
ELK+KAFKA安装部署指南


一、ELK
背景
通常,日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:ELK中的logstash,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心,这里我们使用ELK中的elasticsearch和kibana。
一、ELK是什么?
ELK实际上是三个工具的集合,Elasticsearch + Logstash + Kibana,这三个工具组合形成了一套实用、易用的监控架构,很多公司利用它来搭建可视化的海量日志分析平台。大家熟知的Sina、饿了么、携程、华为、美团、新浪微博、魅族、IBM...... 这些公司都在使用ELK。
Elasticsearch是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统。它构建于Apache Lucene搜索引擎库之上。
Logstash是一个用来搜集、分析、过滤日志的工具。它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 RabbitMQ、kafka)和JMX,它能够以多种方式输出数据,包括电子邮件、websockets和Elasticsearch等。
Kibana是一个基于Web的图形界面,用于搜索、分析和可视化存储在 Elasticsearch指标中的日志数据。它利用Elasticsearch的REST接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据。
二、ELK有何优势?
1. 强大的搜索功能,elasticsearch可以以分布式搜索的方式快速检索,而且支持DSL的语法来进行搜索,简单的说,就是通过类似配置的语言,快速筛选数据。
2. 完美的展示功能,可以展示非常详细的图表信息,而且可以定制展示内容,将数据可视化发挥的淋漓尽致。
3. 分布式功能,能够解决大型集群运维工作很多问题,包括监控、预警、日志收集解析等。
二、KAFKA
kafka详解:https://blog.csdn.net/ychenfeng/article/details/74980531
背景
通过查看网络上一些ELK的性能测试报告、博客和官方文档,发现logstash有性能瓶颈而且不支持缓存,目前业内典型替代方案是将 Redis 或 Kafka 作为中心缓冲池,这里我们选择kafka作为我们的日志收集缓冲池。
一、KAFKA是什么?
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala和java编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
二、KAFKA何优势?
1. 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒。
2. 可扩展性:kafka集群支持热扩展。
3. 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
4. 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)。
5. 高并发:支持数千个客户端同时读写。
二、KAFKA使用场景?
1. 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr、logstash等。
2. 消息系统:解耦和生产者和消费者、缓存消息等。
3. 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
4. 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
三、KAFKA相关名词解释
Kafka中发布订阅的对象是topic。我们可以为每类数据创建一个topic,把向topic发布消息的客户端称作producer,从topic订阅消息的客户端称作consumer。Producers和consumers可以同时从多个topic读写数据。一个kafka集群由一个或多个broker服务器组成,它负责持久化和备份具体的kafka消息。
Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
Topic:一类消息,消息存放的目录即主题,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列
Segment:partition物理上由多个segment组成,每个Segment存着message信息
Producer: 生产message发送到topic
Consumer: 订阅topic消费message, consumer作为一个线程来消费
Consumer Group:一个Consumer Group包含多个consumer, 这个是预先在配置文件中配置好的。各个consumer(consumer 线程)可以组成一个组(Consumer group ),partition中的每个message只能被组(Consumer group ) 中的一个consumer(consumer 线程 )消费,如果一个message可以被多个consumer(consumer 线程 ) 消费的话,那么这些consumer必须在不同的组。Kafka不支持一个partition中的message由两个或两个以上的consumer thread来处理,即便是来自不同的consumer group的也不行。
总体部署架构方案
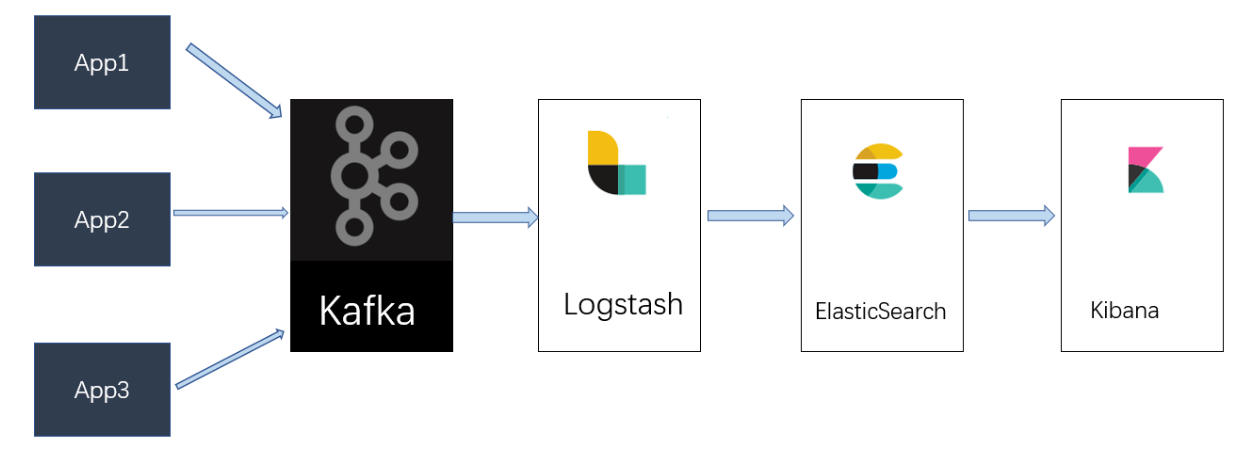
一、准备工作
准备安装包
ELK下载地址:https://www.elastic.co/downloads
zookeeper下载地址:https://www.apache.org/dyn/closer.cgi/zookeeper/
kafka下载地址:http://kafka.apache.org/downloads
elasticsearch中文分词器下载地址: https://pan.baidu.com/s/1i4ZAuwNueb_1-tZKBzQJ4g
VMwareWorkstation
CentOS7(192.168.68.110, 192.168.68.111, 192.168.68.112)
二、安装ES
elasticsearch官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
1、创建用户
因为elasticsearch不能使用root用户启动,所以需要先创建一个用户,并对用户进行授权,使用root用户登录,执行以下命令
useradd es #创建用户 passwd es #设置用户密码,输入与用户名一样的密码
2、安装unzip
yum install -y unzip
3、修改系统参数
vi /etc/security/limits.conf 增加以下内容 * soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096 vi /etc/security/limits.d/90-nproc.conf 修改如下内容: * soft nproc 1024 #修改为 * soft nproc 4096 vi /etc/sysctl.conf 添加下面配置: vm.max_map_count=655360 并执行命令: sysctl -p
4、上传文件
使用elasticsearch用户登录,将之前下载好的elasticsearch-6.2.4.tar.gz、elasticsearch-analysis-ik-6.2.4.zip上传至根目录
5、创建数据与日志目录
在elasticsearch用户的根目录执行以下命令
mkdir {log,data}
6、解压安装包、修改配置
解压安装包
tar -zxvf elasticsearch-6.2.4.tar.gz
进入elasticsearch-6.2.4/config目录,config目录下有三个文件:
elasticsearch.yml # els的配置文件 jvm.options # JVM相关的配置,内存大小等等 log4j2.properties # 日志系统定义
修改后的配置elasticsearch.yml如下:
cluster.name: es-cluster #集群名称 node.name: node-110 #节点名称,仅仅是描述名称,用于在日志中区分 path.data: /home/es/data #数据的默认存放路径 path.logs: /home/es/log #日志默认存放路径 network.host: 192.168.68.110 #当前节点的IP地址 http.port: 9200 #对外提供服务的端口,9300为集群服务的端口 discovery.zen.ping.unicast.hosts: ["192.168.68.110", "192.168.68.111","192.168.68.112"] #集群个节点IP地址 discovery.zen.minimum_master_nodes: 2 #为了避免脑裂,集群节点数最少为 半数+1 bootstrap.system_call_filter: false #禁止系统调用过滤器
jvm.options中默认内存为1G,开发环境可以不修改,生产时需要根据服务器内存调整大小
-Xms1g # JVM最大、最小使用内存 -Xmx1g
7、加入中文分词器插件
日志中可能出现中文,为了方便中文检查,需要加入中文分词器插件
unzip elasticsearch-analysis-ik-6.2.4.zip -d elasticsearch-6.2.4/plugins/ mv elasticsearch/ik #因为ik解压后的目录名为elasticsearch,为了避免其他插件可能冲突,修改名称为ik
8、启动easticsearch
./elasticsearch -d
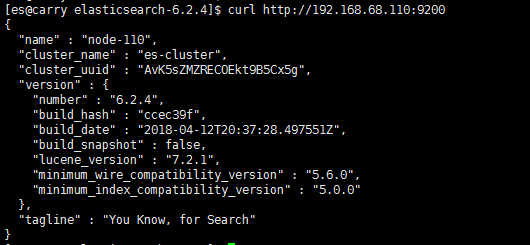
9、访问测试
使用curl访问:curl http://192.168.68.110:9200,出现如下信息,说明访问成功
按上述步骤将三台集群安装好后,检查集群状态
curl -XGET 'http://192.168.68.110:9200/_cat/nodes?pretty'

带“*”的为主节点
安装时遇到的问题
问题一: [1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536])
解决:切换到root用户,进入/etc/security目录下修改配置文件
vi /etc/security/limits.conf
增加以下内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
注:修改以上配置后需要重启服务器
问题二: max number of threads [2048] for user [es] is too low, increase to at least [4096]
解决:切换到root用户,进入limits.d目录下修改配置文件。
vi /etc/security/limits.d/90-nproc.conf
修改如下内容:
* soft nproc 1024
#修改为
* soft nproc 4096
注:修改以上配置后需要重启服务器
问题三:max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
解决:切换到root用户修改配置sysctl.conf
vi /etc/sysctl.conf
添加下面配置:
vm.max_map_count=655360
并执行命令:
sysctl -p
三、kafka集群搭建
1、创建用户
使用root用户登录,执行以下命令
useradd kafka #创建用户 passwd kafka #设置用户密码,输入与用户名一样的密码
2、解压安装包
使用新创建的用户将包上传至用户根目录,并解压
tar -zxvf kafka_2.11-1.1.0.tgz
创建目录
mkdir zookeeper
cd zookeeper
mkdir {logs,data}
3、修改zookeeper配置(kafka自带zookeeper)
进入配置目录:cd kafka_2.11-1.1.0/config/
修改配置文件:vi zookeeper.properties
修改后的配置如下(三台机的zookeeper.properties内容一致):
#zookeeper数据存放目录 dataDir=/home/kafka/zookeeper/data #zookeeper日志存放目录 dataLogDir=/home/kafka/zookeeper/logs # the port at which the clients will connect clientPort=2181 # disable the per-ip limit on the number of connections since this is a non-production config # 客户端连接的最大数量. maxClientCnxns=60 # 心跳间隔时间,zookeeper中使用的基本时间单位,毫秒值。每隔2秒发送一个心跳 tickTime=2000 # leader与follower连接超时时间。表示10个心跳间隔 initLimit=10 # Leader与follower之间的超时时间,表示5个心跳间隔 syncLimit=5 server.1=192.168.68.110:2888:3888 server.2=192.168.68.111:2888:3888 server.3=192.168.68.112:2888:3888
创建myid文件,进入cd /home/kafka/zookeeper/data
192.168.68.110 echo 1 > myid 192.168.68.111 echo 2 > myid 192.168.68.112 echo 3 > myid 注:myid是zk集群用来发现彼此的标识,必须创建,且不能相同
4、修改kakfa配置
进入配置目录:cd kafka_2.11-1.1.0/config/
修改配置文件:vi server.properties
broker.id=0 #分别配置为192.168.68.110=0,192.168.68.111=1,192.168.68.112=2 listeners=PLAINTEXT://192.168.68.110:9092 #监听地址,分别配置不同的服务器PLAINTEXT://192.168.68.111:9092,PLAINTEXT://192.168.68.112:9092 log.dirs=/home/kafka/kafka_2.11-1.1.0/logs zookeeper.connect=192.168.68.110:2181,192.168.68.111:2181,192.168.68.112:2181
5、启动zookeeper
./zookeeper-server-start.sh ../config/zookeeper.properties &
查看日志文件/home/kafka/kafka_2.11-1.1.0/logs/server.log,如无异常信息说明zookeeper集群成功
6、启动kafka
注:启动kafka之前需要将kafka、zookeeper所在服务器的防火墙关闭
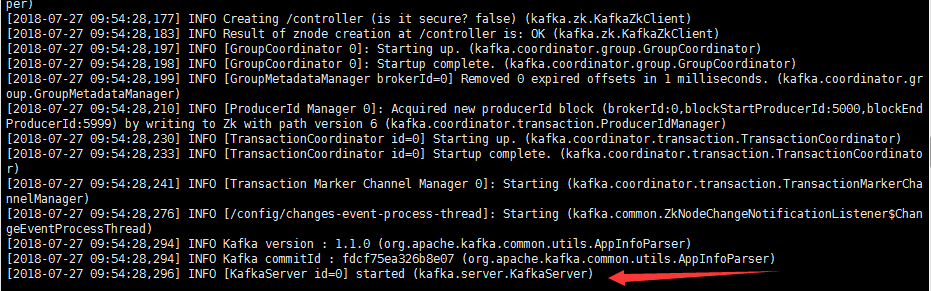
./kafka-server-start.sh ../config/server.properties &
出现下图中日志则说明启动成功了
四、安装logstash(192.168.68.111)
logstash官方文档:https://www.elastic.co/guide/en/logstash/current/index.html
1、解压安装包、修改配置
解压安装包:tar -zxvf logstash-6.2.4.tar.gz
进入到解压后的目录:cd logstash-6.2.4
input {
kafka {
bootstrap_servers => "192.168.68.110:9092, 192.168.68.111:9092,192.168.68.112:9092"
topics => ["test"]
auto_offset_reset => "latest"
consumer_threads => 5
decorate_events => true
}
}
output {
elasticsearch {
hosts => ["192.168.68.110:9200"]
index => "kafka-logs-%{+YYYY-MM-dd}"
}
}
2、启动logstash
启动kafka:./bin/logstash -f config/kafkaInput_esOutPut.conf &

五、安装kibana(192.168.68.1112)
kibana官方配置指南:https://www.elastic.co/guide/en/kibana/current/settings.html
1、解压安装包、修改配置
解压安装包:tar -zxvf kibana-6.2.4-linux-x86_64.tar.gz
进入到解压后的目录:cd kibana-6.2.4-linux-x86_64
修改后的配置如下:
server.port: 5601 server.host: "192.168.68.112" server.name: "kibana" elasticsearch.url: "http://192.168.68.110:9200"
2、启动kibana
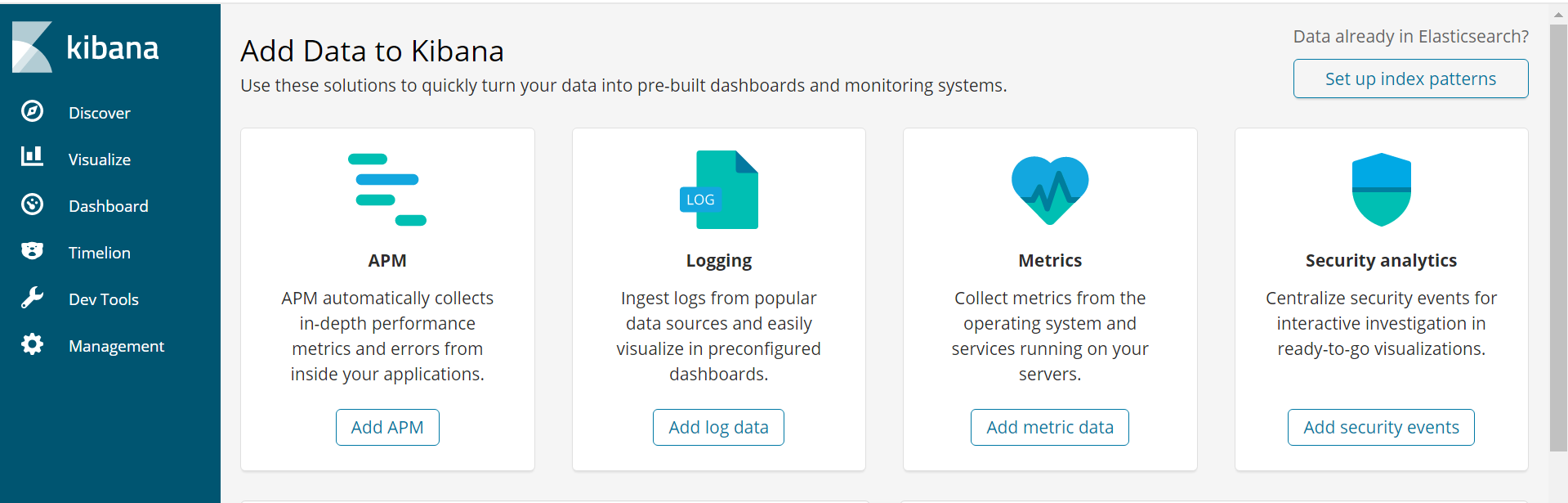
启动:./kibana &
出现下图中日志则说明启动成功

3、访问测试
在浏览器中输入:http://192.168.68.112:5601,出现如下界面,说明部署成功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号