基于 burpsuite的web逻辑漏洞插件开发(来自JSRC安全小课堂,柏山师傅)
基于 burpsuite的web逻辑漏洞插件开发
BurpSuite 提供了插件开发接口,支持Java、Python、Ruby语言的扩展。虽然 BApp Store 上面已经提供了很多插件,其中也不乏优秀好用的插件。
推荐几个个人感觉好的插件CO2,Logger++,Autorize,XSS Validator
但是通用化的工具无法完全符合web安全测试人员的特定需求。
本节我和大家探讨,如何根据实际需求自己开发出提高安全测试效率的插件。
本次课程主要是从以下四个方面展开

1.为什么要独立开发插件
随着厂商安全意识增强,传输过程中,大多数线上业务通过https传输,传输流量加密。无法做中间人攻击了就服务端,数据库中的敏感数据加密存储,访问控制受限,即使拿到数据库也无法拿到明文数据。但是数据在客户端最终要展示给用户,必然明文展现。
传统的安全防御设备和措施对逻辑漏洞收效甚微,现在攻击者更倾向于在客户端利用此类漏洞。而逻辑漏洞种类很多,通用化的工具无法完全符合web安全测试人员的特定需求。一个业务的逻辑漏洞抽象出来的模型,难以在其他业务层进行批量处理,通用的解决方案往往效果不佳。(但是一个业务层抽象出来的模型,在其自身站点往往具有通用性。)
例如,某URL存在越权,可能该站点其他URL也可能存在类似的问题。我们基于该URL特征,开发burpsuite插件,批量扫描该站点,就能更全面的发现同类问题。
2. 开发环境配置
Burp支持Java、Python、Ruby语言的扩展,本次讲座以python环境为 例进行说明。Burpsuite 是运行在java环境,所有的库是java所写。Python作为开发语言,调用Java库就要用到Jython。
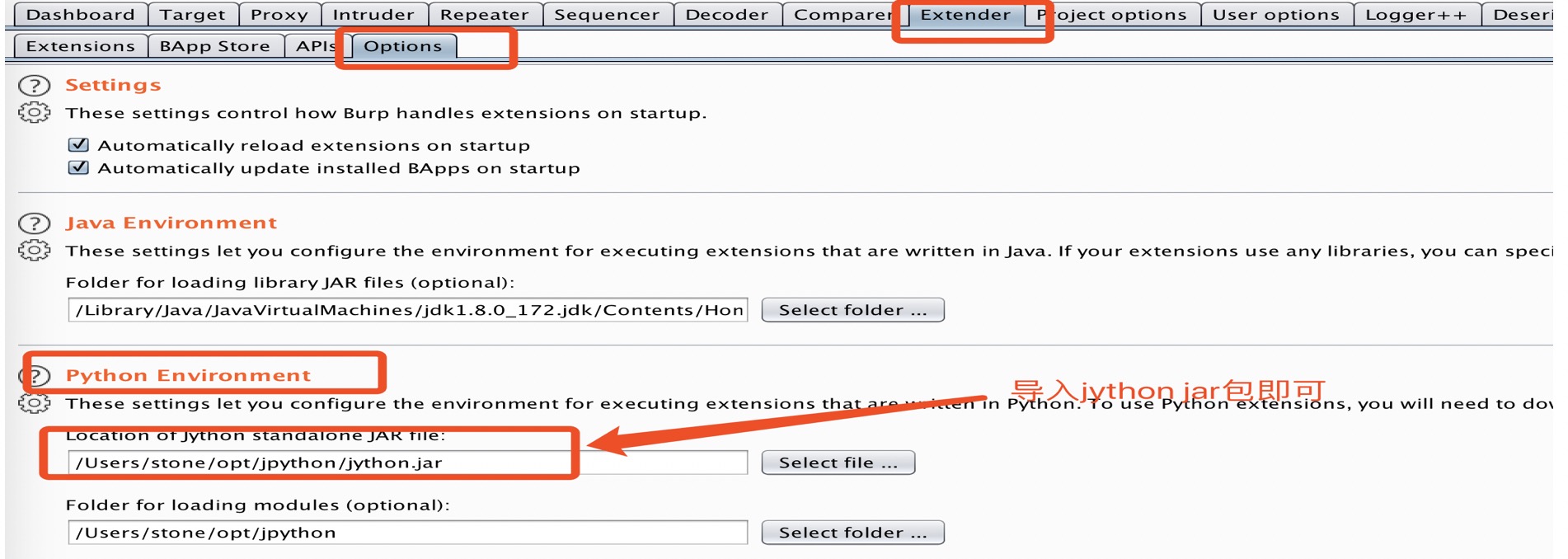
Burpsuite Jython环境的配置
Extender -> options -> python Environment -> select file,导入下载好的jython jar包。
3.插件开发关键接口的使用实例
API接口查阅可以从以下拿到:
API接口文档可以在burpsuite 的Extender -> APIs
也可以通过https://portswigger.net/burp/extender/api/index.html进行查阅。
IBurpExtender
IBurpExtender是Burpsuite插件的入口,所有插件的开发都必须要实现。当插件被建立以后,registerExtenderCallbacks也需要实现。
代码如下:class BurpExtender(IBurpExtender):
def registerExtenderCallbacks(self, callbacks):
参数callbacks可获取核心基础库,例如日志,请求,返回值修改等。IBurpExtenderCallbacks: 这个接口几乎是必备的。在插件编写的过程中会经常用到。
IExtensionHelpers:
提供了编写扩展中常用的一些通用函数,比如编解码、构造请求、获取请求参数,获取请求头等。如:IRequestInfo analyzeRequest(byte[] request)
通过analyzeRequest函数,可以拿到请求的细节。
通过如下几个接口方法可以拿到

IHttpRequestResponse: 这个接口包含了每个请求和响应的细节。在Brupsuite中的每个请求或者响应都是IHttpRequestResponse实例。通过getRequest(), getResponse()方法可以获取请求和响应的细节信息。
以registerHttpListener为例进行代码说明:
如图所示,在user 和 webserver之间建立监听,调用HttpListener接口。获取请求,响应的日志。
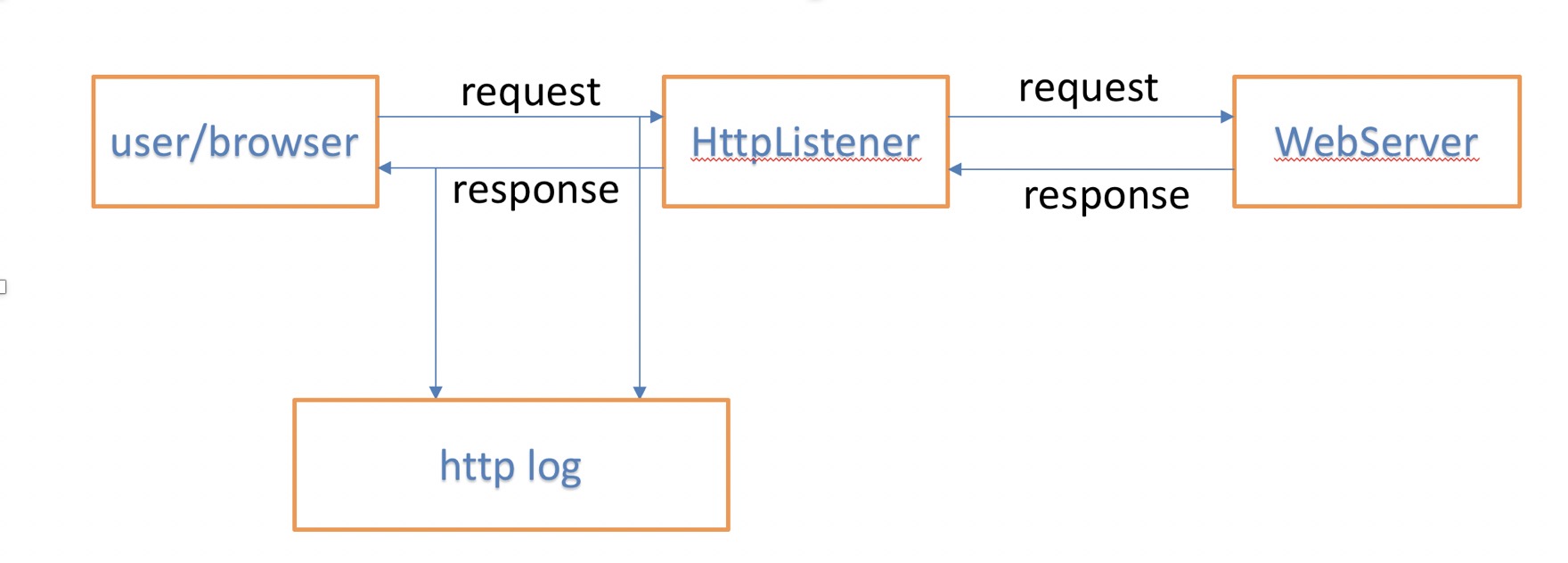
实现这个功能,最重要的是这个方法:
# register ourselves as an HTTP listener
callbacks.registerHttpListener(self)
def registerExtenderCallbacks(self, callbacks):
self._callbacks = callbacks
self._helpers = callbacks.getHelpers()
## 设置插件名
self._callbacks.setExtensionName("getTheRequest")
# //如果没有注册,下面的processHttpMessage方法是不会生效的。处理请求和响应包的插件,这个应该是必要的
callbacks.registerHttpListener(self)
### processHttpMessage(int toolFlag, boolean messageIsRequest, IHttpRequestResponse messageInfo),
### 在messageInfo这个参数中,我们可以获取到request和response日志。
def processHttpMessage(self, toolFlag, messageIsRequest, messageInfo):
if toolFlag == 4:
if not messageIsRequest:
request = messageInfo.getRequest()
analyzedRequest = self._helpers.analyzeResponse(request)
request_header = analyzedRequest.getHeaders()
try:
method, path = res_path.findall(request_header[0])[0]
host = res_host.findall(request_header[1])[0]
url = method + " " + host + path
except:
url = ""
if method == "GET":
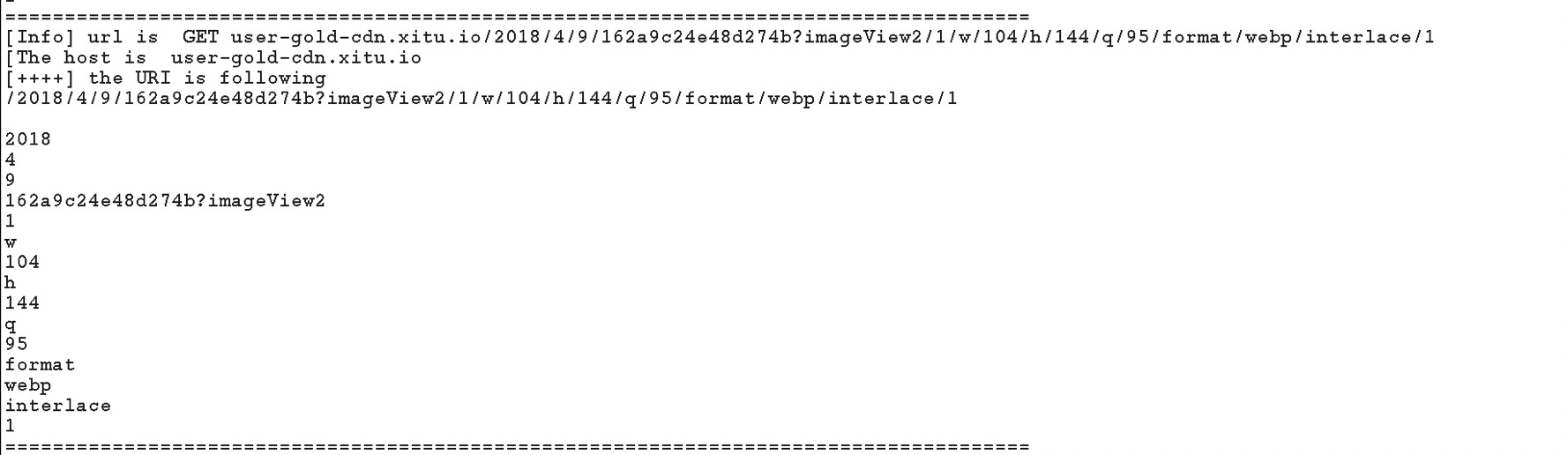
print “[+++++]The URL is ", url
print "[+++++]The host is ",host
print "[++++] The URI is following"
print path
for iterm in path.split("/"):
print iterm
print
代码如上所示,就可以打印出URL,HOST,URI日志信息
如果做扫描类插件:
class BurpExtender(IBurpExtender,IScannerCheck)
callbacks.registerScannerCheck(this);
实现IScannerCheck后需要重写被动扫描的函数。
doPassiveScan(IHttpRequestResponse baseRequestResponse) {}
doPassiveScan这个接口,在baseRequestResponse获取请求和响应数据,并利用这些数据进行基于扫描规则进行扫描。
逻辑漏洞检测插件开发探讨
这个插件实现的基本功能是:确定哪些cookie有效cookie,可以基于这些URL,生成字典,进行目录爆破
首先,我们需要拿到requests 的 cookie
request = messageInfo.getRequest()
analyzedRequest = self._helpers.analyzeResponse(request)
requestHeaders = analyzedRequest.getHeaders()
newHeaders = dict()
cookies = dict()
for header in requestHeaders:
header = header.encode('utf-8')
if "HTTP/" not in header and "Host" not in header and "Cookie" not in header:
header_item = header.split(": ")
newHeaders[header_item[0]] = ": ".join(header_item[1:])
if header.lower().startswith("cookie"):
rawCookie = header.strip("Cookie: ")
for item_cookie in rawCookie.split("; "):
key = item_cookie.split("=")[0]
value = "=".join(item_cookie.split("=")[1:])
cookies[key] = value
lengthList = {}
for key,value in cookies.items():
tempcookie = {}
tempcookie[key] = value
response = requests.get(url,headers=newHeaders,cookies=tempcookie,verify=False)
lengthList[key] = len(response.content)
if lengthList.keys():
print url
print lengthList
根据响应长度的不同确定哪些cookie是有效cookie
针对DES,AES加密参数的逻辑漏洞挖掘:
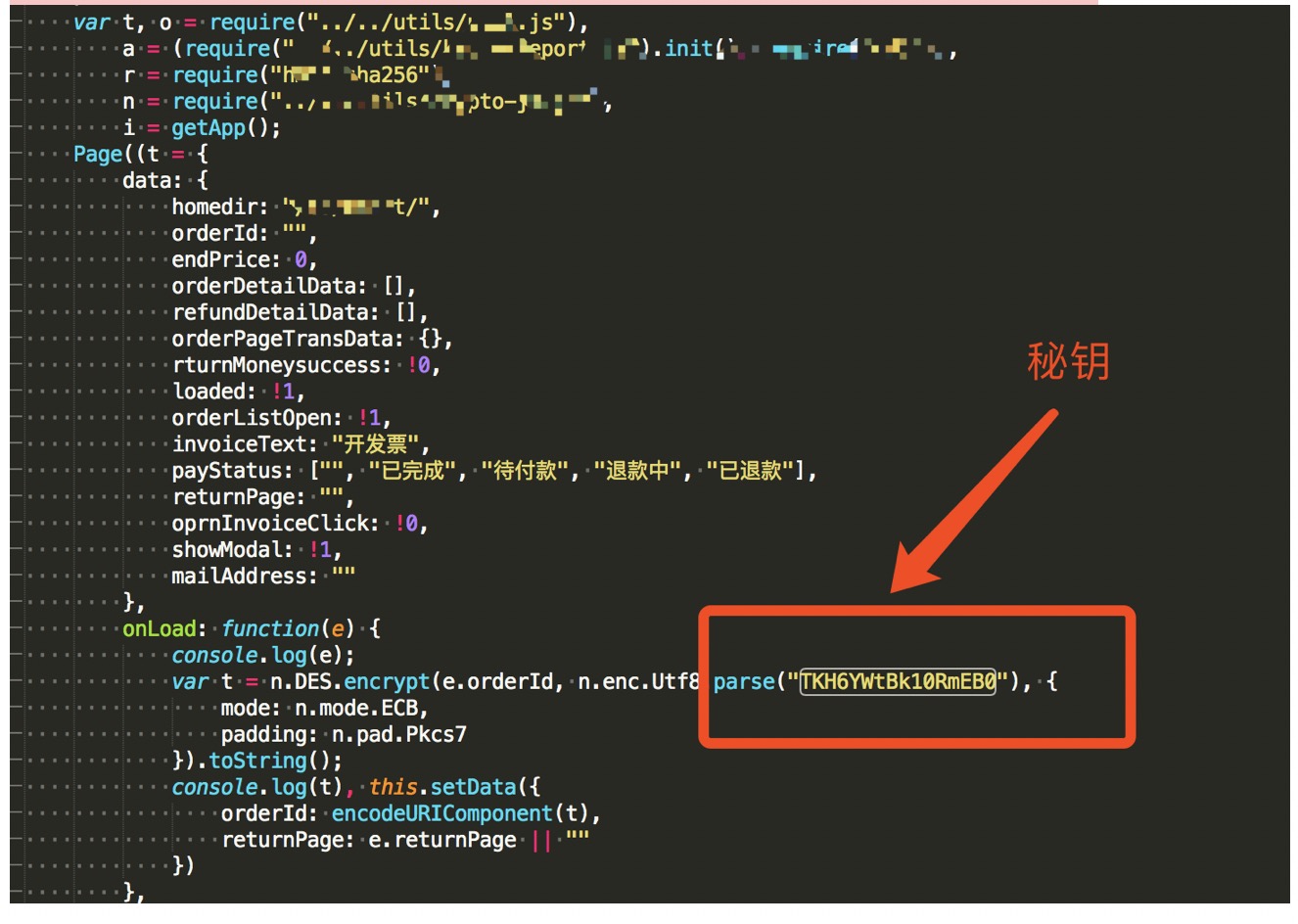
AES,DES属于对称加密,所以客户端和服务器端都会有秘钥存在,也就是说密钥在客户端肯定能找到。网页,微信小程序中,往往在js代码中就能找到,找到密钥即可进行逻辑漏洞测试。
在一次对微信小程序渗透测试中,抓包发现订单ID参数以密文形式进行传输。因此,我们需要获取加密方法。通过反编译微信小程序包,发现了密钥,加密方法是DES加密。
这是在一次渗透测试过程中获取DES秘钥的截图;
昨天分享了一下,今题讲一些插件的tips
## 代码编写获取订单ID密文。
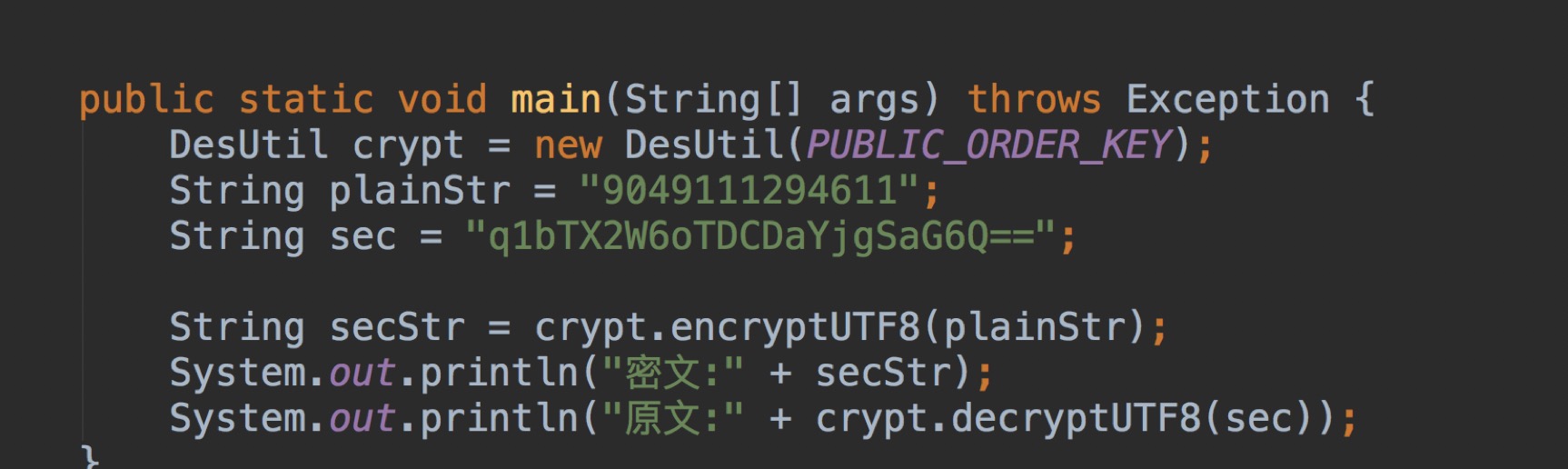
在burpsuite测试过程:
由于是对订单ID加密,我们先遍历明文ID,再对明文Id进行加密,生成字典。再利用burp 的爆破插件,进行爆破即可。
tips:遇到参数加密的情况并不可怕,既然是对称加密,秘钥一定能在客户端拿到。对js代码进行分析,往往就可以获取到秘钥。
# 对消息体进行解析
analyzeRequest= helpers.analyzeRequest(messageInfo);
# 获取请求头
headers= analyzeRequest.getHeaders()
# 获取参数列表
paraList= analyzeRequest.getParameters();#获取参数列表,参数分为三种类型,URL中的参数,cookie中的参数,body中的参数。
for para in paraList:
# 这里可以考虑对加密参数进行筛选
key= para.getName() # 获取参数名
value= para.getValue() # 获取参数
aesValue = aes.encrypt(value);
aesValue = URLEncoder.encode(aesvalue);
遍历参数,可以对参数名进行过滤,处理需要加密的参数
newPara= helpers.buildParameter(key, aesValue, para.getType()); #构造新的参数
updateRequest = helpers.updateParameter(new_Request, newPara); #构造新的请求包
messageInfo.setRequest(updateRequest);//设置最终新的请求包
//如果作为插件开发的话,只需要更改AES秘钥即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号