
hive sql 练习
https://blog.csdn.net/E699A8/article/details/107139850
https://blog.csdn.net/dazuo_001/article/details/116979591
列转行函数
用途:多列数据根据 group by 合并为一行
collect_list(field1)为不去重转换,collect_set(field1)为去重转换。
需要拼接函数concat_ws(separator, value1, value2,...)拼接集合元素,array_sort 可排序
eg:
CREATE table student_score_new
as
SELECT
stu_id,
stu_name,
concat_ws(’,’,collect_set(course)) as course,
concat_ws(’,’,collect_set(score)) as score
from student_score
group by stu_id,stu_name
行转列函数/炸裂函数
用途:上面的逆向操作把string、array或map格式的字段转换成行的形式,一行变多行。
处理string时需要使用split()函数把字段分割为array
eg:lateral view explode(split(course,’,’)) cr as ecourse
出现两个并列的explode的sql会得到size(field1Value) * size(field2Value)行, 没有形成对应关系,所以对于多个数组的行转列可以使用posexplode函数结合where条件。
eg:
lateral view posexplode(split(course,’,’)) cr as a,ecourse
lateral view posexplode(split(score,’,’)) sc as b,escore
where a=b;
over 系列
参考doris
在over()的范围内,分组后内部取值,常用于分区排序、层次查询
窗口函数
first_value(field)
取分组内排序后,截止到当前行,第一个值
select first_value(score) over(distribute by tname sort by score desc ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) score
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:无界限(起点或终点)
UNBOUNDED PRECEDING:表示从前面的起点
UNBOUNDED FOLLOWING:表示到后面的终点
last_value(field)
取分组内排序后,截止到当前行,最后一个值
分析函数
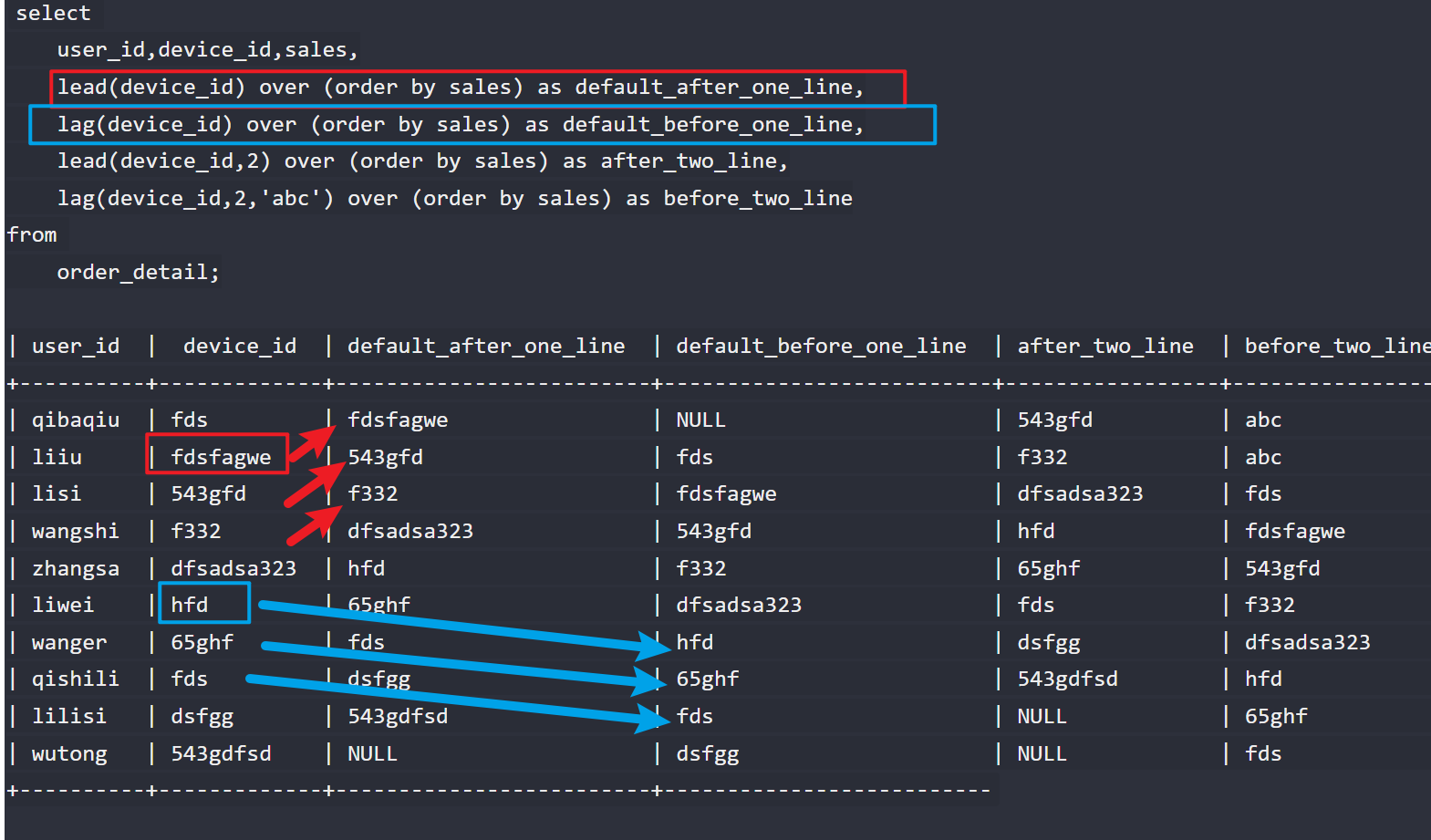
lead(col,n,default)
跟偏移量相关,可以在一次查询中取出同一字段的前N行的数据(lag)和后N行的数据(lead)作为独立的列,从而更方便地进行进行数据过滤。
lag(col,n,default)用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为第n行(可选,默认为1,不可为负数),第三个参数为默认值(当第n行为null时候,取默认值,如不指定,则为null)
row_number
select c_id,s_id,s_score,row_number()over(partition by c_id order by s_score desc)as rank from score;
根据 c_id 分组,并根据 s_score 从大到小排序,顺序 1、2、3 作为 rank 列(相等的也会按顺序排)。
练习!!!!
rank
也是排序赋值 1、2、3 ,但相等的会是一样的排名值但后面的排序值会加1如:1,1,3,3,5,6,7,在名次中会留下空位
select c_id,s_id,s_score,rank() over(distribute by c_id sort by s_score desc)as rank from score;
dense_rank
排名相等会在名次中不会留下空位如:1,1,2,2,3,4,5.
cume_dist: 小于等于当前值的行数/分组内总行数
percent_rank: 分组内当前行的RANK值-1/分组内总行数-1
ntile(n)
用于将分组数据按照顺序切分成n片,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布。ntile不支持rows between
-- 求取sale前20%的用户ID
select
user_id
from
(
select
user_id,
NTILE(5) OVER(ORDER BY sales desc) AS nt
from
order_detail
)A
where nt=1;
聚合函数
也可配合 count(), sum(), min(), max, avg() 等函数使用
group by xx grouping sets 多维数据分析
用途:多维数据分析,实现按照多组维度的结果分组。通过grouping sets的使用可以简化SQL,比group by单维度进行union性能更好。
参考
https://cwiki.apache.org/confluence/x/mxLMAQ
grouping sets() 按需组合
group by f1, f2, f3 grouping sets((f1), (f1, f3), (f2, f3))
select os,device, city ,count(*)
from requests
group by grouping sets((os, device), (city), ());
上述语句等效于如下语句:
select os, device, NULL, count(*)
from requests group by os, device
union all
select NULL, NULL, NULL, count(*)
from requests
union all
select null, null, city, count(*)
from requests group by city;
with cube 维度全组合
group by f1, f2, f3 with cube
全排列
-- (),
-- (f1),
-- (f2),
-- (f3),
-- (f1, f2),
-- (f1, f3),
-- (f2, f3),
-- (f1, f2, f3)
with rollup 维度上卷
group by f1, f2, f3 with rollup
相当于group by f1, f2, f3 grouping sets((), (f1), (f1, f2), (f1, f2, f3))
总结写sql逻辑
对条件分析“主体条件”、“动作条件”,先筛选出主体,再筛选符合的动作,两个join

 浙公网安备 33010602011771号
浙公网安备 33010602011771号