
【零基础】神经网络优化之mini-batch
一、前言
回顾一下前面讲过的两种解决过拟合的方法:
1)L0、L1、L2:在向前传播、反向传播后面加个小尾巴
2)dropout:训练时随机“删除”一部分神经元
本篇要介绍的优化方法叫mini-batch,它主要解决的问题是:实际应用时的训练数据往往都太大了,一次加载到电脑里可能内存不够,其次运行速度也很慢。那自然就想到说,不如把训练数据分割成好几份,一次学习一份不就行了吗?前辈们试了试发现不仅解决了内存不足的问题,而且网络“收敛”的速度更快了。由于mini-batch这么棒棒,自然是神经网络中非常重要的一个技术,但实际实现时你会发现“真的太简单了”。
二、batch、mini-batch、随机梯度下降
这里先解释几个名词,可以帮助大家更好的理解mini-batch。
1)之前我们都是一次将所有图片输入到网络中学习,这种做法就叫batch梯度下降
2)与batch对应的另一种极端方法是每次就只输入一张图片进行学习,我们叫随机梯度下降
3)介于batch梯度下降和随机梯度下降之间的就是我们现在要整的,叫mini-batch梯度下降
三、mini-batch大小、洗牌
前面说,mini-batch是将待训练数据分割成若干份,一次学习一份。那每一份具体包含多少个图片合适呢?实际上是没有什么特定标准的,但这个数值又切实影响着神经网络的训练效果,一般来说就是建议“设置为2的若干次方,如64、128、256、1024等等”。你可以先随便设置一个数看看效果,效果一般再调调。
“洗牌”是mini-batch的一个附加选项,因为我们是将训练数据分割成若干份的,分割前将图片的顺序打乱就是所谓的“洗牌”了,这样每一次mini-batch学习的图片都不一样为网络中增加了一些随机的因素。具体原理上不知道有啥特别的,但实践中确实优化了网络。
四、mini-batch实现与对比
完整的实现代码是基于之前“深层神经网络解析”的,下载方式见文末。这里我做了个简单的实验,下图中分别是无mini-batch、不带洗牌的mini-batch、带洗牌的mini-batch运行效果。
无mini-batch:
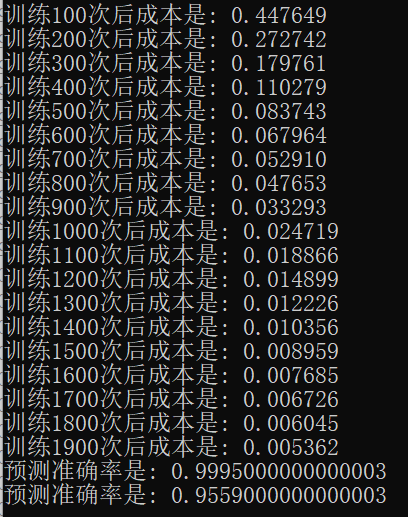
不带洗牌的mini-batch:
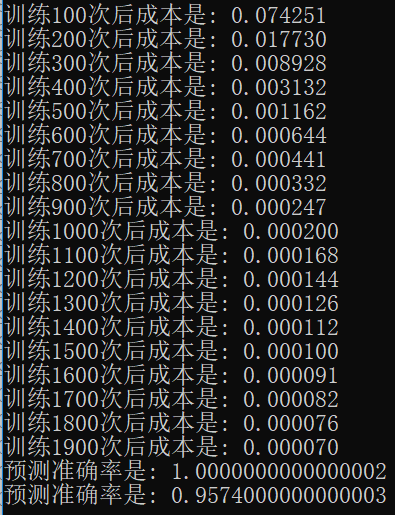
带洗牌的mini-batch:

可以看到,使用mini-batch后网络可以迅速收敛。使用了mini-batch的网络仅用了400次就达到了普通网络2000次的训练效果。由于求解的问题不算很难,所以使用了洗牌的mini-batch与普通的mini-batch似乎没啥差别,不过还是能看出来效果还是好了一点的(不过会使用更长的时间来训练)。
完整实现代码可以关注公众号“零基础爱学习”回复“AI11”获取。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号