大数据HIve视频教程全集笔记
2021-08-06 11:15 cascle 阅读(234) 评论(0) 收藏 举报一.课程介绍
分十一章
- 基本概念
- 安装
- 数据类型
- DDL,数据定义
- DML,数据操作
- 查询
- 函数
- 压缩和存储
- 调优
- 实战谷粒影音
- 常见错误及解决方案
二.基本概念
Hive是个翻译引擎,仅存在于客户端,计算集群中不存在。
Hive无法支持迭代计算,数据挖掘不擅长
三.安装
Hive配置文件:conf/hive-env.sh.template,改为sh脚本再执行。要改hadoop文件位置和hive配置文件夹内容
use 《数据库》;
show tables;
create tables student(id int, name sring);
insert into student values(2, "sq");
desc student;
quit;
load data local inpath "/pata/data.txt" into table student;
drop table student;
create tables student(id int, name sring) row format delimited fields terminated by "\t";
hive默认只有单一用户数据库
Mysql无主机登录:mysql数据库里user表;select User,Host,Password from user;update user set host='%' where host='localhost';delete from user where Host=;hadoop102';flush privilleges;
配置Hive MetaStore数据放Mysql里:1.拷贝mysql驱动到hive/lib下;2.conf/hive-site.xml配置;3.会在mysql里创建metastore数据库(可配置);
-e:sql在字符串里;-f:sql在文件里
exit:先提交再退出
quit:直接退出,但是新版的无区别了
dfs ls /;
! ls /;
历史命令在家目录下的.hivehistory中
hive-site.xml里可以配置当前数据库名称和表结构名称,hive.cli.print.header和hive.cli.print.current.db
数据仓库位置:hive.metastore.warehouse.dir里配置
日志默认都在logs文件下,hive-log4j.properties,配置hive.log.dir
修改配置:全局修改;命令行用-hiveconf配置键值对;终端中用set命令设置
set 键值,查看值
四.数据类型
hive数据类型大写
复合数据类型:STRUCT,MAP,ARRAY
CAST('1' as INT);把字符串1转换为INT
五.DDL
创建数据库:create database 《》;,默认文件夹路径在/usr/hive/warehouse/*.db
location后可以指定路径
if not exists不存在时执行
查询数据库:show databases;
模糊查询:show databases like 'hive#';
查询详情:desc database <数据库>;
extended查看额外信息
alter database 《数据库》 set dbproperties (”a“="b");
删除数据库:drop database 《数据库》;数据库不为空删不掉,最后要加cascade
创建表:CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type) [COMMNET col_commnet],...]……
要用JDBC连接Hive的话,要开hiverserver2服务;Beeline可以模拟JDBC连接Hive;
管理表:也叫内部表,表没了数据也没了
create table as
create table like
desc formatted <数据表>:查看表结构
内部表用来存中间结果和结果表,外部表存原始数据
内部表和外部表互相转换:alte table student2 set tlproperties(‘EXTERNAL'='FALAE');区分大小写和引号模式
partition就是建立一个单独的文件夹,大的数据集分为小的数据集,就是分目录,可以避免全表扫描
数据导入Hive时要指定分区,partition(分区名=’‘),指定分区列
alter table student add partition(分区名='');添加多个分区用空格分离
add改为drop即删除分区,删除多个partition用逗号分离
二级分区表:两个分区字段
分区表和数据产生关联的三种方式:
1.上传数据后修复:msck repair table 表名;
2.上传数据后添加分区
3.上传数据后load到分区
show partitions 表名;显示分区
修改表:
1.重命名:ALTER TABLE 名字 RENAME TO 新名
2.增加、修改、删除表分区
3.增加、修改、替换列信息:ALTER TABLE 表名 CHANGE COLUME 列旧名 列新名 列类型 ,change可为add和replace,replace是替换所有字段
六.DML
load加载数据
本地是复制导入,hdfs是移动导入;
insert插入数据:可以把select的中间表查询结果插入;可以有多插入模式,多行来自一个表可以放在开头;
as select方式创建表
创建表时通过location关键字指定数据位置来加载
import来导入export的数据
导出:
insert,导出到文件夹
hadoop dfs -get导出
hive shell输出重定向
export table 表明 to 路径,命令
清空表数据:truncate tabel 表名
hive可以导入任意格式的数据,只要数据可以被格式化可以被理解
七.查询
Hive的cwiki上有LanguageManual,可看select部分
列重命名:可以用as分隔也可以不用
join只能等值连接,内连接 left right full连接
order by,一个全局reducer,默认升序
sort by,局部reducer
属性mapreduce.job.reduces决定有几个reducer job,默认-1;
distribute by
类似hadoop分区,结合sort by使用,按照字段分配给不同reducer,使其将结果存在不同的文件中
cluster by
sort by和distribute by是一个字段
分桶表:一个文件夹内数据按文件存储而不是按文件夹,应对数据集过大,语法是clustered by;
分桶表用insert模式建立;
hive.enforce.bucketing为true;
reduce数量要hive自己决定;
这个就是hadoop里的分区
分桶抽样:
tablesample(bucket 1 out of 4 on id)
x为从哪个bucket出,y为bucket的几分之几
八.函数
给null赋值:nvl,列如果是null,则返回replace值
case when:case 字段 when 数值 then 数值 else 数值 end
行转列:
所谓的行转列是指把数据表中具有相同key值的多行value数据,转换为使用一个key值的多列数据,使每一行数据中,一个key对应多个value。
行转列完成后,在视觉上的效果就是:表中的总行数减少了,但是列数增加了。
concat:连接字符
concat_ws:用分隔符连接字符,参数的列只能是字符类型或者string类型数组
collect_set:将某列数据去重,返回数组
select t1.c_b, CONCAT_WS("|", COLLECT_SET(t1.name)) from ( select CONCAT_WS(",", constellation, blood_type) c_b, name from person_info) t1 group by t1.c_b
列转行:
所谓的列转行是指把表中同一个key值对应的多个value列,转换为多行数据,使每一行数据中,保证一个key只对应一个value。
列转行完成之后,在视觉上的效果就是:表中的列数减少了,但是行数增加了。
explode:将一列中的map、array分为多行
lateral view udtf(expression) tableAlias as columnAlias,和explode、split等合用,用于拆分后的聚合
对原来的行进行侧写
select movie, category_name from movei_info lateral view explode(category) tmpTable as category_name;
窗口函数:
指定窗口,聚合函数应用窗口范围内数据进行计算
聚合函数,要是同时选区列,没有group by无法选择
跟在聚合函数后面,空格分离
只限定聚合函数
函数over():指定分析函数的窗口大小,不加参数即group by生成的组有几个。可以包含distribute by,按照某个字段分区来生成窗口
窗口限定了数据集合,每行数据按照属性进入不同的窗口中去
current row:当前行
n preceding:往前n行
n following:往后n行
unbounded:起点。unbounded preceding表示从前面的起点,unbounded following表示到后面的终点。
函数lag(col,n):往前第n行数据,可以指定窗口后接over函数
函数lead(col,n):往后第n行
函数ntile(n):有序分区中的行分发到指定数据的组中,各个组有编号,从1开始。ntitle返回的是组号。算百分比
rank:排名,有三个函数
rank:允许重复。直接over()因为没指定排序规则所有排行都一样
dense_rank:不允许重复
row_number:给出行号
partition by跟着order by
distributed by跟着sort by
函数:
show functions显示所有函数
desc function 描述函数
desc function extended 描述详细用法
自定义函数:
udf:
udaf:
udtf:
要继承UDF类,实现evaluate函数
使用add jar命令添加jar包或者用create [temporary] function创建函数
九.压缩和存储;
hadoop checknative检查本地可用
要支持snappy,把支持版本的lib/native里的库全都靠背就行
压缩编码:
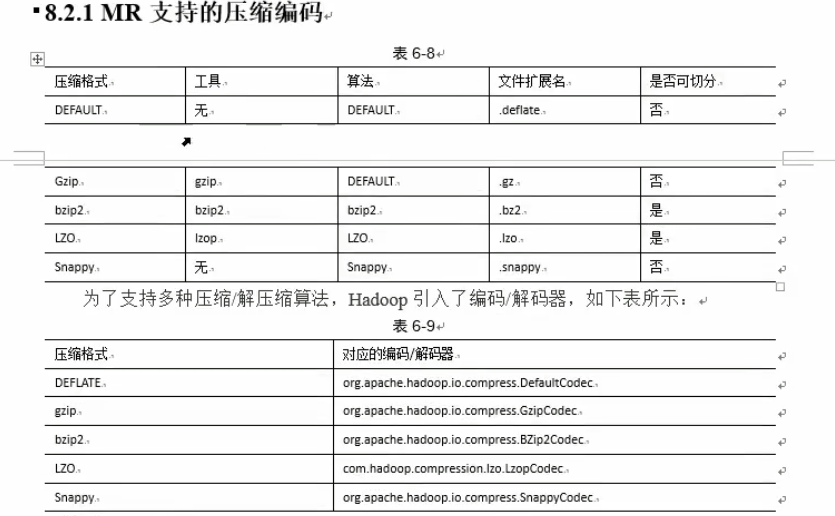

mr中压缩参数配置:
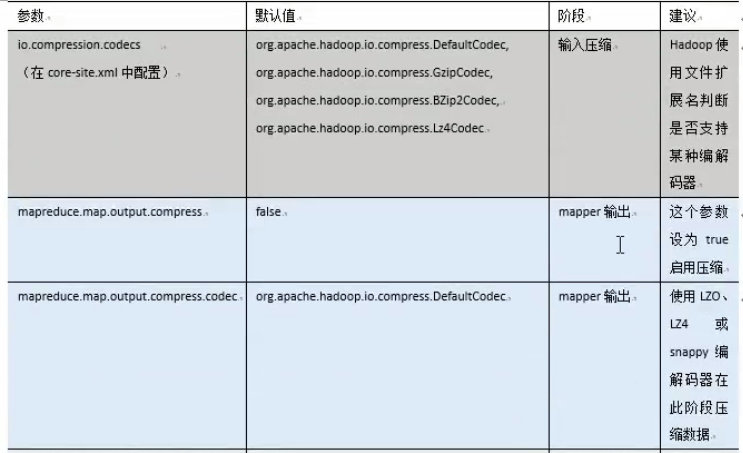
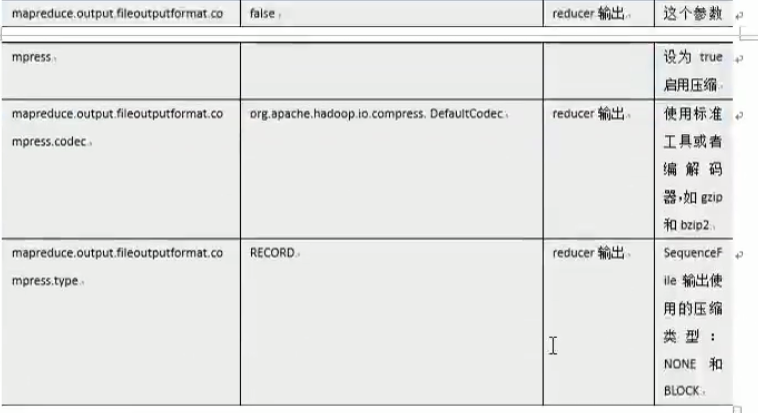
hive中压缩配置:
set hive.exec.compress.intermediate=true;
set mapreduce.map.output.compress=true;
set mapreduce.map.output.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress=true;
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
set mapreduce.output.fileoutputformat.comptess.type=BLOCK;
snappy最优
存储格式:行和列。textfile,sequencefile,orc,parquet
where适用于行,select适用于列
orc和parquet是列,textfile和sequencefile是行
orc存储率和查询效率最佳
创建压缩格式和存储格式可以在建表时指定
十.调优
fetch抓取:一些操作不走map reduce。范围可用hive.fetch.task.conversion控制
本地模式:不用yarn调度,属性hive.exec.mode.local.auto控制开关,hive.exce.mode.local.inputbytes.max控制多少阈值转为yarn,hive.exce.mode.local.auto.input.files.max控制文件阈值
小表join大表:减少内存溢出概率,小表数据先进内存。hive有优化,顺序无所谓
空key处理:过滤掉或者转换为其他值。不然可能产生数据倾斜
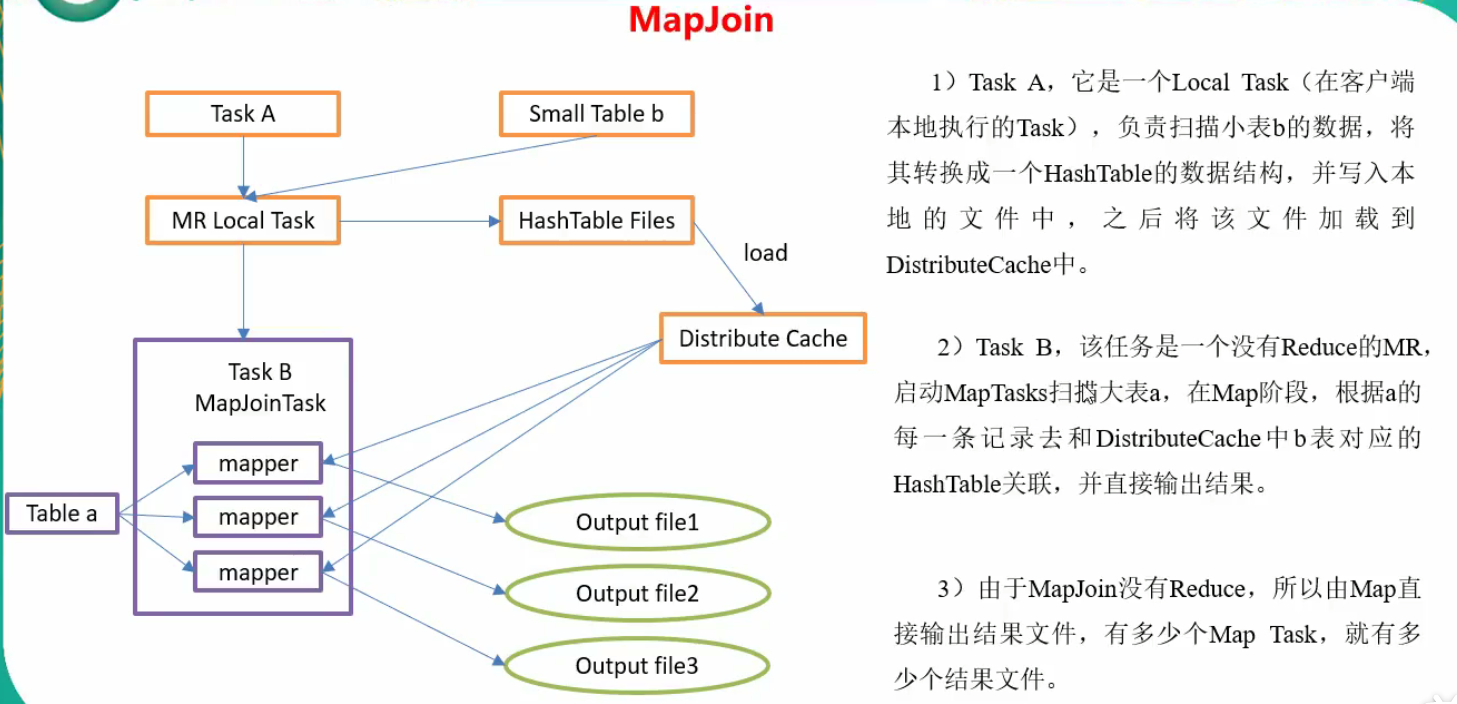
MapJoin:避免reducer阶段处理join。设置hive.auto.convert.join属性,小表阈值用hive.mapjoin.smalltable.filesize设置
GroupBy:在map阶段进行聚合操作。
属性hive.map.aggr判断是否开启;hive.groupby.mapaggr.checkinterval设置聚合数目;hive.groupby.skewindata设置是否在有数据倾斜的时候负载均衡
去重统计:count(distinct)用先group by再count替代。本质是数据交给多个reduce来处理
行列过滤:只拿需要的列;使用外关联时,如果把副表的过滤条件写在where后面,先全表关联再过滤
谓词下推:先走where字句再走select子句
所以先写子查询,where过滤了以后再join
动态分区:插入数据的时候不指定字段进行静态分区,跑MR的时候动态设置分区,用字段代替具体的值
hive.exec.dynamic.partition控制开关
hive.exec.dynamic.partitions设置所有执行MR节点上动态分区最大值
hive.exec.max.dynamic.partitions.pernode设置每个执行MR的节点上动态分区最大值
hive.exec.max.created.files在整个MR job中,最多可以创建多少个HDFS文件
hive.error.on.empty.partition指定空分区生成是否要抛异常
数据倾斜:合理设置map数量。会根据input的大小、数量、文件块大小设定map数目。
一个是小文件太多,一个是条数太多,要尽量设置多个map来处理
小文件合并,hive.input.format指定
大文件要增加map数量,调整切片大小,设置mapreduce.input.fileinputformat.split.maxsize属性,注意联动设置map reduce数量
设置reduce数量
hive.exec.reducers.bytes.per.reducer设置处理的默认数据量
hive.exec.reducers.max设置最大recude数
计算reducer数公式:N=min(参数2,总输入量/参数1)
属性mapreduce.job.reduces也可以设置reduce数,优先级别更高
有几个reduce,生成几个文件
并行执行:多个job并行执行。属性hive.exec.paralled开启,hive.exec.parallel.thread.number控制数量
严格模式:防止执行不好的查询。属性hive.mapred.mode控制
JVM重用:属性mapreduce.job.jvm.numtasks控制jvm数量
推测执行&压缩:属性mapreduce.map.speculative和mapreduce.reduce.speculative控制推测执行开关,推测多久完成
Explain:explain查看sql执行情况
十一.实战
十二.常见错误

 浙公网安备 33010602011771号
浙公网安备 33010602011771号