【入门精讲】数据仓库原理&实战
2021-09-13 20:55 cascle 阅读(502) 评论(0) 收藏 举报一.诞生背景
业务历史低频使用数据太多,产生不必要负载
各个数据系统分离存储,数据不一致,权限分配过多,资源浪费
数据分析需求
总结就是数据积存、数据分析这两个需求
二.概述
面向主题、集成、非易失且随时间变化
OLAP,冗余反范式
三.数据仓库实现
传统:MPP集群。扩展性和热点问题无法解决
大数据数仓:把SQL转为计算引擎任务。移动计算而非移动数据
四.MPP与分布式架构
MPP:CAP
分布式架构:PAC
MPP+分布式架构:常用于流式处理
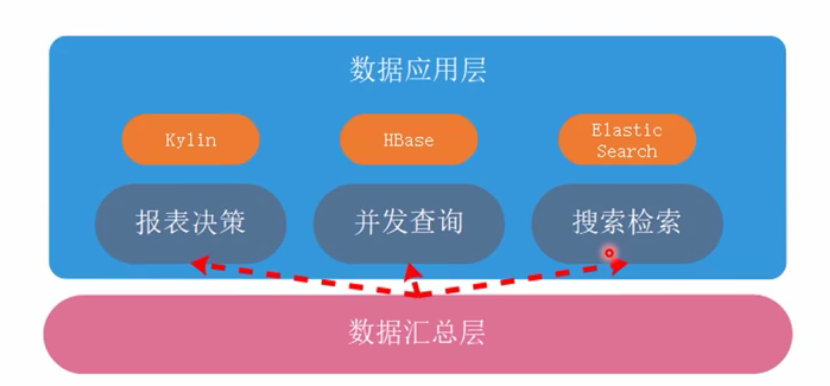
五.架构
架构图
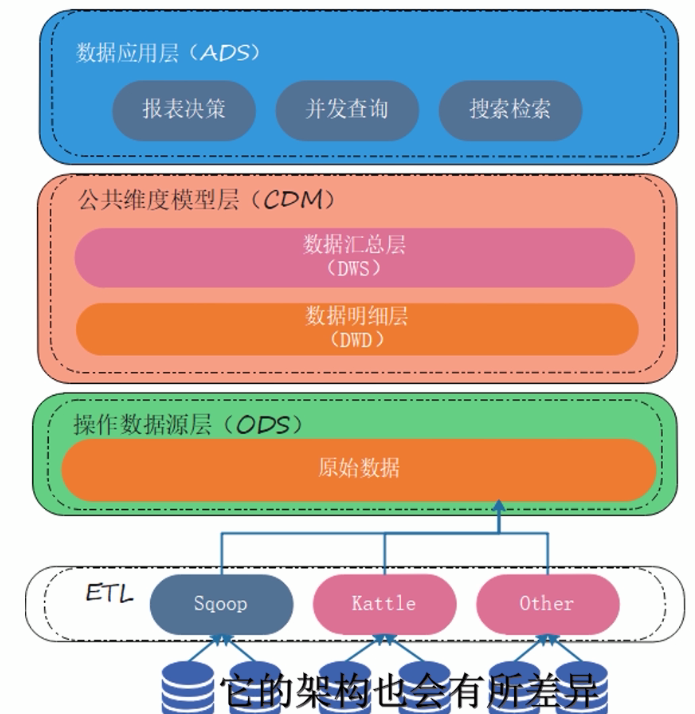
ETL流程:数据清洗(主要是非结构化、半结构化)、标准化
数据积存
ODS:数据非易失性,不准随意修改。目的是为了保存历史数据,源数据可能会被删掉
数据分析
DWD:清洗、标准化,统一编码,统一规范。数据满足三范式。注重数据分析
DWS:按照主题进行汇总、聚合,一般是宽表,进行了join有冗余。还有数据建模也在这一层。注重数据分析
ADS:DWS进行算子运算后得到的结果层。注重数据查询速度,也叫数据集市层
六.ETL
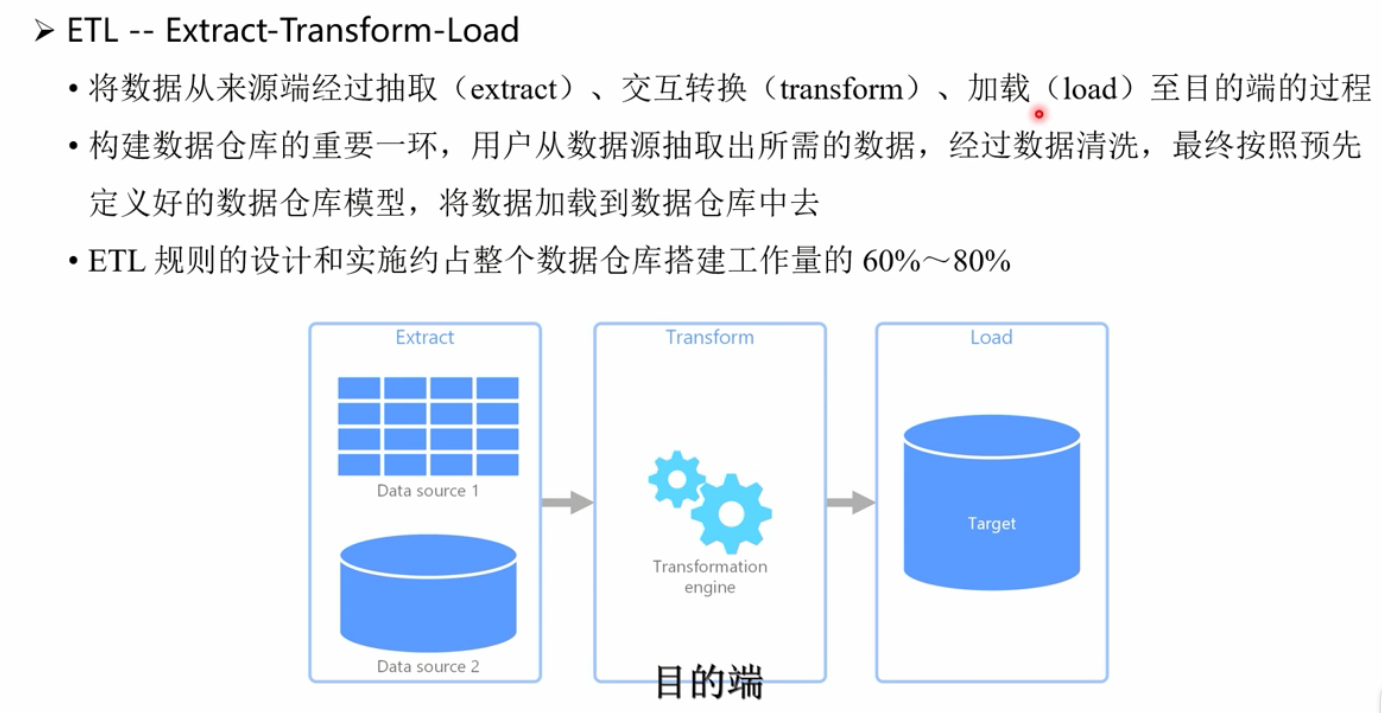
Kafka,Flume,Logstash等工具可以动态监控
七.ODS
与原始数据一致,但是可以加字段,比如时间戳,源头,更新方式等
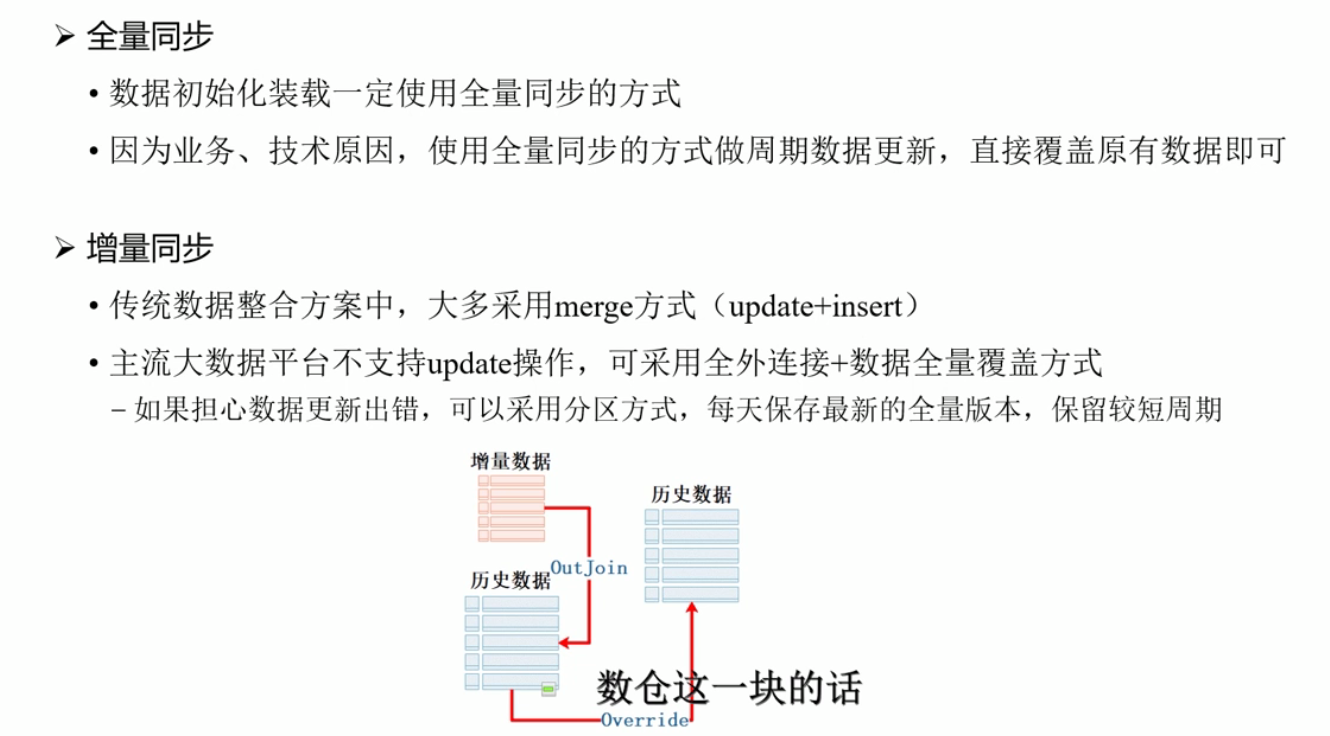
增量导入一般是外连接+全覆盖
八.DWD
ods的数据进行清洗、标准化、维度退化(退维就是取消外键,一些可枚举值不需要建立维度表,比如城市,搞一个城市表再把城市id放在事实表里,直接把城市名放在事实表里即可)
维度退化:把维度表里的数据冗余加载到主表里,避免后续join操作。增加了主表的维度(列)
还符合三范式规范
使用join生成新表完成退维
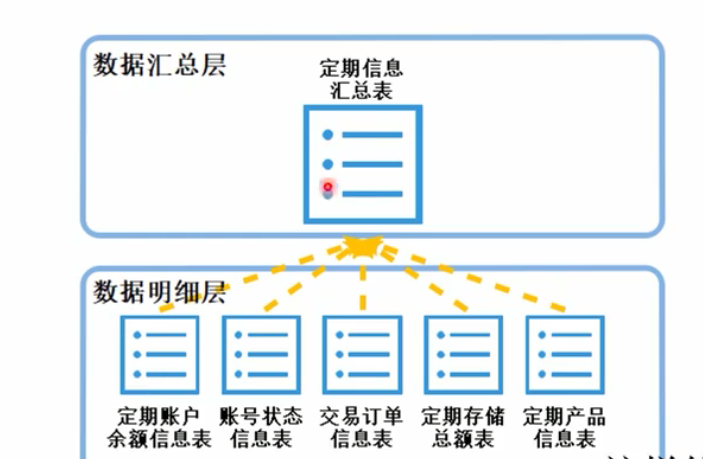
九.DWS
按照主题进行汇总,注重数据聚合、复杂查询、处理性能更优的数据仓库模型,比如维度模型。最终形成一个违背3nf的宽表。里面的数据基础group by聚合统计
十.ADS
不涉及分析、计算,只为快速出结果。通过计算得到ads表,存放数据产品个性化的统计指标数据
数据表不存在数仓中,一般在MySQL、ClickHouse这样的传统数据关系型库里
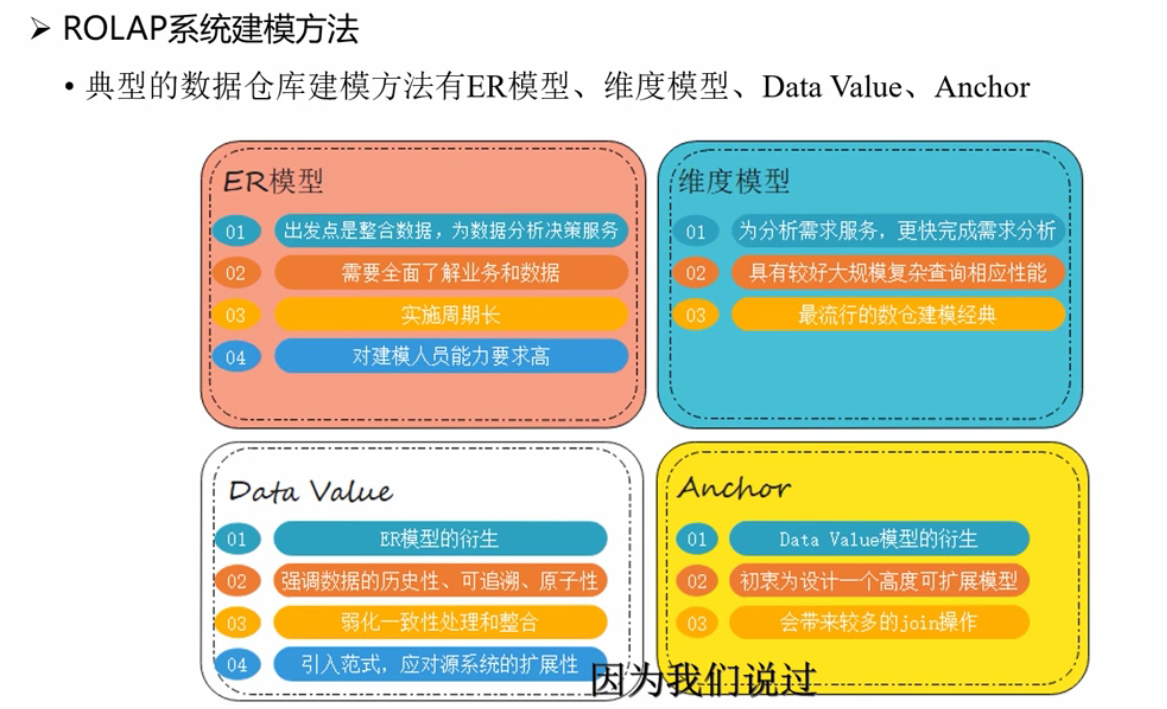
十一.建模方法
基本概念:OLTP,OLAP
OLTP:随机读写,减少冗余,ER模型尽量拆分数据表
OLAP:注重数据整合

ROLAP:面向DWS层
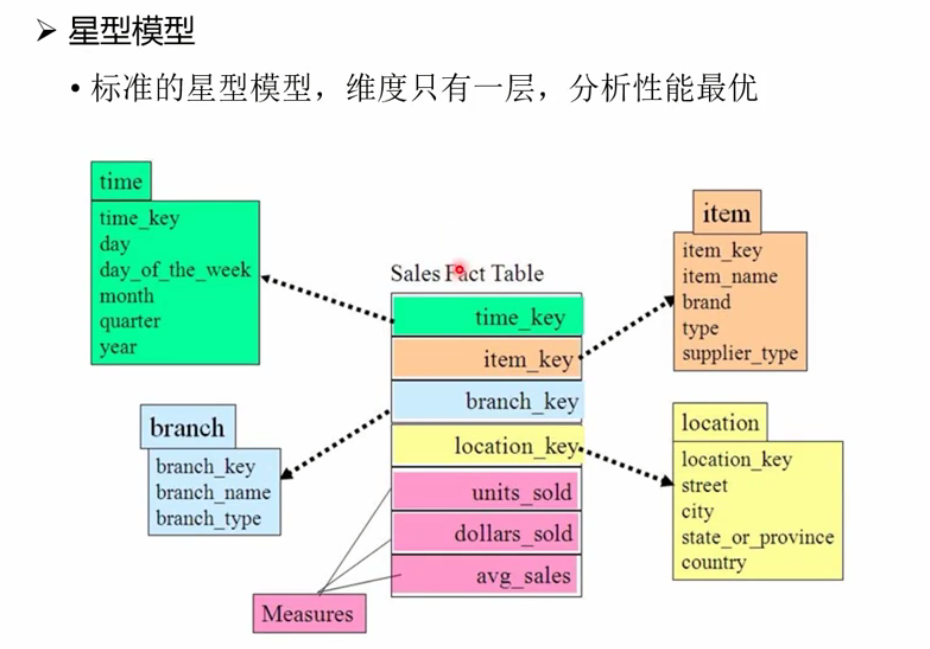
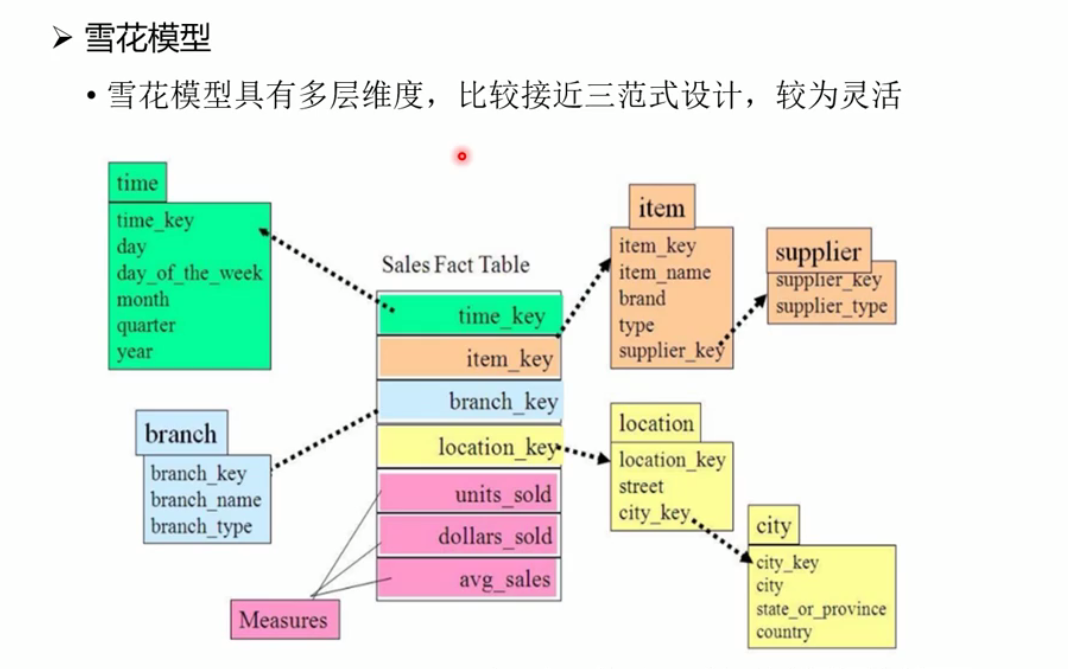
维度表:星型模型、雪花模型、星座模型
星型模型:
雪花模型:
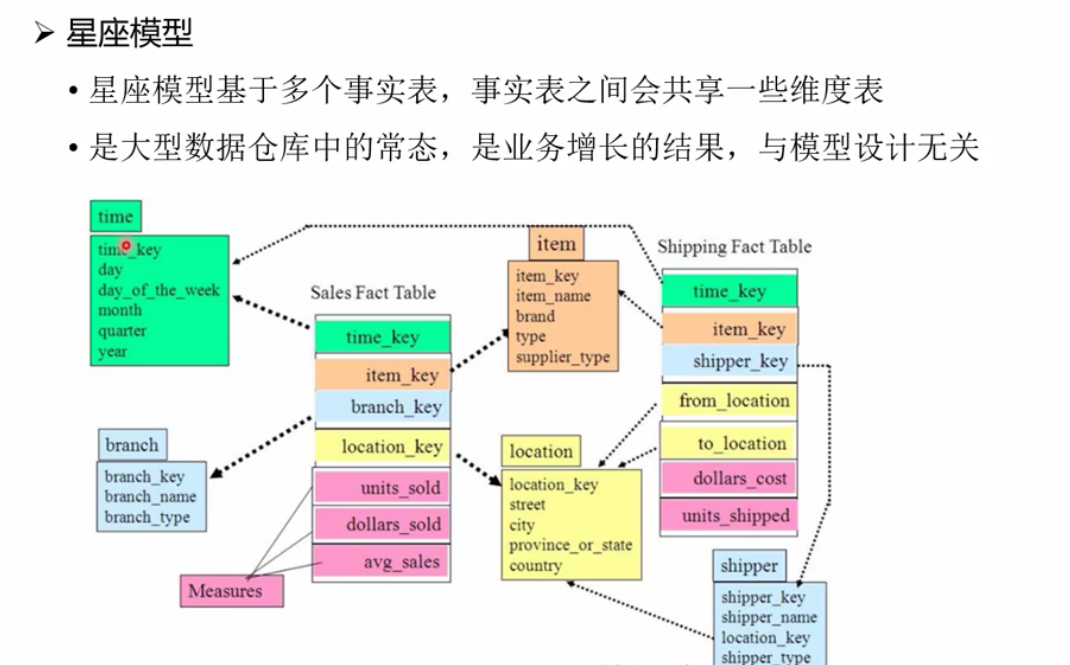
星座模型:
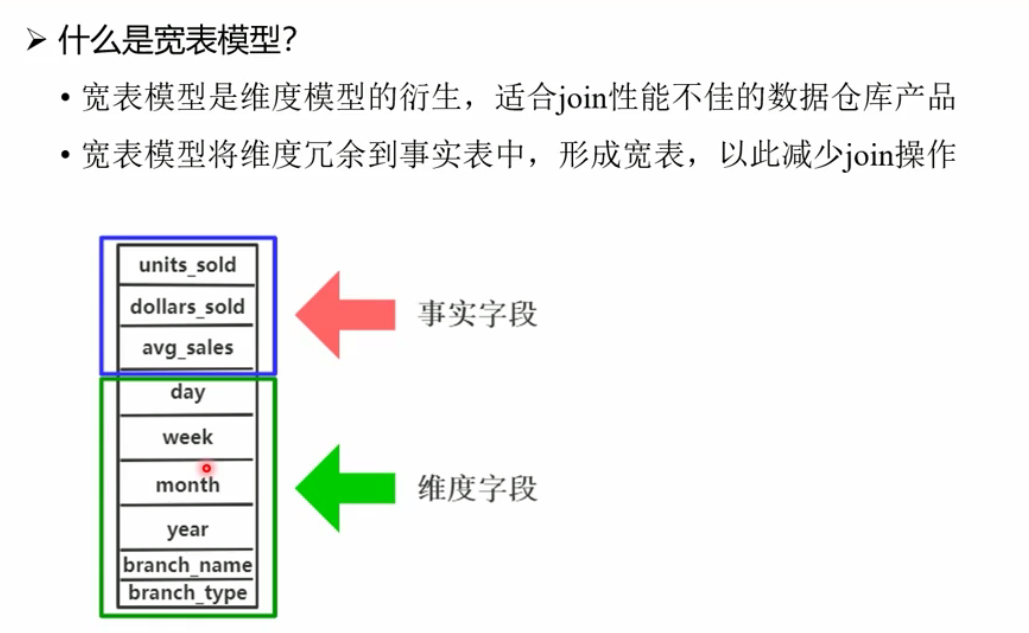
宽表: 维度模型衍生,事实字段、维度字段一起存在
MOLAP:CUBE模型,预计算,失去了灵活性。以多维数组的形式存在。面向ADS层
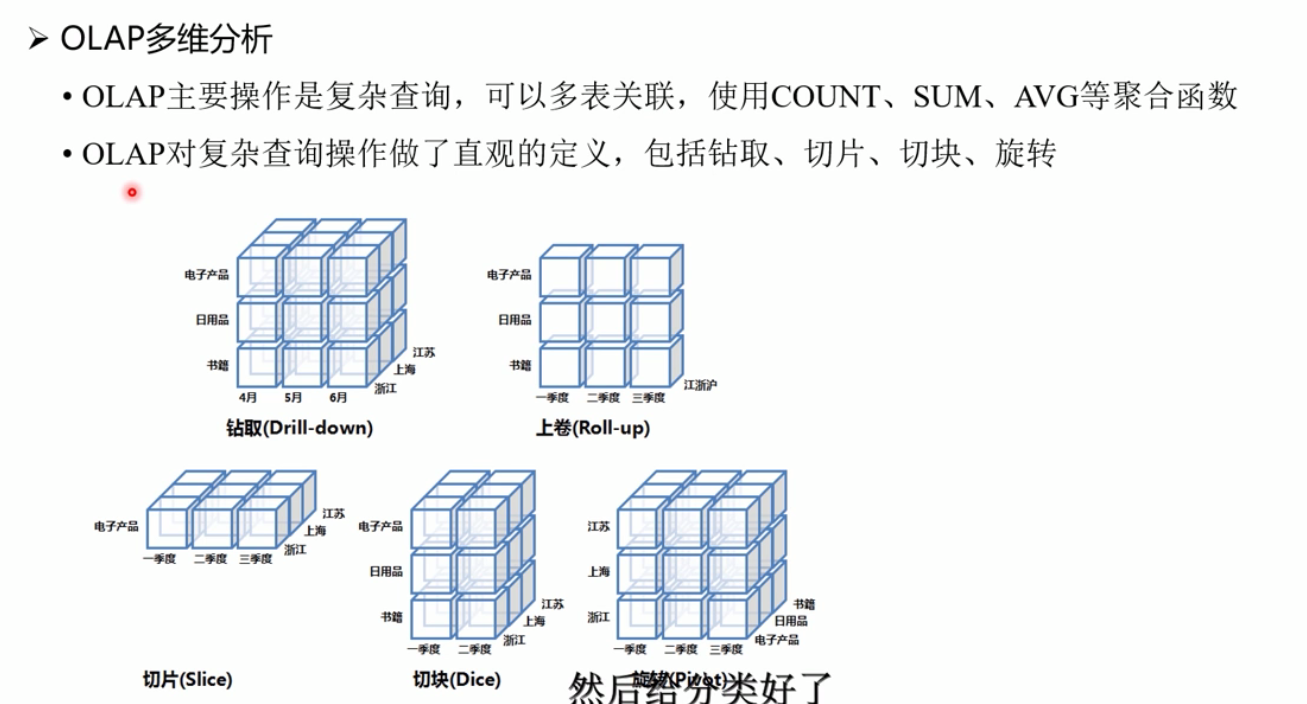
多维分析:钻取、切片、切块、旋转
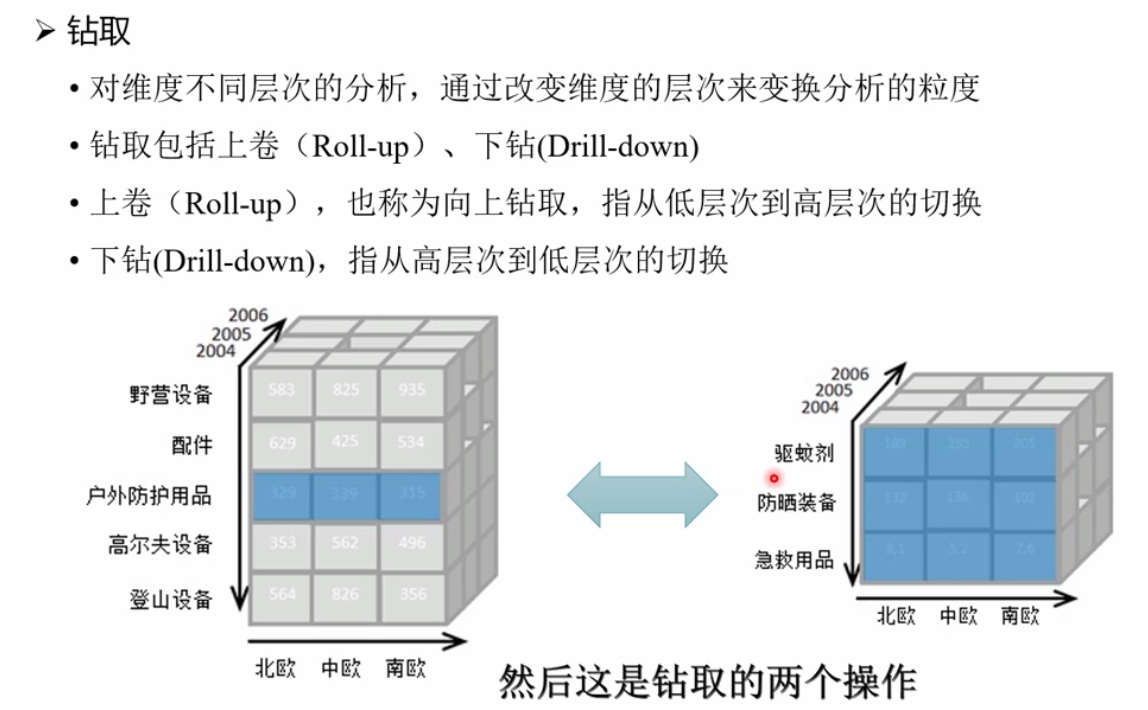
钻取:
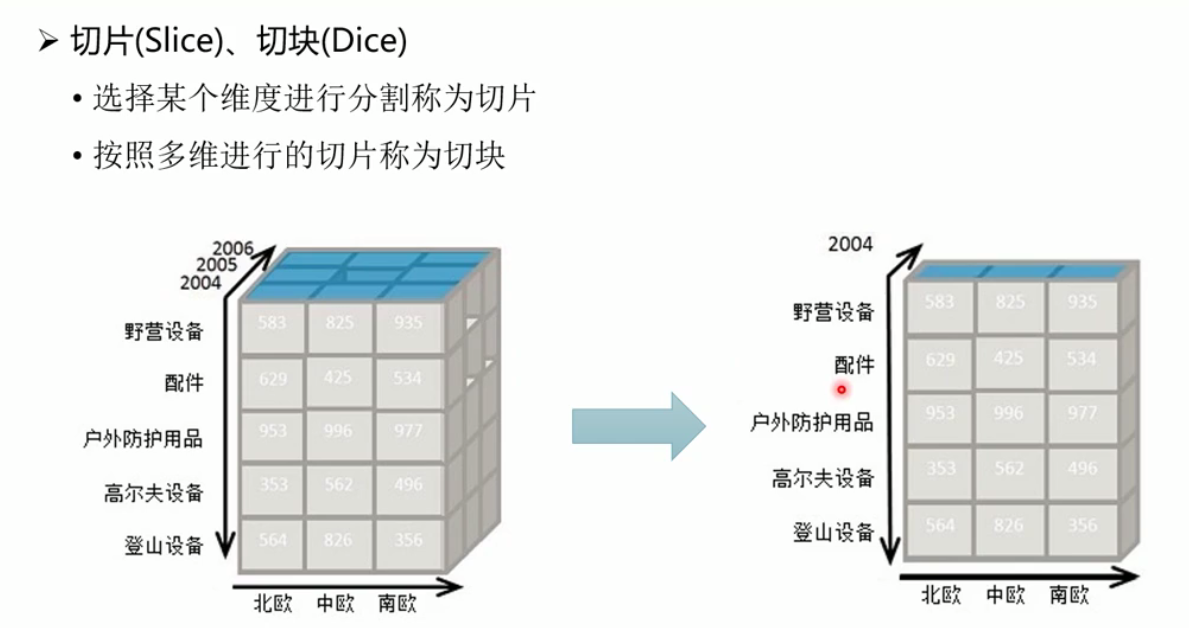
切片切块:
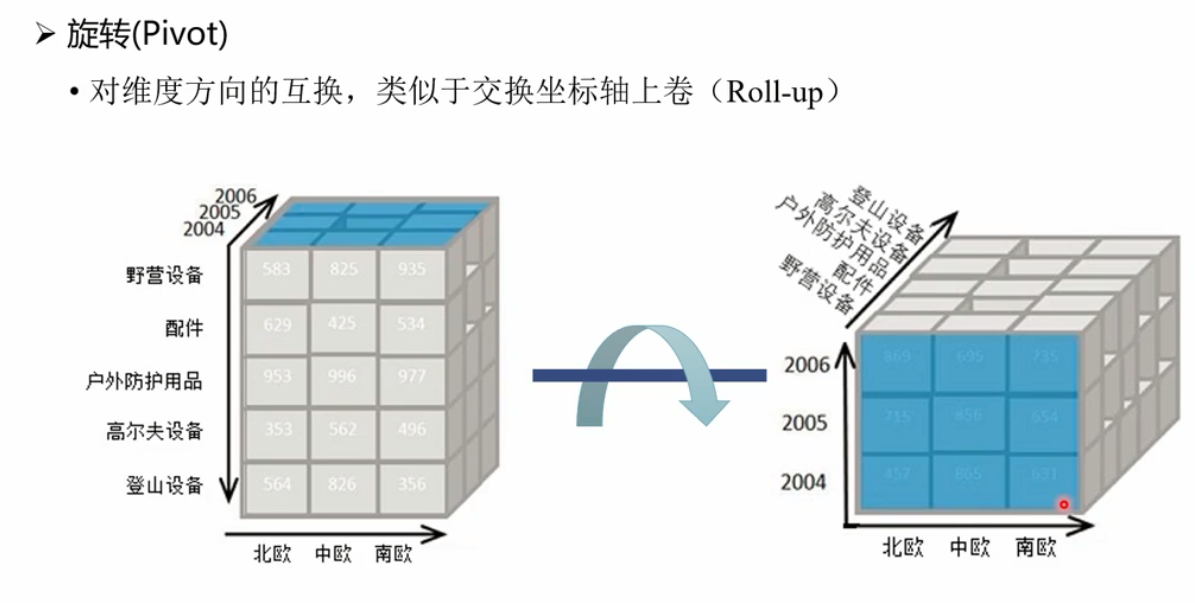
旋转:
十二.表分类
事实表
维度表
事物事实表
周期快照事实表
累积事实快照表:比较随机,意味着高概率修改
三种方案解决:


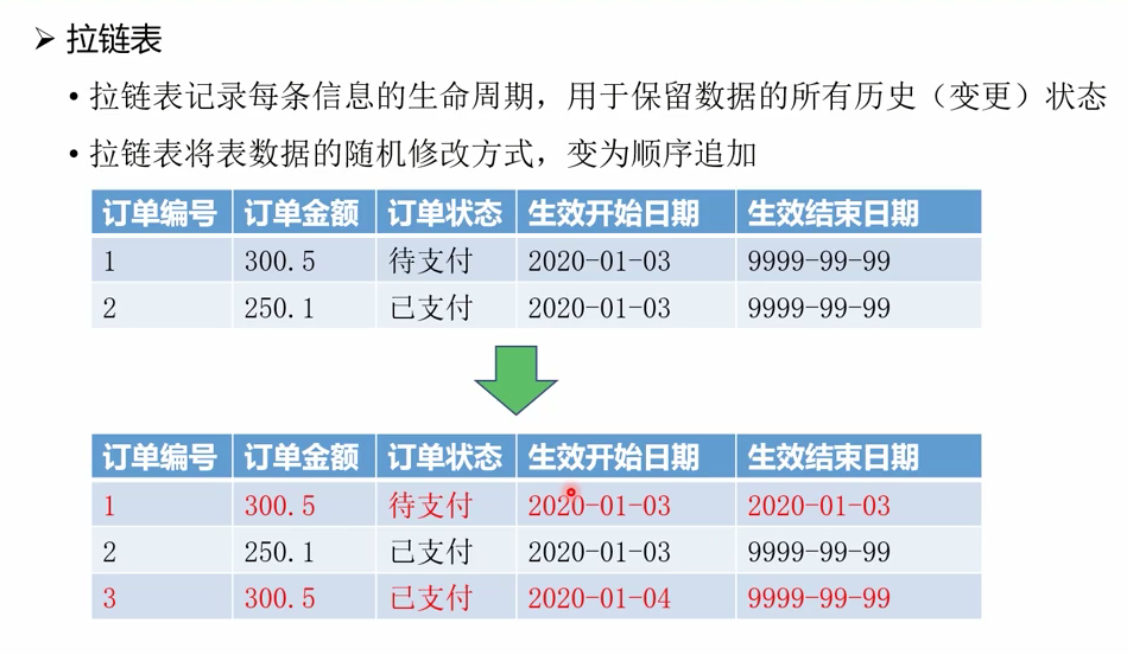
拉链表:
十三.ETL同步策略
十四.任务调度
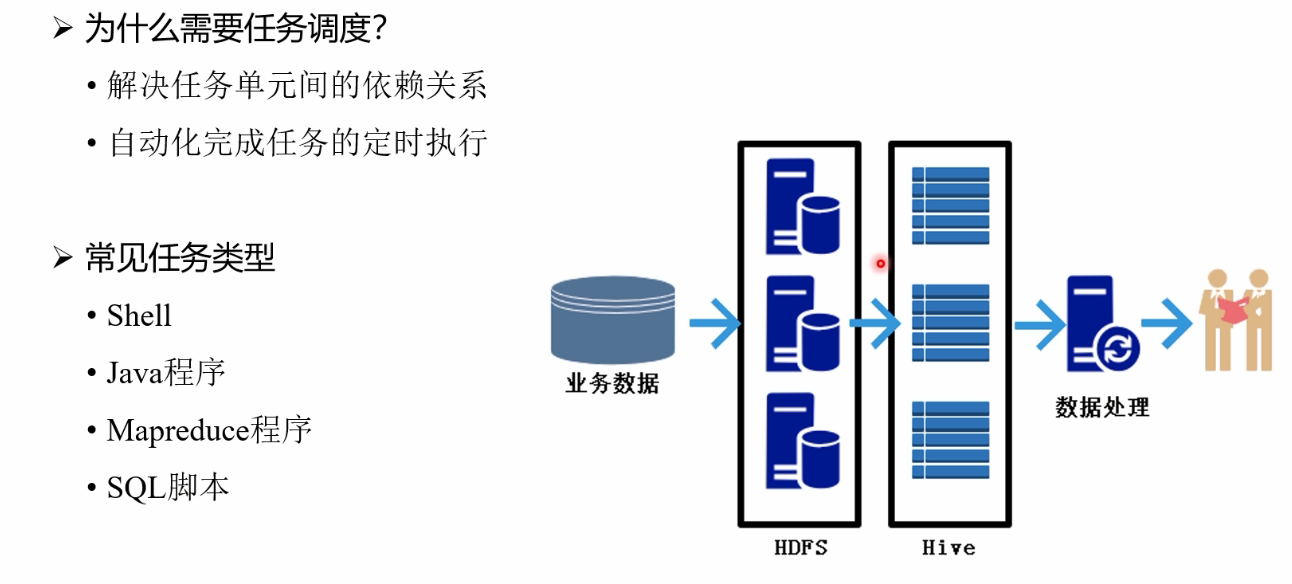
十五.
十六.
十七.
十八.
十九.
二十.
二十一.
二十二.
二十三.
二十四.
二十五.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号