kafaka部署及使用
一、怎么理解kafka
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
但我们这里就单把它看做是一个消息队列。队列这个数据结构我们也很熟悉了,队列的先进先出的结构可以轻松地实现消息的输入和输出。但是为什么还需要使用kafka来实现,而不直接用队列,这个问题不用想都知道kafka对此做了优化。这个优化的内容就是我们需要了解的。这里我们暂时跳过优化的过程,我们直接说结果,优化的结果就是我们作为开发人员,我们并不需要太多地注意消息怎么存放、消息怎么读取,我们只需要调用send()和listen
发送信息
kafkaTemplate.send(topic, KEY, context)
监听信息
@KafkaListener(id = "webGroup", topics = "topic") public String listen(String input, Acknowledgment ack) { logger.info("input value: {}", input); if ("kl".equals(input)) { ack.acknowledge(); } return "successful"; }
有了kafka之后,我们无需关心过多,我们只需要创建好topic,然后往里面发送信息就可以,我们获取消息也只需要监听好对应的topic,设置好自己的groupid。
二、部署kafka
下载链接
https://archive.apache.org/dist/kafka/0.10.2.0/kafka_2.12-0.10.2.0.tgz
① tar -xzf kafka_2.12-0.10.2.0.tgz
② cd kafka_2.12-0.10.2.0
③ bin/zookeeper-server-start.sh config/zookeeper.properties (启动 Zookeeper 服务)
(后台运行 setsid bin/zookeeper-server-start.sh config/zookeeper.properties)
kafka里面有自带的zookeeper的启动器,所以无需先搭建zookeeper。但是kafka的更高版本已经不使用zookeeper做注册中心了,详情可以google一下。
④ 修改 config/server.properties
vim /xx/xx/config/server.properties
# 本地监听的服务器端口listeners=PLAINTEXT://:9092# 提供外网访问时需要配置,192.168.201.128是当前服务器 IPadvertised.listeners=PLAINTEXT://192.168.201.128:9092
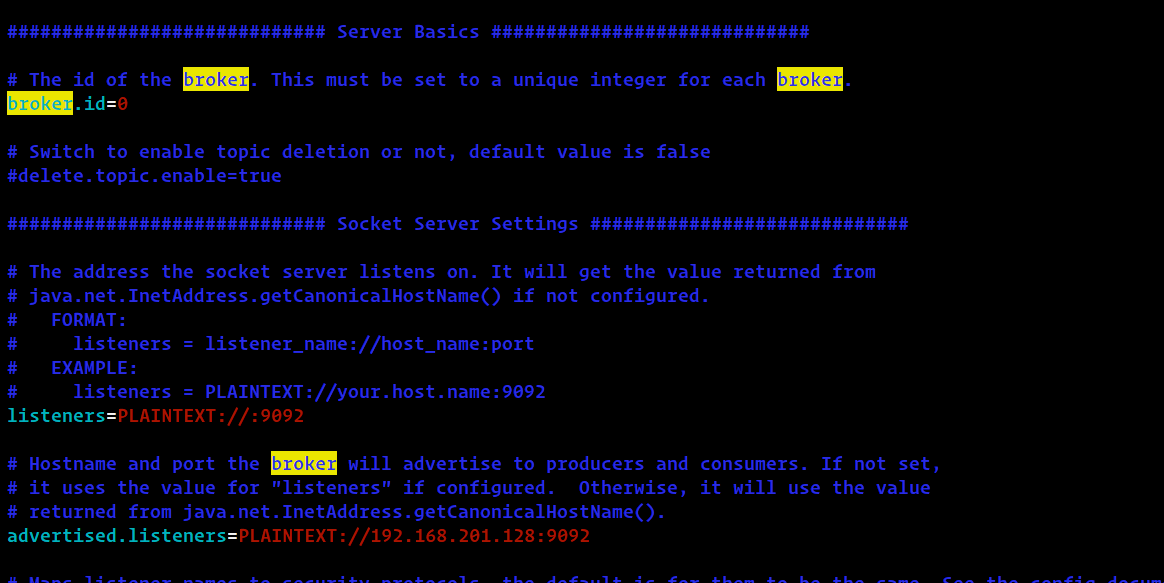
kafka之前是使用zookeeper的端口2182,但是现在用的自己的端口9092了,在代码调用时要注意端口。当然这个端口可以随便改的,只要不冲突就可以了。
⑤ bin/kafka-server-start.sh config/server.properties (启动 Kafka Broker 服务)
(后台运行 setsid bin/kafka-server-start.sh config/server.properties)
最后可以用命令 jps 去看自己的kafka是否部署成功
如果提示 jps 找不到命令,可以执行如下命令进行安装:
- yum install java-1.8.0-openjdk-devel.x86_64
三、用命令行发送与接受消息
1、发送消息时kafka的单位是topic,所以我们需要创建一个topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
创建一个名为“test”的topic
2、查看当前的所有topic
./kafka-topics.sh --list --zookeeper localhost:2181
3、打开两个命令窗口
我们需要在同一台服务器上打开两个命令窗口,这样方便看。
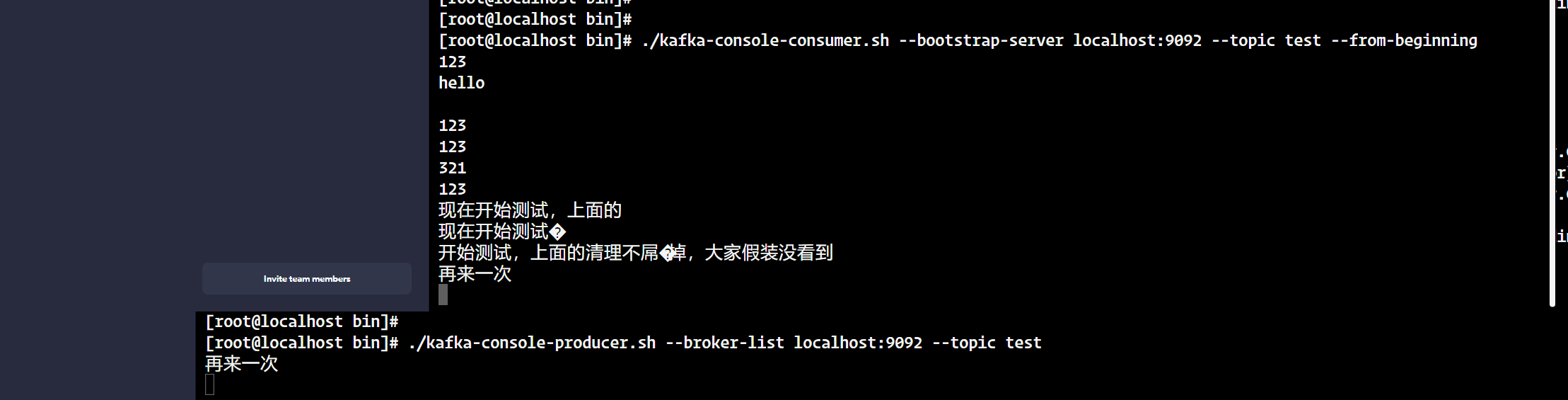
①、首先创建消息生产者。执行如下命令启动 Kafka 基于命令行的消息生产客户端,启动后可以直接在控制台中输入消息来发送,控制台中的每一行数据都会被视为一条消息来发送。
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
(因为我们这里还没打开使用消费者去消费我们输入的消息,所以这些信息都会阻塞在topic--test里,直到有消费者将它消费掉)

② 接着创建消息消费者。我们打开另一个命令窗口执行如下执行命令启动 Kafka 基于命令行的消息消费客户端,启动之后,马上可以在控制台中看到之前我们在消息生产客户端中发送的消息。
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
三、spring-kafka
经过上面的操作我们已经有了kafka的环境以及大概了解到kafka的原理,这里我们直接使用代码来使用
首先,我们需要有一个springmvc或者springboot的项目环境,然后导入spring-kafka的maven
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>2.9.0</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>1.6.6</version> </dependency>
这里需要也导入slf4j,不然会导找不到slf4j。
1、生成kafka
private final KafkaTemplate<String, String> kafkaTemplate = kafkaTemplate();
public Map<String, Object> producerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers); props.put(ProducerConfig.RETRIES_CONFIG, retries); props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize); props.put(ProducerConfig.LINGER_MS_CONFIG, linger); props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory); props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, false); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); return props; } public ProducerFactory<String, String> producerFactory() { return new DefaultKafkaProducerFactory<>(producerConfigs()); } public KafkaTemplate<String, String> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); }
其实上面最重要的就是servers,它需要填写的是kafka的broker.id,一般会有多个服务器,用逗号隔开就行。这里用我自己的测试机举例,那我这里
bootstrap.servers = "192.168.201.128:9092"
注意,这里如果你的ip或者端口填写错了,它会一直报拒绝链接或者连接超时,然后过阵子就不重试了,此时检查一下ip port有没有写错即可。
其他的配置我们一个个来解释一下
- buffer.memory 约束KafkaProducer能够使用的内存缓冲的大小的,默认值32MB。
- batch.size 可以理解为单个数据包的大小
- linger.ms 最久的未发送时间,超过这个时间即使数据量太少也会发出去,单位毫秒
- max.request.size 每次发送给Kafka服务器请求消息的最大大小
- retries和retries.backoff.ms 发送失败重试次数,根据业务场景设置。
- acks:1——表示leader写入成功(但是并没有刷新到磁盘)后即向producer响应。延迟中等,一旦leader副本挂了,就会丢失数据
0——不需要等待服务器的确认
all——需要等待服务器的确认,且在副本里已经做好备份。一般工作中选择这个,它等同于“-1”
2、生产者生产消息
有了上面的方法之后我们已经有了kafka的实例,现在我们来发送消息
kafkaTemplate.send(topic, context);
没错,就是这么简单🤣,但是实际使用时我们不要这么简洁,我们需要获取一些报错之类并且打印日志
try {
// KEY 可以是你自己命名的东西,可以是你公司的名称或者是你业务的名称,key可以指定消息发送到特定的一个partition里,你不指定也可以 ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, KEY, context); SendResult<String, String> result = future.get(); log(String.format("[Kafka#Producer] Push successful topic=%s, key=%s, TopicPartition@Offset(%s).", topic, KEY, result.getRecordMetadata())); } catch (RecordTooLargeException e) {
// 如果 context 太大会导致发不出去,这时可以通过调节配置解决 log("[Kafka#Producer] Failed to send too large message. That will be ignored retry.", e); } catch (Exception e) {
// 这里是未知的发送错误,此处可以做重发动作或者其他与业务相关的操作 log("[Kafka#Producer] Failed to send message.", e); }
这里你可以自己测试,你可以在服务器上监听这个topic,然后你运行这个controller,你就可以看到你发过去的context
3、消费者获取消息
@KafkaListener(topics = {"test"}, groupId = "groupid")
public void listen(ConsumerRecord<?, ?> record) {
log("kafka的key: " + record.key());
log("kafka的value: " + record.value().toString());
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号