正则表达式语法学习
正则表达式
描述了一种字符串匹配的模式。可以用来检查一个串是否包含有某个子串,将匹配的子串替换、从某个串中取出符合条件的子串等
普通字符
-
[ABC]
匹配[...]中所有的字符 -
[^ABC]
匹配除了[...]中字符的所有字符 -
[A-Z]
表示一个区间,匹配所有大写字母,[a-z]表示所有小写字母 -
.
匹配除了换行符(\n、\r) 之外的任何单个字符,相当于/[^\n\r]/ -
[\s\S]
匹配所有,\s 是匹配所有空白符、包括换行,
\S 非空白符,不包括换行 -
\w
匹配字母、数字、下划线。等价于[A-Za-z0-9_]
特殊字符
-
$
匹配输入字符串的结尾位置 -
()
标记一个子表达式的开始和结束位置 -
- 大于等于0 次
表示前面的字符可以不出现、出现一次或多次(0次、1次、多次)
- 大于等于0 次
-
- 大于等于1 次
表示前面的字符必须至少出现一次(1次或多次)
- 大于等于1 次
-
? 等于0 或1 次
表示前面的字符最多只出现一次(0次或1次) -
^
匹配输入字符串的开始位置,除非在放括号表达式中使用,当该符号在方括号表达式中使用是,表示不接受该方括号表达式的字符集合, -
{
标记限定符表达式的开始 -
|
指明两项之间的一个选择,
限定符
匹配前面子表达式零次或多次,例如,zo* 能匹配'z'以及'zoo',等价于{0,}
匹配前面的子表达式 一次或多次,例如,zo+ 能匹配zo和zoo 但是不能匹配z 等价于{1,}
-
?
匹配前面的子表达式零次或1次,例如 do(es)? 可以匹配do、does、doxy ? 等价于 -
{n}
n是个非负整数,匹配确定的n 次,例如o{2} 不能匹配Bob 中的o,但是能匹配food中的两个oo -
{n,}
n是个非负整数,至少匹配n次,例如,0{2,} 不能匹配Bob 中的o, 但能匹配 foooood 中所有o 。o{1,} 等价于o+ ,而o{0,} 等价于o* -
{n,m}
m和n均为非负整数,其中n<=m ,最少匹配n次和最多匹配m次,例如 o{1,3} 将匹配 foooooood
中钱三个ooo ,o{0,1} 等价于0? ,请注意逗号在两个数之间不能有空格。
案例
-
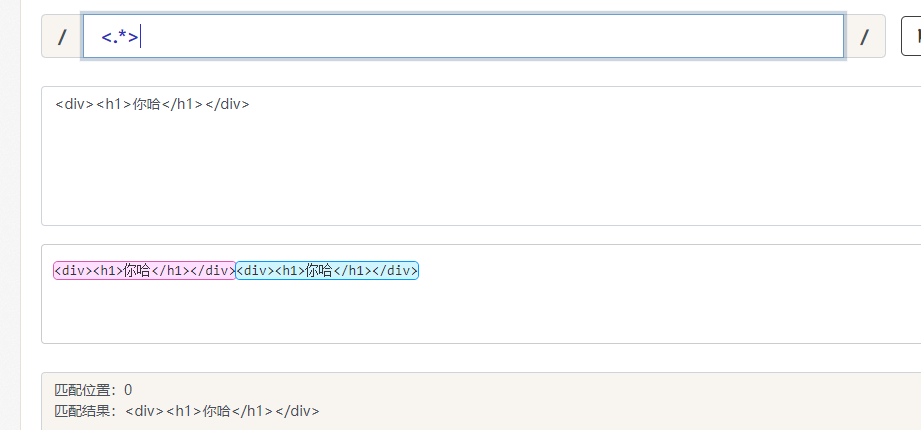
/<.*>/ 贪婪
![]()
-
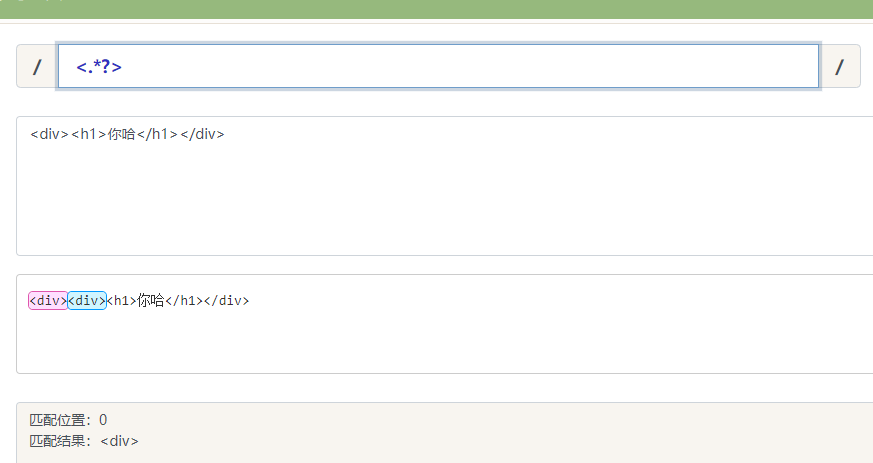
/<.*?>/ 非贪婪
![]()
-
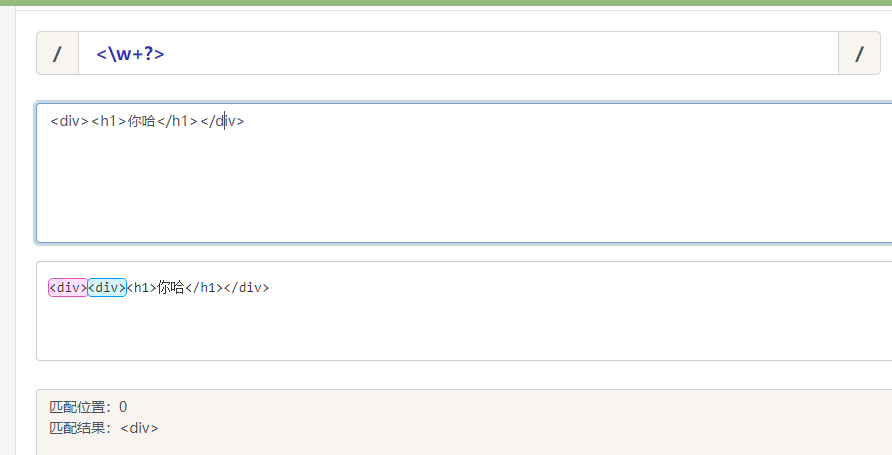
/<\w+?>/
![]()
定位符
使您能够将正则表达式固定在行首或行尾。
定位符用来描述字符串或单词的边界,^和$ 分别指字符串的开始和结束,\b 描述单词的前或后边界,\B表示非单词边界。
- ^ 匹配输入字符串开始的位置
- $ 匹配输入字符串结尾的位置
- \b 匹配一个单词边界,即字与空格间的位置
- \B 非单词边界匹配
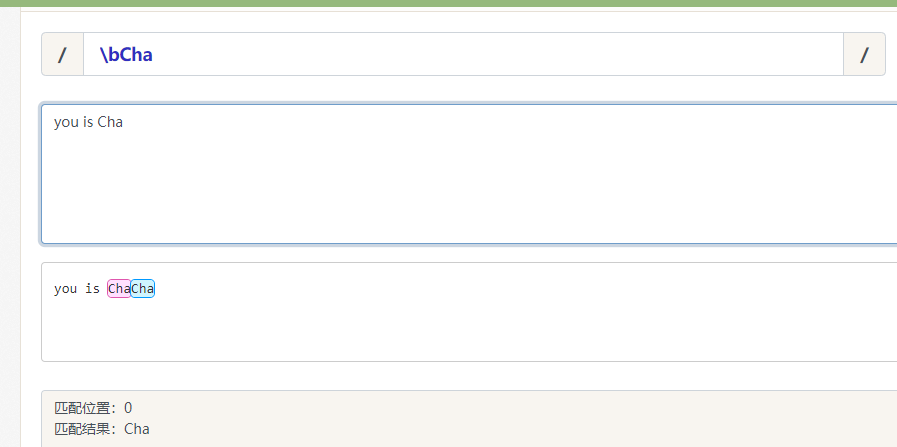
注意: 不能将限定符与定位符一起使用
反向应用
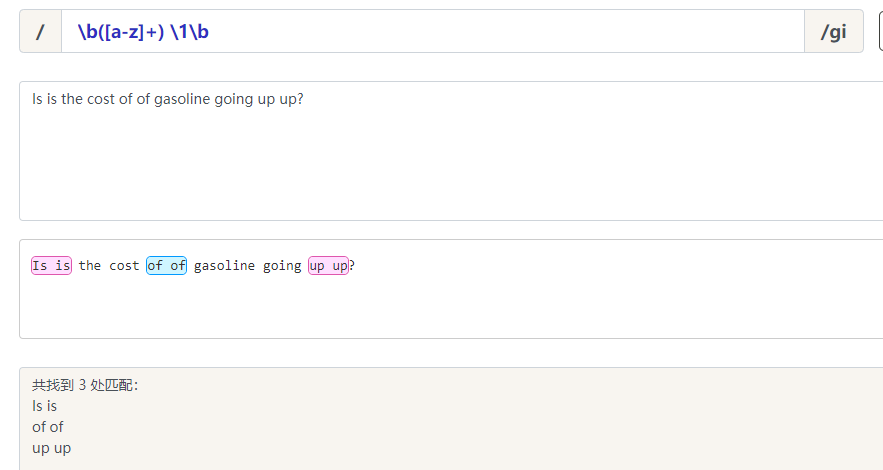
捕获的表达式,正如 [a-z]+ 指定的,包括一个或多个字母。正则表达式的第二部分是对以前捕获的子匹配项的引用,即,单词的第二个匹配项正好由括号表达式匹配。\1 指定第一个子匹配项。
单词边界元字符确保只检测整个单词。否则,诸如 "is issued" 或 "this is" 之类的词组将不能正确地被此表达式识别。
正则表达式后面的全局标记 g 指定将该表达式应用到输入字符串中能够查找到的尽可能多的匹配。
表达式的结尾处的不区分大小写 i 标记指定不区分大小写。
修饰符(标记)
- i
不区分大小写 - g
全局匹配 - m
多行匹配 - s
特殊字符圆点. 中包含换行符\n
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号