【计算机视觉】如何解决目标检测中的漏检问题
一、问题描述
目标检测算法的漏检,一直是极具挑战性的问题。谈到漏检(low recall),离不开较高的检测精度(high precision)的要求,只有在precision得到保证条件下讨论recall才有意义。下面的讨论主要围绕precision可以接受的条件下,如何进一步提高recall,也就是减少漏检。
二、可行方案
解决当前基于深度学习的目标检测器的问题,系统地来看,应该分别从数据集、网络架构、损失函数、后处理,以及学习算法等方面考虑。下面对一些常见的解决办法做下总结,并着重讲讲学习算法方面可行的方案(部分节选自知乎高赞回答)。
- 数据集平衡扩增:干净且均衡的数据,从来都是解决问题最有力的办法。通常数据集中的各个类别的样本呈“长尾”分布,直接用来训练检测器容易导致对样本少的类别出现漏检。这时可以考虑对样本少的类别,进行样本扩增。扩增过程最好考虑新增样本的diversity以及context,比如在前文小目标检测专题中我们提到过的小目标检测中的数据扩增方法:

- 改进网络结构:神经网络结构设计,决定了从数据集到检测结果之间映射的假设空间。正如
有人提到的Anchor的设计,可以很好地引入样本少的类别的bbox分布先验,使生成的region proposals在这些类别有较高的召回(Recall)。除此之外,由于漏检也很大程度上来自于目标尺度的巨大变化,比如自动驾驶场景中,同是Car类别的bbox样本在远处只占据极小部分pixels,而在近处甚至占据近半幅图像。经典的做法包括image/featur pyramid 如FPN等,以及Multi-scale Training/Testing策略,但最近 @Naiyan Wang
等人提出的Trident Network提出使用不同ratio的dilated conv分别匹配不同的感受野,达到检测不同尺度目标的目的,效果也很惊艳,应该能够很好地解决尺度变化带来的漏检问题。参考:TridentNet:处理目标检测中尺度变化新思路
- 改进损失函数:前面提到的Class-balanced Focal Loss是个很好的尝试方法。除此之外,Online Hard Example Ming(OHEM)策略也可以尝试(实现细节可以去看下OHEM的论文:https://openaccess.thecvf.com/content_cvpr_2016/papers/Shrivastava_Training_Region-Based_Object_CVPR_2016_paper.pdf)。由于易漏检样本通常在训练过程中较容易产生较大的loss,那么在每次训练迭代中,将loss值较大的的样本筛选出来加入训练集进入下一次迭代,使得检测模型更多关注易漏检样本。推荐文章:focal loss和OHEM(on-line hard example mining)如何应用到faster RCNN中
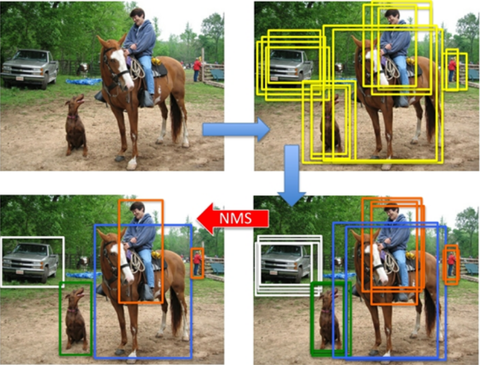
- 后处理:在崇尚end-to-end检测模型的今天,一般不提倡使用过多后处理设计,但实际工程应用中后处理经常起到至关重要的作用。前面已有提到改进NMS后处理算法,在目标遮挡严重的场景中效果非常明显。其中关键是如何区分目标的duplicated bbox及其周围目标的occluded bbox。解决的好得话,能够显著改善漏检问题。针对NMS目前已有许多改进方案,在此不做详述,可以参考:目标检测之非极大值抑制(NMS)各种变体
- 其它学习算法:除了目前主流的监督学习模型,也可以考虑其它的学习算法,比如我最近比较感兴趣的lifelong/continual learning。针对目标检测漏检问题,可以考虑将不同类别的检测问题,划分为不同难度的task分别训练检测器,利用lifelong learning实现一个模型解决不同类别目标的检测。不同于multi-task learning,lifelong learning无需要求在每个task的训练过程中获取全部task的数据(所有类别的样本)。以经典的Elastic Weights Consolidation (EWC)算法为例,可以根据各类样本分布,划分不同的子数据集得到不同的detection tasks,训练完一个task后,在新的task的训练过程中,利用EWC regularizer调整weights的优化方向,使模型能够学习当前detection task的同时,不遗忘已经学习过的detection tasks。这样最终得到的模型能够处理所有task中的所有类别的检测,对漏检问题应该有一定的改善作用,但是否会削弱容易检测的类别的性能,需要实验验证。
补充说明:
目标检测回归损失函数简介:SmoothL1/IoU/GIoU/DIoU/CIoU Loss
参考:
朱颜辞镜花辞树,敏捷开发靠得住!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号