
深度学习模型压缩与加速
简介
将深度学习模型应用于自动驾驶的感知任务上,模型预测结果的准确性和实时性是两个重要指标。一方面,为了确保准确可靠的感知结果,我们会希望选择多个准确性尽可能高的模型并行执行,从而在完成多种感知任务的同时,提供一定的冗余度,但这不可避免的意味着更高的计算量和资源消耗。另一方面,为了确保车辆在各种突发情况下都能及时响应,我们会要求感知模块的执行速度必须与自动驾驶场景的车速相匹配,这就对深度学习模型的实时性提出了很高的要求。另外,在保证高准确性和高实时性的前提下,我们还希望降低模型对计算平台的算力、内存带宽、功耗等方面的要求,从而提高自动驾驶系统整体的效能。为了应对上述挑战,我们需要从各种角度对深度学习模型进行压缩和加速。实际上,模型压缩和加速是一个相当庞大且活跃的研究领域,包含众多的研究方向。本文接下来会简要介绍目前模型压缩和加速领域的主要技术方向,并聚焦于模型裁剪算法这一方向进行详细探讨。在讨论具体的算法之前,首先让我们简要回顾一下深度学习模型的理论复杂度评价指标,以及影响模型实际运行性能的各种因素。
1.复杂度分析
深度学习模型的复杂度主要体现在计算量、访存量和参数量上。
- 计算量:即模型完成一次前向传播所需的浮点乘加操作数,其单位通常写作 FLOPs (FLoating-point OPerations)。对卷积神经网络而言,卷积操作通常是整个网络中计算量最为密集的部分,例如 VGG16 [1] 网络 99% 的计算量都来自于其卷积层。假设卷积层的输出特征图空间尺寸为 H × W,输入通道数为 Cin,卷积核个数(输出通道数)为 Cout,每个卷积核空间尺寸为 KH × KW,那么该卷积层的理论计算量为 H × W × KH × KW × Cin × Cout FLOPs。可以看到,卷积层的计算量由输出特征图的大小、卷积核的大小以及输入和输出通道数所共同决定。对输入特征图进行下采样,或者使用更小、更少的卷积核都可以明显降低卷积层的计算量。
- 访存量:即模型完成一次前向传播过程中发生的内存交换总量,单位是 Byte。访存量的重要性经常会被人们忽视,实际上,模型在逐层进行前向传播的过程中,需要频繁的读写每层的输入特征图、权重矩阵和输出特征图,而读写速度取决于计算平台的内存带宽。如果我们在尝试加速模型的时候,只关注减少模型计算量,而没有等比例减小其访存量,那么依据 Roofline [2] 理论,这将导致模型在实际运行过程中,发生单位内存交换所对应的计算量下降,模型会滑向越来越严重的内存受限状态(即下图中的红色区域),从而无法充分的利用计算平台的算力,因此最后观察到的实际加速比与理论计算量的减小并不成正比。
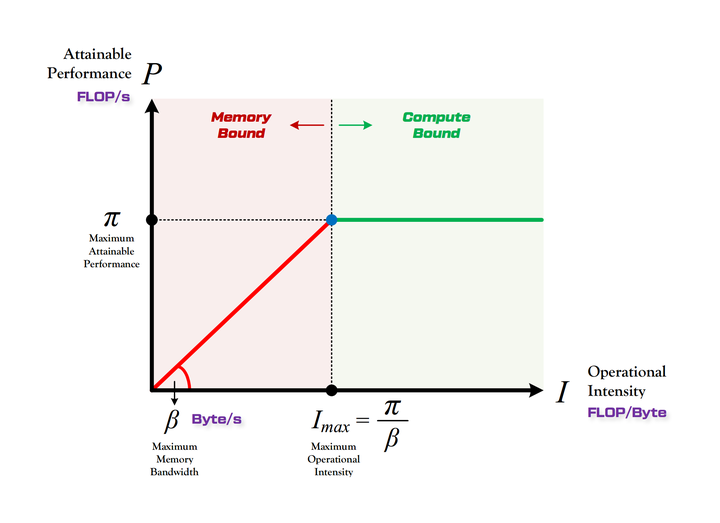
图1:Roofline Model(图中左侧红色区域为带宽受限,右侧绿色区域为算力受限)
- 参数量:即模型所含权重参数的总量,单位是 Byte,表现为模型文件的存储体积大小。全连接层通常是整个网络参数量最为密集的部分,例如 VGG16 网络中超过 80% 的参数都来自于最后三个全连接层。资源严重受限的移动端小型设备会对模型文件的大小较为敏感。
- 并行度:如果以 GPU 作为计算平台,那么由于 GPU 本身所具有的高吞吐特性,模型的并行度会成为影响模型实际运行效率的一个重要方面。模型的并行度越高,意味着模型越能够充分利用 GPU 的算力,执行效率越高。影响并行度的因素有很多,例如模型的计算强度(计算量与访存量的比值)、卷积算法的具体实现方式等,Batch Size 也会显著的影响模型的并行度。
2.模型压缩和加速的主要技术方向
深度学习模型压缩和加速算法是一个相当庞大且活跃的研究领域,涵盖软件和硬件,包括众多的技术方向,简要概括如下:
- 轻量网络设计:指重新设计新型网络结构,而不局限于仅对现有网络进行优化加速。轻量网络设计方向的主要代表论文是 MobileNet v1 / v2 [3, 4] , ShuffleNet v1 / v2 [5, 6] 等,其主要思想是利用 Depthwise Convolution、Pointwise Convolution、Group Convolution 等计算量更小、更分散的卷积操作代替标准卷积。这类模型的计算量通常仅有几十到几百 MFLOPs,与传统的大型网络例如 VGG / Inception [7] / ResNet [8] 等动辄上 GFLOPs 的计算量相比有明显优势,同时在比较简单的任务上与大模型的准确率差距较小。
- 模型裁剪:相比轻量网络设计,模型裁剪主要关注对现有模型做减法,由大化小。其主要思想是在保持现有模型的准确率基本不变的前提下,设计某种筛选机制(稀疏化),在某个尺度上筛选掉卷积层中重要性较低的权重,从而达到降低计算资源消耗和提高实时性的效果 [12, 13, 14, 15, 16, 17]。模型裁剪算法的核心就在于权重筛选机制的设计以及筛选粒度的选择上。这也是本文接下来会着重深入讨论的方向。
- 模型蒸馏:相比于模型裁剪的目标是把大模型逐渐变小,同时保持精度损失较小,模型蒸馏的目标是利用大模型(Teacher Network)提供的监督特征帮助计算量较小的模型(Student Network)达到近似于大模型的精度,从而实现模型加速。模型蒸馏的关键在于监督特征的设计,例如使用 Soft Target 所提供的类间相似性作为依据 [9],或使用大模型的中间层特征图 [10] 或 attention map [11] 作为暗示,对小网络进行训练。
- 矩阵分解:由于深度学习模型中计算量最密集的部分就是卷积,而卷积可以经过 im2col 之后用矩阵乘法实现,因此我们可以使用多种矩阵低秩近似方法 [18, 19],将两个大矩阵的乘法操作拆解为多个小矩阵之间的一系列乘法操作,降低整体的计算量,加速模型的执行速度。
- 量化与低精度运算:深度学习模型在运行过程时需要进行大量的浮点乘加运算,一般默认数据位宽是 32bit,但是实际上我们完全可以用更低的位宽(例如 16bit / 8bit / 4bit / 2bit 甚至 1bit)来量化模型的权重和特征图,完成近似的运算 [21, 22, 23]。这么做一方面可以成倍的降低模型运行时的访存量,一方面在相应硬件指令集的支持下,可以成倍的提高模型的运算速度。其重点在于如何控制低精度对模型带来的精度损失。
- 计算图优化:深度学习模型的层数通常在几十层到上百层,但实际上层与层之间有很多部分都存在固定的组合关系(例如 Conv-BatchNorm-ReLU 组合),因此我们可以对计算图中的这些固定组合进行优化,分别在水平和垂直方向上将多层融合为一层执行,从而大量减少层间不必要的内存拷贝以及多次 kernel launch 带来的开销,有效提升模型的运行速度。
- 卷积算法优化:卷积运算本身有多种算法实现方式,例如滑动窗、im2col + gemm、FFT、Winograd卷积等方式。这些卷积算法在速度上并没有绝对的优劣,因为每种算法的效率都很大程度上取决于卷积运算的尺寸。因此,在优化模型时,我们应该对模型的各个卷积层有针对性的选用效率最高的卷积算法,从而充分利用不同卷积算法的优势。
- 硬件加速:任何模型的运行都需要依托于某种计算平台来完成,因此我们可以直接从计算平台的硬件设计方面进行加速。目前深度学习模型的主流计算平台是 GPU,从 Volta 架构开始,GPU 配备了专门用于快速矩阵乘法运算的硬件计算单元 Tensor Core,可以显著提升深度学习模型的吞吐量。同时,以低功耗低延迟为主要特性的 FPGA / ASIC 加速芯片也开始在业界崭露头角。
除此之外,在更广义的视角下,使用多任务学习、多传感器融合、利用多帧之间的相关性等方法通过减少模型数量和数据处理量,也能间接的降低计算资源消耗,提高实时性。总体而言,上面介绍的各种技术路线分别从不同的角度提升模型的运行速度、减少模型的资源消耗,可谓条条大路通罗马。在实际应用中,这些方法相互之间通常并不矛盾,可以相互弥补,因此我们通常会叠加使用,使整体达到更好的效果。
下面让我们聚焦在模型裁剪算法这个研究方向上。
3.模型裁剪算法
广义上的模型裁剪算法,其本质是在各种粒度下寻找更为稀疏的模型表征。对于模型的权重,我们既可以在神经元的粒度上进行裁剪(Fine Grained Pruning),也可以在每个卷积核的通道粒度上进行裁剪(Channel Pruning),甚至可以直接拿掉那些我们认为对于模型表征没有太多贡献的卷积核(Filter Pruning)。按照裁剪的粒度,我们可以将裁剪算法划分为非结构化裁剪和结构化裁剪这两大类方式。
模型的非结构化裁剪是在神经元级别对网络的权重进行裁剪 [12],算法的具体流程分为三步,第一步是正常训练网络,第二步是人为设定一个阈值并对所有权值低于该阈值的神经元进行裁剪,第三步是通过微调网络来恢复损失的精度。这种裁剪方式的灵活性最高,但是会导致权重矩阵稀疏化,需要额外的稀疏矩阵运算库或者专门设计的硬件支持 [20] 才能真正达到加速效果,在实际应用中存在一定限制。因此下面我们主要介绍对于实现较为友好的各种结构化裁剪算法。
3.1 Filter 粒度上的裁剪
论文 [13] 提出了一种在 Filter 粒度上简单高效的模型裁剪算法。该算法的裁剪依据是卷积核的 L1Norm。对于每个卷积层,我们会统计每个卷积核权重矩阵的 L1Norm,并按照 L1Norm 的取值从小到大排序,如图2所示。然后人为设定一个保留的比例(例如 80%),将最小的 20% 卷积核移除。作者认为,对于同样的输入特征图,一个卷积核相比其他卷积核是否更重要、是否有必要继续存在于模型中,很大程度上取决于它的整体权值大小,L1Norm越大的卷积核更有可能产生响应值较大的输出特征图,进而更有可能对网络最后的输出结果产生更大贡献。反过来,如果一个卷积核的所有权值都非常接近于 0,那么无论给它输入什么样的特征图,其输出也将都是 0,这说明该卷积核对于整个模型的表征能力贡献较小,很有可能是冗余的,因此可以直接裁剪去除。算法的具体执行流程与上面介绍的非结构化裁剪类似,逐层执行 Filter Pruning 并搭配进行 Finetune 恢复精度,直到所有层都完成裁剪。
从计算量优化角度来分析,如果我们对第 i 个卷积层进行 Filter Pruning,保留其中 r% 的卷积核,由于卷积层的计算量与输出通道数呈正比,因此该层的计算量将降为裁剪前的 r%;同时,由于第 (i+1) 个卷积层的输入通道数降为原来的 r%,因此该层的整体计算量也降为原来的 r%,而且每个卷积核也都得以精简相应的输入通道。简而言之,对第 i 个卷积层按保留比例 r% 进行裁剪,会导致第 i 层和第 (i+1) 层的计算量都降为之前的 r%。
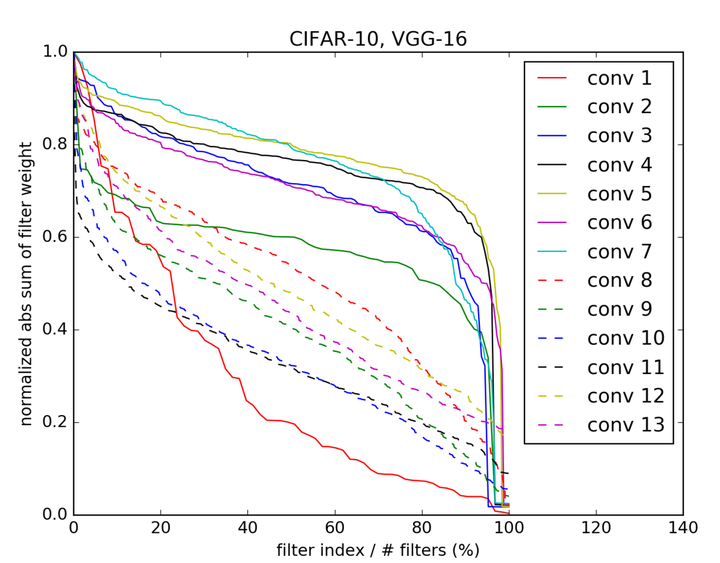
图2:对 VGG16 模型每个卷积层的所有卷积核按照 L1Norm 进行排序后的取值分布情况。横轴为归一化后的卷积核索引,纵轴为归一化后的卷积核权重的 L1Norm 取值。
3.2 Channel 粒度上的裁剪
论文 [14] 提出了一种在 Channel 粒度上的模型裁剪算法。该算法没有依据卷积核的取值进行裁剪,而是将注意力聚焦在特征图的不同通道上,其核心思想在于分析输入特征图的各个通道对输出特征图的贡献大小,并使用 LASSO 回归将这一问题转变为对输入通道的选择问题。作者指出,如果我们可以去掉输入特征图的某个或多个通道,并且还能够确保该卷积层的输出特征图基本不变,那么这就意味着那些去掉的输入通道本身对于输出特征图的贡献很小,可以安全去除而不影响网络的精度。
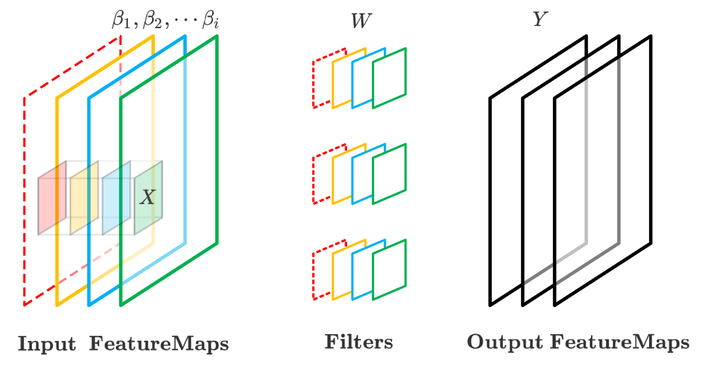
图3:Channel Pruning 示意图,左侧为输入特征图,中间为卷积核,右侧为输出特征图,虚线表示裁剪。
整个裁剪算法主要分为两步,可以参考图3所示。
第一步:通道选择。如上图所示,假设该卷积层的输入特征图具有 4 个通道,3 个卷积核,每个输入通道定义一个权重系数 beta_i。为了获取输入特征图与输出特征图的原始对应关系,我们需要对输入特征图按照卷积核的感受野进行多次随机采样,获得矩阵 X,并根据权重矩阵 W 获得相应的输出特征点集合 Y,构造优化方程,这里我们对 beta 进行优化,目标是最小化原输出特征点与经过 beta 权重系数得到的输出特征点之间的误差,添加 L1 正则项,通过调整 lambda 可以调整 beta 中置零项的个数,lambda 越大,意味着我们裁剪的输入通道数越多。
LaTeX
第二步:最小化重建误差。在完成 beta 权重系数的选择后(如上图所示,输入特征图中的红色通道被移除,与此同时,所有卷积核的红色输入通道也被移除),我们可以进一步对卷积核的权重矩阵 W' 进行优化,目的是通过调整 W',让裁剪后的输入特征图经过卷积后与输出特征图的误差尽可能小。这步操作能够有效的恢复裁剪后模型的精度,减小后期微调训练的工作量。
代码块LaTeX
我们评价模型裁剪算法通常会关注两个指标,一个是裁剪后模型的准确率损失是多少,一个是裁剪前后模型在相同计算平台上的实际运行速度提升是多少,前者反映了算法所使用裁剪依据的合理性,后者反映了算法的实际有效性。
针对第一个指标,表1给出了多种模型加速算法针对同一个模型(VGG16)分别将计算量进行 50% 裁剪(2x)、75% 裁剪(4x)、80% 裁剪(5x)情况下在 ImageNet 数据集上的 Top5 准确率损失数据。可以看到,Filter Pruning 在裁剪 75% / 80% 计算量的情况下,导致模型的精度分别下降 7.9% 和 22%,而同样裁剪比的 Channel Pruning 对模型的精度损失仅有 1% 和 1.7%,裁剪质量提升十分明显。
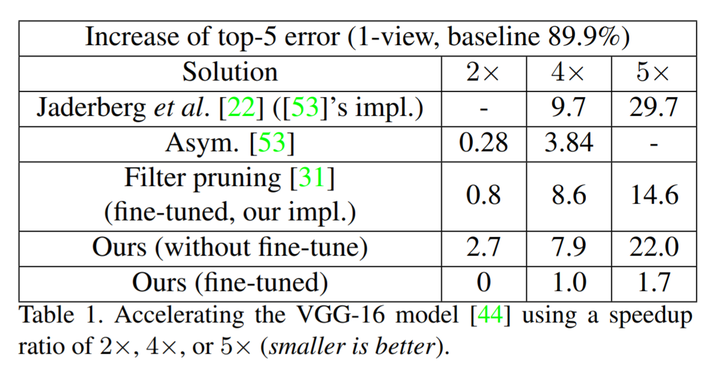
图4:不同裁剪算法在同样减少 VGG16 模型 2倍、4倍、5倍计算量的条件下,在 ImageNet 数据集上 Top5 Accuracy 的下降情况,数值越小越好。
针对第二个指标,表2给出了Channel Pruning与其他基于矩阵低秩近似算法在相同裁剪比的实际加速效果对比。可以看到,同样是裁剪掉 75% 的计算量,经过各种矩阵低秩近似算法变换后的模型由于并行度下降,几乎没有加速效果,甚至有些运行速度比之前更慢;相比之下,采用结构化裁剪的 Channel Pruning 算法能够达到 2.5 倍的加速,同时精度损失只有 1%。

图5:不同裁剪算法在同样减少 VGG16 模型 4 倍计算量的条件下,在 Titan X 上实测的准确率损失和每张图片预测耗时情况,数值越小越好。
在两种粒度上进行裁剪的异同点
- 如果我们从裁剪的实际操作上来看,Filter Pruning 与 Channel Pruning 是完全等效的。Filter Pruning 的操作是:移除第 i 层的部分卷积核,同时移除第 i+1 层所有卷积核的相应通道。Channel Pruning 的操作是:移除第 i + 1 层所有卷积核的某些通道,同时移除第 i 层的产生这些通道的卷积核。两种方式仅仅顺序不同,但最终表现出来的裁剪操作是相同的。
- 但是如果我们从裁剪的依据上来看,两者是完全不同的。Filter Pruning 仅关注权重的取值,不需要数据驱动。而 Channel Pruning 会首先逐层灌入数据,获得输入和输出特征图,然后综合考虑输入特征图经过权重矩阵后对输出特征图的贡献,再将其中部分通道裁剪。后者的数据驱动方式使其可以获得更好的裁剪质量。
3.3 边训练边学习裁剪
上面介绍的 Channel Pruning 方法主要适用于已经完成训练的模型,那么我们是否能够在模型的最初训练阶段就为 Channel Pruning 做好准备呢?答案是肯定的。论文 [15, 16] 提出对模型每个卷积层的各个输入通道分配权重系数 gamma,然后将这些权重系数作为 L1 正则项加入损失函数,从而实现在模型训练阶段同时对常规模型权重和各通道权重进行优化,如图6所示。这种裁剪机制的好处在于,当完成模型训练后,我们不仅得到了可用的模型,还同时得到了模型各层权重在通道尺度上的重要性分布,因此我们就可以通过设置阈值来快速完成所有卷积层的通道裁剪操作,最后 Finetune 恢复精度。
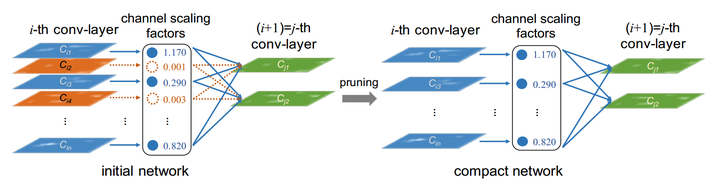
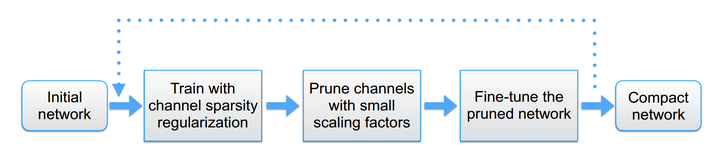
图6:对卷积层的每个通道设置缩放系数,在训练过程中对各个通道进行稀疏约束。
在具体实现上,卷积层各个通道重要性系数的学习,并不是通过在每个卷积层之后添加 Scaling layer 来进行的,因为卷积与缩放操作都属于线性变换,连在一起整体依然是一个线性变换,如果仅对Scaling层进行L1正则,可能会导致卷积层权重出现负补偿,并不能有效的对卷积层的各个通道进行稀疏约束。因此论文中使用的方法是,在每个卷积层之后添加 BN 层,然后对 BN 层的 Scaling Factor gamma 施加 L1 正则。我们知道 Batch Norm 会首先对输入特征图的每个通道按照当前batch的均值和方差进行归一化,再通过缩放与平移输出。为了强制使 BN 的 gamma 取值尽可能稀疏,我们可以在 Loss 中添加 gamma 的 L1 Norm 作为惩罚项,修改 BN 层的反向传播过程,其他部分正常训练即可。实际上,很多网络中(例如 ResNet)已经默认将卷积与BN搭配使用,因此对于这些网络而言,甚至网络结构都不需要改变,就可以直接使用这种裁剪算法边训练、边学习通道裁剪系数,十分方便。
3.4 基于强化学习的自动化裁剪
上面介绍的裁剪算法,不论裁剪粒度是通道还是卷积核,不论裁剪依据是来自于权重还是特征图,都有一个共性,就是需要基于经验选择各层的裁剪阈值比例和迭代轮数,整个模型裁剪过程中不可避免的需要大量人工干预。这带来两个方面的问题,一个是效率,一个是质量。一方面我们希望模型裁剪的过程能够像模型训练一样全自动高效完成,另一方面,基于人工经验的裁剪方案往往在实际中很难达到最优解,我们希望能够让模型裁剪算法生成更高质量的方案。因此,论文 [17] 提出了一种基于强化学习的自动化模型裁剪算法 AMC。该方法不仅可以自动化执行,而且与使用相同裁剪算法的人工裁剪方案相比,这种方法最后生成的整体模型裁剪方案的精度损失更低。
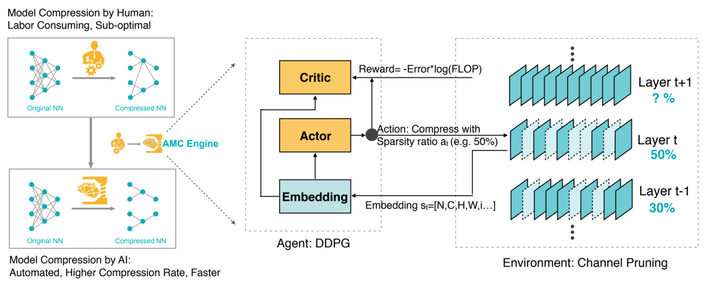
图7:Overview of AutoML for Model Compression (AMC) Engine.
该算法采用基于 DDPG 的 Agent,对模型的各个卷积层进行逐层裁剪。对于每一层,Agent 首先会获得描述该层以及相邻层计算特性的状态空间向量(包括卷积的尺寸、计算量等信息),Actor 根据该状态和自己的策略网络生成相应的裁剪比(即行为),然后调用裁剪算法完成相应的裁剪操作。当整个网络都完成一次裁剪后,就可以计算出裁剪前后引入的精度损失,然后通过预定义的奖励函数将奖励值返回给 Agent, Critic 会根据状态和奖励更新自己的价值网络,经过多次迭代不断更新策略网络和价值网络,完成 Exploration-Exploitation 的过程,获得最后的裁剪模型,然后对这个模型进行 Finetune,获得最终的模型。论文提出了奖励函数的两种设计方案,一种是通过限定搜索空间,搜索在指定裁剪范围内精度损失最小的模型裁剪方案。另一种则是将模型计算量、参数量、预测耗时等指标直接引入到奖励函数,在保持精度不变的前提下,搜索让这些指标尽可能小的裁剪方案。针对 VGG16 的裁剪实验结果显示,在同样精简 80% 计算量的情况下,采用 AMC 裁剪方法不仅可以自动完成,而且最终模型的精度损失比其他人工裁剪方案的精度损失更低,在 ImageNet 上的 Top1 准确率下降仅有 1.4%。
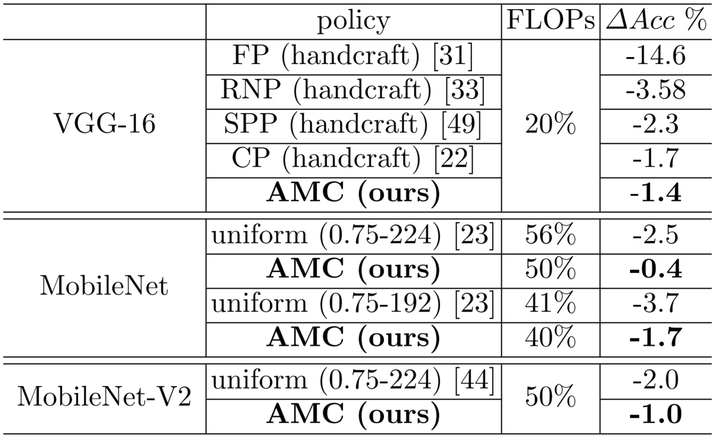
图8:AMC 与其他裁剪算法在计算量减少量和准确率损失上的对比。
4. 小结
本文回顾了模型加速领域中模型裁剪方向上的几种比较成功的裁剪算法。通过上面的介绍,我们可以看到,模型裁剪算法的核心思想是在各种粒度下寻找更为稀疏的模型表征,去除模型的冗余部分。需要注意的是,模型中的“冗余部分”始终是一个相对的概念,它与模型本身的结构以及模型所处理的任务难度有密切关系。模型体积越大、层数越深、所面对的任务越简单,也就意味着模型的相对冗余度越高,可以使用更大比例进行裁剪而不明显影响精度。但同时我们也需要认识到,从目前的模型裁剪算法来看,在保持精度损失较小的前提下,所有裁剪算法都存在一定的裁剪上限,一旦超过上限,再进一步裁剪都会不可避免的损伤模型的精度,即便 finetune 也无法恢复。因此,如何能够更为精准的对模型进行裁剪而不损失精度,并且同时保证实际运行的加速比,是模型裁剪方向的未来研究重点,让我们拭目以待。
5. 参考文献
1. Karen Simonyan and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition". The International Conference on Learning Representations (ICLR). 2015.
2. Samuel Williams, Andrew Waterman, and David Patterson. "Roofline: An insightful visual performance model for multicore architectures". Communications of The ACM, Vol.52. 2009.
3. Andrew G. Howard, et al. "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications". arXiv preprint arXiv:1704.04861. 2017.
4. Mark Sandler, et al. "MobileNetV2: Inverted Residuals and Linear Bottlenecks". arXiv preprint arXiv:1801.04381. 2018.
5. Xiangyu Zhang, et al. "ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices". IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018.
6. Ningning Ma, et al. "ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design". European Conference on Computer Vision (ECCV). 2018.
7. S. Ioffe and C. Szegedy. "Batch normalization: Accelerating deep network training by reducing internal covariate shift". arXiv preprint arXiv:1502.03167. 2015.
8. Kaiming He, et al. "Deep residual learning for image recognition". IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016.
9. Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. "Distilling the Knowledge in a Neural Network". Conference and Workshop on Neural Information Processing Systems (NIPS) Workshop. 2014.
10. Adriana Romero, et al. "FitNets: Hints for thin deep nets". The International Conference on Learning Representations (ICLR). 2015.
11. Sergey Zagoruyko, Nikos Komodakis. "Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer". The International Conference on Learning Representations (ICLR). 2017.
12. Han Song, et al. "Learning both weights and connections for efficient neural network". Advances in Neural Information Processing Systems (NIPS). 2015.
13. Hao Li, et al. "Pruning filters for efficient convnets". The International Conference on Learning Representations (ICLR). 2017.
14. He Yihui, Zhang Xiangyu, and Sun Jian. "Channel pruning for accelerating very deep neural networks". Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017.
15. Zhuang Liu, et al. "Learning efficient convolutional networks through network slimming". IEEE International Conference on Computer Vision (ICCV). 2017.
16. Jianbo Ye, et al. "Rethinking the Smaller-Norm-Less-Informative Assumption in Channel Pruning of Convolution Layers". The International Conference on Learning Representations (ICLR). 2018.
17. He Yihui, et al. "AMC: AutoML for Model Compression and Acceleration on Mobile Devices". European Conference on Computer Vision (ECCV). 2018.
18. Max Jaderberg, Andrea Vedaldi and Andrew Zisserman. "Speeding up convolutional neural networks with low rank expansions". arXiv preprint arXiv:1405.3866. 2014.
19. Zhang Xiangyu, et al. "Accelerating very deep convolutional networks for classification and detection". IEEE transactions on pattern analysis and machine intelligence, 38(10):1943–1955. 2016.
20. Han Song, et al. "EIE: Efficient Inference Engine on Compressed Deep Neural Network". arXiv preprint arXiv:1602.01528. 2016.
21. Matthieu Courbariaux, Yoshua Bengio, and Jean-Pierre David. "BinaryConnect: Training Deep Neural Networks with binary weights during propagations". arXiv preprint arXiv:1511.00363. 2015.
22. Mohammad Rastegari, et al. "XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks". European Conference on Computer Vision (ECCV). 2016.
23. Itay Hubara, et al. "Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations". arXiv preprint arXiv:1609.07061. 2016.
24. 模型加速概述与模型裁剪算法技术解析(美团无人配送算法团队)
25. https://www.zhihu.com/search?type=content&q=%E6%A8%A1%E5%9E%8B%E5%8E%8B%E7%BC%A9
26. 《解析卷积神经网络》关于第四章卷积神经网络的压缩
27. 深度学习模型压缩与加速综述

 浙公网安备 33010602011771号
浙公网安备 33010602011771号