Fork/Join高并发处理百万级以上数据
了解Fork/Join这个框架是因为我在工作上遇到了一个需求,需要处理一个百万以上的数据。一开始我没有做任何的优化,第一版去测试的时候,差不多40万的数据,运行了50分钟,因为客户的需求是每天都要定时运行一次,那这样肯定是不行。然后我就去问我导师怎么搞,他就推荐我使用Fork/Join去做。先说结果,速度提升了10倍,5分钟就跑完了。
言归正传,我们来开始了解一下Fork/Join这个框架。
- Fork/Join
Fork/Join框架是Java7提供的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。使用工作窃取(work-stealing)算法,主要用于实现“分而治之”。
但我觉得可以直接把它当做递归来思考,因为你在真正用Fork/Join的时候也是跟递归是一样的。对递归还不熟悉的同学建议先去了解一下递归再来学习Fork/Join。因为它其实就是把大任务分解成一个个小的任务,然后建立一个线程池,线程池里面的线程并发去处理这些个小任务。
2.方法
fork() 就是执行子任务
join()方法的主要作用是阻塞当前线程并等待获取结果,所以Join()是用在有返回值的情况里的
invokeAll() 这个是将两个分解出来的子任务一起执行,执行子任务调用fork方法并不是最佳的选择,最佳的选择是invokeAll方法。用我下面贴的代码来举例就是
invokeAll(leftTask, rightTask);
等同于
leftTask.fork();
rightTask.fork();
3.实例
在我上面说到我工作遇到的事例就是,我要对一个百万以上的数据做同步操作。那么我就是将List分解成一个个小List,然后每个线程去遍历这个小的List将每个List里面的数据去做同步操作。(我这里是有一个同步的api,我只需要将每个数据拿出来,然后调用这个接口就可以了)
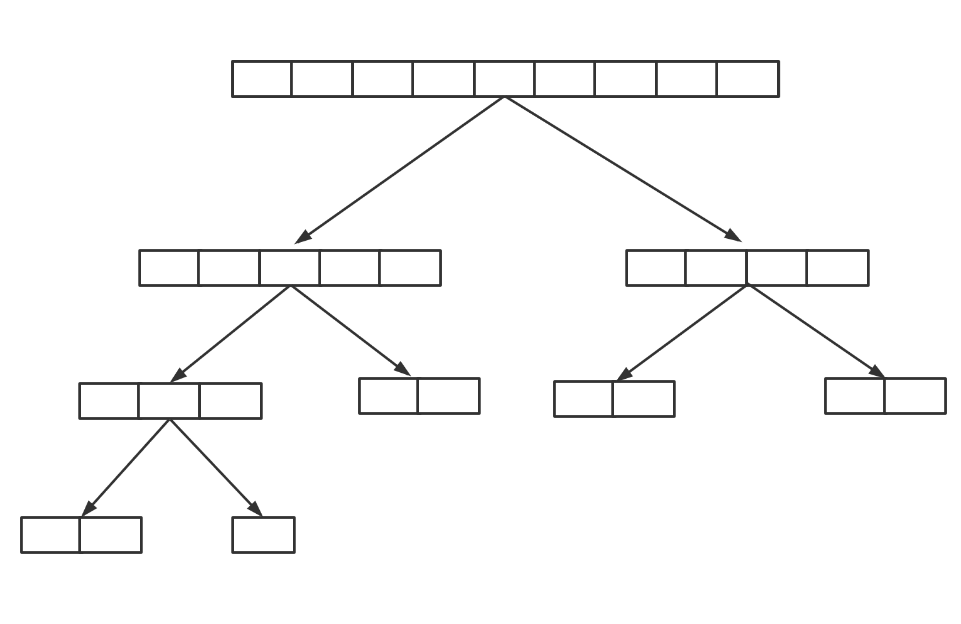
举个栗子,假设这个List的size是9,我要去分割这个List,我先设定最小的任务的大小是2,那么当分割到任务小于或等于2的时候,就不会继续分割下去了。如图所示,我最后分割成了5个小任务,然后多个线程并发去遍历这几个小任务。
3.工作上用到的代码
上面这个例子,大伙可以自己去摸索一下代码要怎么写,我就懒得写了,要春节了,偷懒一下。下面我贴一下我工作上写的代码。我这里去分割List是使用下标start和end去分割的,我一开始还傻傻的以为要去new一个List,把自己给蠢到了。
ps:ColumnSet是自己包装的类型
AddressBookDBSync就是同步的类
这里继承的是RecursiveAction,还可以继承RecursiveTask。前者适用于没有返回值的场景,而后者适合于有返回值的场景
public class SyncEoaAddressBookForkJoin extends RecursiveAction { private int minTaskSize; //最小任务大小 private int start; private int end; private List<ColumnSet> list; private ConfigSection configSection; int totalSize; public SyncEoaAddressBookForkJoin(int start, int end, List<ColumnSet> list, ConfigSection configSection) { this.start = start; this.end = end; this.list = list; this.configSection = configSection; this.totalSize = list.size(); minTaskSize = configSection.getItem("minTaskSize").getInt(); } @Override protected void compute() { boolean executable = (end - start) > minTaskSize; if (!executable) { //直接调用同步方法 try { AddressBookDBSync addressBookDBSync = new AddressBookDBSync(configSection); for (int i = start; i <= end ; i++) { ColumnSet columnSet = list.get(i); addressBookDBSync.getUserEoaUid(columnSet.getString("eoa_user_id")); } } catch (Exception e) { LOG.warning("request error"); } } else { int middle = (start + end) / 2; SyncEoaAddressBookForkJoin leftTask = new SyncEoaAddressBookForkJoin(start, middle, list, configSection); SyncEoaAddressBookForkJoin rightTask = new SyncEoaAddressBookForkJoin(middle + 1, end, list, configSection); invokeAll(leftTask, rightTask); } } }
然后就是怎么去创建线程池和调用这个方法去并发处理
//调用ForkJoin去并发处理数据 ForkJoinPool forkJoinPool = ForkJoinPool.commonPool(); SyncEoaAddressBookForkJoin syncEoaAddressBookForkJoin = new SyncEoaAddressBookForkJoin(0, listSize, list, configSection); forkJoinPool.submit(syncEoaAddressBookForkJoin); syncEoaAddressBookForkJoin.join(); //等待整个任务完成 //检查报错 if (syncEoaAddressBookForkJoin.isCompletedAbnormally()) { CmcuUtils.LOG.warning("forkJoin hsa error :" + syncEoaAddressBookForkJoin.getException()); } //关闭线程池 forkJoinPool.shutdown();
forkJoinPool.submit(syncEoaAddressBookForkJoin)就是将分割成的一个个小任务扔到线程池里面,然后最后记得关闭线程池就可以了,亲测有效。
![]()
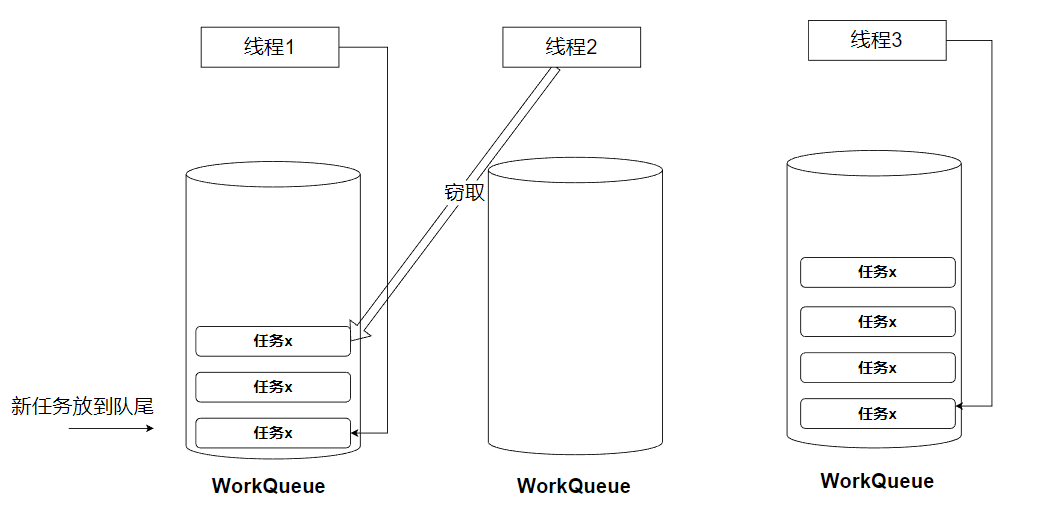
当然,Fork/Join的知识点远远不止这点,里面还包含着它设计的工作队列、工作窃取(work-stealing)算法,只是对于我们平常工作中的使用,我们认识这么多就够了。并且网上关于这些的描述已经很完善了,“前人之述备矣”。https://ld246.com/article/1517841032139https://zhuanlan.zhihu.com/p/101418412
4.实际使用时遇到的问题:
因为分的任务太多了,导致请求量太高被nignx拦截了。查看nignx的错误日志可以看到
2022/04/20 09:00:49 [error] 2799268#0: *179131 limiting requests, excess: 50.200 by zone "mylimit", client: xx.xxx.xxx.xx, server: , request: "POST /abcsync/contact/xxxx?param=xxx HTTP/1.0", host: "xxx.test.abc"
它这个意思就是被nignx里面的“mylimit”命中,被拦截了,所以报了 Http Status : 503
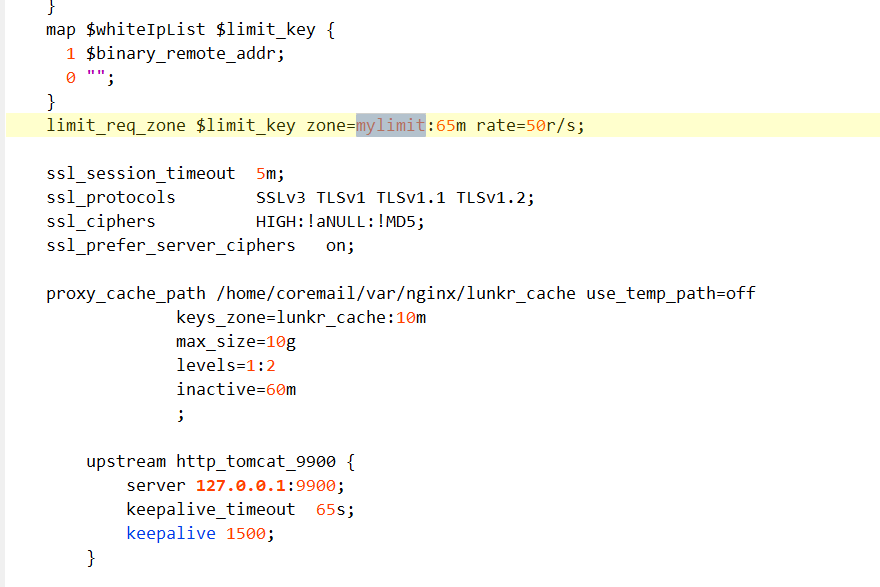
以上配置表示,限制每个 IP 访问的速度为 50r/s,因为 Nginx 的限流统计是基于毫秒的,我们设置的速度是 50r/s,转换一下就是 20ms 内单个 IP 只允许通过 1 个请求,从 21ms 开始才允许通过第 2 个请求。
所以我这个“mylimit”限制每秒只允许通过50个请求,但是如果我们调整“rate=50r/s”的话,服务器可能会处理不过来,也会导致报错,看网友说也可以修改那个“65m”,这个好像是缓存空间,就是如果有请求超过
这个限制量,则会被存放到这个缓存空间里面,当服务器空闲时就会重新处理被暂时搁置的请求。但是这个当时没仔细看,如果想修改这个的话,可以google一下。
最后说一下我最后是怎么解决问题的,我用了最简单的方法,我把minTaskSize调大了,这样子请求量就会降下来。因为我这个系统不可能全部都来处理我这个任务,所以只能放弃性能。但是最后处理时间也才
几十分钟,也算是完成任务了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号