数据分析常用术语
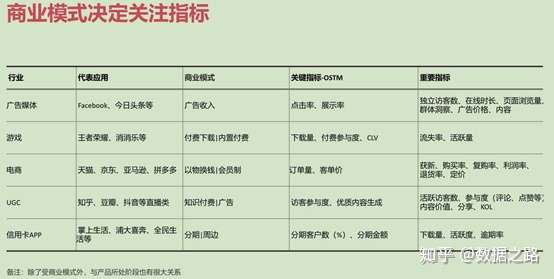
对于做数据分析的同学来说,可能没有参与搭建指标体系,但是每天会与各项业务指标打交道。不同的业务会有不同的指标衡量,如电商行业关注购买率、退货率、客单价等,而游戏行业关注下载量、付费参与度等。
下面从以下三个方面对常用的数据名词进行介绍。
- 互联网常用名词/指标
- 统计学指标
- 数据分析指标
一、互联网常用名词/指标
1. PV(Page View)页面浏览量
指某段时间内访问网站或某一页面的用户的总数量,通常用来衡量一篇文章或一次活动带来的流量效果,也是评价网站日常流量数据的重要指标。PV可重复累计,以用户访问网站作为统计依据,用户每刷新一次即重新计算一次。
2.UV(Unique Visitor)独立访客
指来到网站或页面的用户总数,这个用户是独立的,同一用户不同时段访问网站只算作一个独立访客,不会重复累计,通常以PC端的Cookie数量作为统计依据。
从这里可以看到PV和UV的区别,PV可重复累计,而UV不会重复累计
3.Bounce Rate 跳出率
指用户通过链接来到网站,在当前页面没有任何交互就离开网站的行为,这就算作此页面增加了一个“跳出”,跳出率一般针对网站的某个页面而言。
跳出率=在这个页面跳出的用户数/PV
4.退出率
指用户访问某网站的某个页面之后,从浏览器中将与此网站相关的所有页面全部关闭,就算此页面增加了一个“退出“。退出率=在这个页面退出的用户数/PV。
5.CTR 点击率
指某个广告、Banner、URL被点击的次数和被浏览的总次数的比值。一般用来考核广告投放的引流效果。CTR=点击数(click)/被用户看到的次数
6.Conversion rate 转化率
指用户完成设定的转化环节的次数和总会话人数的百分比,通常用来评价转化的好坏。转化率较低则急需优化该转化环节。转化率=转化会话数/总会话数
7.投资回报率(ROI:Return On Investment )
衡量投入与产出的关系,投资是否值得。公式为:投资回报率(ROI)=年利润或年均利润/投资总额×100%,通常用来评估某项项目/活动的价值。
8.重复购买率:指消费者在网站中的重复购买次数。
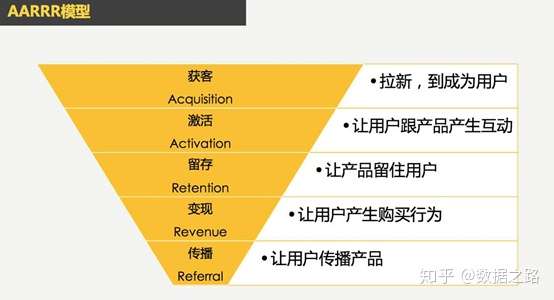
9.漏斗:如在京东商城购物,从点击商品链接到查看详情页,再到查看顾客评价、领取商家优惠券,再到填写地址、付款,每个环节都有可能流失用户,这就要求商家必须做好每一个转化环节,漏斗是评价转化环节优劣的指标、也可以很直观的看到哪个环节存在问题,并进行针对性改善。
10.流失分析(Churn Analysis/Attrition Analysis)
哪些顾客可能停止使用公司的产品/业务,以及识别哪些顾客的流失会带来最大损失。流失分析的结果用于为可能要流失的顾客准备新的优惠。
11.用户画像(Customer Segmentation & Profiling)
根据现有的顾客数据,将特征、行为相似的顾客归类分组。描述和比较各组。也有为用户打标签,如高潜力客户、低潜力客户;土豪客户、促销敏感客户、屌丝客户等,每个企业会根据不同为维度进行细分打标签。
12.用户命周期价值 (Lifetime Value, LTV)
顾客在他/她的一生中为一个公司产生的预期折算利润。
3.购物篮分析(Market Basket Analysis)
交易中经常同时出现的商品组合或服务组合,例如经常被一起购买的产品,被杜撰的额“啤酒与尿布”的故事。此类分析的结果可以为商品陈列提供决策支持。
14.实时决策(Real Time Decisioning, RTD)
帮助企业做出实时(近乎无延迟)的最优销售/营销决策。比如,实时决策系统(打分系统)可以通过多种商业规则或模型,在顾客与公司互动的瞬间,对顾客进行评分和排名。
15.Referrer 引荐流量
将用户引导至目标页面的URL(超链接),如最近的知乎好物推荐,可以在回答、文章中插入购入链接,将用户引流至京东、淘宝、拼多多等平台,从而赚取佣金。
二、 统计学名词解释
1、同比和环比
同比:指的是与历史同时期的数据相比较而获得的比值,反应事物发展的相对性
环比:指与上一个统计时期的值进行对比获得的值,主要反映事物的逐期发展的情况
2、频数和频率
频数:一个数据在整体中出现的次数。
频率:某一事件发生的次数与总的事件数之比。频率通常用比例或百分数表示。
3.百分比和百分点
百分比:是相对数中的一种,他表示一个数是另一个数的百分之几,也成为百分率或百分数。百分比的分母是100,也就是用1%作为度量单位。如服装销售占平台销售额的20%。
百分点:是指不同时期以百分数的形式表示的相对指标的变动幅度,1%等于1个百分点,如今年销售额比去年增长5个百分点,其实就是增长了5%。
4.比例与比率
比例:是指在总体中各数据占总体的比重,通常反映总体的构成和比例,即部分与整体之间的关系。比率:是样本(或总体)中各不同类别数据之间的比值,由于比率不是部分与整体之间的对比关系,因而比值可能大于1
5.连续变量VS离散型变量
统计学中,按变量值是否连续可分为连续变量与离散变量两种。在一定区间内可以任意取值的变量叫连续变量,其数值是连续不断的,相邻两个数值可作无限分割,即可取无限个数值。如:年龄、体重等变量。
6、均值
平均数是表示一组数据集中趋势的量数,是指在一组数据中所有数据之和再除以这组数据的个数。
7.中位数:对于有限的数集,可以通过把所有观察值高低排序后找出正中间的一个作为中位数。如果观察值有偶数个,通常取最中间的两个数值的平均数作为中位数。
8.均值:即平均值,平均数是表示一组数据集中趋势的量数,是指在一组数据中所有数据之和再除以这组数据的个数。
9.缺失值:它指的是现有数据集中某个或某些属性的值是不完全的,可能在数据采集中出现错误、或者被人为的删除。
10.缺失率:某属性的缺失率=数据集中某属性的缺失值个数/数据集总行数。
11.异常值
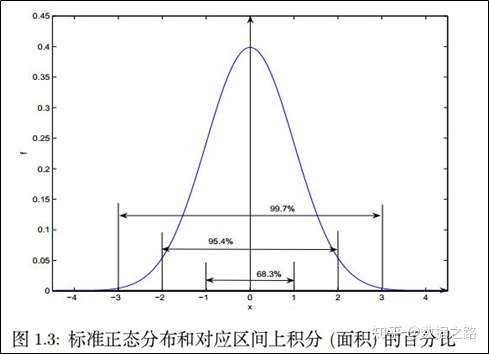
指一组测定值中与平均值的偏差超过两倍标准差的测定值,与平均值的偏差超过三倍标准差的测定值,称为高度异常的异常值。经常用于品质检验中,在上一家公司,只要数据超过3西格玛,就要写报告向品质部门解释。
12.方差:统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。在许多实际问题中,研究方差即偏离程度有着重要意义。方差是衡量源数据和期望值相差的度量值。
13.标准差:用σ表示。标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。平均数相同的两组数据,标准差未必相同。
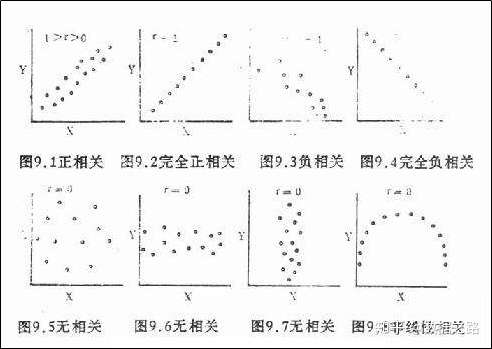
14.皮尔森相关系数:用来反映两个变量线性相关程度的统计量。相关系数用r表示, r描述的是两个变量间线性相关强弱的程度。
15重数和众数
给定含有n个元素的多重集合S,每个元素在S中的次数称为该元素的重数。多重集S中重数最大的元素称为众数。
三、数据分析专业名词解释
聚合(Aggregation):搜索、合并、显示数据的过程。
算法(Algorithms):可以完成某种数据分析的数学公式。
异常检测(Anomaly detection):在数据集中搜索与预期模式或行为不匹配的数据项
匿名化(Anonymization):使数据匿名,即移除所有与个人隐私相关的数据。
客户关系管理(CRM):用于支持决策,改善公司跟顾客的互动或提高互动的价值。
行为分析法(Behavioural Analytics):这根据用户的行为如“怎么做”,“为什么这么做”,以及“做了什么”来得出结论,而不是仅仅针对人物和时间的一门分析学科,它着眼于数据中的人性化模式。
商业智能(Business Intelligence): 分析数据、展示信息以帮助企业的执行者、管理层、其他人员进行更有根据的商业决策的应用、设施、工具、过程。
云计算(Cloud computing):网络上的分布式计算系统,数据是存储于机房外的(即云端)。
集群计算(Cluster computing):这是一个使用多个服务器集合资源的“集群”的计算术语。要想更技术性的话,就会涉及到节点,集群管理层,负载平衡和并行处理等概念。
聚类分析(Clustering analysis):它是将相似的对象聚合在一起,每类相似的对象组合成一个聚类(也叫作簇)的过程。这种分析方法的目的在于分析数据间的差异和相似性。
冷数据存储(Cold data storage):在低功耗服务器上存储那些几乎不被使用的旧数据。但这些数据检索起来将会很耗时。
相关性分析(Correlation analysis):是一种数据分析方法,用于分析变量之间是否存在正相关,或者负相关。
仪表板(Dashboard):使用算法分析数据,并将结果用图表方式显示于仪表板中,制造业常用于生产看板。
数据聚合工具(Data aggregation tools):将分散于众多数据源的数据转化成一个全新数据源的过程。
暗数据(Dark Data):基本上指的是,由企业收集和处理的,但并不用于任何意义性目的的数据,因此它是“暗”的,可能永远不会被分析。它可以是社交网络反馈,呼叫中心日志,会议笔记等等。有很多人估计,所有企业数据中的 60-90% 可能是“暗数据”。
数据挖掘(Data mining):通过使用复杂的统计学习方法,结合商业实践,并得出大量数据的见解。
数据清洗(Data cleaning):对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
数据质量(Data Quality):确保数据可靠性和实用价值的过程和技术。高质量的数据应该忠实体现其背后的事务进程,并能满足在运营、决策、规划中的预期用途。
数据集市(Data Mart):进行数据集买卖的在线交易场所。
分布式文件系统(Distributed File System):提供简化的,高可用的方式来存储、分析、处理数据的系统。
提取-转换-加载(ETL:Extract,Transform and Load):是一种用于数据库或者数据仓库的处理过程,即从各种不同的数据源提取(E)数据,并转换(T)成能满足业务需要的数据,最后将其加载(L)到数据库。
Hadoop:一个开源的分布式系统基础框架,可用于开发分布式程序,进行大数据的运算与存储。
Hadoop数据库(HBase):一个开源的、非关系型、分布式数据库,与Hadoop框架共同使用。
HDFS:Hadoop分布式文件系统(Hadoop Distributed File System);是一个被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。
高性能计算(HPC:High-Performance-Computing):使用超级计算机来解决极其复杂的计算问题。
物联网(IoT):最新的流行语是物联网(IOT)。IOT通过互联网将嵌入式对象(传感器,可穿戴设备,汽车,冰箱等)中的计算设备进行互连,并且能够发送以及接收数据。IOT生成大量数据,提供了大量大数据分析的机会。
日志文件(Log file):由计算机系统自动生成的文件,记录系统的运行过程。
自然语言处理(Natural Language Processing):是计算机科学的一个分支领域,它研究如何实现计算机与人类语言之间的交互。
平台即服务(PaaS:Platform-as-a-Service):为云计算解决方案提供所有必需的基础平台的一种服务。
软件即服务(SaaS:Software-as-a-Service):基于Web的通过浏览器使用的一种应用软件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号