

出自小宫的博客
fhq Treap(非旋Treap)
前面已经讨论过了treap,那已经是一种非常好写而优秀的算法了,但是下面要讨论的非旋treap比普通treap更好写,时间也差不多,最重要的,非旋treap可以像splay一样维护区间信息,因此除了LCT,所有的splay几乎都可以被非旋Treap代替
(非旋Treap又名fhq Treap,是因为这个算法是由神犇范浩强在大约十年前发明的)
非旋Treap的核心操作有二:split(分裂)和merge(合并),树的结构只有在这两种情况下才会改变,而这两种情况可以做到维护堆性质等随机化操作,从而改善树的平衡性
分裂(split)
不妨考虑下图这棵BST树:
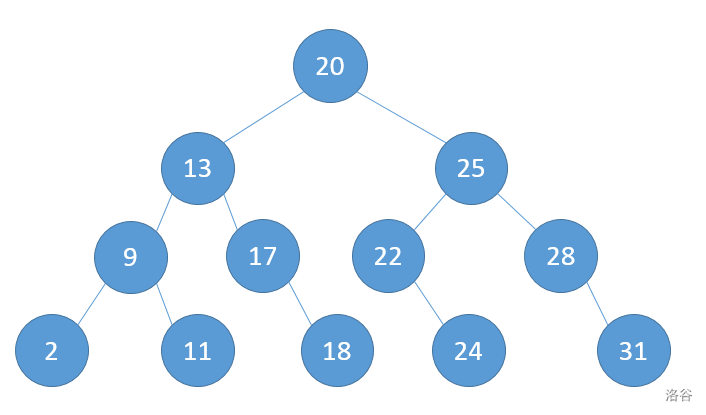
分裂操作有两种方式:按值分裂和按排名分裂 具体含义就是把值小于等于分裂值的节点或者排名小于分裂排名的节点都分到树的一边,剩下节点分到另一边
将树分裂成A树和B树,x记录A树中最新(最后进来的满足<=val)的节点,y记录B树中最新的节点。
接下来我们尝试对这棵树进行按22这个值分裂:
设我们目前走到的节点为p,由于要分成两个树,所以用两个指针,首先p走到根,根的值20小于22,因此应在A树中,而根的左子树都比根小,因此都在A树中,因此有:
然后考虑指针的转移,由于x的左子树已经都是A树中的节点了,因此a[p].l是不用修改的,有可能修改的就只有a[p].r,因此把a[p].r作为指针x传递下去,走根的右子树.
void split (int p, ll val, int &x, int &y){
if(a[p].v <= al) x=p,split(a[p].r,val,a[p].r,y);
else y=p,split(a[p].l,val,x,a[p].l);
}
如果a[p].v <= al,将a[p].r一直传下去"split(a[p].r,val,a[p].r,y)";
直到a[p].v > al, 则将A树中最后一个结点一直传下去(split(a[p].r,val,x,y)中的x),且这个值就是A树中最后的a[p].r。
因此参数的传递过程是这样的:
a[p].r -> ……->a[p].r (最后一个a[p].r)-> x ->…… -> x = p( 当a[p].v <= al,x=p,倒推回去即a[p].r = p)
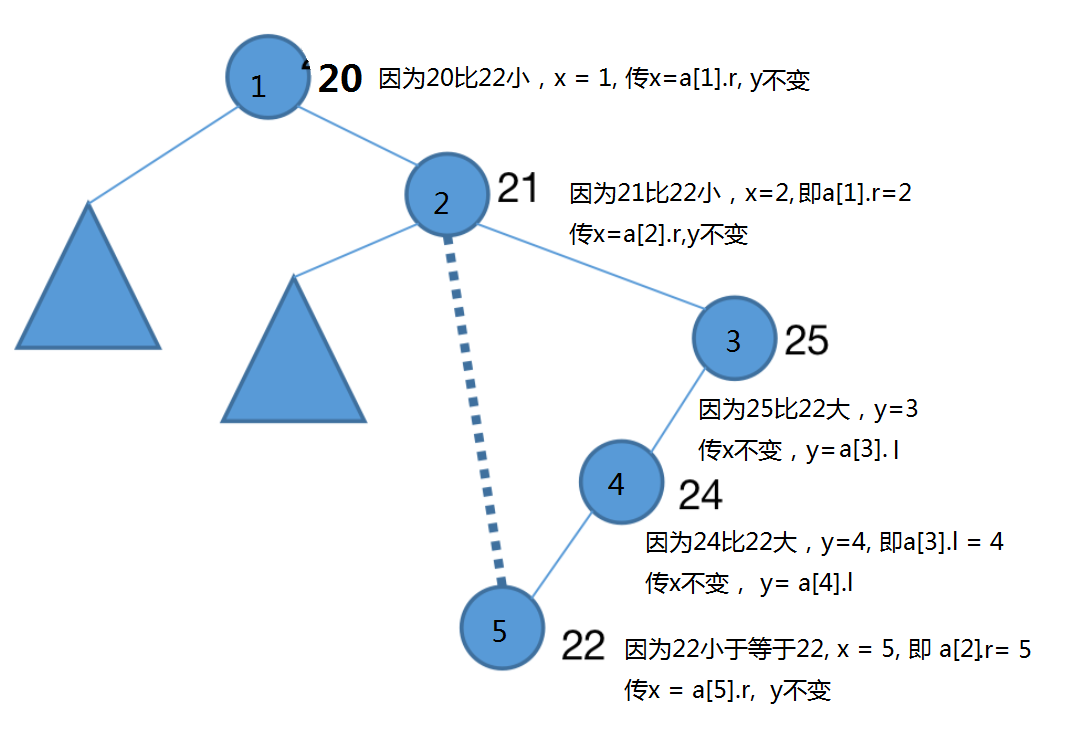
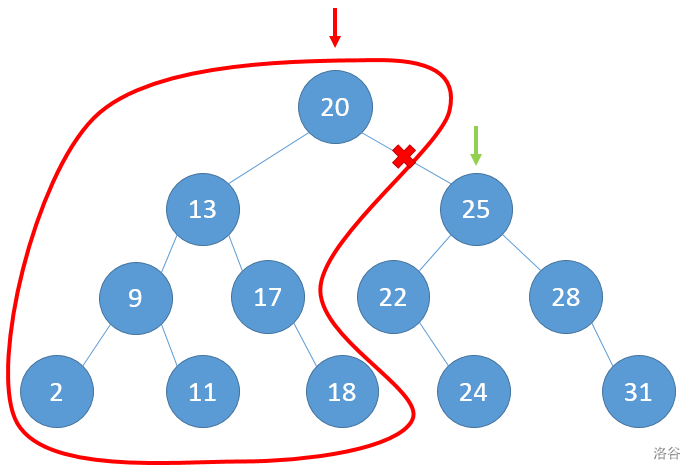
p走到25节点处,发现25大于22,因此25应分到B树中,而25的右子树都比25大,所以25的右子树都会分到B树中,因此要修改a[p].l,所以指针y设置为a[p].l,并且p走25的左子树
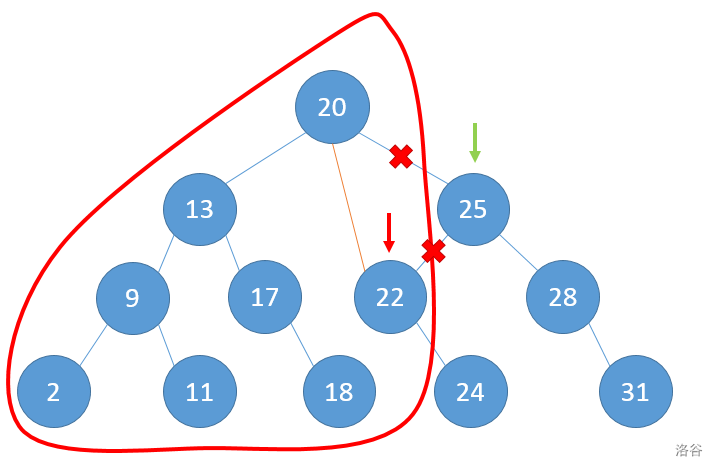
p走到22节点处,由于我们的判断是小于等于分裂值的值都分到A树中,所以22也分到A树中,这时就可以使x(也就是a[root].r)指向22了,然后这时就可以向右子树走,并且把x设为a[p].r,p向右子树走
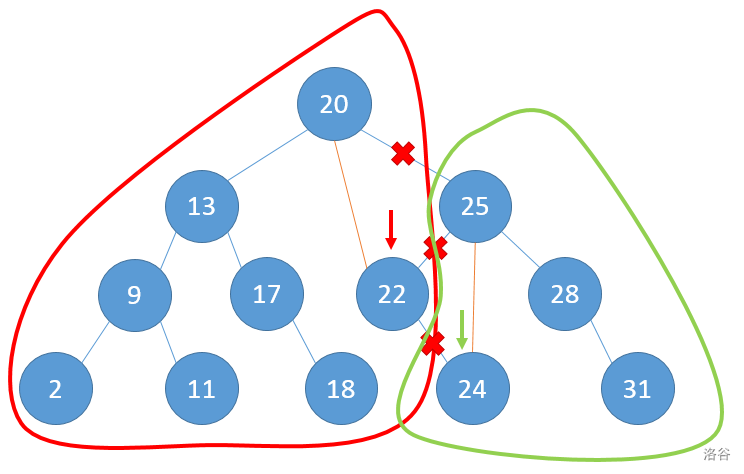
p走到24节点处,根据刚才的原理,y代表的25的左子树会连上24,24会被分到B树中,p再走x的左子树,却会走到0,这说明底下没有节点可以再分了,因此x代表的22的右子树和y代表的24的左子树都会指向空,这样,AB两棵树就分离完成了
还有另外一种情况——一条链
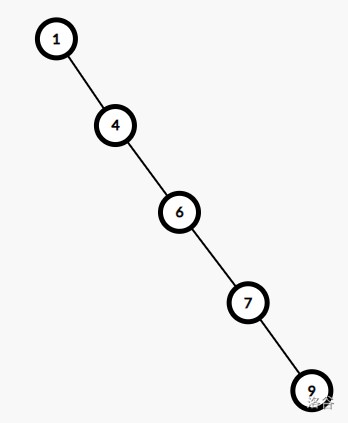
如果以6为分裂值,x指针就会一直下传一直到7,然后y会指向7,接着搜7的左子树为0,因此x(6的右指针)和y(7的左指针)都会指向空,这样整个树就被划分成两个了
因此有代码:
void split(int p,ll val,int &x,int &y){//这里的引用相当于上文中的指针(引用相当于指针常量)
if(p==0)x=y=0;//搜完了,把x和y两个引用指向空
else if(a[p].v<=val)x=p,split(a[p].r,val,a[p].r,y);
//当前节点值小于等于分裂值,要分到A树中,上一个A树节点的右孩子要指向当前节点。继续递归的时候把这个节点当做上一个A树节点,用a[p].r代替x,这样后面可以直接修改当前节点的右子树指针
else y=p,split(a[p].l,val,x,a[p].l);//同上,分到B树,上一个B树节点的左孩子要指向当前节点,用a[p].l代替y,理由同上
up(p);//分裂以后只有经过节点的左右子树会改变,因此回溯的时候只要把它们up即可
return;
}调用split的时候,可以找两个变量填充在x和y的引用位置,相当于运行以后这两个变量会自动指向两个树的根
合并(merge)
话说天下大势,分久必合,合久必分
合并相当于分裂的逆过程,因此只需要用x,y两个指针检查,由于根据分裂的原理,A树中的元素总比B树中的元素小,因此直接判断x节点接在y的左子树还是y接在x的右子树上就行了
那么这两种情况的选择怎么办呢?其实这里就是Treap随机化的核心,通过某些操作把这一步随机化,就可以保证树的平衡
第一种随机方法:优先级/修正值
这个值和旋转Treap里面那个完全一样,就是为了保证合并的时候整棵树的堆性质。
例如维护大根堆,AB两树都是满足堆性质的,因此合并时如果x的值大,x应放在原树这一位置,否则y应放在原树这一位置
例如x放在这一位置后,由于y树的值都比x树大,因此合并后y树节点应都在x的右子树中,应继续递归x的右子树,看看如何和y合并
y放在原树的这一位置同理
因此有:
int merge(int x,int y){
if(!x||!y)return x+y;//有一个为空,直接返回另一个,或者两个都为空时返回空
if(a[y].dat>=a[x].dat){//y的优先级比x大,把y留在原树的这一位置
a[y].l=merge(x,a[y].l);//继续递归合并y的左子树和x,并接到y的左子节点上
up(y);//更新y
return y;//返回y
}else {
a[x].r=merge(a[x].r,y);//继续地柜合并x的右子树和y,并接到x的右子节点上
up(x);//更新x
return x;//返回x
}
}(感谢LJC00101大佬的hack)
第二种随机方法:随机合并
这种方法不需要rand出优先级:
int merge(int x,int y){
if(!x||!y)return x+y;//先返回,避免后面size取模出问题
int rd=std::rand()%(a[x].size+a[y].size);//rand出一个在0~合并后树的大小的值
if(rd<a[y].size){//如果rand出的值在y树的大小内,就把y放在x上面(可以这么想:如果y树的大小占总共的比例大,那么rd就更有可能比y的大小小,因此rd比y树大小小的时候,y更有可能比x更大,为了保证平衡y要在上面先放进原树)
......ps.随机合并非常卡常,会导致性能大幅下降,一般不要使用(感谢MatixCascade大佬的hack)
有了merge和split操作,剩下的操作就可以直接完成了
建树与加入节点
非旋Treap有一个特性——可以加入多个值相同的点
因此不用考虑cnt的情况了,插入的时候直接新来一个节点,删除的时候也直接把其中一个删掉即可
建树也不必用正无穷和负无穷两个节点了(如果有这两个size为0的节点,插入第一个节点合并的时候随机合并取模会出问题),直接往空树里加节点即可
插入(insert)
可以用插入值split一下,分成小于等于插入值和大于插入值的两棵树AB,把插入值插入到A树以后再把两个树合并即可
因此有:
void insert(ll val){
int x,y;
split(root,val,x,y);//把x、y放在引用位置相当于自动变成两个分树的根
root=merge(merge(x,newnode(val)),y);//先合并新建的val值节点和A树,再把A树和B树合并
return;
}删除(Delete)
fhqTreap的一大好处就是删除非常简单
若删除值为val:
- 把树用val分裂为两个分树AB,要删除的节点一定在A树中
- 把A树用val-1分裂为两个分树CD,要删除的节点一定在D中
- 这时候D中的节点的值一定都等于删除值,但是由于非旋Treap可重,所以D树中可能有多个节点,因此先把D树的根的两个孩子合并,然后把根删掉即可
- 最后把CDB三个树按顺序合并即可
因此有:
void Delete(ll val){
int x,y,z;
split(root,val,x,z);//分成两个树AB
split(x,val-1,x,y);//A树分成两个树CD
y=merge(a[y].l,a[y].r);//D树中节点全都是val,因此删根(y指向两个孩子合并形成的树的根)
root=merge(merge(x,y),z);//先合并CD两个树形成A',然后合并A'B
return;
}用值查询排名(rank)
由于我们分裂用的就是值,因此直接用查询值-1分裂成两棵树AB,A树中任意节点都比val要小,B树中任意节点都大于等于val,因此rank就是A树的大小
因此有:
int rank(ll val){
int x,y,rk;
split(root,val-1,x,y);
rk=a[x].size+1;
root=merge(x,y);
return rk;
}用排名查询值(rerank)
可以仿照上面,写一个按排名分裂的split函数,不过这样更麻烦,不如直接用以前的rerank就可以了
int rerank(int x,int rk){
if(a[a[x].l].size+1>rk)return rerank(a[x].l,rk);
else if(a[a[x].l].size+1+1<=rk)
return rerank(a[x].r,rk-a[a[x].l].size-1);
else return x;
}查询前驱(fpre)
先把树按照查询值val-1分裂成两棵树,前驱一定是小树中排名最大的那一个,直接用rerank函数即可
因此有:
int fpre(ll val){
int x,y,an;
split(root,val-1,x,y);//按val-1分裂
an=rerank(x,a[x].size);//查找小树中有小树大小-1个节点值比他小的节点,就是val的前驱
root=merge(x,y);
return an;
}查询后继(fnxt)
先把树按照查询值val分裂成两棵树,然后在大树中找最小的那一个即可
因此有:
int fnxt(ll val){
int x,y,an;
split(root,val,x,y);//按val分裂
an=rerank(y,1);//查找大树中值最小的节点,就是val的后继
root=merge(x,y);
return an;
}至此,整个非旋Treap就构造完成了
平衡树维护区间(非旋Treap)
这里只讲一下最好写的非旋Treap维护区间,其他的维护方式原理也是相同的
如果要对一个区间的数进行修改的话,我们显然不能把原数都从平衡树里面删掉,然后把新数插入
因此想到了平衡树的另一个性质:如果用排名维护平衡树,一个节点在平衡树中的排名是不变的
也就是说,如果我们维护一个这样的BST,用序列下标当关键值,每个位置再单独维护一个该下标处的序列元素的值即可。
但是这样只能处理对值操作的情况,如果出现改变序列顺序的操作(如翻转某一区间),怎样处理呢?
可以发现,如果不进行任何操作,这棵BST的某一节点序列下标(关键值)就是它在这棵树中的排名位置(rank函数得到的值),如果对这棵BST的树形结构进行修改,虽然不能满足依赖于某个关键值的BST性质,但是我们可以在进行操作的过程中保证某一节点在这棵树中的排名位置就是它对应的节点下标
例如,对于序列5,4,3,2,1,如果我们翻转下标2~4的区域,我们可以直接把树中排名为3的节点的左右子树(下标为2值为4的节点和下标为4值为2的节点)调换位置,这样原来下标为4(值为2)的节点的新的下标就变成它的新排名2了,同理原来下标为4(值为2)的节点的新的下标就变成它的新排名4了,在这个过程中我没法很快改变下标,索性就不记录每个节点对应的下标了,直接用每个点的排名代替下标也是正确的。
这个方法的核心在于我们要保证以下性质:
- 平衡树的中序遍历就是对整个区间的遍历
- 通过性质1可以得到平衡树中每个节点的排名等于它对应的下标(中序遍历会先把一个节点的下标前面所有的下标对应的节点先遍历,而rank函数返回的就是一个节点前面会有多少节点先被中序遍历)
因此开始建树的时候要把下标按在序列当中的位置插入(按排名插入),这样保证了新树中每个节点的排名就等于它对应的下标
而splay,split,merge这些平衡树内操作并不会改变一个节点在树中的排名,因此不必担心出问题(当然split的时候要按排名split因为我们建的是排名平衡树)
还有一点,如果我们每次操作都要把平衡树中操作涉及到的节点都处理一遍,显然是一次就需要On的时间复杂度,因此借用线段树的方法——设置lazy tag,这样需要操作的时候打一个标记,下次遇到这个节点的时候pushdown即可
P3391文艺平衡树
这道题就是纯粹的区间翻转问题,因此用到我们刚才说的性质“每个节点在树中的排名就是这个节点对应的区间下标”
这样的话如果想翻转一个区间,只需要把整棵树按排名分成[1,l-1],[l,r],[r+1,n]三部分,然后直接交换中间那棵树的根的左右子树并继续递归左右子树即可(试想,我们最后是要输出平衡树的中序遍历,那么把x的左右子树交换之后就相当于在序列之中把rank(x)那个位置的左边和右边交换了一下位置,继续递归两边交换相当于就是分治的思路)
当然,如果每次都这么递归操作时间复杂度肯定爆炸,因此我们打个lazy标记,记录当前这个节点的左右子树需不需要交换,然后在进行split和merge的过程中pushdown即可
最后还要注意插入一个0节点和n+1节点以处理翻转1或n的情况
这里用到了一个新操作:
按第k名split
其实跟查找排名对应的值(rerank)是基本一致的,除了考虑一下正好查到排名为rk的值的时候的情况即可,在这里是把这个节点也分到x树中了
另外,这个程序中rk代表的不是排名,而是它前面有多少个数(也就是排名-1)
void split(int p,int rk,int &x,int &y){
reverse(p);
if(!p)x=y=0;
else if(a[a[p].l].size+1<=rk)x=p,split(a[p].r,rk-a[a[p].l].size-1,a[x].r,y);
else y=p,split(a[p].l,rk,x,a[y].l);
return up(p);
}
#include<bits/stdc++.h>
#define N 100010
class FHQ{
public:
int rt,tot;
class node{
public:
int l,r,v,size,dat,rev;
}a[N];
void reverse(int x){
if(a[x].rev){
a[x].l^=a[x].r^=a[x].l^=a[x].r;
a[a[x].l].rev^=1,a[a[x].r].rev^=1;
}a[x].rev=0;
return;
}int newnode(int val){
a[++tot].v=val,a[tot].dat=std::rand(),a[tot].rev=0,a[tot].size=1;
return tot;
}void up(int x){
if(x)a[x].size=a[a[x].l].size+a[a[x].r].size+1;
return;
}void split(int p,int rk,int &x,int &y){
reverse(p);
if(!p)x=y=0;
else if(a[a[p].l].size+1<=rk)x=p,split(a[p].r,rk-a[a[p].l].size-1,a[x].r,y);
else y=p,split(a[p].l,rk,x,a[y].l);
return up(p);
}int merge(int x,int y){
reverse(x),reverse(y);
if(!x||!y)return x+y;
if(a[x].dat<a[y].dat){
a[x].r=merge(a[x].r,y),up(x);
return x;
}else {
a[y].l=merge(x,a[y].l),up(y);
return y;
}
}void insert(int val){
rt=merge(rt,newnode(val));
return;
}void reverse(int l,int r){
int x,y,z;
split(rt,r,x,z),split(x,l-1,x,y);
a[y].rev^=1;
rt=merge(merge(x,y),z);
return;
}void dfsprint(int x){
if(!x)return;
reverse(x);
dfsprint(a[x].l);
printf("%d ",a[x].v);
dfsprint(a[x].r);
return;
}
}tr;
int n,m;
int main(){
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++)tr.insert(i);
for(int i=1;i<=m;i++){
int l,r;
scanf("%d%d",&l,&r);
tr.reverse(l,r);
}tr.dfsprint(tr.rt);
return 0;
}平衡树非常适合用于维护会插入中间节点的区间
——未完待续
发表于 2020-12-26 17:34:26 in 算法竞赛进阶指南


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架