softmax和softmax loss的学习记录
0. 喜洋洋
小黑喵教程3之卷积神经网络中的softmax函数和softmax loss。在CNN完成MNIST手写识别的实验中,我们的loss函数选用了softmax loss,但没有多作说明。今天特别的把这一点内容补上,小白喵要认真听课哦。
听到softmax不禁就会想起max。要区别两者的关系,打个最通俗的比方:max是一个很专一的人,无论有多少的输出,它也只会对应一个输出;而softmax不同,它会把所有的输入当做“备胎“,给每一个输入打分,输出为等同输入长度的向量,每个元素值域为[0,1],且加和为1(例如CNN的MNIST实验中,某一个图片对应0-9十个分类的概率)。
对softmax这个渣男有了基本认识之后,就需要对其公式和loss函数公式进行简单的讲解了。不要怕公式,放平心态其实挺简单的。
1. 灰太狼
1.1 softmax
首先回忆一下softmax出现在网络的哪个位置。前面也讲了,他是最后做“分类预测”(打分)时出现,所以肯定是神经网络完成“卷积-池化-全连接层”之后。所以它接收的输入为全连接层输出的向量。
在CNN的MNIST实验中,可以理解为softmax就是接收了最后一个全连接层10维向量的输出。之前全连接层的输出每个元素的值可能千奇百怪并不是在[0,1]之间,当然值越大代表某个数字的概率也就越大。softmax要做的其实就是把这组10维向量经过一个数学公式进行归一化。
softmax公式如下:
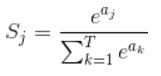
上式中,Sj为10维向量的第j维对应的softmax输出,aj为第j维向量原来的值,分母中即为所有的该向量的总和(归一化,在MNIST例子中T=10)。所以每一个Sj均在[0,1]直接,且加和为1。
举个例子,对于一个3分类的问题。如果最后一层全连接输出为(1,2,3),那么经过softmax函数之后输出为(0.09,0.24,0.67)。这就代表了它属于第3类的概率最高。
丹丹可能会疑惑。既然(1,2,3)已经能好好的表达属于哪个概率最大了,为什么还要softmax呢。第一是为了归一化,方便设计loss函数;第二是在神经网络训练减少loss时,方便求导(减少loss就是按照梯度下降最快的方式,softmax loss函数求导性质比较好,所以优化相对简单),先简单这么理解吧,需要发论文的时候这一块要更深入的了解。
1.2 softmax loss
讲完softmax后感觉softmax loss就很容易了,就是一个数学定义式。loss函数是为了做什么,不就是记录预测值和真实值的差距吗。定义为:
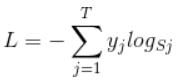 上式中,L代表softmax loss。Sj就是1.1中介绍的softmax输出,yj代表这幅图片属于哪个类(也就是说,MNIST例子中,yj这个10维向量只有1个元素为1,其他都为0)。所以上式简单表达为:
上式中,L代表softmax loss。Sj就是1.1中介绍的softmax输出,yj代表这幅图片属于哪个类(也就是说,MNIST例子中,yj这个10维向量只有1个元素为1,其他都为0)。所以上式简单表达为:
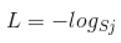 最后softmax loss就变为了softmax输出中打分最高的一维的log函数取负。对应的实际意义是什么呢,我们可以先看看-log函数的图像:
最后softmax loss就变为了softmax输出中打分最高的一维的log函数取负。对应的实际意义是什么呢,我们可以先看看-log函数的图像:
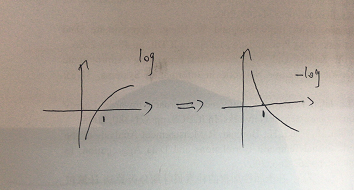 我们的Sj是处于[0,1]之间,对于loss函数来说,Sj越大(网络预测的概率越大,越准),那么L的值就越小;相反L的值越大。例如,Sj=0.6和Sj=0.3都是归类到数字1,但是前者的L值更小代表它预测得更准。所以当我们训练很多轮加强网络深度之后,对于MNIST这个例子,最好的效果就是让softmax输出类似于(0.99,0,0,0,0,0,0,0,0,0,0),这样L值无限趋近于0。
我们的Sj是处于[0,1]之间,对于loss函数来说,Sj越大(网络预测的概率越大,越准),那么L的值就越小;相反L的值越大。例如,Sj=0.6和Sj=0.3都是归类到数字1,但是前者的L值更小代表它预测得更准。所以当我们训练很多轮加强网络深度之后,对于MNIST这个例子,最好的效果就是让softmax输出类似于(0.99,0,0,0,0,0,0,0,0,0,0),这样L值无限趋近于0。
2. 我只是一只喵
我也学到了很多东西,当然也愿意和丹丹分享。如果有不明白的地方一定要和小黑喵讨论。好啦,今天的内容就到这里了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号