【计算机视觉】FFC平场校正算法剖析
一、前言
实际相机采集图像,其图像中各像素的值往往会有较大差异,一般是由以下几个原因造成:
(1)光照不均匀
(2)镜片中心和镜片边缘的响应不一致
(3)成像器件各像元响应不一致(光敏元自身的非均匀性工艺)
(4)固定的图像背景噪声等等.
所谓的平场校正就是校正传感器芯片上这些不一致性.
通常对于单个像元,其响应灰度值与入射光强度程线性关系.但由于上面所讲的原因,传感器上不同像元对入射光的响应是不同的直线,他们起点不同,斜率也会有差别.平场校正就是通过改变每个像元响应直线的斜率(即信号增益Gain)和偏移(即信号偏移量Offset),使所有像素点的响应 直线相同.
最常用的平场校正方法是”两点校正法”,该方法的前提就是探测器像元为线性响应.首先相机对暗场进行一次曝光,得到每个像元的偏移(Offset);接下来对均匀光照条件下的灰度均匀物体进行一次成像,得到均匀场图像,最好能够使图像中所有的点都接近最大的灰度值;最后用均匀光场图像减去暗场图像,用相对标定的方法对图像增益(Gain)进行校正。
主要校正介绍:
1)Fixed Pattern Noise (FPN): 暗场,固定图像噪声校正
2)Photo Response Non Uniformity (PRNU):明场,图像非均匀性响应校正
3)Lens and light source non-uniformity:明场,镜头与光源非均匀性校正
* FPN校正时,像素值必须在1DN与127DN(可理解为灰度值)之间;PRNU校正时,像素值必须在128DN与254DN之间。校正前最好首先使用“gl”命令确认DN值是否满足要求。
二、校正方法公式
①相机线性响应过程中使用 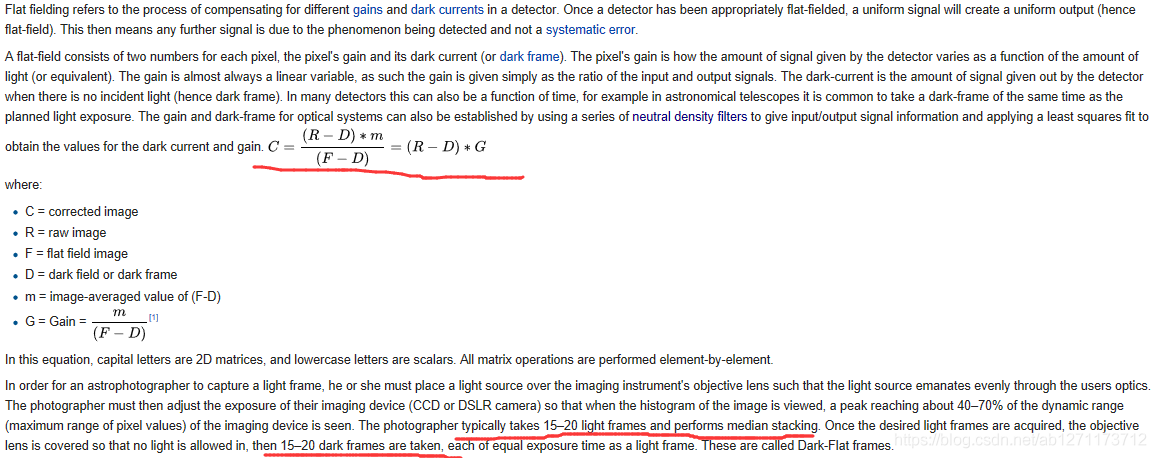
②暗场校正(FPN)
a)首先要获取系统的暗场像素值(取平均值);获得该值的目的在于得到CCD在特定的环境下(光亮、温度、时间相同)产生的暗像素值的大小,用一下公式表示
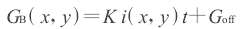
Goff是图像的偏置量,一般为一常量,i(x,y)为探测器在相应工作条件下的暗电流,以像元考虑的话,单位可以用电子数/秒 像元来表示;t为获取一幅图像的时间;K为转换关系,相应的单位可以用图像灰度/电子数表示
明场校正(PRNU)
b)通过对均匀光场的成像以获得一幅用于平场校正的参考图像GR(x,y),该图像原则上要求用均匀光场X0进行照明且时间与暗本底图像GB(x,y)相同,并且照明光场光照水平尽量接近饱和照明条件,参考图像GR(x,y)可表示为

C)被用于校正的图像G(x,y)表示为
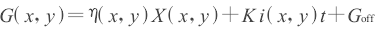
当系统是线性响应的时候(η(x,y)是一常量),由式(4)减去式(3)

这样就获得了经过平场校正后的图像,式(5)表示的是一幅相对值图像.由于X0是均匀的,在式(5)中乘以一个合理的数据(可根据经验)就可以得到一幅灰度适中的图像,并不会对图像处理产生不良影响.
该类平场校正方法一般运用于线阵CCD相机,对于其他的相机,有其他的处理方法;该算法有一定的局限性,受环境温度、光线的影响比较大,因此要求在工作环境变换不大的情况下才能最大的发挥出算法的效果,一旦工作环境发生较大的变化时,需要重新做平场校正;
③面阵CCD非均匀性校正计算方式
根据面阵CCD的响应特性,校正采用单点、亮点和多点校正方法,单点校正法只是当积分球在一种辐照度输出时将不同像元输出信号矫正成平均信号,具有一定局限性,当面阵CCD响应度为线性时采用两点校正法;若面阵CCD响应为非线性时采用多点定标分段校正,将定标区间分成多段,在每个段内将面阵CCD的非线性响应当作线性响应处理,但随定标点越多,计算的数据量越大。
两点校正法
面阵CCD每个像元灵敏度响应及暗电流都不可能完全相同,为和定标时面阵CCD响应度表达式区分,这里把每个像元的灵敏度响应及暗电流描述成增益和偏移量,可建立模型:
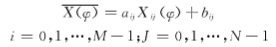
?(?)表示在辐照度为?时面阵CCD所有像元的平均灰度值,?(?)??表示未经校正的图像第i行第j列像元的实际输出灰度值,???为对应像素位置的像元增益,???为对应像素位置的像元偏移量,M,N分别为图像行列。两点校正方法需要选取两个定标点,由此可推出CCD各像元的增益和偏移量,
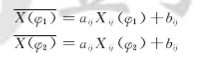
由此可推出CCD各像元的增益和偏移量,
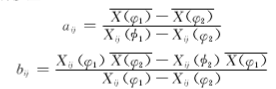
4.均匀性评估
将平场校正前后该处的光强分别读出,比较平场校正前后图像的均匀性。图像的均匀性以图像的灰度值的峰谷值(dpv归一化后的)和标准差S表示。
三、实际应用
3.1 Flat-field correction(ImageJ Version)Proper correction
Use this technique on brightfield images. You can correct uneven illumination or dirt/dust on lenses by acquiring a “flat-field” reference image with the same intensity illumination as the experiment. The flat field image should be as close as possible to a field of view of the cover slip without any cells/debris. This is often not possible with the experimental cover slip, so a fresh cover slip may be used with approximately the same amount of buffer as the experiment.

- Open both the experimental image and the flat-field image.
- Click the Select all button on the flat-field image and measure the average intensity. This value, the k1 value, will appear in the results window.
- Use the Image Calculator plus plugin (Analyze › Tools › Calculator plus).
- i1 = experimental image; i2 = flat-field image; k1 = mean flat-field intensity; k2 = 0. Select the “Divide” operation.
This can also be done using the Process › Image Calculatorfunction with the 32-bit Result option checked. Then adjust the brightness and contrast and convert the image to 8-bit.
Pseudo-correction

Sometimes it is not possible to obtain a flat-field reference image. It is still possible to correct for illumination intensity, though not small defects like dust, by making a “pseudo-flat field” image by performing a large-kernel filter on the image to be corrected. For those working with DIC images, this is particularly useful because they generally have an intrinsic, and distracting, gradient in illumination.
This can be accomplished simply by subtracting the Gaussian-blurred image version of the image.
This can also be used with stacks for brightfield time-courses that vary in intensity with time. Doing this with stacks can be time consuming.
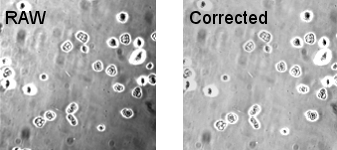
The first RAW image (top) is pseudo-flat field corrected. Here the pseudo-flat field corrects for the uneven illumination, but does not correct for the dust specks. Look at this compared to the result of a proper flat-field correction above.
BigStitcher › Flatfield Correction

3.2 Flat Field Correction (FFC) in cameras for Machine Vision
平场校正是一个广泛使用的术语,因为许多工业和机器视觉相机都有某种形式的校正算法来克服图像伪影。 然而,并不是所有形式的平场校正都是相同的,随着传感器上像素数量的增加,实现平场的方法的变化只会增加。 在本文中,我们将阐明现有的纠正机制。
术语平场校正(FFC)经常用于与灵敏度和暗电流的像素到像素变化有关的校正,例如,照片响应不均匀性(PRNU)和暗信号不均匀性(DSNU)。 然而,由照明和照明光学引起的伪影校正也被认为是FFC相关的。 在所有情况下,你想要达到的是一个平坦的相机图像,例如平坦的场。
然而,像素与像素之间的变化,如PRNU和DSNU,和光路中的扭曲有一个重要的区别。 前者通常是高频校正,后者一般是低频校正。
对于低像素分辨率的相机来说,这种差异不是特别重要。 这些相机能够进行像素到像素的校准(基于像素的FFC),可以纠正低频和高频缺陷。 然而,高像素分辨率的相机不能总是在像素对像素的基础上进行校正,因为它需要太多的存储容量来存储一个完整的校正图像在相机中。 这些相机通常有一个列明智的PRNU和DSNU校正,而不是像素到像素校正(基于列FFC)。 柱式校正是一种高频校正,不能校正低频缺陷。
为了纠正高分辨率相机中的低频缺陷,采用了一种与柱校正完全无关的单独算法。 该算法将传感器划分为由一堆像素组成的更小的正方形段。 这些片段将被视为单个像素。 因此,这些片段通常被称为超级像素。 为每个超级像素确定一个平均值,并拟合一个模型来描述所有超级像素的低频值(模型的质量和选择通常是相机制造商的专利)。 然后,该模型用于计算每个像素的校正因子,以便对低频变化进行校正。 这种FFC的变体我们称之为低频FFC.

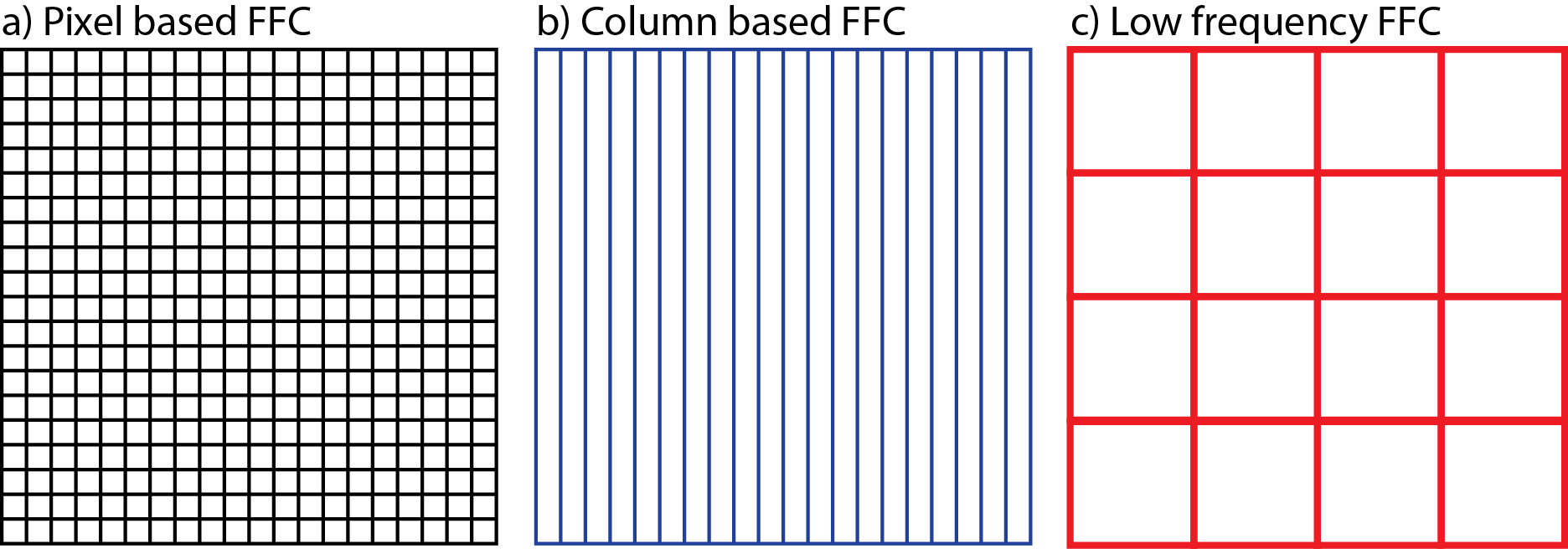
图1所示。各种平场校正机制之间差异的图示。对于基于像素的FFC (a),为每个像素存储一个校正值。对于基于列的FFC (b),每个列存储一个校正值。对于低频FFC (c),每个超像素存储一个值。
根据使用的图像传感器及其分辨率,不同类型的FFC被应用于最佳的图像质量。FFC的质量取决于相机制造商如何将校正算法应用到相机中。这意味着一个相机制造商的FFC与另一个相机的FFC是不一样的。
四、延伸拓展
处理图像光照不均匀问题或者光照矫正的常用方法有哪些?(比如,均值白平衡法,gamma矫正等等,参考:https://github.com/18150167970/image_process_tool/blob/master/lighting_enhancement.py)
import cv2
import numpy as np
import math
def mean_white_balance(img):
"""
第一种简单的求均值白平衡法
:param img: cv2.imread读取的图片数据
:return: 返回的白平衡结果图片数据
"""
# 读取图像
b, g, r = cv2.split(img)
r_avg = cv2.mean(r)[0]
g_avg = cv2.mean(g)[0]
b_avg = cv2.mean(b)[0]
# 求各个通道所占增益
k = (r_avg + g_avg + b_avg) / 3
kr = k / r_avg
kg = k / g_avg
kb = k / b_avg
r = cv2.addWeighted(src1=r, alpha=kr, src2=0, beta=0, gamma=0)
g = cv2.addWeighted(src1=g, alpha=kg, src2=0, beta=0, gamma=0)
b = cv2.addWeighted(src1=b, alpha=kb, src2=0, beta=0, gamma=0)
balance_img = cv2.merge([b, g, r])
return balance_img
def perfect_reflective_white_balance(img_input):
"""
完美反射白平衡
STEP 1:计算每个像素的R\G\B之和
STEP 2:按R+G+B值的大小计算出其前Ratio%的值作为参考点的的阈值T
STEP 3:对图像中的每个点,计算其中R+G+B值大于T的所有点的R\G\B分量的累积和的平均值
STEP 4:对每个点将像素量化到[0,255]之间
依赖ratio值选取而且对亮度最大区域不是白色的图像效果不佳。
:param img: cv2.imread读取的图片数据
:return: 返回的白平衡结果图片数据
"""
img = img_input.copy()
b, g, r = cv2.split(img)
m, n, t = img.shape
sum_ = np.zeros(b.shape)
# for i in range(m):
# for j in range(n):
# sum_[i][j] = int(b[i][j]) + int(g[i][j]) + int(r[i][j])
sum_ = b.astype(np.int32) + g.astype(np.int32) + r.astype(np.int32)
hists, bins = np.histogram(sum_.flatten(), 766, [0, 766])
Y = 765
num, key = 0, 0
ratio = 0.01
while Y >= 0:
num += hists[Y]
if num > m * n * ratio / 100:
key = Y
break
Y = Y - 1
# sum_b, sum_g, sum_r = 0, 0, 0
# for i in range(m):
# for j in range(n):
# if sum_[i][j] >= key:
# sum_b += b[i][j]
# sum_g += g[i][j]
# sum_r += r[i][j]
# time = time + 1
sum_b = b[sum_ >= key].sum()
sum_g = g[sum_ >= key].sum()
sum_r = r[sum_ >= key].sum()
time = (sum_ >= key).sum()
avg_b = sum_b / time
avg_g = sum_g / time
avg_r = sum_r / time
maxvalue = float(np.max(img))
# maxvalue = 255
# for i in range(m):
# for j in range(n):
# b = int(img[i][j][0]) * maxvalue / int(avg_b)
# g = int(img[i][j][1]) * maxvalue / int(avg_g)
# r = int(img[i][j][2]) * maxvalue / int(avg_r)
# if b > 255:
# b = 255
# if b < 0:
# b = 0
# if g > 255:
# g = 255
# if g < 0:
# g = 0
# if r > 255:
# r = 255
# if r < 0:
# r = 0
# img[i][j][0] = b
# img[i][j][1] = g
# img[i][j][2] = r
b = img[:, :, 0].astype(np.int32) * maxvalue / int(avg_b)
g = img[:, :, 1].astype(np.int32) * maxvalue / int(avg_g)
r = img[:, :, 2].astype(np.int32) * maxvalue / int(avg_r)
b[b > 255] = 255
b[b < 0] = 0
g[g > 255] = 255
g[g < 0] = 0
r[r > 255] = 255
r[r < 0] = 0
img[:, :, 0] = b
img[:, :, 1] = g
img[:, :, 2] = r
return img
def gray_world_assumes_white_balance(img):
"""
灰度世界假设
:param img: cv2.imread读取的图片数据
:return: 返回的白平衡结果图片数据
"""
B, G, R = np.double(img[:, :, 0]), np.double(img[:, :, 1]), np.double(img[:, :, 2])
B_ave, G_ave, R_ave = np.mean(B), np.mean(G), np.mean(R)
K = (B_ave + G_ave + R_ave) / 3
Kb, Kg, Kr = K / B_ave, K / G_ave, K / R_ave
Ba = (B * Kb)
Ga = (G * Kg)
Ra = (R * Kr)
# for i in range(len(Ba)):
# for j in range(len(Ba[0])):
# Ba[i][j] = 255 if Ba[i][j] > 255 else Ba[i][j]
# Ga[i][j] = 255 if Ga[i][j] > 255 else Ga[i][j]
# Ra[i][j] = 255 if Ra[i][j] > 255 else Ra[i][j]
Ba[Ba > 255] = 255
Ga[Ga > 255] = 255
Ra[Ra > 255] = 255
# print(np.mean(Ba), np.mean(Ga), np.mean(Ra))
dst_img = np.uint8(np.zeros_like(img))
dst_img[:, :, 0] = Ba
dst_img[:, :, 1] = Ga
dst_img[:, :, 2] = Ra
return dst_img
def color_correction_of_image_analysis(img):
"""
基于图像分析的偏色检测及颜色校正方法
:param img: cv2.imread读取的图片数据
:return: 返回的白平衡结果图片数据
"""
def detection(img):
"""计算偏色值"""
img_lab = cv2.cvtColor(img, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(img_lab)
d_a, d_b, M_a, M_b = 0, 0, 0, 0
for i in range(m):
for j in range(n):
d_a = d_a + a[i][j]
d_b = d_b + b[i][j]
d_a, d_b = (d_a / (m * n)) - 128, (d_b / (n * m)) - 128
D = np.sqrt((np.square(d_a) + np.square(d_b)))
for i in range(m):
for j in range(n):
M_a = np.abs(a[i][j] - d_a - 128) + M_a
M_b = np.abs(b[i][j] - d_b - 128) + M_b
M_a, M_b = M_a / (m * n), M_b / (m * n)
M = np.sqrt((np.square(M_a) + np.square(M_b)))
k = D / M
# print('偏色值:%f' % k)
return
b, g, r = cv2.split(img)
# print(img.shape)
m, n = b.shape
# detection(img)
I_r_2 = np.zeros(r.shape)
I_b_2 = np.zeros(b.shape)
# sum_I_r_2, sum_I_r, sum_I_b_2, sum_I_b, sum_I_g = 0, 0, 0, 0, 0
# max_I_r_2, max_I_r, max_I_b_2, max_I_b, max_I_g = int(r[0][0] ** 2), int(r[0][0]), int(b[0][0] ** 2), int(
# b[0][0]), int(g[0][0])
#
# for i in range(m):
# for j in range(n):
# I_r_2[i][j] = int(r[i][j] ** 2)
# I_b_2[i][j] = int(b[i][j] ** 2)
# sum_I_r_2 = I_r_2[i][j] + sum_I_r_2
# sum_I_b_2 = I_b_2[i][j] + sum_I_b_2
# sum_I_g = g[i][j] + sum_I_g
# sum_I_r = r[i][j] + sum_I_r
# sum_I_b = b[i][j] + sum_I_b
# if max_I_r < r[i][j]:
# max_I_r = r[i][j]
# if max_I_r_2 < I_r_2[i][j]:
# max_I_r_2 = I_r_2[i][j]
# if max_I_g < g[i][j]:
# max_I_g = g[i][j]
# if max_I_b_2 < I_b_2[i][j]:
# max_I_b_2 = I_b_2[i][j]
# if max_I_b < b[i][j]:
# max_I_b = b[i][j]
I_r_2 = (r.astype(np.float32) ** 2).astype(np.float32)
I_b_2 = (b.astype(np.float32) ** 2).astype(np.float32)
sum_I_r_2 = I_r_2.sum()
sum_I_b_2 = I_b_2.sum()
sum_I_g = g.sum()
sum_I_r = r.sum()
sum_I_b = b.sum()
max_I_r = r.max()
max_I_g = g.max()
max_I_b = b.max()
max_I_r_2 = I_r_2.max()
max_I_b_2 = I_b_2.max()
[u_b, v_b] = np.matmul(np.linalg.inv([[sum_I_b_2, sum_I_b], [max_I_b_2, max_I_b]]), [sum_I_g, max_I_g])
[u_r, v_r] = np.matmul(np.linalg.inv([[sum_I_r_2, sum_I_r], [max_I_r_2, max_I_r]]), [sum_I_g, max_I_g])
# print(u_b, v_b, u_r, v_r)
# b0, g0, r0 = np.zeros(b.shape, np.uint8), np.zeros(g.shape, np.uint8), np.zeros(r.shape, np.uint8)
# for i in range(m):
# for j in range(n):
# b_point = u_b * (b[i][j] ** 2) + v_b * b[i][j]
# g0[i][j] = g[i][j]
# # r0[i][j] = r[i][j]
# r_point = u_r * (r[i][j] ** 2) + v_r * r[i][j]
# if r_point > 255:
# r0[i][j] = 255
# else:
# if r_point < 0:
# r0[i][j] = 0
# else:
# r0[i][j] = r_point
# if b_point > 255:
# b0[i][j] = 255
# else:
# if b_point < 0:
# b0[i][j] = 0
# else:
# b0[i][j] = b_point
b_point = u_b * (b.astype(np.float32) ** 2) + v_b * b.astype(np.float32)
r_point = u_r * (r.astype(np.float32) ** 2) + v_r * r.astype(np.float32)
b_point[b_point > 255] = 255
b_point[b_point < 0] = 0
b = b_point.astype(np.uint8)
r_point[r_point > 255] = 255
r_point[r_point < 0] = 0
r = r_point.astype(np.uint8)
return cv2.merge([b, g, r])
def dynamic_threshold_white_balance(img):
"""
动态阈值算法
算法分为两个步骤:白点检测和白点调整。
只是白点检测不是与完美反射算法相同的认为最亮的点为白点,而是通过另外的规则确定
:param img: cv2.imread读取的图片数据
:return: 返回的白平衡结果图片数据
"""
b, g, r = cv2.split(img)
"""
YUV空间
"""
def con_num(x):
if x > 0:
return 1
if x < 0:
return -1
if x == 0:
return 0
yuv_img = cv2.cvtColor(img, cv2.COLOR_BGR2YCrCb)
(y, u, v) = cv2.split(yuv_img)
# y, u, v = cv2.split(img)
m, n = y.shape
sum_u, sum_v = 0, 0
max_y = np.max(y.flatten())
# print(max_y)
# for i in range(m):
# for j in range(n):
# sum_u = sum_u + u[i][j]
# sum_v = sum_v + v[i][j]
sum_u = u.sum()
sum_v = v.sum()
avl_u = sum_u / (m * n)
avl_v = sum_v / (m * n)
du, dv = 0, 0
# print(avl_u, avl_v)
# for i in range(m):
# for j in range(n):
# du = du + np.abs(u[i][j] - avl_u)
# dv = dv + np.abs(v[i][j] - avl_v)
du = (np.abs(u - avl_u)).sum()
dv = (np.abs(v - avl_v)).sum()
avl_du = du / (m * n)
avl_dv = dv / (m * n)
num_y, yhistogram, ysum = np.zeros(y.shape), np.zeros(256), 0
radio = 0.5 # 如果该值过大过小,色温向两极端发展
# for i in range(m):
# for j in range(n):
# value = 0
# if np.abs(u[i][j] - (avl_u + avl_du * con_num(avl_u))) < radio * avl_du or np.abs(
# v[i][j] - (avl_v + avl_dv * con_num(avl_v))) < radio * avl_dv:
# value = 1
# else:
# value = 0
#
# if value <= 0:
# continue
# num_y[i][j] = y[i][j]
# yhistogram[int(num_y[i][j])] = 1 + yhistogram[int(num_y[i][j])]
# ysum += 1
u_temp = np.abs(u.astype(np.float32) - (avl_u.astype(np.float32) + avl_du * con_num(avl_u))) < radio * avl_du
v_temp = np.abs(v.astype(np.float32) - (avl_v.astype(np.float32) + avl_dv * con_num(avl_v))) < radio * avl_dv
temp = u_temp | v_temp
num_y[temp] = y[temp]
# yhistogram = cv2.calcHist(num_y, 0, u_temp | v_temp, [256], [0, 256])
# yhistogram[num_y[u_temp | v_temp].flatten().astype(np.int32)] += 1
for i in range(m):
for j in range(n):
if temp[i][j] > 0:
yhistogram[int(num_y[i][j])] = 1 + yhistogram[int(num_y[i][j])]
ysum = (temp).sum()
sum_yhistogram = 0
# hists2, bins = np.histogram(yhistogram, 256, [0, 256])
# print(hists2)
Y = 255
num, key = 0, 0
while Y >= 0:
num += yhistogram[Y]
if num > 0.1 * ysum: # 取前10%的亮点为计算值,如果该值过大易过曝光,该值过小调整幅度小
key = Y
break
Y = Y - 1
# print(key)
sum_r, sum_g, sum_b, num_rgb = 0, 0, 0, 0
# for i in range(m):
# for j in range(n):
# if num_y[i][j] > key:
# sum_r = sum_r + r[i][j]
# sum_g = sum_g + g[i][j]
# sum_b = sum_b + b[i][j]
# num_rgb += 1
num_rgb = (num_y > key).sum()
sum_r = r[num_y > key].sum()
sum_g = g[num_y > key].sum()
sum_b = b[num_y > key].sum()
if num_rgb == 0:
return img
# print("num_rgb", num_rgb)
avl_r = sum_r / num_rgb
avl_g = sum_g / num_rgb
avl_b = sum_b / num_rgb
# for i in range(m):
# for j in range(n):
# b_point = int(b[i][j]) * int(max_y) / avl_b
# g_point = int(g[i][j]) * int(max_y) / avl_g
# r_point = int(r[i][j]) * int(max_y) / avl_r
# if b_point > 255:
# b[i][j] = 255
# else:
# if b_point < 0:
# b[i][j] = 0
# else:
# b[i][j] = b_point
# if g_point > 255:
# g[i][j] = 255
# else:
# if g_point < 0:
# g[i][j] = 0
# else:
# g[i][j] = g_point
# if r_point > 255:
# r[i][j] = 255
# else:
# if r_point < 0:
# r[i][j] = 0
# else:
# r[i][j] = r_point
b_point = b.astype(np.float32) * int(max_y) / avl_b
g_point = g.astype(np.float32) * int(max_y) / avl_g
r_point = r.astype(np.float32) * int(max_y) / avl_r
b_point[b_point > 255] = 255
b_point[b_point < 0] = 0
b = b_point.astype(np.uint8)
g_point[g_point > 255] = 255
g_point[g_point < 0] = 0
g = g_point.astype(np.uint8)
r_point[r_point > 255] = 255
r_point[r_point < 0] = 0
r = r_point.astype(np.uint8)
return cv2.merge([b, g, r])
def gamma_trans(img):
"""
gamma 校正
使用自适应gamma校正
:param img: cv2.imread读取的图片数据
:return: 返回的gamma校正后的图片数据
"""
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
mean = np.mean(img_gray)
gamma = math.log10(0.5) / math.log10(mean / 255) # 公式计算gamma
gamma_table = [np.power(x / 255.0, gamma) * 255.0 for x in range(256)] # 建立映射表
gamma_table = np.round(np.array(gamma_table)).astype(np.uint8) # 颜色值为整数
return cv2.LUT(img, gamma_table) # 图片颜色查表。另外可以根据光强(颜色)均匀化原则设计自适应算法。
def contrast_image_correction(img):
"""
contrast image correction论文的python复现,HDR技术
:param img: cv2.imread读取的图片数据
:return: 返回的HDR校正后的图片数据
"""
img_yuv = cv2.cvtColor(img, cv2.COLOR_BGR2YUV)
mv = cv2.split(img_yuv)
img_y = mv[0].copy()
# temp = img_y
temp = cv2.bilateralFilter(mv[0], 9, 50, 50)
# for i in range(len(img)):
# for j in range(len(img[0])):
# exp = np.power(2, (128 - (255 - temp[i][j])) / 128.0)
# temp[i][j] = int(255 * np.power(img_y[i][j] / 255.0, exp))
# # print(exp.dtype)
# print(temp.dtype)
exp = np.power(2, (128.0 - (255 - temp).astype(np.float32)) / 128.0)
temp = (255 * np.power(img_y.flatten() / 255.0, exp.flatten())).astype(np.uint8)
temp = temp.reshape((img_y.shape))
dst = img.copy()
img_y[img_y == 0] = 1
for k in range(3):
val = temp / img_y
val1 = img[:, :, k].astype(np.int32) + img_y.astype(np.int32)
val2 = (val * val1 + img[:, :, k] - img_y) / 2
dst[:, :, k] = val2.astype(np.int32)
# for i in range(len(img)):
# for j in range(len(img[0])):
# if (img_y[i][j] == 0):
# dst[i, j, :] = 0
# else:
# for k in range(3):
# val = temp[i, j]/img_y[i, j]
# val1 = int(img[i, j, k]) + int(img_y[i, j])
# val2 = (val * val1+ img[i, j, k] - img_y[i, j]) / 2
# dst[i, j, k] = int(val2)
# """
# BUG:直接用下面计算方法会导致值溢出,导致计算结果不正确
# """
# dst[i, j, 0] = (temp[i, j] * (img[i, j, 0] + img_y[i, j]) / img_y[i, j] + img[i, j, 0] - img_y[
# i, j]) / 2
# dst[i, j, 1] = (temp[i, j] * (img[i, j, 1] + img_y[i, j]) / img_y[i, j] + img[i, j, 1] - img_y[
# i, j]) / 2
# dst[i, j, 2] = (temp[i, j] * (img[i, j, 2] + img_y[i, j]) / img_y[i, j] + img[i, j, 2] - img_y[
# i, j]) / 2
return dst
if __name__ == '__main__':
"""
img : 原图
img1:均值白平衡法
img2: 完美反射
img3: 灰度世界假设
img4: 基于图像分析的偏色检测及颜色校正方法
img5: 动态阈值算法
img6: gamma校正
img7: HDR校正
"""
import time
img = cv2.imread("image/Lighting_enhancement.jpg")
start_time = time.time()
# img = cv2.resize(img, (512, 512), cv2.INTER_LINEAR)
img1 = mean_white_balance(img)
img2 = perfect_reflective_white_balance(img)
img3 = gray_world_assumes_white_balance(img)
img4 = color_correction_of_image_analysis(img)
img5 = dynamic_threshold_white_balance(img)
img6 = gamma_trans(img) # gamma变换
img7 = contrast_image_correction(img)
end_time = time.time()
print("use time=", end_time - start_time)
# cv2.imshow("image1", img)
img_stack = np.vstack([img, img1, img2, img3])
img_stack2 = np.vstack([img4, img5, img6, img7])
cv2.imshow("image1",img_stack)
cv2.imshow("image2",img_stack2)
# cv2.imwrite("result.jpg",img_stack)
# cv2.imwrite("result2.jpg", img_stack2)
cv2.waitKey(0)
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号