数据分析基本思路
numpy是python的一个科学计算库,提供了数组和矩阵运算的能力。
pandas是python环境下最常用的数据统计包
安装包后可以直接在notebook中导入
import numpy as np
import pandas as pd
一、numpy
1.1 numpy的数据类型
数组(array):
一维数组:只有一个维度的数组,即只有一行,可以有n个列,对应该行的每一个值。
二维数组:有行、列两个维度。
1.2 常用指令
numpy.shape
计数该数组的行、列
numpy.dtype
显示该数组的数据类型
numpy.mean()
平均值
numpy.std()
标准差
numpy[0] numpy[0,0] numpy[:,0]
切片查询数组,和前面学习的切片知识一样,巩固复习即可
二、pandas
2.1. pandas的数据类型
序列(series)
创建DataFrame
可以通过定义字典来创建一个DataFrame
salesDict={}
定义字典后要排序
from collections import OrderedDict
salesOrderDict=OrdererDict()
salesDf=pd.DataFrame(salesOrderDict)
salesDf#输出数据#
2.2. 常用指令
DataFrame.shape
计数行、列
DataFrame.index
返回索引
DataFrame.describe()
获取描述统计信息
DataFrame.dropna()
删除缺失值
s3=s1.add(s2,fill_value=0)
补充缺失值
2.3. DataFram的查询
基本的查询功能同上文提到的array 的查询方式;
另外,可以通过列名,index等条件查询特定的一列或者多列
DataFrame.iloc/DataFrame.loc 条件查询
iloc功能大多可以通过loc实现,所以初学可以全部使用loc来实现想要的查询方式
DataFrame.loc[#行][#列]
切片行时需要注意,需要查询的是行编号,而不是index,使用iloc语句
主要的查询方式有,查询一个或多个列,查询一行或多行,查询指定位置
DataFrame[#指定位置].mean()
对指定位置的数据求平均值
DataFrame[#指定位置].max()
DataFrame[#指定位置].mix()
对指定位置的数据求最大最小值
三、根据实例进行简单数据分析
3.1数据分析的步骤
提出问题->理解问题->清洗数据->构建模型->数据可视化
3.1.1提出问题
制定KPI,确定要分析的值和要计算的值
1)每月平均消费次数
2)每月平均消费金额
3)客单价
3.1.2理解问题
月均消费次数=总消费次数 / 月份数
月均消费金额 = 总消费金额 / 月份数
客单价=总消费金额 / 总消费次数
3.1.3数据清理
1)选择子集
选择需要进行清洗和分析的数据部分
2)列名重命名
#字典:旧列名和新列名对应关系
colNameDict = {'购药时间':'销售时间'}
inplace=False,数据框本身不会变,而会创建一个改动后新的数据框,
默认的inplace是False
inplace=True,数据框本身会改动
salesDf.rename(columns = colNameDict,inplace=True)
3)缺失值处理
python缺失值有3种:
1)Python内置的None值
2)在pandas中,将缺失值表示为NA,表示不可用not available。
3)对于数值数据,pandas使用浮点值NaN(Not a Number)表示缺失数据。
虽然None和NaN两个都用作空值,但它们是有区别的,通过type()函数可以看到,None是Python的一种数据类型,NaN是浮点类型。
删除缺失值
通过DataFrame.dropna()删除缺失值,并比较处理前后的shape值确认
清理无意义值
#删除列(销售时间,社保卡号)中为空的行
#how='any' 在给定的任何一列中有缺失值就删除
salesDf=salesDf.dropna(subset=['销售时间','社保卡号'],how='any')
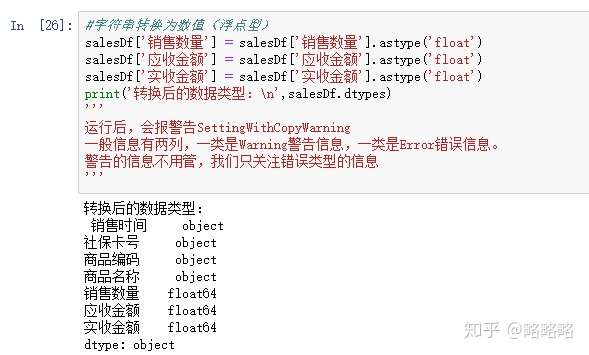
4)数据类型转换
字符串转化为浮点型数据(float)
对于数字型的数据,需要将其从字符串格式转移成float格式
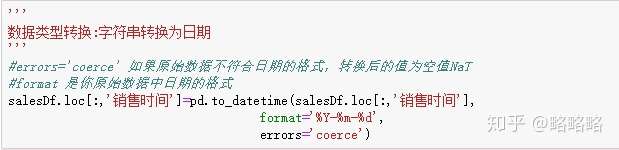
日期转化为datetime类型
通过Series.str.split()将Series内的字符串数据进行分割处理。
也可以直接定义函数,通过for循环来进行操作

清理后生成的数据是新的一列值,可通过赋值来直接修改原始值,完成后进行日期格式的修改
5)数据排序
排序语句如下,分别是排序条件,序列

需要注意的是,排序后,index值是不变的,所以需要对排序后的数据重新定义index

6)异常值处理
根据业务需求,查看describe后处理异常值
一般是通过条件筛选删除
第四步 构建模型
业务指标1:月均消费次数
月均消费次数=总消费次数 / 月份数
通过以下语句获取总消费次数

通过以下语句获取月份数


计算数据

业务指标2:月均消费金额
月均消费金额 = 总消费金额 / 月份数
总金额使用sum函数获取
业务指标3:客单价
客单价=总消费金额 / 总消费次数
以上环节已求出对应指标,计算即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号