深度学习模型热更新及libtorch显存管理
一、深度学习模型热更新
在工程中,完成一个模型的核心目标就是上线来跑,而且版本需要做迭代,或者是针对一些实时的情况,需要对模型或者模型内的参数进行热更新。然而,一旦服务上线了,就不能随意停止或者是重启服务,服务终止所带来的损失在互联网时代看来是非常难以支撑的,所以要保证尽可能小的损失的话,就需要有特定的热更新机制进行快速切换。
本文旨在探讨可用的模型热更新方案。
所谓的热更新,来看一个百度的解释:
热更新就是动态下发代码,它可以使开发者在不发布新版本的情况下,修复 BUG 和发布功能。
简单地说,就是不需要停止服务,也能更新到最新版本,对于算法而言,就是更新这个模型不需要重启服务,不可影响服务的正常运行,拆解开来,其实有这几个细节的需求:
- 原子化。简单地说就是一件事,要么做要么不做,中间不可以有插入其他任务的机会。这个是高并发所提出的要求,一般而言我们的模型会同时被多个线程请求计算,此时我们在更新模型的时候,如果不能保证原子化,那么进行预测的进程就可能读到被改到一半的模型从而导致计算错误。
- 模型加载更新过程服务不可终止。加载模型本身是一个非常耗时的任务,如果和常规的推理任务放在一个进程里,必然会导致大量的请求被堵塞。
- 新模型并非100%成功,失败的时候需要一定的回滚保护机制。
为了这个热更新的需求,double buffer机制应运而生。
double buffer
中文叫做双备份机制,这个机制的原理并不复杂。就是对于要更新的部分,如模型、配置,在运行过程中用两个变量来保存,一个变量用于正常运行,给预测的请求用,另一个则用来更新模型,模型更新完以后,把带着新模型的变量用来进行预测。
深度学习模型部署方案
常用的深度学习部署方案如下:
- pytorch模型作为一种服务进行部署(比如使用Flask框架搭建,或者使用grpc微服务等);
- pytorch模型导出为torchscript,然后在C++代码中使用libtorch调用导出的模型;
- pytorch模型导出onnx,tensorrt,tensorflow等其他方式;
用flask框架搭建服务进行部署,为了保证模型能够热更新,有的会启动两个相同的服务,使用nginx中的backup功能,需要更换模型时,只暂停一个服务进行更换,另一个服务继续工作。使用tensorflow部署的模型,可以使用tensorflow-serving,自带模型热更新功能。而libtorch导出的模型,如果要进行热更新,会面临一个问题,如何在加载新模型前,卸载GPU上的旧模型,否则GPU显存容易爆掉。因为在有些场景下,double buffer以及backup等方案不适用,就需要考虑下面libtorch显存的管理了。
二、libtorch显存管理
在使用libtorch进行部署时,会面临显存不够用的情况。因此需要对显存的利用进行管理,对此研究libtorch的api,尝试进行显存管理。libtorch运行程序时,显存占用可以分为3块:模型参数占用显存、输入输出tensor占用显存、模型forword过程临时变量占用显存。
使用cudaFree(tensor.data_ptr())可以释放掉tensor所占用的显存,也可以使用该函数释放掉模型参数所占用的显存。使用CUDACachingAllocator::emptyCache函数可以释放掉模型在forword过程中的一些显存。
测试代码:
#include <torch/script.h>
#include <torch/torch.h>
#include <c10/cuda/CUDAStream.h>
#include <ATen/cuda/CUDAEvent.h>
#include <iostream>
#include <memory>
#include <string>
#include <cuda_runtime_api.h>
using namespace std;
static void print_cuda_use( )
{
size_t free_byte;
size_t total_byte;
cudaError_t cuda_status = cudaMemGetInfo(&free_byte, &total_byte);
if (cudaSuccess != cuda_status) {
printf("Error: cudaMemGetInfo fails, %s \n", cudaGetErrorString(cuda_status));
exit(1);
}
double free_db = (double)free_byte;
double total_db = (double)total_byte;
double used_db_1 = (total_db - free_db) / 1024.0 / 1024.0;
std::cout << "Now used GPU memory " << used_db_1 << " MB\n";
}
int main() {
string path = "d_in_out.pt";
//设置不需要存储梯度信息
at::NoGradGuard nograd;
int gpu_id = 0;
//加载模型
torch::jit::Module model = torch::jit::load(path);
model.to(at::kCUDA);
model.eval();//设置评价模式
std::cout << "加载模型后的显存占用\n";
print_cuda_use();
//构建双输入数据
//对于单输入模型只需要push_back一次
at::Tensor x1_tensor = torch::ones({ 1,3,512,512 }).to(at::kCUDA);
at::Tensor x2_tensor = torch::ones({ 1,3,512,512 }).to(at::kCUDA);
at::Tensor result1,result2;
std::cout << "\n初始化tensor的显存占用\n";
print_cuda_use();
std::cout << "\n循环运行5次\n";
for (int i = 0;i < 5;i++) {
//result=model.forward({ x1_tensor,x2_tensor }).toTensor();//one out
auto out = model.forward({ x1_tensor,x2_tensor });
auto tpl = out.toTuple();//out.toTensorList();
result1 = tpl->elements()[0].toTensor();
result2 = tpl->elements()[1].toTensor();
print_cuda_use();
}
std::cout << "\n释放tensor所占用的显存(帮助不大)\n";
cudaFree(x1_tensor.data_ptr());
cudaFree(x1_tensor.data_ptr());
cudaFree(result1.data_ptr());
cudaFree(result2.data_ptr());
print_cuda_use();
std::cout << "\nCUDACachingAllocator::emptyCache (有点效果)\n";
c10::cuda::CUDACachingAllocator::emptyCache();
print_cuda_use();
std::cout << "\n释放模型参数占用的显存(无意义)\n";
for (auto p : model.parameters())
cudaFree(p.data_ptr());//接下来不能使用cuda,导致model.to(at::kCUDA);报错
print_cuda_use();
//torch::jit::Module::Module::freeze(model);
std::cout << "\n调用模型的析构函数(无效)\n";
model.~Module();//对显存变化没有实际帮助
print_cuda_use();
std::cout << "\n重置cuda状态(无效)\n";
c10::cuda::CUDACachingAllocator::init(gpu_id);
c10::cuda::CUDACachingAllocator::resetAccumulatedStats(gpu_id);//对显存变化没有实际帮助
c10::cuda::CUDACachingAllocator::resetPeakStats(gpu_id);
print_cuda_use();
std::cout << "\ncudaDeviceReset(有效,会导致后续模型无法使用cuda)\n";
//需要配置cuda
cudaDeviceReset();//完全释放GPU资源 接下来不能使用cuda,导致model.to(at::kCUDA);报错 除非能重新初始化libtorch的cuda环境
print_cuda_use();
torch::cuda::synchronize();
model = torch::jit::load(path);
model.to(at::kCUDA);
print_cuda_use();
return 0;
}
运行结果:
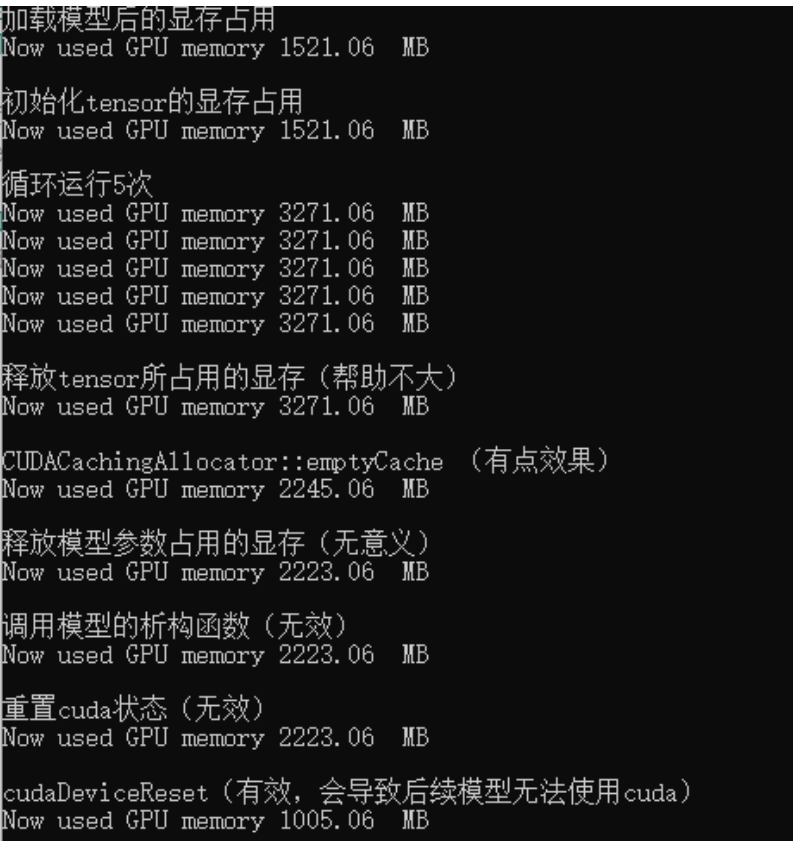
其实最简单直接的方法就是将模型移动到CPU上,然后清除GPU的缓存,再update新的模型到GPU上:
m_model.to(at::kCPU); c10::cuda::CUDACachingAllocator::emptyCache(); m_model = torch::jit::load(model_file);
对于算法模型运行后显存不释放的情况,上面清除cuda缓存是一种方法,另外一种方法就是可以在子线程中进行模型的推理,任务结束,达到显存释放的目的。
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号