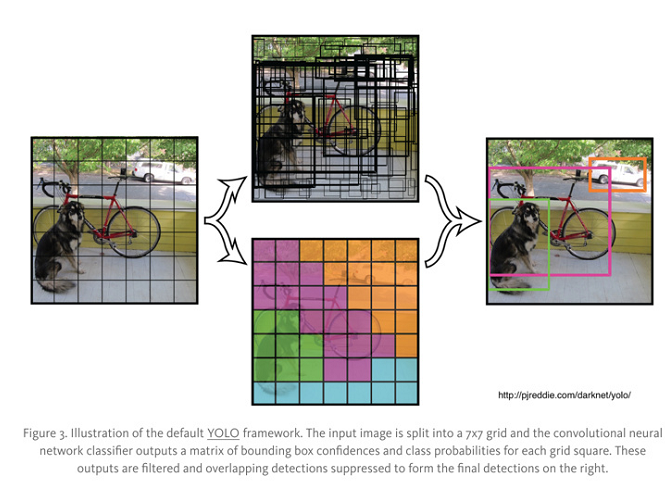
这个模型有以下几个局限,从原论文中引用原句并封装成三点:
1、我们的模型在小物体检测上的性能会有所下降,比如小鸟。
2、在检测新的或者不寻常的长宽比或者配置的目标上性能会下降。
3、我们模型使用先对粗糙的特征来预测bounding box因为我们的结构在原始图像上采用了很多下采样层。
为了解决这些问题,我们做了一下改变,我们将改变了的模型叫做YOLT:You Look Only Twice。
对于第一个局限性的解决方法:
- 通过滑动窗口进行过采样来寻找小的,密密麻麻的目标。
- 在多尺度上运行一个集成探测器
对于第二个局限性的解决方法:
- 通过重构和旋转来增强训练数据。
对于第三个局限性的解决方法:
- 定义一个新的网络模型,使得最后的卷积层有最终的网格密度。
YOLY模型的输出是通过预处理将来自于一张很大测试图像的全部的图像碎片组合在一起。这些改变将模型的速率从每秒44张图像降低到每秒18张图像。我们输入的最大图像的尺寸是500像素。密集网格(dense grid)的最大参数数量占满了12GB的内存。在没有要求寻找密密麻麻的目标,最大图像的大小可以增加2-4倍。
- YOLT Training Data
训练数据来自于DigitalGlobe和Planet产生的卫星图像的碎片。每个目标的标记包括bounding box和类别信息。
我们聚焦于一下四类:
- 开阔水面的船
- 港口的船
- 飞机
- 机场

作者标记了157张含有船的图像,每一张平均有3~6只船。64张标记了飞机的图像碎片,平均每张有2~4架飞机。收集了37个飞机场图像碎片,每一张都有一个飞机场。作者还旋转和在HSV空间随机的改变图像大小来增加分类器面对不同的传感器、大气条件和光线条件的鲁棒性。

输入语料的训练在一个NVIDIA Titan X GPU上花费了2~3天的时间。我们初始化的YOLT的分类器被训练去区分船和飞机。对YOLT的运行我们在两个不同尺度的巨大图像——一个120米的优化窗口寻找小船和飞行器,一个225米的窗口寻找大船和商用飞机,上采用滑动窗口的形式。
这个操作被用来最大化准确率而不是速度。我们可以通过只跑一个简单的滑动窗口或者或者通过下采样图像来增加滑动窗口的大小来增加速度。因为我们寻找的是非常小的东西,这会影响我们对不同的小物体的检测能力,比如从背景是15m建筑物的图像提取15米的船。未处理的DigitalGlobe图像大概有260megapixels,直接输入这个图像到深度学习框架会使硬件的处理能力超载。因此,过度下采样或图像切割时必须的,作者接受后一个方法。
- YOLT Object Detection Results
在一块NVIDIA Titan X GPU一运行代码,YOLT需要花费4-15秒来检测下面的图像。下面的figure6-10是基于公平的准则对比了HOG+滑动窗口和YOLT两个方法。HOG+滑动窗口被训练用来区分船以及船的航向,YOLT被训练用来处理船和飞机的定位(不是航向)。所有的图都使用Jaccard系数极限为0.25。




YOLT在开阔水域中的性能很好,尽管没有进行进一步的预处理YOLT中不理想的极度密集的区域,Figure9中证实了这个观点。上面讨论的四个区域处理了相关不统一的背景,HOG+滑动窗口的性能很好。正如figure2中所示,在一个高度不统一的背景里面HOG+滑动窗口很难从线性背景特征中区分不同的船。卷积网络可以保证在这一任务上的性能。

为了测试YOLT的鲁棒性,我们分析了在另一个卫星上得到的卫星图像的性能。

最后测试了这个分类器在飞机检测上的性能,如下方所示。

之前,我们证实了分类机器学习用于卫星图像检测的一个局限性——在高度不统一的背景上性能很差。为了解决这个问题,我们使用了YOLT来在卫星图像上快速定位船只和飞机。这个分类器不经旋转的bounding box的输出在拥挤的地区并不是最理想的,但是在稀疏的场景里面分类器的性能远高于HOG+滑动窗口的方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号