FAST协议详解1 不同数据类型的编码与解码
一、概述
FAST协议里不同的数据类型在编码时有非常大的区别,比如整数只需要将二进制数据转为十进制即可,而浮点数则需要先传小数点位数,再传一个整数,最后将二者结合起来才是最终结果。本篇使用openfast自设了一些数据并编码成FAST数据,再对这些FAST数据进行人工解码,以图看懂FAST协议是如何传递不同类型的数据。
二、数据类型
看接口文档,存在以下类型的数据:
|
数据类型 |
说明 |
备注 |
|
ascii |
ASCII字符串类型 |
|
|
byteVector |
字节向量类型 |
|
|
decimal |
浮点数类型 |
|
|
int16 |
有符号整数 |
都是有符号整数,区别仅在于取值范围 |
|
int32 |
有符号整数 |
|
|
int64 |
有符号整数 |
|
|
int8 |
有符号整数 |
|
|
string |
字符串 |
|
|
uInt16 |
无符号整数 |
都是无符号整数,区别仅在于取值范围 |
|
uInt32 |
无符号整数 |
|
|
uInt64 |
无符号整数 |
|
|
uInt8 |
无符号整数 |
浓缩一下:
|
数据类型 |
说明 |
备注 |
|
ascii |
ASCII字符串类型 |
|
|
string |
字符串 |
|
|
byteVector |
字节向量类型 |
|
|
decimal |
浮点数类型 |
|
|
int |
有符号整数 |
|
|
uInt |
无符号整数 |
|
三、不同数据类型的编码与解码
1、ASCII字符串类型
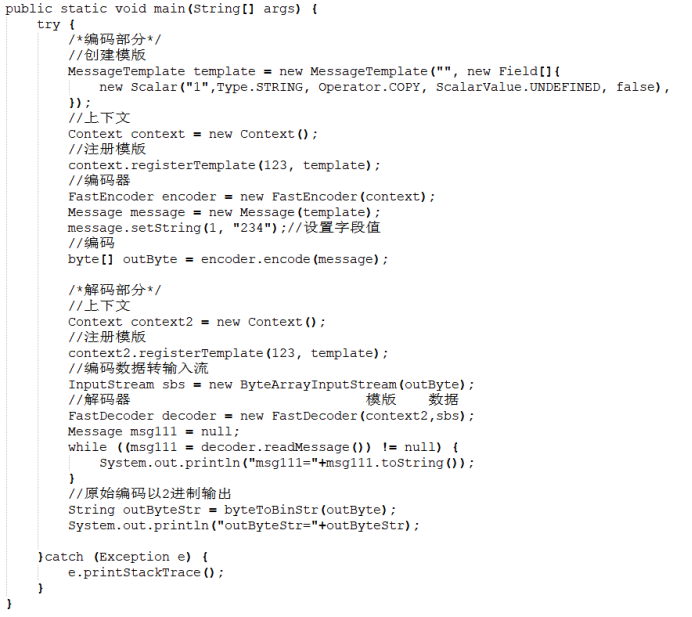
使用上述代码输出为:
msg111= -> {123, 234}
outByteStr=11100000,11111011,00110010,00110011,10110100,
二进制数据解析如下:
|
二进制数 |
解码过程 |
解码结果 |
|
11100000 |
|
PMap |
|
11111011 |
01111011=123 |
123 |
|
00110010,00110011,10110100 |
00110010=50=’2’ 00110011=51=’3’ 00110100=52=’4’ |
234 |
2、String字符串类型
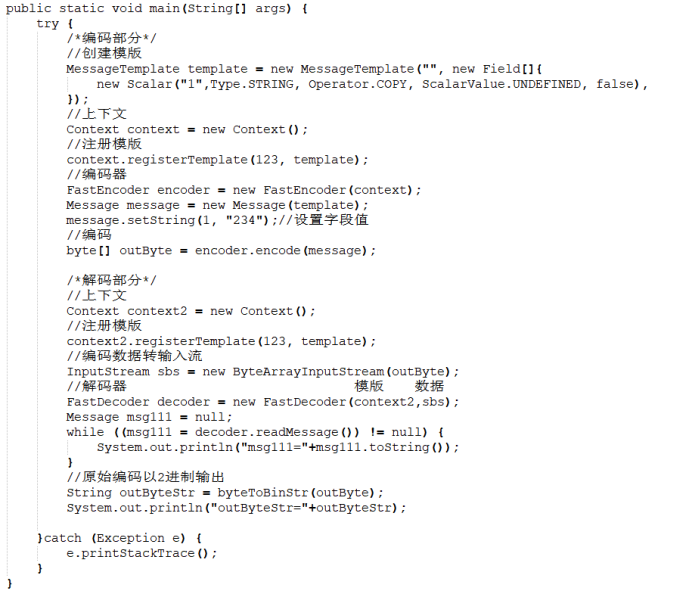
使用上述代码输出为:
msg111= -> {123, 234}
outByteStr=11100000,11111011,00110010,00110011,10110100,
二进制数据解析如下:
|
二进制数 |
解码过程 |
解码结果 |
|
11100000 |
|
PMap |
|
11111011 |
01111011=123 |
123 |
|
00110010,00110011,10110100 |
00110010=50=’2’ 00110011=51=’3’ 00110100=52=’4’ |
234 |
ASCII与string编码、解码一致,看不出区别。
3、int有符号整数类型
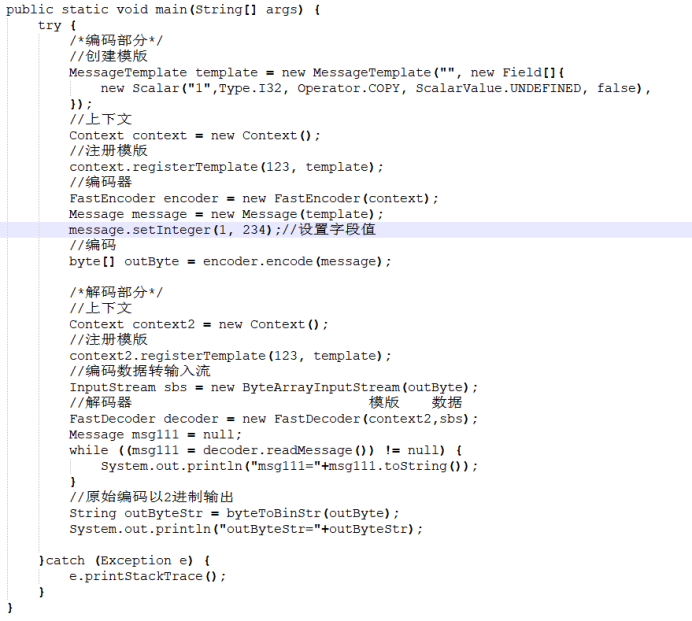
使用上述代码输出为:
msg111= -> {123, 234}
outByteStr=11100000,11111011,00000001,11101010,
二进制数据解析如下:
|
二进制数 |
解码过程 |
解码结果 |
|
11100000 |
|
PMap |
|
11111011 |
01111011=123 |
123 |
|
00000001,11101010 |
00000001=1*128=128 01101010=106 128+106=234 |
234 |
将输入修改为负值
msg111= -> {123, -234}
outByteStr=11100000,11111011,01111110,10010110
二进制数据解析如下:
|
二进制数 |
解码过程 |
解码结果 |
|
11100000 |
|
PMap |
|
11111011 |
01111011=123 |
123 |
|
01111110,10010110 |
01111110->1111110 10010110->0010110 实际:11111100010110 =-234 |
-234 |
问题:有符号整数如何传输负值?
可以看到,在传输234这个值时,我们解码的方式是将2个字节分开,前面的字节转十进制后乘以128,后面的字节直接转十进制,然后两个十进制数相加。
在传输-234时,是两个字节分别去掉第一个位(停止位),拼接起来直接转成了十进制。
我们知道,在计算机中,对于有符号整数的二进制存储,是默认了,第一个位是1的话认为是负数,第一个位是0的话则认为是正数。这里也是一样,去掉每个字节的第一个位(停止位)后,第一个位如果是1则认为是负数,适用负数转换规则。第一个位如果是0则认为是正数,适用正数转换规则。
对于一些数值,刚好第一位是1该如何处理,比如126=1111110?
msg111= -> {123, 126}
outByteStr=11100000,11111011,00000000,11111110,
实例如上,只需要在前面补0即可。
4、uInt无符号类型
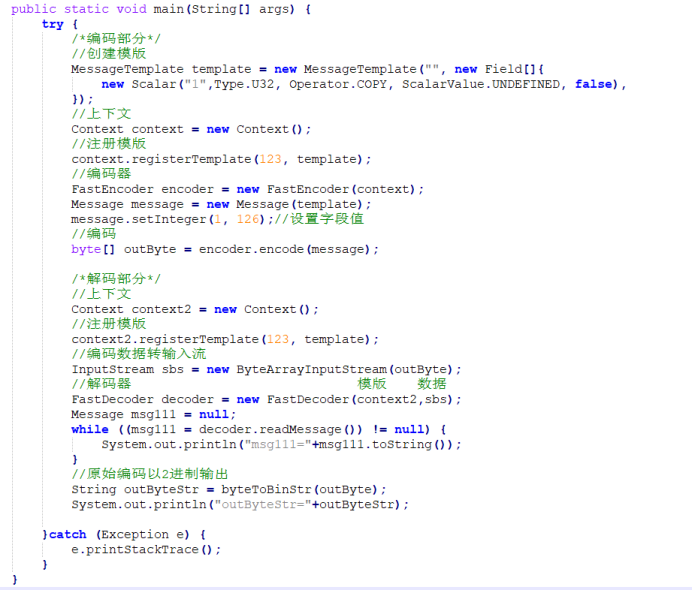
使用上述代码输出为:
msg111= -> {123, 126}
outByteStr=11100000,11111011,11111110,
二进制数据解析如下:
|
二进制数 |
解码过程 |
解码结果 |
|
11100000 |
|
PMap |
|
11111011 |
01111011=123 |
123 |
|
11111110 |
01111110=126 |
126 |
可见,对于无符号数,直接按正数规则解码即可。
5、decimal浮点数类型
使用上述代码输出为:
msg111= -> {123, 234.456}
outByteStr=11100000,11111011,11111101,00001110,00100111,11011000,
二进制数据解析如下:
|
二进制数 |
解码过程 |
解码结果 |
|
11100000 |
|
PMap |
|
11111011 |
01111011=123 |
123 |
|
11111101 |
11111101=-3 |
-3 |
|
00001110,00100111,11011000 |
00001110=14 00100111=39 01011000=88 14*128*128+39*128+88=234456 |
234456 |
很容易看明白,对浮点数进行编码时分成了2个部分,第一部分是“小数点”位数,第二部分是整数。解码后将两部分合并才能得到最终结果。
问题:如何传递负浮点数?
将234.456修改为-234.456后,输出为:
msg111= -> {123, -234.456}
outByteStr=11100000,11111011,11111101,01110001,01011000,10101000,
二进制数据解析如下:
|
二进制数 |
解码过程 |
解码结果 |
|
11100000 |
|
PMap |
|
11111011 |
01111011=123 |
123 |
|
11111101 |
11111101=-3 |
-3 |
|
01110001,01011000,10101000 |
111000110110000101000=-234456 |
-234456 |
与有符号整数差不多,是否传递负数,只需要将除去“停止位”后,判断第一个位是否是“1”即可。所以只需要将浮点数的传递看成是“小数点”+“整数”两个部分即可。
6、byteVector字节向量类型
前面我们讨论了整数、浮点数、字符串,所有的编码其实都遵循了一个原则,即一个字节能够传递的最大值只能小于128,要传递更大的值则需要“进位”。但我们需要传递的字节一定要大于128该如何是好,比如中文。我们使用前面的字符串、ASCII、整数,也不是不能编码,但解码起来就有点麻烦。很明显这时候就可以用到字节向量。

使用上述代码输出为:
msg111= -> {123, ????????}
outByteStr=11100000,11111011,10001000,11001110,11111011,11001110,11111011,10111001,11111110,10111001,11111110,
二进制数据解析如下:
|
二进制数 |
解码过程 |
解码结果 |
|
11100000 |
|
PMap |
|
11111011 |
01111011=123 |
123 |
|
10001000 |
00001000=8 |
8个字节 |
|
11001110,11111011, 11001110,11111011, 10111001,11111110, 10111001,11111110 |
11001110,11111011=CE FB 11001110,11111011=CE FB 10111001,11111110=B9 FE 10111001,11111110=B9 FE CEFB CEFB B9FE B9FE=嘻嘻哈哈 |
嘻嘻哈哈 |
有点类似浮点数的编码,这里先传递字节向量的长度“8”,接着传递字节向量。由于字节向量的长度已指定,故传输数据时不再遵循停止位的概念。
另注意这里使用的是GBK编码,故直接输出是乱码。
四、回顾
|
数据类型 |
说明 |
备注 |
|
ascii |
ASCII字符串类型 |
遵循一般停止位规则,最后一个字节的第一位为1则是该字段最后一个字节,而后根据ASCII码表直接转字符串即可。 |
|
string |
字符串 |
同上 |
|
int |
有符号整数 |
遵循一般停止位规则,注意第一位(除开停止位之外的)为“0”则是正整数,则按128进位的规则进行数值转换即可。第一位(除开停止位之外的)为“1”则是负整数,则将全部字节去掉停止位后,直接转为整数即可。负数转换时需要注意前面要补1。 |
|
uInt |
无符号整数 |
遵循一般停止位规则,由于知道一定是正整数,则直接按128进位的规则进行数值转换即可。 |
|
decimal |
浮点数类型 |
分两部分进行传递,两个部分均遵循一般停止位规则。第一部分是浮点数的“小数点位数”,第二部分则是整数。注意是有符号整数,遵循int的解码方式即可。 |
|
byteVector |
字节向量类型 |
分两部分进行传递,第一部分是字节向量的长度,遵循一般停止位规则。第二部分则是纯byte数据,不再遵循停止位规则,但由于前面有传递其长度,故也不会出错。 |
结语:这里只是最基本的编码解码规则,到这里也只是能稍微看懂一点还无法进行真正的FAST解码。后面的“操作符”及null什么的才是硬骨头。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号