Linux性能优化实战:开篇+平均负载
摘 学习笔记:
开篇
性能指标概念:高并发 => 吞吐 响应快 => 延时
该概念是从应用负载的角度出发:Application ▹Libraries▹System Call▹Linux Kernel ▹Drive
与之对应的是系统资源视角出发 :Drive▹Linux Kernel ▹System Call ▹Libraries ▹Application
性能指标的评判有以上二种常用的角度
接着六步
1.选择性能指标评估应用和系统的性能
2.为应用和系统设定性能目标
3.进行性能基准测试
4.性能分析定位瓶颈
5.优化系统和应用程序
6.性能监控和告警
六步总结,从正确的角度出发,设定目标(性能优化不是漫无目的的),基准测试(了解现有系统应用的运行时情况),根据情况分析瓶颈,优化它,设置监控和告警(其实可以再扩展比如达到一定的负载,采取降级等操作)
https://static001.geekbang.org/resource/image/92/1d/920601da775da08844d231bc2b4c301d.png
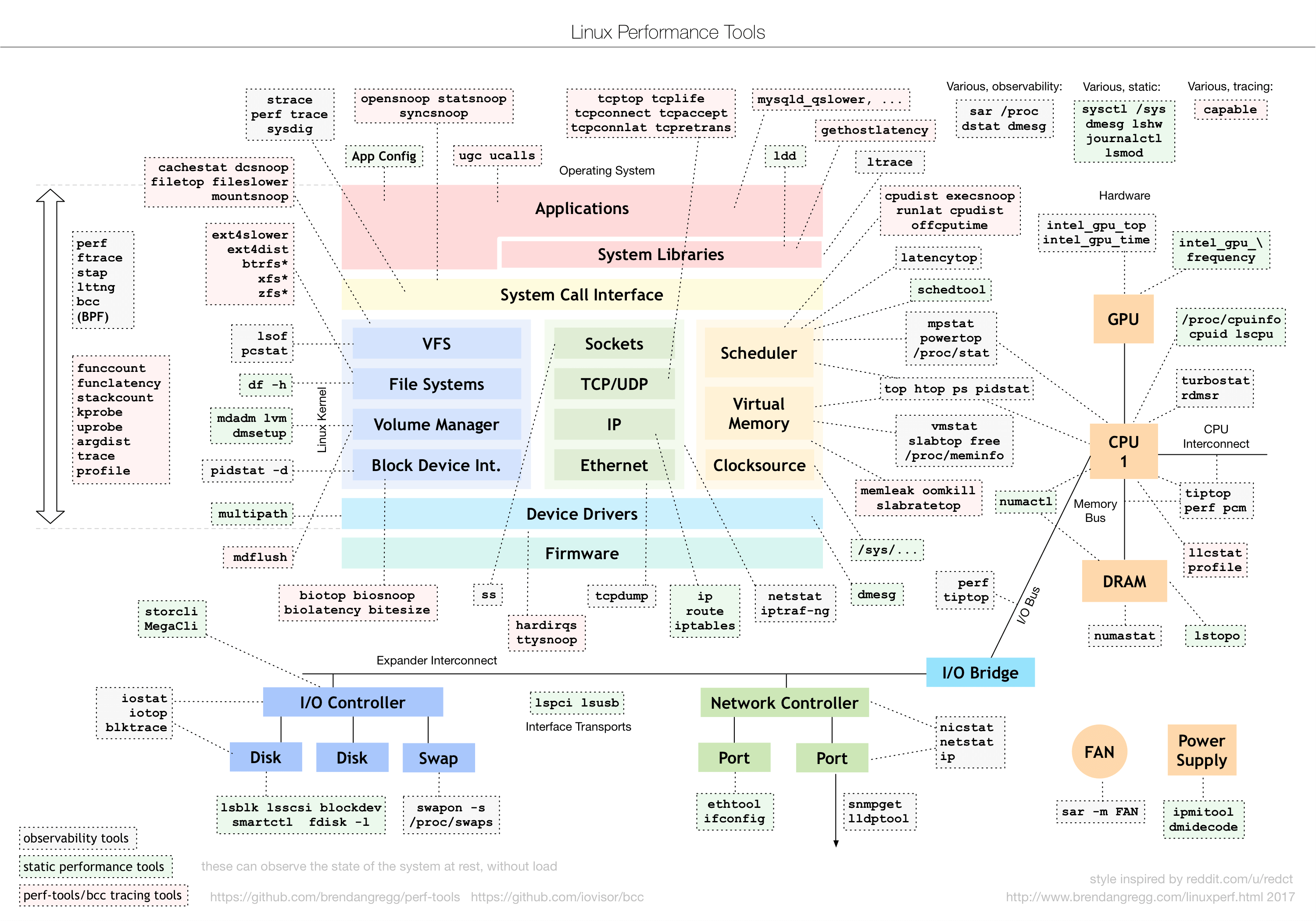
工具图谱
https://static001.geekbang.org/resource/image/9e/7a/9ee6c1c5d88b0468af1a3280865a6b7a.png
思维导图
一、什么是平均负载
正确定义:单位时间内,系统中处于可运行状态和不可中断状态的平均进程数。
错误定义:单位时间内的cpu使用率。
可运行状态的进程:正在使用cpu或者正在等待cpu的进程,即ps aux命令下STAT处于R状态的进程。
不可中断状态的进程:处于内核态关键流程中的进程,且不可被打断,如等待硬件设备IO响应,ps命令D状态的进程。
理想状态:每个cpu上都有一个活跃进程,即平均负载数等于cpu数。
过载经验值:平均负载高于cpu数量70%的时候。
二、相关命令
cpu核数: lscpu、 grep 'model name' /proc/cpuinfo | wc -l
显示平均负载:uptime、top,显示的顺序是最近1分钟、5分钟、15分钟,从此可以看出平均负载的趋势
watch -d uptime: -d会高亮显示变化的区域
strees: 压测命令,--cpu cpu压测选项,-i io压测选项,-c 进程数压测选项,--timeout 执行时间
mpstat: 多核cpu性能分析工具,-P ALL监视所有cpu
pidstat: 进程性能分析工具,-u 显示cpu利用率
三、平均负载与cpu使用率的区别
CPU使用率:单位时间内cpu繁忙情况的统计
情况1:CPU密集型进程,CPU使用率和平均负载基本一致
情况2:IO密集型进程,平均负载升高,CPU使用率不一定升高
情况3:大量等待CPU的进程调度,平均负载升高,CPU使用率也升高
四、平均负载过高时,如何调优
工具:stress、sysstat,yum即可安装
1. CPU密集型进程case:
mpstat -P ALL 5: -P ALL表示监控所有CPU,5表示每5秒刷新一次数据,观察是否有某个cpu的%usr会很高,但iowait应很低
pidstat -u 5 1:每5秒输出一组数据,观察哪个进程%cpu很高,但是%wait很低,极有可能就是这个进程导致cpu飚高
2. IO密集型进程case:
mpstat -P ALL 5: 观察是否有某个cpu的%iowait很高,同时%usr也较高
pidstat -u 5 1:观察哪个进程%wait较高,同时%CPU也较高
3. 大量进程case:
pidstat -u 5 1:观察那些%wait较高的进程是否有很多
五、其他推荐工具和命令
htop看负载,更直接(在F2配置中勾选所有开关项,打开颜色区分功能),不同的负载会用不同的颜色标识。比如cpu密集型的应用,它的负载颜色是绿色偏高,iowait的操作,它的负载颜色是红色偏高等等,根据这些指标再用htop的sort就很容易定位到有问题的进程。
atop命令,好像是基于sar的统计生成的报告,直接就把有问题的进程标红了,更直观。
六、其他问题
现在大多数CPU有超线程能力,在计算和评估平均负载的时候,CPU的核数并不是指物理核数,而是指超线程功能的逻辑核数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}
{kind=link}