Lenet-5的学习记录
0. 红豆生南国
最近没什么动力,在虚机上把几个网络的NLP应用跑了一下,基本过程算和部分的数学推导算是了解了。突然想起某只喵要学习Lenet-5的东西,周一下午的课也拿着之前打印的论文呢,突然像找到了这个阶段的意义一样。之前也用CNN实战了一些,我可能会学得快一点。写这篇博文希望能一点一滴从细节上帮助某只喵理解好这个经典的网络(不要,不,拒绝,没有,不存在,guna~)。从原理到代码实战,我会认真推敲好用猫咪一定能弄明白的方式好好做完这篇博文的。
这是我第一次写博客,以前我总是太自我又只看中结果。现在我想要更多的分享我的学习和思考过程。
1. 春来发几枝
1.1 网络结构
小猫咪十天前告诉我,小徐老师让她开始看LeNet,我不知道那是啥。LeNet-5是一种典型的用来识别数字的卷积网络,一些实验结果和paper参考(http://yann.lecun.com/exdb/lenet/index.html)。查了一下,发现这个东西是很有实际应用的,上个世纪开始美国有很多银行都用这个技术来进行手写数字识别。我想起老杨以前给我“看的”MNIST手写识别....能达到92+上限的准确率,哈哈哈,那个太古老了,现在用python一个库都解决了。作为当时革命性的技术,对LeNet的学习无疑是给卷积神经网络打下基础。
不管是哪个网络,其网络结构决定了它的作用和特点效益,决定它记录信息的方式(dropout率等等参数,对信息的不同采集方式等)。在用tensorboard读取训练好的模型时也能够清晰的画出网络的graphic。
LeNet-5总共分为7层(不含输入层的话),如图1。网上很多的博客和教程也有,我想用我的语言和理解来重现一遍。
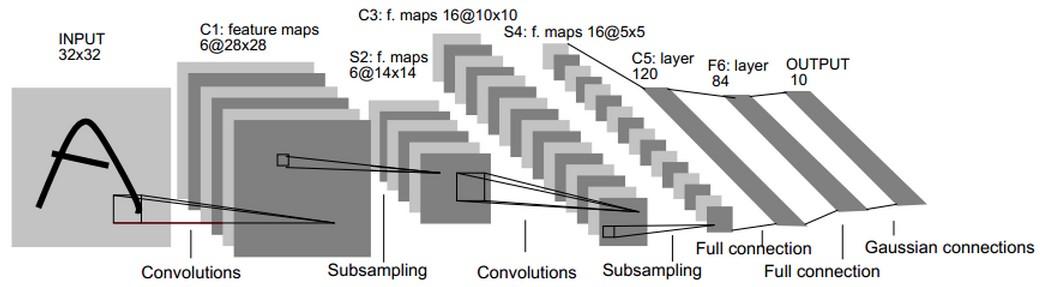 图1 LeNet网络结构
图1 LeNet网络结构
第一层为卷积层(C1:feature maps)。它接收原始输入的图片,原始图片的尺寸为32*32*1的灰度图像。然后一个小filter像传感器一样(滑动窗口固定大小为5*5)以步长为1深度为6(6个不同参数的窗口,为了提取不同传感条件下的局部信息。其现实意义就是光照啊黑暗啊我都能提取图片的信息,增加鲁棒性),慢慢的对原始图像进行采集(卷积,为了压缩和局部信息提取),见图2示例。所以可以想见,对于一次采集(共6次),窗口每次滑动都像图2一样算出一个数字,那么它形成28*28(横竖方向都是32-5+1=28如图3,不补充0所以窗口到达边缘就前往下一行)的一个矩阵如图1。6次采集就对应第一层的结果28*28*6。
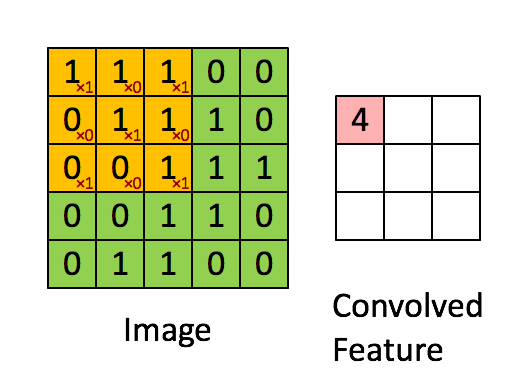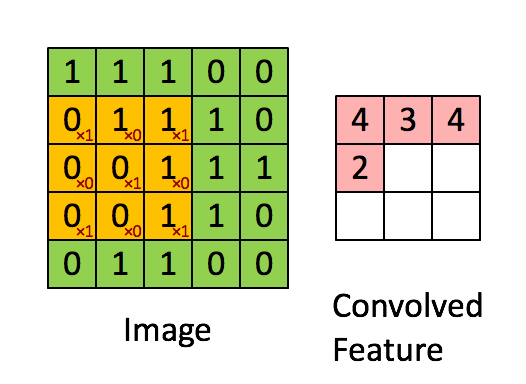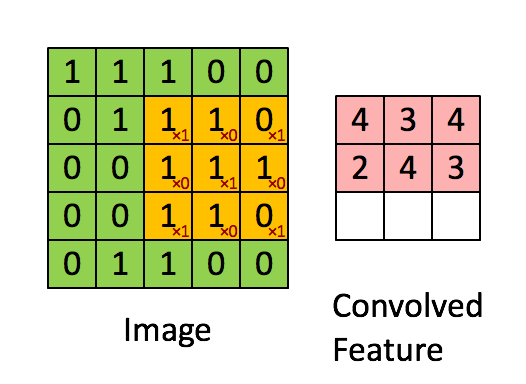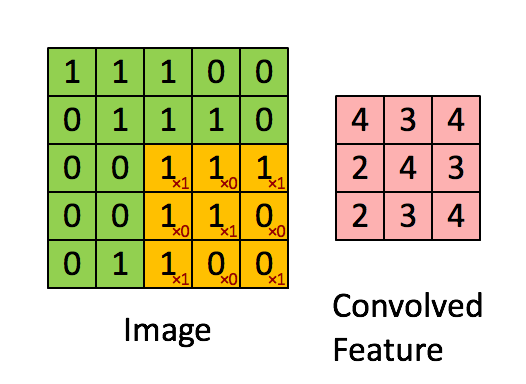
图2 滑动窗口的卷积过程
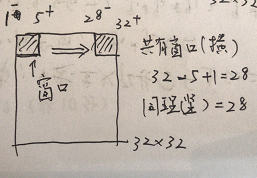
图3 数量问题
第二层称为池化层,简单来说就是降采样的。使用的方法和第一层差不多,相当于提取特征后再提特征。同样使用卷积,旨在降维时尽可能的保证信息不丢失。这层中的filter大小为2*2,步长为2(即不再有任意两个窗口重叠)。所以第二层的输出为大小为14*14*6(28/2=14)。
第三层依然为卷积层,使用的方法无非也是使用更多个数、不同的滑动窗口去采样,主要是为了增加冗余和鲁棒性。这一层filter的大小为5*5,共有16个不同的窗口,步长为1。所以本层的输出为10*10*16。(14-5+1=10同图3)
第四层还是池化层,降采样。其实看到这里发觉,以前的网络偏简单,所以大多是以重复的方式来增加复杂度(可以理解为冗余信息或者信息熵)。filter的大小为2*2,步长为2,这时候就只有一个固定参数的窗口对10*10*16,这16个矩阵滑来滑去啦,因为已经有16个了嘛,再复杂也没有什么意义了。所以本层的输出为5*5*16的矩阵。
第五层为卷积层。作者觉得前面从32*32到5*5*16已经够麻烦了,终于要开始做一些“总结性”计算工作了。论文当中把这一层称为卷积层,因为实际上还是在做卷积。我个人认为把16个5*5的矩阵一起做的运算,所以把它当做全连接层也没有问题。本层的输出结果设计了120个神经元。我们将输入的16个5*5的矩阵铺平变为“一维向量”的形式(排排坐吃果果),120个神经元的任一个计算结果都需要元素个数为5*5*16这个向量的参与。前面没有提到层与层之间的参数个数问题,以这层为例,参数共有5*5*16*120+120个。该层的过程和参数个数如图4所示。
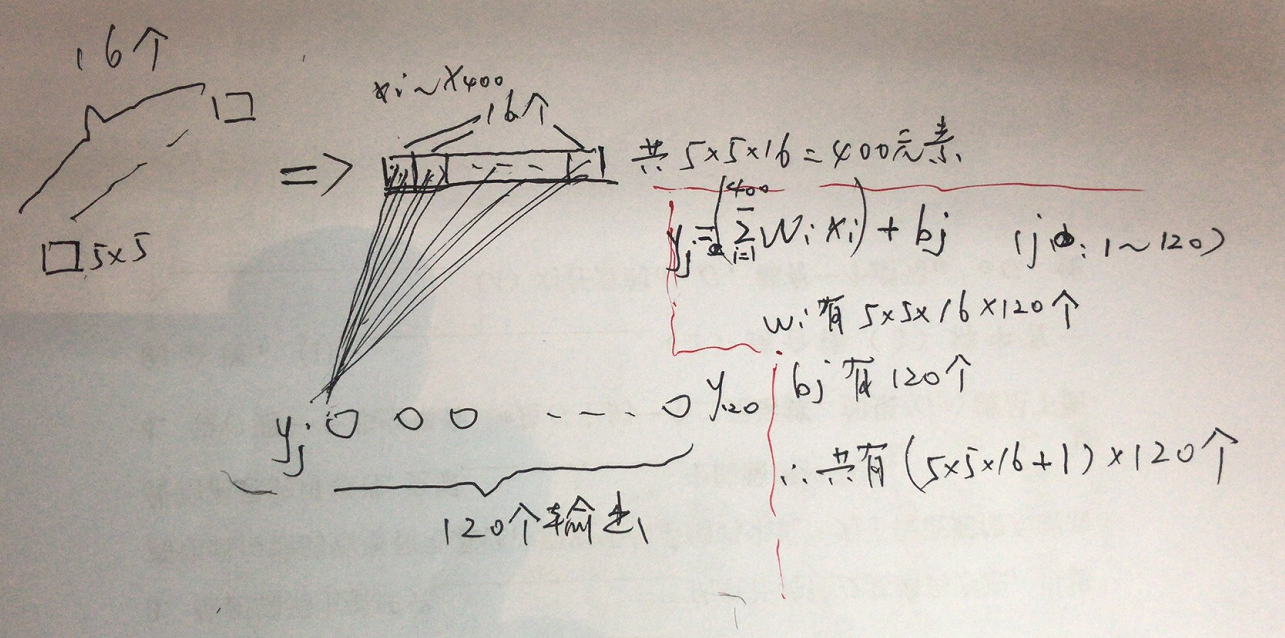 图4 第5层映射过程与参数个数问题
图4 第5层映射过程与参数个数问题
第6层的设计就很顺理成章了,称为全连接层。和第5层相似,将输入的120变为输出的84。那么层之间的参数个数计算方法与图5类似,为120*84+84个。
第7层也是全连接层。将84输入变为10。参数个数84*10(因为计算公式不同,没有偏移项bi了),输出的10个神经元就对应的数字0-9,看最开始输入的32*32的图片属于哪个类别的概率最大。
1.2 小结
其实可以感觉到,过去的神经网络是在重复一些复杂运算,但是其思想是值得借鉴的。输入数据只有32*32,我们通过“折腾”自己,换各种采样方式将它变化为28*28*6,进而14*14*6,然后10*10*16,最后5*5*16。这种交叉卷积运算无疑是为了提取到更多信息,增加互信息熵。但为了计算不复杂,又不断地重复“采样-降维“的过程。当然,哪怕是最后的5*5*16,它表示得仍然是同一图片,所以全连接层就再把所有的”眼线“的信息进行汇总。
2. 愿君多采撷
接下来是代码部分。github上有很多有些的代码。调通了跑一跑看看实验结果,对网络会理解更深,同时自己也更有成就感和兴趣。数据集和代码参考(链接:http://pan.baidu.com/s/1eRG6TqU 密码:uf4m)。作者的tensorflow版本较低,猫咪可以把tensorflow降低版本后运行。我使用的python3.5,所以import skimage要更换包为import scikit-image,后者包含了前者。代码如下所示:
import os
import glob
import numpy as np
import tensorflow as tf
#将所有的图片重新设置尺寸为32*32
w = 32
h = 32
c = 1
#mnist数据集中训练数据和测试数据保存地址
train_path = "/home/echo/Desktop/prac/LeNet-5/train/"
test_path = "/home/echo/Desktop/prac/LeNet-5/test/"
#读取图片及其标签函数
def read_image(path):
label_dir = [path+x for x in os.listdir(path) if os.path.isdir(path+x)]
images = []
labels = []
for index,folder in enumerate(label_dir):
for img in glob.glob(folder+'/*.png'):
print("reading the image:%s"%img)
image = io.imread(img)
image = transform.resize(image,(w,h,c))
images.append(image)
labels.append(index)
return np.asarray(images,dtype=np.float32),np.asarray(labels,dtype=np.int32)
#读取训练数据及测试数据
train_data,train_label = read_image(train_path)
test_data,test_label = read_image(test_path)
#打乱训练数据及测试数据
train_image_num = len(train_data)
train_image_index = np.arange(train_image_num)
np.random.shuffle(train_image_index)
train_data = train_data[train_image_index]
train_label = train_label[train_image_index]
test_image_num = len(test_data)
test_image_index = np.arange(test_image_num)
np.random.shuffle(test_image_index)
test_data = test_data[test_image_index]
test_label = test_label[test_image_index]
#搭建CNN
x = tf.placeholder(tf.float32,[None,w,h,c],name='x')
y_ = tf.placeholder(tf.int32,[None],name='y_')
def inference(input_tensor,train,regularizer):
#第一层:卷积层,过滤器的尺寸为5×5,深度为6,不使用全0补充,步长为1。
#尺寸变化:32×32×1->28×28×6
with tf.variable_scope('layer1-conv1'):
conv1_weights = tf.get_variable('weight',[5,5,c,6],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable('bias',[6],initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor,conv1_weights,strides=[1,1,1,1],padding='VALID')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1,conv1_biases))
#第二层:池化层,过滤器的尺寸为2×2,使用全0补充,步长为2。
#尺寸变化:28×28×6->14×14×6
with tf.name_scope('layer2-pool1'):
pool1 = tf.nn.max_pool(relu1,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
#第三层:卷积层,过滤器的尺寸为5×5,深度为16,不使用全0补充,步长为1。
#尺寸变化:14×14×6->10×10×16
with tf.variable_scope('layer3-conv2'):
conv2_weights = tf.get_variable('weight',[5,5,6,16],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable('bias',[16],initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1,conv2_weights,strides=[1,1,1,1],padding='VALID')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2,conv2_biases))
#第四层:池化层,过滤器的尺寸为2×2,使用全0补充,步长为2。
#尺寸变化:10×10×6->5×5×16
with tf.variable_scope('layer4-pool2'):
pool2 = tf.nn.max_pool(relu2,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
#将第四层池化层的输出转化为第五层全连接层的输入格式。第四层的输出为5×5×16的矩阵,然而第五层全连接层需要的输入格式
#为向量,所以我们需要把代表每张图片的尺寸为5×5×16的矩阵拉直成一个长度为5×5×16的向量。
#举例说,每次训练64张图片,那么第四层池化层的输出的size为(64,5,5,16),拉直为向量,nodes=5×5×16=400,尺寸size变为(64,400)
pool_shape = pool2.get_shape().as_list()
nodes = pool_shape[1]*pool_shape[2]*pool_shape[3]
reshaped = tf.reshape(pool2,[-1,nodes])
#第五层:全连接层,nodes=5×5×16=400,400->120的全连接
#尺寸变化:比如一组训练样本为64,那么尺寸变化为64×400->64×120
#训练时,引入dropout,dropout在训练时会随机将部分节点的输出改为0,dropout可以避免过拟合问题。
#这和模型越简单越不容易过拟合思想一致,和正则化限制权重的大小,使得模型不能任意拟合训练数据中的随机噪声,以此达到避免过拟合思想一致。
#本文最后训练时没有采用dropout,dropout项传入参数设置成了False,因为训练和测试写在了一起没有分离,不过大家可以尝试。
with tf.variable_scope('layer5-fc1'):
fc1_weights = tf.get_variable('weight',[nodes,120],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc1_weights))
fc1_biases = tf.get_variable('bias',[120],initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshaped,fc1_weights) + fc1_biases)
if train:
fc1 = tf.nn.dropout(fc1,0.5)
#第六层:全连接层,120->84的全连接
#尺寸变化:比如一组训练样本为64,那么尺寸变化为64×120->64×84
with tf.variable_scope('layer6-fc2'):
fc2_weights = tf.get_variable('weight',[120,84],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc2_weights))
fc2_biases = tf.get_variable('bias',[84],initializer=tf.truncated_normal_initializer(stddev=0.1))
fc2 = tf.nn.relu(tf.matmul(fc1,fc2_weights) + fc2_biases)
if train:
fc2 = tf.nn.dropout(fc2,0.5)
#第七层:全连接层(近似表示),84->10的全连接
#尺寸变化:比如一组训练样本为64,那么尺寸变化为64×84->64×10。最后,64×10的矩阵经过softmax之后就得出了64张图片分类于每种数字的概率,
#即得到最后的分类结果。
with tf.variable_scope('layer7-fc3'):
fc3_weights = tf.get_variable('weight',[84,10],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc3_weights))
fc3_biases = tf.get_variable('bias',[10],initializer=tf.truncated_normal_initializer(stddev=0.1))
logit = tf.matmul(fc2,fc3_weights) + fc3_biases
return logit
#正则化,交叉熵,平均交叉熵,损失函数,最小化损失函数,预测和实际equal比较,tf.equal函数会得到True或False,
#accuracy首先将tf.equal比较得到的布尔值转为float型,即True转为1.,False转为0,最后求平均值,即一组样本的正确率。
#比如:一组5个样本,tf.equal比较为[True False True False False],转化为float型为[1. 0 1. 0 0],准确率为2./5=40%。
regularizer = tf.contrib.layers.l2_regularizer(0.001)
y = inference(x,False,regularizer)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=y_)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
train_op = tf.train.AdamOptimizer(0.001).minimize(loss)
correct_prediction = tf.equal(tf.cast(tf.argmax(y,1),tf.int32),y_)
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#每次获取batch_size个样本进行训练或测试
def get_batch(data,label,batch_size):
for start_index in range(0,len(data)-batch_size+1,batch_size):
slice_index = slice(start_index,start_index+batch_size)
yield data[slice_index],label[slice_index]
#创建Session会话
with tf.Session() as sess:
#初始化所有变量(权值,偏置等)
sess.run(tf.global_variables_initializer())
#将所有样本训练10次,每次训练中以64个为一组训练完所有样本。
#train_num可以设置大一些。
train_num = 10
batch_size = 64
for i in range(train_num):
train_loss,train_acc,batch_num = 0, 0, 0
for train_data_batch,train_label_batch in get_batch(train_data,train_label,batch_size):
_,err,acc = sess.run([train_op,loss,accuracy],feed_dict={x:train_data_batch,y_:train_label_batch})
train_loss+=err;train_acc+=acc;batch_num+=1
print("train loss:",train_loss/batch_num)
print("train acc:",train_acc/batch_num)
test_loss,test_acc,batch_num = 0, 0, 0
for test_data_batch,test_label_batch in get_batch(test_data,test_label,batch_size):
err,acc = sess.run([loss,accuracy],feed_dict={x:test_data_batch,y_:test_label_batch})
test_loss+=err;test_acc+=acc;batch_num+=1
print("test loss:",test_loss/batch_num)
print("test acc:",test_acc/batch_num)
运行结果如图5所示:
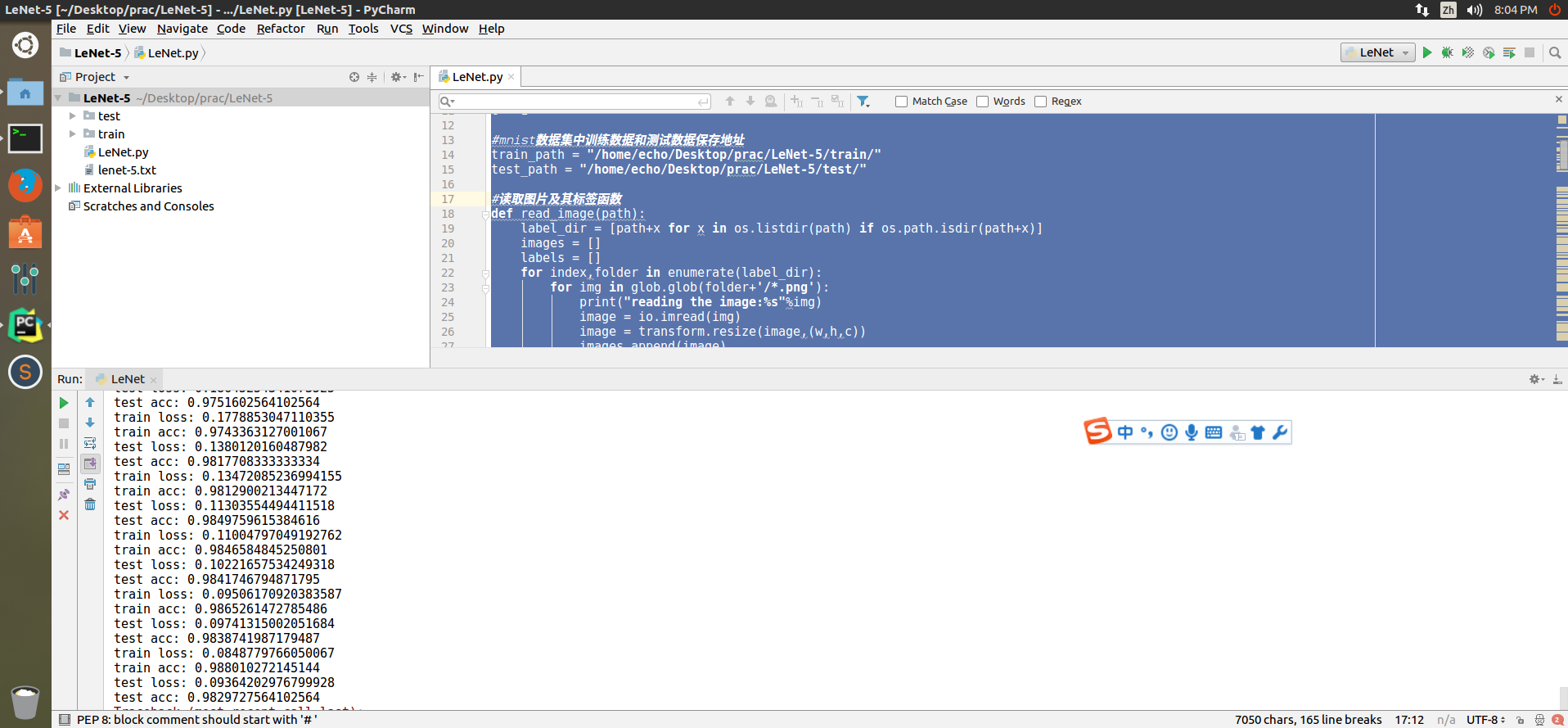
图5 运行结果
3. 此物最相思
希望这篇博文能对猫咪有所帮助。有任何疑问秋涵君都在你身后,和你一起学习一起进步。我不够好,可我想让自己更好,然后把最好的,给你。谢谢猫咪。
*2018-04-12 更新:猫咪有什么问题和新学的不明白的可以和我一起讨论,博客我会一直更新下去的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号