Java8的新特性--并行流与串行流
写在前面
我们都知道,在开发中有时候要想提高程序的效率,可以使用多线程去并行处理。而Java8的速度变快了,这个速度变快的原因中,很重要的一点就是Java8提供了并行方法,它使得我们的程序很容易就能切换成多线程,从而更好的利用CPU资源。
下面我们就来简单学习一下java8中得并行流与串行流。
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
Java8中将并行进行了优化,我们可以很容易的对数据进行并行操作。Stream API 可以声明性地通过parallel()与sequential()在并行流与顺序(串行)流之间进行切换
Fork/Join框架
在说并行流之前呢,我们首先来来接一下这个Fork/Join框架框架。
Java 7开始引入了一种新的Fork/Join线程池,它可以执行一种特殊的任务:把一个大任务拆成多个小任务并行执行。即在必要的情况下,将一个大的任务,进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行join汇总。
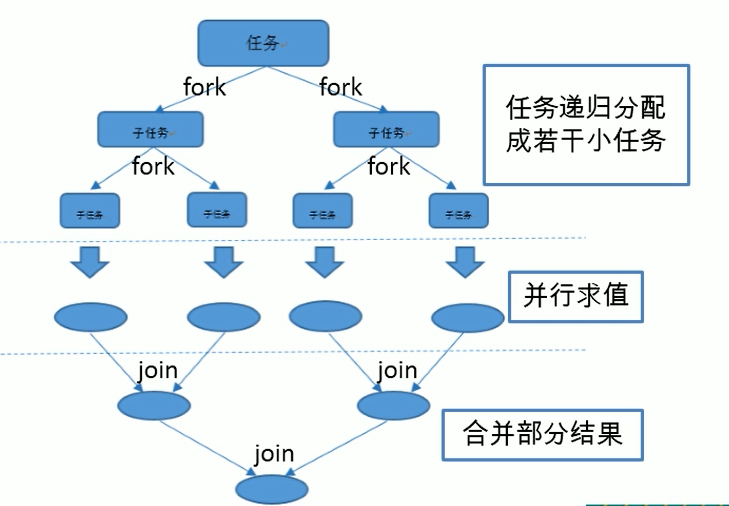
Fork/Join框架与传统线程池的区别
传统的线程池
我们就多线程来说吧,所谓的多线程就是把我们的任务分配到CPU不同的核上(也就是CPU不同的线程上)进行执行,我们以4核CPU为例。如果是传统线程的话,每个任务都有可能会阻塞,因为每个线程什么时候执行是由CPU时间片给他分配的执行权决定的,当这个时间片用完了以后,CPU会剥夺他的执行权,然后交给其他的线程去执行,这时就有可能出现阻塞的情况。即4核CPU我们可以看成4个线程,有可能其中俩线程中的一个任务阻塞造成后面的任务排队得不到执行,而另外两个没有阻塞的线程,则顺利执行完处于空闲状态了,这种有的线程在阻塞线程里的任务得不到执行,而别的不阻塞的线程空闲没有任务可以执行的状态,就造成了CPU资源的浪费,这样就会大大影响我们程序的执行效率。
Fork/Join框架
是把一个大任务拆分成若干个小任务,然后把这些小任务都压入到对应的线程中,也就是把这些小任务都压入到对应的CPU中(默认CPU有几核就有几个线程),然后形成一个个的线程队列。
Fork/Join任务的原理:判断一个任务是否足够小,如果是,直接计算,否则,就分拆成几个小任务分别计算。这个过程可以反复“裂变”成一系列小任务。
Fork/Join框架会将任务分发给线程池中的工作线程。Fork/Join框架的独特之处在于它使用“工作窃取”(work-stealing)算法。完成自己的工作而处于空闲的工作线程,能够从其他扔处于忙碌状态的工作线程中窃取等待执行的任务,每个工作线程都有自己的工作队列,这是使用双端队列(dequeue)来实现的。线程执行任务是从队列头部开始执行的,而处于空闲状态的线程,在窃取别的线程的任务的时候,是从被窃取线程的等待队列的队尾开始窃取的。这种情况下,就不会出现空闲的线程浪费CPU资源,因为一旦空闲便会去窃取任务执行。没有资源浪费,减少了线程的等待时间,所以效率就高,就提升了性能。
下面我们举个例子:如果要计算一个超大数组的和,最简单的做法是用一个循环在一个线程内完成。还有一种方法,可以把数组拆成两部分,分别计算,最后加起来就是最终结果,这样可以用两个线程并行执行,如果拆成两部分还是很大,我们还可以继续拆,用4个线程并行执行,这种即使用Fork/Join对大数据进行并行求和。
Fork/Join框架的使用
下面我们来写测试类演示一下:实现数的累加操作,比如说计算1到100亿的和。
我们要编写一个类继承RecursiveTask类,并重写compute()方法。
package com.cqq.java8.parallel;
import java.util.concurrent.RecursiveTask;
/**
* @Description:递归进行拆分
* @date 2021/3/14 7:55
*/
public class ForkJoinCalculate extends RecursiveTask<Long> {
private Long start;
private Long end;
public ForkJoinCalculate(Long start, Long end) {
this.start = start;
this.end = end;
}
//临界值,当大于临界值的时候就一直拆分,小于临界值就不再进行拆分了
private static final long THREASHOLD = 100000000L;
//重写compute方法
@Override
protected Long compute() {
long length = end - start;
if(length <= THREASHOLD){//到临界值就不能再拆了
long sum = 0;
for (Long i = start; i <= end; i++) {
sum += i;
}
return sum;
}else{//不到临界值就进行拆分
long middle = (end + start);
ForkJoinCalculate left = new ForkJoinCalculate(start,middle);
//拆分子任务,同时压入线程队列
left.fork();
ForkJoinCalculate right = new ForkJoinCalculate(middle+1,end);
right.fork();
//拆完之后,合并,把fork()之后的结果得一个个合并,即累加总和
return left.join()+right.join();
}
}
}
测试方法
package com.cqq.java8;
import com.cqq.java8.parallel.ForkJoinCalculate;
import org.junit.Test;
import java.time.Duration;
import java.time.Instant;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
/**
* @Description:
* @date 2021/3/14 8:17
*/
public class TestForkJoin {
@Test
public void test01(){
//开始时间
Instant start = Instant.now();
//ForkJoin的执行需要一个ForkJoinPool的支持
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Long> task = new ForkJoinCalculate((long) 0,100000000L);
Long invoke = pool.invoke(task);
System.out.println(invoke);
//结束时间
Instant end = Instant.now();
//计算一下时间用 耗时多少
System.out.println(Duration.between(start,end).toMillis());
}
//一个普通for循环即传统的单线程的测试类 与Fork/Join的执行结果做对比
@Test
public void test02(){
Instant start = Instant.now();
long sum = 0L;
for (long i = 0; i < 100000000L; i++) {
sum += i;
}
System.out.println(sum);
Instant end = Instant.now();
System.out.println(Duration.between(start,end).toMillis());
}
}
测试结果
| 类加和 | ForkJoin耗时 | 传统单线程耗时 |
|---|---|---|
| 1-1亿 | 521 | 85 |
| 1-10亿 | 241 | 363 |
| 1-100亿 | 1103 | 2431 |
从测试结果可以看出,当任务量不大时,传统单线程耗时短,任务达到一定量时ForkJoin的性能就很好了,因为在任务量不大时,拆分任务也要耗时,所以总的执行时间就比较长。说明,多线程也是要在合适的时候用才能提升性能。
Java8中的并行流
在Java 8中我们用的是parallel()方法,对并行流进行了优化。但是实际上底层还是用的Fork/Join框架。
@Test
public void test03(){
Instant start = Instant.now();
//顺序流
long reduce = LongStream.rangeClosed(0, 100000000L)
.reduce(0, Long::sum);
//使用parallel()并行流
OptionalLong reduce1 = LongStream.rangeClosed(0, 100000000L)
.parallel()//并行
.reduce(Long::sum);
Instant end = Instant.now();
System.out.println(Duration.between(start,end).toMillis());
}
Java8 中不仅仅对代码进行了优化,而且效率也大大提升。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号