Light-Weight RefineNet for Real-Time Semantic Segmentation
Light-Weight RefineNet for Real-Time Semantic Segmentation
1. 概述
语义分割依赖高分辨率的输入,存在大量的参数,因此实时性变成了致命弱点。本文的方法建立在RefineNet之上,可用于任何骨干网络,如ResNet、DenseNet、NASNet或任何其他网络。本文的贡献在于:i)节省了超过50%的参数; ii)确定了架构中残差块的冗余度,并表明除去这些块后性能保持不变。
在PASCAL VOC, NYUDv2和PASCAL-Person-Part数据集上进行实验,平均Iou分别为82.7%、44.4%、67.6%,保持稳定的32FPS。
2. 方法介绍
降低参数的方法:量化法、剪枝法、knowledge distillation。其思想围绕着低秩分解和分解的思想,将大的层通过使用线性结构分解成更小的层,实现压缩。
2.1 RefineNet
本文目的是减少最初的RefineNet体系结构的参数和浮点操作的数量,同时保持相同的性能水平。
RefineNet属于“编码器-解码器”网络系列,其中输入图像首先逐步向下采样,然后逐步向上采样,以恢复原始输入大小, 缺点是参数较多。
RefineNet主要内容如下:
1 作者提出了一种多路径精细网络(RefineNet),它利用多层抽象的特征来实现高分辨率的语义分割。RefineNet以递归的方式将低分辨率(粗)语义特征与细粒度的低层特征进行精化,从而生成高分辨率语义特征图。模型是灵活的,它可以级联和修改很容易。
2.级联RefineNets可以被有效地端到端训练,这对于获得最佳的预测性能至关重要。更具体地说,RefineNet中的所有组件都使用残差连接和同等映射,这样梯度可以直接通过短距离和长程残差连接传播,从而实现高效的端到端训练。
3.提出了一种新的网络组件称之为链式剩余池,它能够从一个大的图像区域捕获背景上下文。它是通过有效地汇集具有多个窗口大小的特征,并通过剩余连接和可学习权值将它们融合在一起来实现的。
4. 提出的RefineNet在7个公共数据集上实现了最新的性能,包括PASCAL VOC 2012、PASCAL- context、NYUDv2、SUN-RGBD、Cityscapes、ADE20K,以及对人-部件数据集的对象解析。特别是,在PASCAL VOC 2012数据集上,我们获得了IoU的83.4分,远远超过了目前最好的方法DeepLab。
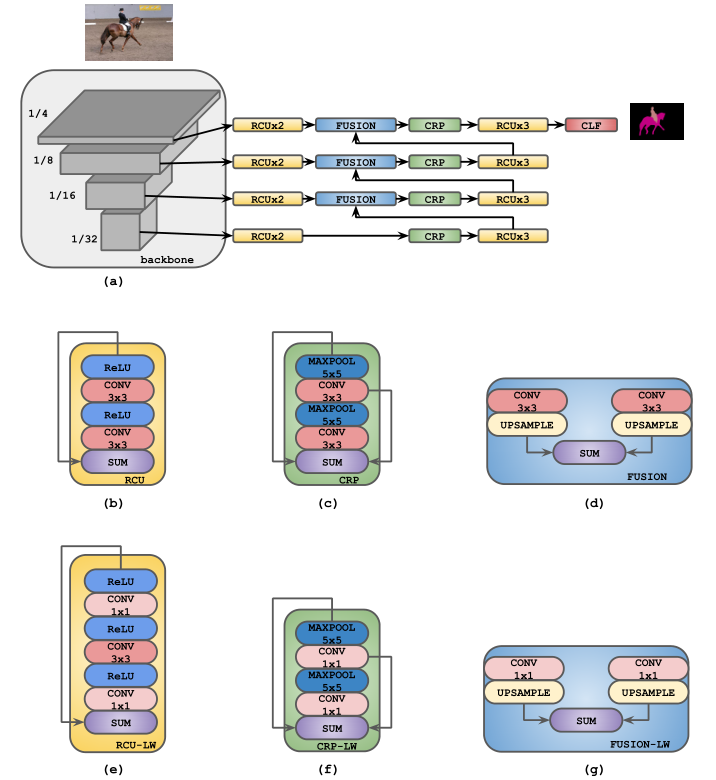
图1 RefineNet结构
(a)使用RefineNet进行语义分割的通用网络架构,其中CLF表示单个3x3卷积层,信道数等于输出类数;(b)-(d)原始RCU、CRP和融合块的大体轮廓;(e)-(g)轻量RCU、CRP和融合块。
注:在最终的架构中没有使用任何RCU块
RefineNet解码器部分:RCU即residual convolutional unit(残差卷积单元),为经典残差网络ResNet中的residual block去掉batch normalisation部分,由ReLU和卷积层构成;CRP为链式残差池化(chained residual pooling),由一系列的池化层与卷积层构成,以残差的形式排列;RCU与CRP中使用3*3卷积和5*5池化。FUSION部分则是对两路数据分别执行3*3卷积并上采样后求和SUM。
2.2 具体改进点:
- 将CRP内部的3*3卷积改成1*1;
- RCU修改为瓶颈结构,并省略了该部分,作者尝试去除RefineNet
网络中部分及至所有RCU模块,发现并没有任何的精度下降,并进一步发现原来RCU blocks已经完全饱和。
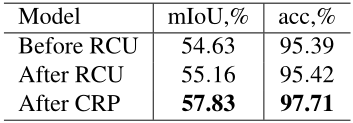
作者对比了有无使用RCU模块的参数量和浮点运算数,结果如下表:

- 使用轻量级NASNet-Mobile、MobileNet-v2骨干网络。
- 保留CPR模块,负责收集上下文信息,实验证明CRP是准确分割和分类的主要驱动力,而RCU块对结果的改善微乎其微。
3. 实验部分
目的:通过实验证明,能够i)实现与原始网络类似的性能水平;ii)显著减少参数的数量;iii)大幅提高前进通过的速度;和iv)强调将方法应用于其他架构的可能性。
数据集:PASCAL VOC,NYUDv2和PASCAL-Person-Part
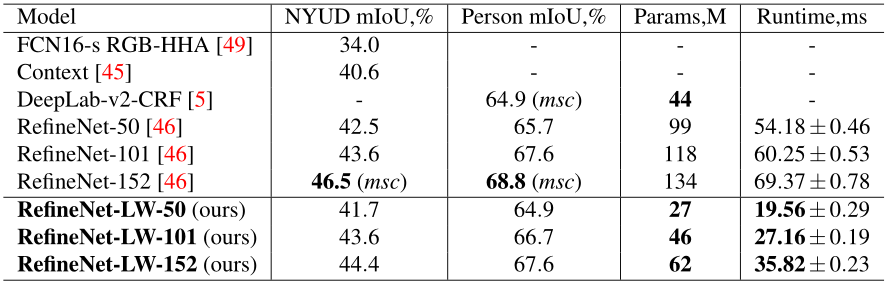
结果显示性能略有下降,但参数量和计算时间大幅降
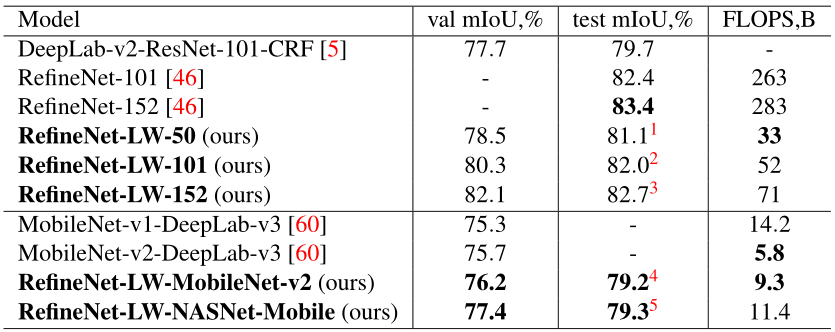
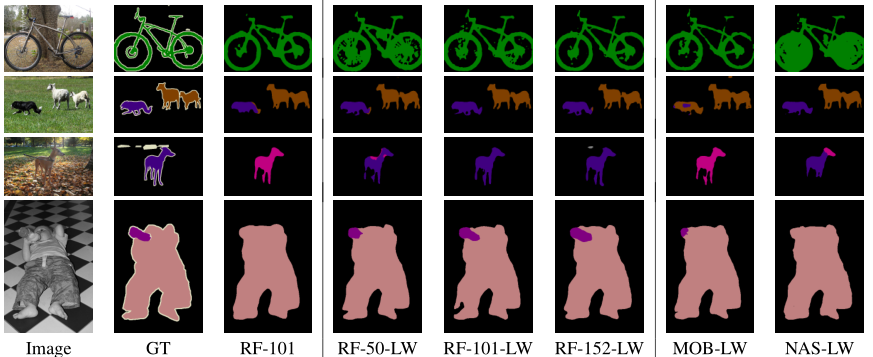
可视化结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号