C++并行编程探讨分析(OpenMP & TBB & Thread Pool)
一、前言
在日常并行编程开发时,我们通常想到的方式有OpenMP,TBB和原生的多线程等。这里先简要各种比较结论如下,然后会在各部分详细论述:
- TBB需要相当可观的重新设计程序,而OpenMP足够简单;
- TBB不太适合并行化已有的实现,它为新设计的并行程序培养一种好的编程风格和更高的抽象层;
- 在论文的实验中,OpenMP稍稍超过TBB;
- TBB只能针对C++, 如果程序基于C或者Fortran就用不上了;
- TBB提供了并行容器,使得结构上的并行更加简单方便;
- 如果您的并行模式主要用于内建类型的有界循环(bounded loop),最好采用 OpenMP;
- OpenMP需要编译器支持,TBB需要下载运行库;
PS:以下多线程库比较图示仅供参考(From https://www.xcelerit.com/computing-benchmarks/software/multi-threading/):

二、OpenMP
2.1 OpenMP简介
OpenMP是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括C、C++和Fortran。OpenMP提供了对并行算法的高层抽象描述,特别适合在多核CPU机器上的并行程序设计。编译器根据程序中添加的pragma指令,自动将程序并行处理,使用OpenMP降低了并行编程的难度和复杂度。当编译器不支持OpenMP时,程序会退化成普通(串行)程序。程序中已有的OpenMP指令不会影响程序的正常编译运行。
2.2 OpenMP执行模式
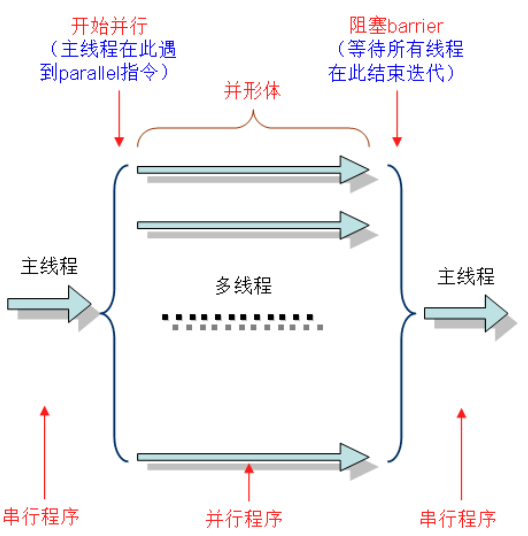
OpenMP采用fork-join的执行模式。开始的时候只存在一个主线程,当需要进行并行计算的时候,派生出若干个分支线程来执行并行任务。当并行代码执行完成之后,分支线程会合,并把控制流程交给单独的主线程。
一个典型的fork-join执行模型的示意图如下:
2.3 OpenMP编程模型
2.3.1 共享内存模型
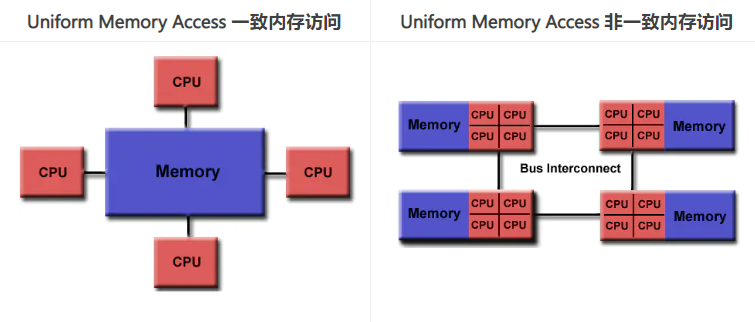
OpenMP是为多处理器或多核共享内存机器设计的。底层架构可以是共享内存UMA或NUMA。
2.3.2 在HPC中使用OpenMP
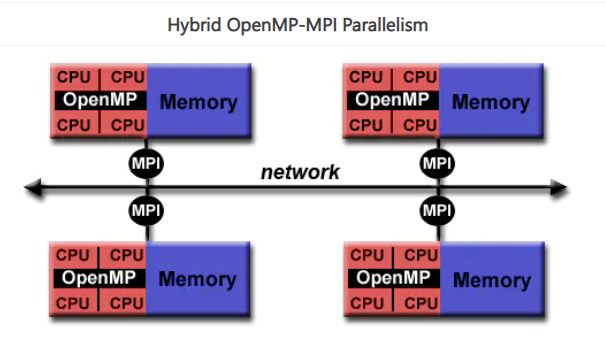
OpenMP本身的并行性仅限于单个节点。对于高性能计算(HPC - Hign Performance Computing)应用程序,OpenMP与MPI相结合以实现分布式内存并行。这通常被称为混合并行编程。
- OpenMP用于每个节点上的计算密集型工作。
- MPI用于实现节点之间的通信和数据共享。
2.4 OpenMP API概述
OpenMP编程模型以线程为基础,通过编译制导指令制导并行化,有三种编程要素可以实现并行化控制,他们分别是编译器指令、API函数集和环境变量。
2.4.1 编译器指令
OpenMP的编译器指令的目标主要有:1)产生一个并行区域;2)划分线程中的代码块;3)在线程之间分配循环迭代;4)序列化代码段;5)同步线程间的工作。编译制导指令以#pragma omp 开始,后边跟具体的功能指令,格式如:
#pragma omp 指令[子句],[子句] …]
常用的功能指令如下:
- parallel :用在一个结构块之前,表示这段代码将被多个线程并行执行;
- for:用于for循环语句之前,表示将循环计算任务分配到多个线程中并行执行,以实现任务分担,必须由编程人员自己保证每次循环之间无数据相关性;
- parallel for :parallel和for指令的结合,也是用在for循环语句之前,表示for循环体的代码将被多个线程并行执行,它同时具有并行域的产生和任务分担两个功能;
- sections :用在可被并行执行的代码段之前,用于实现多个结构块语句的任务分担,可并行执行的代码段各自用section指令标出(注意区分sections和section);
- parallel sections:parallel和sections两个语句的结合,类似于parallel for;
- single:用在并行域内,表示一段只被单个线程执行的代码;
- critical:用在一段代码临界区之前,保证每次只有一个OpenMP线程进入;
- flush:保证各个OpenMP线程的数据影像的一致性;
- barrier:用于并行域内代码的线程同步,线程执行到barrier时要停下等待,直到所有线程都执行到barrier时才继续往下执行;
- atomic:用于指定一个数据操作需要原子性地完成;
- master:用于指定一段代码由主线程执行;
- threadprivate:用于指定一个或多个变量是线程专用,后面会解释线程专有和私有的区别。
相应的OpenMP子句为:
- private:指定一个或多个变量在每个线程中都有它自己的私有副本;
- firstprivate:指定一个或多个变量在每个线程都有它自己的私有副本,并且私有变量要在进入并行域或任务分担域时,继承主线程中的同名变量的值作为初值;
- lastprivate:是用来指定将线程中的一个或多个私有变量的值在并行处理结束后复制到主线程中的同名变量中,负责拷贝的线程是for或sections任务分担中的最后一个线程;
- reduction:用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的归约运算,并将结果返回给主线程同名变量;
- nowait:指出并发线程可以忽略其他制导指令暗含的路障同步;
- num_threads:指定并行域内的线程的数目;
- schedule:指定for任务分担中的任务分配调度类型;
- shared:指定一个或多个变量为多个线程间的共享变量;
- ordered:用来指定for任务分担域内指定代码段需要按照串行循环次序执行;
- copyprivate:配合single指令,将指定线程的专有变量广播到并行域内其他线程的同名变量中;
- copyin n:用来指定一个threadprivate类型的变量需要用主线程同名变量进行初始化;
- default:用来指定并行域内的变量的使用方式,缺省是shared。
2.4.2 API函数集
OpenMP API 包括越来越多的运行时库函数。
2.4.3 环境变量
OpenMP提供了一些环境变量,用来在运行时对并行代码的执行进行控制。这些环境变量可以控制:1)设置线程数;2)指定循环如何划分;3)将线程绑定到处理器;4)启用/禁用嵌套并行,设置最大的嵌套并行级别;5)启用/禁用动态线程;6)设置线程堆栈大小;7)设置线程等待策略。
常用的环境变量:
- OMP_SCHEDULE:用于for循环并行化后的调度,它的值就是循环调度的类型;
- OMP_NUM_THREADS:用于设置并行域中的线程数;
- OMP_DYNAMIC:通过设定变量值,来确定是否允许动态设定并行域内的线程数;
- OMP_NESTED:指出是否可以并行嵌套。
2.5 OpenMP实战
2.5.1 安装OpenMP
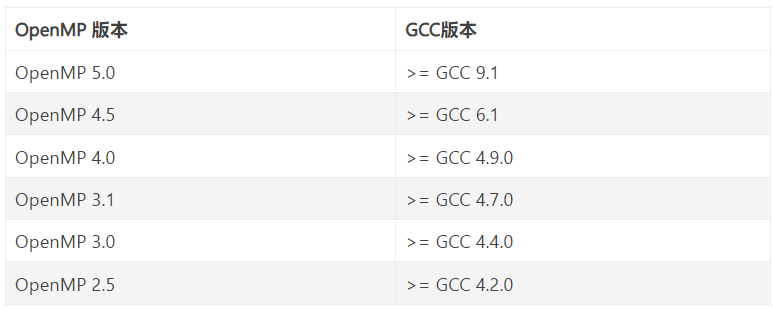
GCC从版本4.2.0开始提供对OpenMP的支持。OpenMP各版本依赖的GCC版本:
Ubuntu下配置gcc环境:
sudo apt install gcc echo |cpp -fopenmp -dM |grep -i open
2.5.2 cmake引入OpenMP
使用cmake中find_package指令查找openmp,格式如下:
find_package(OpenMP REQUIRED)
cmake target_link_libraries链接openmp:
target_link_libraries(${you_executable_name} OpenMP::OpenMP_CXX)
注:openmp 提供的omp_get_wtime() 才记录的运行时的真实时间。
2.5.3 C++使用OpenMP示例
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char* argv[])
{
int nthreads, tid;
// Begin of parallel region
#pragma omp parallel private(nthreads, tid)
{
// Getting thread number
tid = omp_get_thread_num();
printf("Welcome to GFG from thread = %d\n",
tid);
if (tid == 0) {
// Only master thread does this
nthreads = omp_get_num_threads();
printf("Number of threads = %d\n",
nthreads);
}
}
}
输出:

更多示例请参考末尾的文档(非常详细,不占用此处篇幅~)
2.5.4 C++使用OpenMP并行处理vector崩溃案例分析
当我在使用OpenMP并行处理vector时,出现了segmentation fault或者double free or corruption (fasttop) aborted (core dumped)等错误。基本可以确定是内存问题。
经过分析:在使用openmp之前,将一些数据逐个push到向量元素中。然而,使用openmp,将有几个线程并行运行for循环中的代码。当多个线程同时将数据推回vector元素时,并且没有代码来确保一个线程不会在另一个线程完成之前开始推,就会发生问题。这就是代码崩溃的原因。
为了解决这个问题,有两种方法:
- 方法1: 你可以使用局部buff向量。每个线程首先将数据推入其私有的本地缓冲区向量,然后您可以将这些缓冲区向量连接到一个单独的向量中。需要注意,此方法不能保持向量元素中数据元素的原始顺序。如果希望这样做,可以计算数据元素的每个期望索引,并将数据直接分配到正确的位置。
std::vector<int> vec;
#pragma omp parallel
{
std::vector<int> vec_private;
#pragma omp for nowait //fill vec_private in parallel
for(int i=0; i<100; i++) {
vec_private.push_back(i);
}
#pragma omp critical
vec.insert(vec.end(), vec_private.begin(), vec_private.end());
}
- 方法2:OpenMP 4.0版本即允许用户自定义缩略语,使用#pragma omp declare reduction。 上面的代码可以简化为:
#pragma omp declare reduction (merge : std::vector<int> : omp_out.insert(omp_out.end(), omp_in.begin(), omp_in.end())) std::vector<int> vec; #pragma omp parallel for reduction(merge: vec) for(int i=0; i<100; i++) vec.push_back(i);
如果顺序很重要,那么可以这样做:
std::vector<int> vec;
#pragma omp parallel
{
std::vector<int> vec_private;
#pragma omp for nowait schedule(static)
for(int i=0; i<N; i++) {
vec_private.push_back(i);
}
#pragma omp for schedule(static) ordered
for(int i=0; i<omp_get_num_threads(); i++) {
#pragma omp ordered
vec.insert(vec.end(), vec_private.begin(), vec_private.end());
}
}
思路来源于:https://stackoverflow.com/questions/18669296/c-openmp-parallel-for-loop-alternatives-to-stdvector 和 https://stackoverflow.com/questions/19620081/pragma-omp-parallel-for-schedule-crashes-my-program
三、TBB
3.1 TBB简介
TBB(Thread Building Blocks)是英特尔发布的一个库,全称为 Threading Building Blocks。TBB 获得过 17 届 Jolt Productivity Awards,是一套 C++ 模板库,和直接利用 OS API 写程序的 raw thread 比,在并行编程方面提供了适当的抽象,当然还包括更多其他内容,比如 task 概念,常用算法的成熟实现,自动负载均衡特 性还有不绑定 CPU 数量的灵活的可扩展性等等。在多核的平台上开发并行化的程序,必须合理地利用系统的资源 - 如与内核数目相匹配的线程,内存的合理访问次序,最大化重用缓存。有时候用户使用(系统)低级的应用接口创建、管理线程,很难保证是否程序处于最佳状态。 而 TBB 很好地解决了上述问题:
1)TBB提供C++模版库,用户不必关注线程,而专注任务本身。
2)抽象层仅需很少的接口代码,性能上毫不逊色。
3)灵活地适合不同的多核平台。
4)线程库的接口适合于跨平台的移植(Linux, Windows, Mac)
OneTBB源码: https://github.com/oneapi-src/oneTBB
OneTBB开发手册: https://oneapi-src.github.io/oneTBB/
3.2 TBB主要模块介绍
TBB包含了 Algorithms、Containers、Memory Allocation、Synchronization、Timing、Task Scheduling这六个模块。TBB的结构:
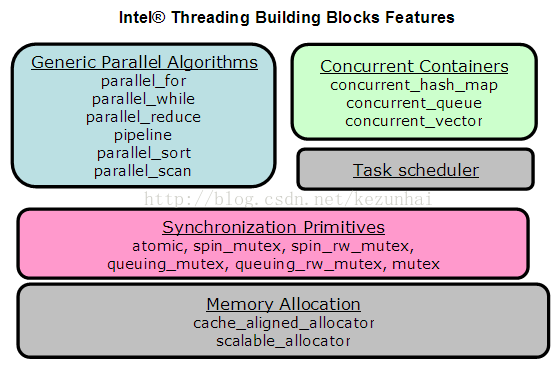
通用的并行算法 :
- 循环的并行:
- parallel_for:它是在一个值域执行并行迭代操作的模板函数。parallel_for(range, body, partitioner)提供了并行迭代的泛型形式。它表示在区域的每个值,并行执行body。partitioner选项指定了分割策略。Range类型必须符合Range概念模型。
-
- parallel_reduce:parallel_reduce模板在一个区域迭代,将由各个任务计算得到的部分结果合并,得到最终结果。parallel_reduce对区域(range)类型的要求与parallel_for一样。body类型需要分割构造函数以及一个join方法。body的分割构造函数拷贝运行循环体需要的只读数据,并分配并归操作中初始化并归变量的标志元素。join方法会组合并归操作中各任务的结果。parallel_reduce使用分割构造函数来为每个线程生成一个或多个body的拷贝。当它拷贝body的时候,也许body的operator()或者join()正在并发运行。要确保这种并发运行下的安全。
- 更多 ......
3.3 TBB安装与实践
- TBB安装
源码安装(推荐):
# Do our experiments in /tmp cd /tmp # Clone oneTBB repository git clone https://github.com/oneapi-src/oneTBB.git cd oneTBB # Create binary directory for out-of-source build mkdir build && cd build # Configure: customize CMAKE_INSTALL_PREFIX and disable TBB_TEST to avoid tests build cmake -DCMAKE_INSTALL_PREFIX=/tmp/my_installed_onetbb -DTBB_TEST=OFF .. # Build cmake --build . # Install cmake --install . # Well done! Your installed oneTBB is in /tmp/my_installed_onetbb
后续可以直接作为依赖包使用,很灵活。
参考:
OpenMP Application Programming Interface Examples
C ++ 17并行算法vs tbb并行vs openmp性能
tbb::parallel_for+tbb::concurrent_vector速度对比测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号