FAST协议解析3 FIX Fast Tutorial翻译 HelloWorld示例
1.3. Variable Sized Fields
Fields in FAST do not have a fixed size and do not use a field separator. Instead, there is a notion of a stop bit (the high order bit on each byte of the message acts as a stop bit) signaling the end of the field.
All of the above concepts used together allow the sender to compress a message (sometimes as much as 90%) and the receiver to restore the original message content from the encoded bytes.
The next section looks at a small message example to show encoding and decoding in practice.
1.3 可变大小字段
FAST中的字段没有固定大小,也不使用字段分隔符。相反,有一个停止位的概念(消息中每个字节的第一位作为停止位)来标识字段的结束。
上述概念的使用使得消息发送方可以压缩信息(有时高达90%),同时接收方可以通过编码后的字节来恢复原始消息。
下一节将介绍一个小型示例,以演示实际情况下的编码和解码。
2. Hello World Example
To introduce the encoding and decoding process, we describe how a trivial message with only 1 field would be FAST encoded and decoded.
- Hello World 示例
为了介绍编码和解码过程,我们描述了如何对只有一个字段的消息进行FAST编码和解码。
2.1. Input Message
Here’s the message we’ll start with:
58=HelloWorld<SOH>.
The SOH (ASCII 1) is the FIX separator byte.
2.1 输入消息
这是我们使用的消息:
58=HelloWorld<SOH>
SOH(ASCII 1)是FIX分隔符。
2.2. The Template
This message requires a very simple template (expressed in XML and described in greater detail in later sections):
2.2 模版
这个消息使用一个非常简单的模版(用XML表示,并在后面详细描述)

2.3. Stop Bits
The high order bit of each byte of the message is reserved to indicate the end of the field.
So each of the fields described below will only use 7 bit bytes and the 8th bit will be set on the last byte of the field.
2.3 停止位
消息中,每个字节的最高位被保留用以标识字段的结束。
所以,我们这里描述的每一个字段都只使用7个字节位,并且字段的最后一个字节的最高位将被设置为1。
(译注:每个字节由8个位(bit)组成,我们只使用其中的7位,第8位(也就是最高位)被用作停止位。由于一个字段是由多个字节组成,所以当组成字段的多个字节中的某一字节的最高位被置为1,那就说明这个字节是这个字段的最后一个字节了。举例如下:
Int 256 FAST压缩后等于 0000 0010,1000 0000。由2个字节组成,其中最后一个字节1000 0000的最高位(也可以说是从左边数第一个位,或者从右边数第8个位)是停止位,标识了该字段的结束。第一个字节0000 0010的最高位也是停止位,但它是0表明字段未结束,其可能的最大值是0111 1111。)
2.4. Encoding the Message:
To encode the message, we need to produce a Presence Map (PMap) that goes onto the front of the compressed FAST message followed by the encoded fields.
PMap is described in detail in section 3.1, but simply has 1 bit for each field to indicate whether the field has been included in subsequent bytes, or has been omitted.
Note: In our example, if the Text field is omitted, it will default to an empty string. (Because of the xml element: <default value=””/> in the above template.)
When encoding the message the template ID is usually put into the message right after the PMap. (We’ll discuss this more later.) This requires a PMap bit, too.
So for our trivial one field message, we need a PMap with 2 bits:
- indicate template ID is in the message
- indicate Text field is in the message
Encoding steps:
-
- These are the high order bits and the rest are zeros: 110 0000.
This is a 1 byte PMap, so its 8th bit is set to 1 to indicate it is the last byte of the PMap: 1110 0000 = 0xE0.
- These are the high order bits and the rest are zeros: 110 0000.
-
- The next field is the template field (for template 1): 000 0001.
Again, this is a 1 byte field so we set the 8th bit to indicate the end: 1000 0001 = 0x81.
- The next field is the template field (for template 1): 000 0001.
- The next field is the text field contents: “HelloWorld”.
In the hex format it is: H=0x48, e=0x65, l=0x6C, l=0x6C, o=0x6F, W=0x57, o=0x6F, r=0x72, l=0x6C, d=0x64.
The last byte will have its high order bit set to “1”. Using this, we have the following binary representation of our text field:
01001000 01100101 01101100 01101100 01101111 01010111 01101111 01110010 01101100 11100100
2.4 消息编码
要对消息进行编码,我们需要生成一个PMap(存在图、存在映射),PMap位于压缩后的FAST消息前面,PMap后跟着FAST编码后的字段。
PMap在第3.1节中有详细描述,在PMap中每个字段只使用1个位来标识是否存在或已被忽略。
注意:在我们的示例中,如果省略text字段,则默认是一个空字符串(因为模版中的xml元素是<default value=””/>)
对消息进行编码时,模版ID通常放在PMap的后面(后面详细讨论),这同样需要占用PMap的1位。所以对于我们的只有一个字段的消息,需要占用PMap的2个位:
- 标识模版ID是否在消息中
- 标识text字段是否在消息中
编码步骤:
1)高位为1,其他的为0:110 0000。
(译注:两个1,分别标识了模版ID和text字段的存在)
这个PMap只有1个字节,所以它的第八位(最高位)被置为1,表示这是PMap的最后一个字节:1110 0000 = 0xE0。
2)下一个字段是模版ID字段(模版ID=1):000 0001.
同样的,这也是1个字节的字段,所以我们将第八位置1标识这是最后一个字节:1000 0001 = 0x81。
3)接下来的是text字段,内容是“HelloWorld”。
“HelloWorld”的十六进制格式为:H=0x48, e=0x65, l=0x6C, l=0x6C, o=0x6F, W=0x57, o=0x6F, r=0x72, l=0x6C, d=0x64。
最后一个字节的最高位需要被设置为1,也就是d=0x64=0xE4,那么我们可以得到text字段的二进制格式:
01001000 01100101 01101100 01101100 01101111 01010111 01101111 01110010 01101100 11100100
2.5. Encoded FAST Message “HelloWorld”
The fields strung together are shown below:

2.5 FAST编码后的“HelloWorld”消息
所有字段放在一起,如下所示:

2.6. Decoding the Message
Looking at the just the above binary data and the template file, we can reconstruct the original message content by reversing the encoding process.
Our input (encoded) FAST message is:
HEX format: 0xE0 0x81 0x48 0x65 0x6C 0x6C 0x6F 0x57 0x6F 0x72 0x6C 0xE4
Binary format: 11100000 10000001 01001000 01100101 01101100 01101100 01101111 01010111 01101111 01110010 01101100 11100100
Lets decode it step by step:
- Extracting Message PMap. Message PMap must be present before each encoded message so the first step of decoding process must be defining PMap.
We get the first byte from the stream: “11100000“, check its stop bit (high order bit or first bit).
It is set to “1”, so our encoded PMap consists of 1 byte: 11100000. We remove the stop bit which yields the decoded message PMap: 1100000
- Extracting Message PMap. Message PMap must be present before each encoded message so the first step of decoding process must be defining PMap.
- Decoding template ID. We get the first bit from our PMap which is “1” and it indicates presence of template ID value in the input message.
Using the same way as for PMap decoding we decode template ID:
- Decoding template ID. We get the first bit from our PMap which is “1” and it indicates presence of template ID value in the input message.
- We get the next byte after PMap from the stream. It is the second byte: “10000001” and the stop bit of this byte is “1”. So our template ID is the 1 byte value.
- After removing stop bit from template ID encoded value we receive: "0000001" = "1" which is the actual value of template ID.
Template ID is used to define FAST message template which contains references for field decoding.
- “HelloWorld” field decoding. The next bit (second bit in this case) from our PMap is set to “1” and it indicates that the “HelloWorld” field is present in the input message too.
As our text field consists of more than one byte we must get next input bytes (after template ID) one by one. This is required to find the byte which has stop bit set to “1” and indicates the end of “HelloWorld” encoded field.
Byte which has high order bit (stop bit) set to “1” is the last byte in input stream so our encoded text field is:
01001000 01100101 01101100 01101100 01101111 01010111 01101111 01110010 01101100 11100100
Stop bit decoding of this text field is in following. We must replace the stop bit of last byte of text field from “1” to “0”.
After this we receive actual value of our text field:
Binary format: 01001000 01100101 01101100 01101100 01101111 01010111 01101111 01110010 01101100 01100100
HEX format: 0x48 0x65 0x6C 0x6C 0x6F 0x57 0x6F 0x72 0x6C 0x64
Character format: HelloWorld
We combine decoded output fields and receive message: 58=HelloWorld<SOH>.
In the picture below are shown all of these steps:
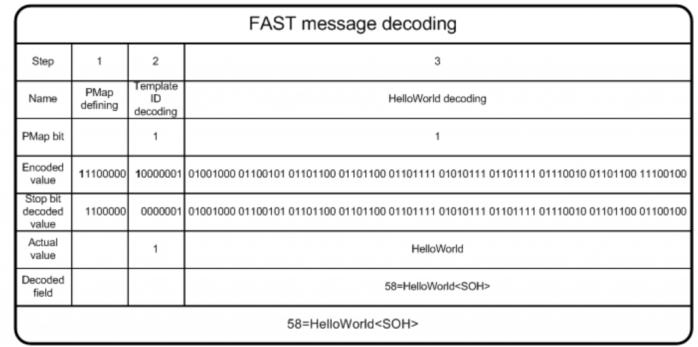
Picture 2.2 – “HelloWorld message decoding”
The next section will describe the different FAST elements (such as the FAST Template and the PMap) in much greater detail and walk through more complex decoding examples.
2.6 消息解码
查看前面的二进制数据和模版文件,我们可以反转编码过程来重建原始消息内容。
我们已编码的FAST消息如下:

下面一步一步来解码:
1)提取PMap。PMap必定在每个已编码消息的最前面,所以解码的第一步必须是先找到PMap。
我们从流中获取第一个字节“1110 0000”,检查其停止位(最高位)发现它被置为“1”,因此我们的PMap由一个字节组成。移除停止位得到“110 0000”。
2)模版ID解码。我们从PMap中获取第一位(译注:移除停止位后的),即“1”,表明消息中存在模版ID字段。
使用与PMap相同的方式来对模版ID进行解码。
- 从流中获取PMap后的字节,也就是第二个字节“1000 0001”,其停止位(最高位)是“1”,所以我们的模版ID字段为1个字节。
- 我们将停止位从模版ID中移除,得到“000 0001”=“1”,这就是实际的模版ID值。
模版ID用于定义包含字段解码参考信息的FAST消息模版。
3)“HelloWorld”字段解码。PMap中的第二个位(译注:移除停止位后的)被置为“1”,表明输入消息中存在“HelloWorld”字段。
由于text字段由多个字节组成,所以我们需要逐个获取模版ID后的每一个字节,并找到停止位被置为“1”的字节,也就是text字段的最后一个字节。
停止位被置为“1”的字节在最后一个字节,所以我们的text字段的内容是:
01001000 01100101 01101100 01101100 01101111 01010111 01101111 01110010 01101100 11100100
text字段解码如下。我们需要将text字段最后一个字节的停止位从“1”替换为“0”。这样我们就得了到文本字段的实际值:
二进制格式:01001000 01100101 01101100 01101100 01101111 01010111 01101111 01110010 01101100 01100100
十六进制格式:0x48 0x65 0x6C 0x6C 0x6F 0x57 0x6F 0x72 0x6C 0x64
字符格式:HelloWorld
我们结合解码输出字段可以得到如下消息:
58=HellowWorld<SOH>
下图示意了整个过程:

图2.2-“HelloWoeld消息解码”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号