
nifi的一段经历
简介
https://www.cnblogs.com/ronnieyuan/p/11935871.html
https://github.com/apache/nifi
Apache NiFi是一个基于流编程概念的数据流Data Flow 框架系统。
可以对来自多种数据源的流数据进行处理
- Data Flow 数据流 :解决的是数据端到端传输的问题。
数据流中的数据可以来自很多种类型,比如 CSV、JSON、HTTP、IoT 和音视频流等等。 - Data Pipeline 数据管道 :提供多渠道数据来源来进行实时摄取、数据清洗、任务流管理、元数据管理、流批一体等功能。
讲的可以:https://www.pianshen.com/article/2812347473/
可以看看:
https://www.e-learn.cn/content/qita/627407
https://www.e-learn.cn/content/wangluowenzhang/2193412
https://www.e-learn.cn/topic/1447804
https://www.e-learn.cn/tag/nifi
NiFi有一个基于web的用户界面,用于设计、控制、反馈和监视数据流。
它在服务质量的几个维度上是高度可配置的,比如容错与保证交付、低延迟与高吞吐量以及基于优先级的队列。
NiFi为所有接收的、分叉的、连接的、克隆的、修改的、发送的和最终到达配置的最终状态时丢弃的数据提供细粒度的数据来源。
特点
-
基于 Web 的用户界面
设计、控制、反馈和监控之间的无缝体验 -
高度可配置
2.1 容错与可靠投递
2.2 低延迟与高吞吐量
2.3 动态优先级
2.4 流可以在运行时修改
2.5 背压 -
数据来源
从头到尾跟踪数据流 -
专为扩展而设计
4.1 构建自己的处理器等
4.2 实现快速开发和有效测试 -
安全
5.1 SSL、SSH、HTTPS、加密内容等...
5.2 多租户授权和内部授权/策略管理
————————————————
版权声明:本文为CSDN博主「DataFlow范式」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
一个大佬的讲解:https://blog.csdn.net/jiangshouzhuang/article/details/105609041
安装
linux: wget https://archive.apache.org/dist/nifi/1.11.4/nifi-1.11.4-bin.tar.gz
-b 后台执行,wget-log 记录日志
https://www.cnblogs.com/h--d/p/10079418.html
nifi.properties:
# web properties #
nifi.web.http.host=
nifi.web.http.port=8080
nifi.web.http.network.interface.default=
nifi.web.https.host=
nifi.web.https.port=
其他配置参考:https://blog.csdn.net/weibokong789/article/details/88554855
mac:brew install nifi
日志:/nifi/1.11.4/libexec/logs/nifi-app.log
启动命令
./bin/nifi.sh start
访问 localhost:8080/nifi/
stop、status
mac:nifi start
k8s安装
文档
在线:https://nifi.apache.org/docs/nifi-docs/html/getting-started.html#for-linux-macos-users
别人翻译的:https://nifichina.gitee.io/3-Processors/AttributesToCSV.html#属性配置
工作流组成
https://blog.csdn.net/memoordit/article/details/78804594
- Processor 处理器,是用于监听传入数据的 NiFi 组件、从外部获取数据、对外发布数据,以及从 FlowFiles 中路由、转换或提取信息。
可以用来创建、发送、接受、转换、路由、割裂、合并、处理FlowFiles。
包含的类型很多,多达 两百多个,比如传统数据库、大数据组件、日志文件、消息流、aws 云服务的产品(DynamoDB、Lambda、S3 等)等。
处理器可以使用标准调度方法将此处理器调度为在计时器或使用CRON,也可以由传入的流文件触发(有些组件不支持,有的是experimental)。
CRON即是Crontab的应用,CRON的各参数含义分别代表:秒、分、时、日、月、周、年,需要配合、?和L共同执行(代表字段的值都有效;?代表对于指定的字段不指定值;L代表长整形)。如:“0 0 13 * * ?”代表想要在每天下午1点进行调度执行。
https://www.cnblogs.com/zxbdboke/p/11299506.html
- FlowFile 表示 NiFi 中的单个数据块。
一个 FlowFile 由两个组件组成: - FlowFile Content
Content 是 FlowFile 数据流的实际内容,比如通过 GetFile、GetHTTP 等方式获取文件的实际内容。 - FlowFile Attributes
FlowFile 的元数据信息,包含 Content 的信息有:
FlowFile 什么时候创建、FlowFile 名字、FlowFile 来自哪里、FlowFile 表示什么等。
Processor 可以添加、更新或删除 FlowFile attributes,以及修改 FlowFile content。
-
Connection 是指 Processor 或 Process Group 之间的连接,从而创建一个自动化的数据流。每个 Connection 都包含一个 FlowFile Queue,用于缓存传输的流数据,并可设置 Back Pressure和数据流的优先级方案(先进先出等)。
-
Processor Group 针对一个复杂的业务处理数据流,建议最好使用逻辑的 Process Group 来组织这个复杂的 processes,方便维护这些数据流。相当于系统中的文件夹,作用就是使数据流的各个部分看起来更工整,思路更清晰,不至于从头到尾一条线阅读起来十分不方便。
另外 Process Group 还有 Input/Ouput Port(组与组之间的数据流连接的传入点与输出点),可以用来在它们之间移动数据。 -
Controller Service 控制器,例如数据库连接,XML读取,JSON读取器,用来被 processes 使用,比如一个 process 需要写入或读取数据库的数据,需要使用一个 Controller Service 用来建立数据库的连接信息。
NiFi 提供了 几十 种 Controller Service。另外在权限控制方面,可以对每个 Controller Service 进行授权操作。
https://blog.csdn.net/wangmin1983/article/details/80466736
Processors 分类
-
数据摄取 Processors
-
数据转换 Processors
-
数据流出/发送数据 Processors
-
路由和中转 Processors
-
数据库访问 Processors
-
Attribute 抽取 Processors
-
系统交互 Processors
-
切分和聚合 Processors
-
HTTP 和 UDP Processors
-
Amazon Web Services Processors
详见:https://zhuanlan.zhihu.com/p/299075280
文本处理组件
ReplaceText:
使用正则表达式修改文本内容(Replacement Value替换 Search Value);
可以利用属性,进行转换:
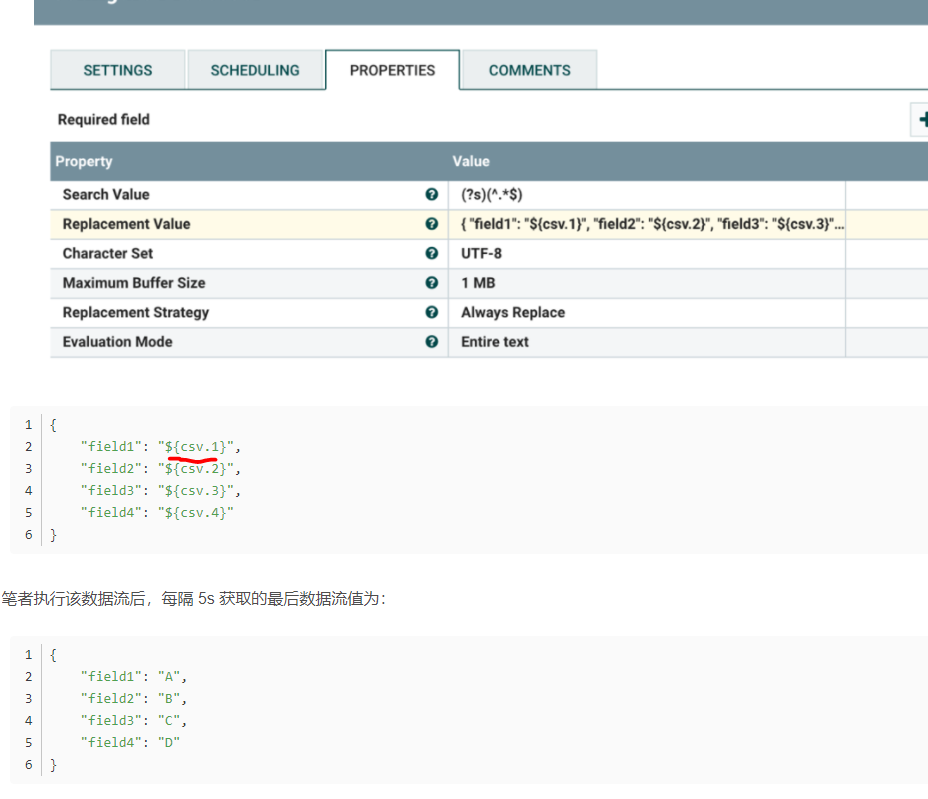
正则替换参考 https://stackoverflow.com/questions/46236125/nifi-usign-replace-text-for-replacing-with-n
ExtractText:
使用一个或多个正则表达是有FlowFile内容中提取数据,以替换FlowFile内容或将该值提取到用户命名的Attribute中。
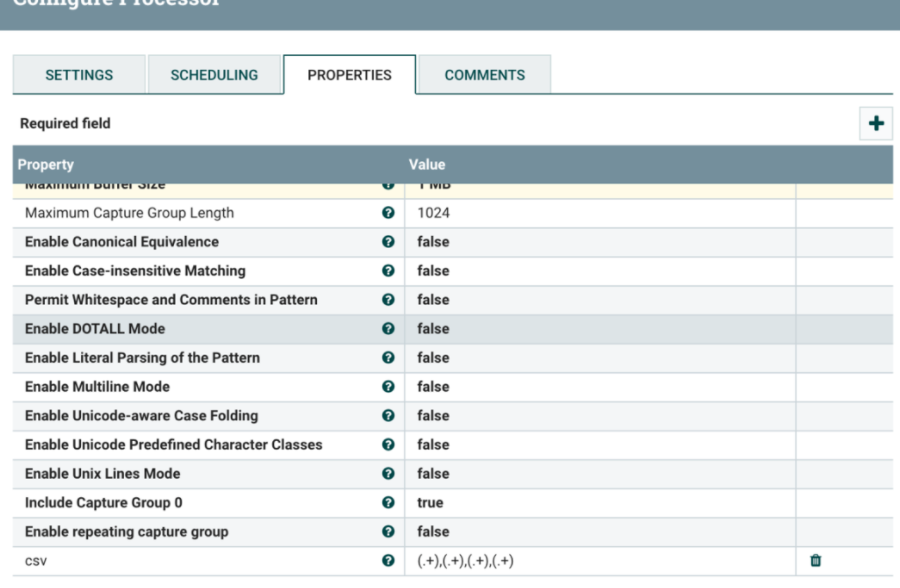
原始数据A,B,C,D匹配后得到dataFlow属性:
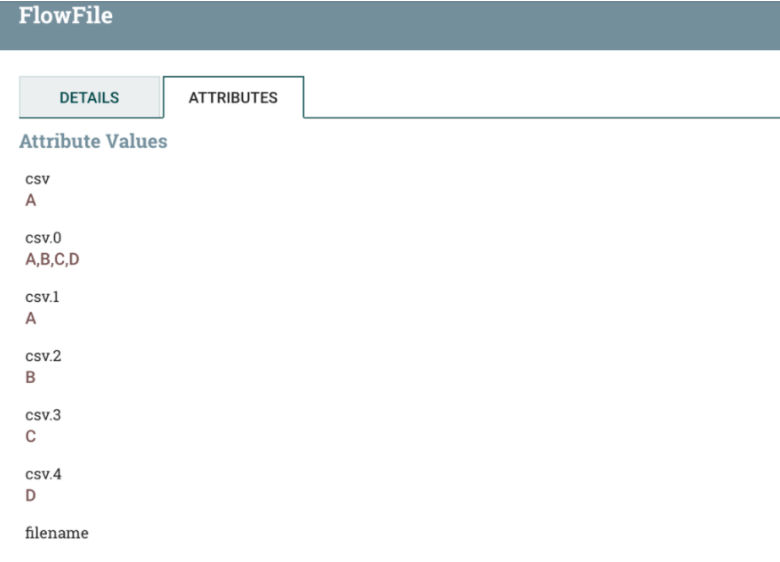
数据流被解析为 CSV 格式,以逗号分隔。
ReplaceText
替代方案,可以用replaceText自己生成插入的sql语句。
SplitJson
对json进行拆分?根据jsonPath(JsonPath中的“根成员对象”始终称为$,无论是对象还是数组 https://www.cnblogs.com/jpfss/p/10973590.html)允许用户根据JSON元素将由数组或许多子对象组成的JSON对象拆分为FlowFile。
JsonPath Expression:选择json中需要拆分的字段名称,该字段名称中的value为json格式的多条数据,组件会将value中的多条数据拆分成数量相等的数据流,并舍弃拆分字段名称value值之外的所有数据。
jsonPath:$.name[]
原始数据:{“name”: [{“last”: “li”},{“first”: “wang”}],”testdata”: “test”}
分割后后变成两条:
{“last”:”li”}
{“first”:”wang”}
如果整体数据就是jsonArray的形式,jsonPah可以用$.。另外如果文件名重复,可以使用updateAttribute更改filename,设置为uuid。
————————————————
版权声明:本文为CSDN博主「quguang1011」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/quguang65265/article/details/78698088
EvaluateJsonPath
提取json中的某个属性作为参数,用户提供JSONPath表达式(类似于XPath,用于XML解析/提取),然后根据表达式内容对这些json进行计算提取,以替换FlowFile内容或将值提取到用户命名的Attribute中(Destination)。
UpdateAttribute:
向FlowFile添加或更新任意数量的用户定义属性。
这对于添加静态配置的值以及使用表达式语言动态派生属性值很有用。
该处理器还提供了一个“高级用户界面”,允许用户根据用户提供的规则有条件地更新属性。
如修改 filename 的格式为${filename}-${now():toNumber():format("yyyy-MM-dd_HHmmss")}.json:
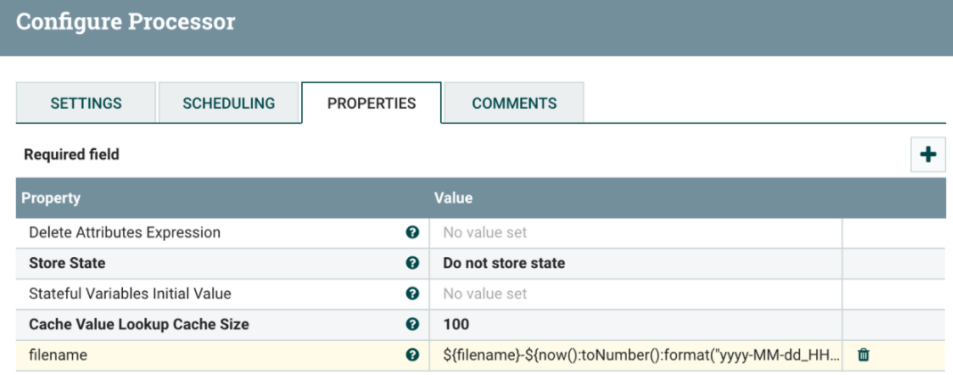
https://blog.csdn.net/u010022051/article/details/51276170
https://stackovernet.xyz/cn/q/12472401
AddSchemaNameAttribute:对处理的flowfile添加一个属性
UpdateRecord
https://zhuanlan.zhihu.com/p/257009588
https://cloud.tencent.com/developer/ask/154354/answer/267084
服务日志组件
LogMessage 用它可以在服务端打日志,内容是自己设置的,少用
LogAttribute 用它可以在服务端打日志,内容是FlowFile的属性,少用
数据库组件
SelectHiveQL 执行hql查询语句,结果格式是Avro or CSV
HiveConnectionPool
PutSQL 执行INSERT、UPDATE 的sql,sql可直接写,也可来自flowFile
ExecuteSQL 执行sql查询语句,结果格式是Avro。参数支持?如果它是由传入的FlowFile触发的,则在评估选择查询时,该FlowFile的属性将可用,并且该查询可以使用?,参数必须作为FlowFile属性存在
HiveConnectionPool
DBCPConnectionPool
DBCPConnectionPoolLookup DBCPConnectionPoolLookup
DBCPConnectionPoolLookup这个Controller Service很简单,也非常有用,说白了,它就是保存了一个我们使用者定义的Map,key是我们自己命名的,value是我们选择的当前流程可用的DBCPConnectionPool,然后在流程运行过程中,DBCPConnectionPoolLookup根据FlowFile中一个叫database.name的属性去这个Map里查找DBCPConnectionPool。使用DBCPConnectionPoolLookup的最大优点是什么?灵活啊!组件不绑定于一个数据库,根据流文件中的属性动态去查找对应的数据库。
https://blog.csdn.net/weixin_36048246/article/details/87359310
ConvertJSONToSQL
(注意:该处理器有一个特性,只能处理flat json,所谓flat是指it consists of a single JSON element and each field maps to a simple type)
另外ConvertJSONToSQL 不支持hive 这是nifi的一个bug https://blog.csdn.net/aiyinsitan215/article/details/93617838
大量数据插入,这个Processor的效率很低的,为什么这么说呢,一个流的数据如果是json,也应该是json数组,但一个json数组通过这个processor得到的结果是若干个insert语句,每一个insert语句中只有一条数据;可以改进成insert into table ()values ()()。。。的形式;也可以使用PutDatabaseRecord 做大量数据的insert,PutDatabaseRecord的优势是内置reader,减少了流程的中间落地(当然PutDatabaseRecord 也没有做到最好,还可以再优化,我自己改过一版PutDatabaseRecordQuicklyForInsert ,有空再更一下)
————————————————
版权声明:本文为CSDN博主「酷酷的诚(公众号:Panda诚)」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_36048246/article/details/87363263
ExecuteSQLRecord 执行sql查询语句,结果格式可通过Record Writer自定义 https://blog.csdn.net/weixin_36048246/article/details/87359310
可选连接池同上
Record Writer:
FreeFormTextRecordSetWriter
ParquetRecordSetWriter
XMLRecordSetWriter
JsonRecordSetWriter
CSVRecordSetWriter
AvroRecordSetWriter
ScriptedRecordSetWriter
使用有点难度还用好很高级的组件
RouteOnAttribute
http://www.blogjava.net/tw-ddm/articles/433714.html
RouteOnContent
Nifi表达语言
https://nifi.apache.org/docs/nifi-docs/html/expression-language-guide.html#replaceempty
if else语句
https://www.javaroad.cn/questions/124812
${uuid:replaceEmpty(${device_id})}
${field.value:toDate("yyyy-MM-dd HH:mm:ss", "GMT"):format("yyyy/MM/dd", "GMT")}
${field.value:toDate("yyyy-MM-dd HH:mm:ss", "GMT"):format("HH:mm:ss", "GMT")}
${$area:isEmpty():not()}
RecordPath Domain-Specific Language (DSL)
http://192.168.0.40:18080/nifi-docs/html/record-path-guide.html
${gId:equals(1):ifElse('男', '女')}
${gender:equals(1)}
${field.value:toDate("yyyy-MM-dd HH:mm:ss", "GMT+8"):format("yyyy/MM/dd HH:mm:ss", "GMT+8")}
https://www.renfei.net/posts/1003284
一些例子
https://note.youdao.com/ynoteshare1/index.html?id=298cd2d8df4131161f350ef328ccbcb9&type=note
使用例子
这里很多别人的使用经验:
https://ask.hellobi.com/blog/seng/category/3137
文件读取、输出
组件:GetFile、PutFile
https://www.cnblogs.com/h--d/p/10079418.html
这种,相当于在动态MV或COPY文件,同名文件可以有替换(会一直循环不断替换)、忽略、报错三种处理方式。
FTP读取 、修改、输出到 HDFS
组件:GetFTP、CompressContent(压缩或解压FlowFile的内容)、ReplaceText(通过定义正则表达式,可对正则表达式匹配到的内容进行替换)、PutHDFS
https://www.jianshu.com/p/d2ed34060dfd?from=singlemessage
hdfs读取 ,输出到 hive
https://www.cnblogs.com/fengwenit/p/5795580.html
文件内容处理
Excel to ES
组件:GetFile Processor拉取表格、
ConvertExcelToCSVProcessor 将Excel多sheet表格转为多个csv Flowfile、
ConvertRecord Processor 将csv Flowfile转换为Avro Flowfile、
SplitRecord Processor 将从csv取到的Avro Flowfile按行split为单条Avro、
Record Processor为每一条数据添加source字段标明数据来源,并将Avro Flowfile转为json Flowfile、
PutElasticsearch Processor 将数据存入ES
https://zhuanlan.zhihu.com/p/257009588
用到的控制器:
CSVReader:
https://blog.csdn.net/qinqinyijia/article/details/77775054
AvroSchemaRegistry:
{ "name": "people", "namespace": "nifi", "type": "record", "fields":
[ {"name": "id" , "type" : "int"}
, {"name": "name" , "type" : "string"}
, {"name": "age" , "type" : "string"}
, {"name": "address" , "type" : "string"}
, {"name": "祖籍" , "type" : "string"}
] }
es:
https://www.cnblogs.com/lightsong/p/12688996.html
CSV 格式 转为 JSON 格式
json to csv
https://www.cnblogs.com/fengwenit/p/5795576.html
数据库查询
mysql 查询
组件:ExecuteSQL(执行SQL语句,返回avro格式数据。)、ConvertAvroToJSON、ConvertJSONToSQL、PutSQL
一个同步表的例子:https://blog.csdn.net/zhulu52166/article/details/83380717
https://www.cnblogs.com/h--d/p/10079418.html
一个处理文本然后插入表的例子(ExecuteScript写脚本处理数据 ):https://blog.csdn.net/qinqinyijia/article/details/77869566
ExecuteSQLRecord 需要配置 RecordWriter ,可以灵活地指定输出格式,(如添加JsonRecordSetWriter -> 编辑JsonRecordSetWriter -> 在JsonRecordSetWriter添加AvroSchemaRegistry -> 编辑AvroSchemaRegistry -> AvroSchemaRegistry添加内容(内容是Avro格式)--> 激活AvroSchemaRegistry -> 激活JsonRecordSetWriter 参考:https://www.cnblogs.com/h--d/p/10081777.html)
mysql to hive
https://blog.csdn.net/aiyinsitan215/article/details/93617838
Change Data Capture (CDC)
https://community.cloudera.com/t5/Community-Articles/Change-Data-Capture-CDC-with-Apache-NiFi-Part-1-of-3/ta-p/246623
- Mysql导入至HBase
https://www.meiwen.com.cn/subject/fkzxlqtx.html
kafka读取
https://www.jianshu.com/p/626c32c43294
web api 取数据到 hdfs
组件: InvokeHttp可以通过http请求获取数据
https://www.cnblogs.com/fengwenit/p/5589397.html
更多例子:
https://cwiki.apache.org/confluence/display/NIFI/Example+Dataflow+Templates
https://www.cnblogs.com/fengwenit/p/5557035.html
https://blog.csdn.net/quguang65265/article/details/78698088
https://blog.csdn.net/quguang65265/article/details/78697678
https://note.youdao.com/ynoteshare1/index.html?id=298cd2d8df4131161f350ef328ccbcb9&type=note
https://github.com/xmlking/nifi-examples
https://github.com/simonellistonball/masterclass-hdf
资料大全:https://my.oschina.net/u/2306127/blog/858096
csv to mysql
https://blog.csdn.net/u012261499/article/details/109612107
PutDatabaseRecord
https://blog.csdn.net/weixin_36048246/article/details/108781872
更多例子
https://blog.csdn.net/xuzhaoa/article/details/107042660
https://www.cnblogs.com/adolfmc/archive/2012/10/07/2713562.html
https://www.iteye.com/blog/hck-1566801
https://blog.csdn.net/lamp113/article/details/79176410
https://www.cnblogs.com/mkl34367803/p/10566827.html
https://blog.csdn.net/xiaoguangtouqiang/article/details/82182654
https://blog.csdn.net/weixin_40763897/article/details/105048517
- 如果要使用NiFi提供Web服务,请查看HandleHTTPRequest和HandleHTTPResponse处理器。通过使用两个处理器的组合,您将通过HTTP接收来自外部客户端的请求。您将能够对请求中的数据进行处理,并将自定义答案/结果发送回客户端。例如,您可以使用NiFi通过HTTP访问外部系统,例如FTP服务器。您将使用两个处理器并通过HTTP发出请求。当您在NIFi中收到查询时,NiFi会针对FTP服务器进行查询以获取文件,然后将文件发送回客户端。
- 使用NiFi,所有这些独特的请求都可以很好地扩展。在这种用例中,NiFi将根据需求进行水平扩展,并在NiFi实例的前面设置负载均衡器,以平衡集群中NiFi节点之间的负载。
nifi中的数据聚合?
nifi集群
nifi架构原理
https://www.jianshu.com/p/115e6771ed5a 讲解了一些参数
https://www.jianshu.com/p/d2ed34060dfd?from=singlemessage 里面还有ReplaceText组件使用例子。
https://www.cnblogs.com/zskblog/p/7284198.html
https://www.cnblogs.com/ronnieyuan/p/11935871.html
https://www.cnblogs.com/cobub-yx/p/7772196.html
一些灵魂拷问
如果可以使用Kafka作为群集的入口点,为什么还要使用NiFi?
https://my.oschina.net/bigdatagrocery/blog/4901507
我不知道这个blog说了些啥?
https://blogs.apache.org/nifi/
nifi的容器化部署,遇到数据不能持久化的问题
1、发现数据(流配置文件)存储在 conf/ 下,然而conf/ 又没有进行挂载
尝试挂载conf目录,然而容器启动报错
replacing target file /opt/nifi/nifi-current/conf/nifi.properties
sed: can't read /opt/nifi/nifi-current/conf/nifi.properties: No such file or directory
2、数据存储的位置设置到一个被挂载的牡蛎,比如 work/ 下
在configmap里,挂载了bootstrap.conf文件,
在文件里修改 nifi.flow.configuration.file 更改为 ./work/flow.xml.gz,还有archive.dir地址,然而并不生效。
bootstrap.conf文件是配置NiFi应该如何启动的地方,不知道谁把nifi.properties的设置项也考进来了
3、添加nifi.properties文件挂载,并设置流配置文件路径。
然而容器启动报错
replacing target file /opt/nifi/nifi-current/conf/nifi.properties
sed: cannot rename /opt/nifi/nifi-current/conf/sedB1aWUR: Device or resource busy
因为nifi启动会 replacing target file /opt/nifi/nifi-current/conf/nifi.properties
4、指定环境变量来设置
NIFI_VARIABLE_REGISTRY_PROPERTIES=./conf/bootstrap.conf
似乎仍不起效
因为这里的变量并不是针对nifi服务的变量,参考
5、研究启动脚本,start.sh,发现 这一段
prop_replace () {
target_file=${3:-${nifi_props_file}}
echo 'replacing target file ' ${target_file}
sed -i -e "s|^$1=.*$|$1=$2|" ${target_file}
}
export nifi_props_file=${NIFI_HOME}/conf/nifi.properties
prop_replace 'nifi.cluster.flow.election.max.wait.time' "${NIFI_ELECTION_MAX_WAIT:-5 mins}"
有了点灵感
- 先在容器里添加环境变量
2)再把环境变量里的值,通过start.sh脚本,修改在 nifi.properties里
Configmap添加:
prop_replace 'nifi.flow.configuration.file' "${NIFI_FLOW_CONFIGURATION_FILE:-}"
prop_replace 'nifi.flow.configuration.archive.dir' "${NIFI_FLOW_CONFIGURATION_ARCHIVE.DIR:-}"
prop_replace 'nifi.templates.directory' "${NIFI_TEMPLATES_DIRECTORY:-}"
容器env里添加:
env:
- name: NIFI_FLOW_CONFIGURATION_FILE
value: ./work/flow.xml.gz
- name: NIFI_FLOW_CONFIGURATION_ARCHIVE_DIR
value: ./work/archive/
- name: NIFI_TEMPLATES_DIRECTORY
value: ./work/templates

 浙公网安备 33010602011771号
浙公网安备 33010602011771号