Object-Contextual Representations for Semantic Segmentation(ECCV2020)
1. 概述
论文提出了对象上下文表示的方法,即通过利用对应类的对象区域的表示来增加一个像素的表示,利用该区域学习更好的像素表示,从而得到更好的像素标记。实验验证,截止ECCV 2020提交日期,“HRNet + OCR + SegFix”在cityspace上前排名第一。
2. 方法介绍
方法包括三个主要步骤:首先,将上下文像素划分为一组软目标区域,每个软目标区域对应一个类,即在ground-truth分割的监督下从深度网络计算得到的粗软分割。其次,通过聚合像素在相应的目标区域的表示估计每个目标区域的表示。最后,使用对象上下文表示(OCR)来增强每个像素的表示。OCR是将所有目标区域表示与根据像素和目标区域之间的关系计算出的权重进行加权聚合。
ASPP等多尺度上下文只区分空间位置不同的像素,OCR区分相同对象类的上下文像素和不同对象类的上下文像素。
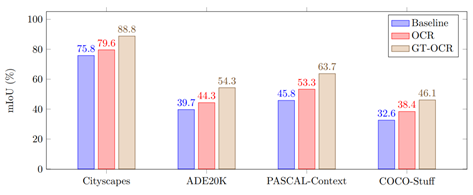
图1 分割结果
2.1 OCR方法
(1)将图像I中的所有像素结构化为K个软目标区域;
(2)将第K个目标区域中所有像素的表示聚合为fk;
(3)聚合K个目标区域表示来增强每个像素的表示,公式表示为:
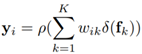
其中wik为第i个像素点与第k个目标区域的关系,其余为转换函数。
2.2 Soft object regions(软目标区域)
将图像I划分为K个软目标区域{M1,M2,…, MK}。每个对象区域Mk对应类k,由一个2D映射(或粗分割映射)表示,其中每个条目表示对应像素属于类k的程度。
作者从一个主干输出的中间表示来计算K个对象区域。在训练过程中利用交叉熵损失从ground-truth分割中学习在监督下的目标区域生成器。
2.3 Object region representations
将所有属于第k个目标区域的按度加权的像素集合表示,形成第k个目标区域表示:
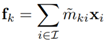
其中xi是像素pi的表示。˜mki是像素属于k对象区域的归一化程度。使用softmax来归一化每个对象区域Mk。
2.4 Object contextual representations
计算每个像素和每个目标区域之间的关系如下:
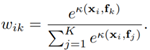
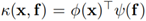
其中, 分子部分是未标准化的关系函数,两个变换函数由1×1 conv→BN→ReLU实现。
2.5 Augmented representations
像素pi的最终表示为两部分的聚合,(1)原始表示xi;(2)对象上下文表示yi。
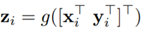
其中g(·)用于融合原始表示和对象上下文表示的变换函数,由1×1 conv→BN→ReLU实现。
3. 结构
3.1 Backbone
ResNet-101(output stride 8)或HRNet-W48 (output stride 4)。
dilated ResNet-101:有两种表示输入到OCR模块。来自阶段3用于预测粗分割(目标区域);第4阶段的另一个表示经过3×3卷积(512个输出通道),然后送入OCR模块。
HRNet-W48:只使用最终输出作为OCR模块的输入。
3.2 OCR module
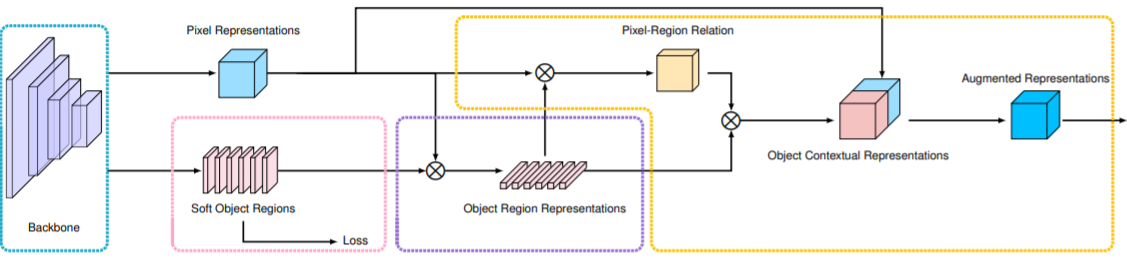
图2 OCR原理
(i)在粉红色虚线框中形成软对象区域。(ii)紫色虚线框中估计目标区域表示;(iii)橙色虚线框中计算对象上下文表示和增强表示。
如图2所示,使用一个线性函数(1×1卷积)来预测粗分割(软目标区域),使用像素级的交叉熵损失。所有的transform函数实现均为1×1 conv→BN→ReLU。使用一个线性函数从最终图像表示中预测最终的分割,在最终的分割预测中也应用了像素级交叉熵损失。
4. 实验
4.1 数据集
Cityscapes、ADE20K、LIP、PASCAL-Context、COCO-Stuff
4.2 实验设置
数据增强:水平随机翻转,在[0.5,2]范围内进行随机缩放,在[−10,10]范围内进行随机亮度抖动; poly学习策略
4.3 实验结果
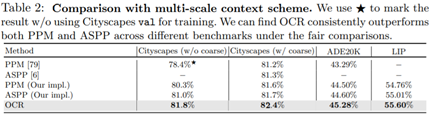
Comparison with multi-scale context scheme
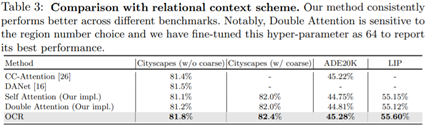
Comparison with relational context scheme
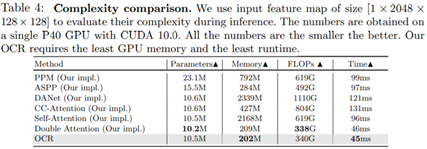
Complexity comparison
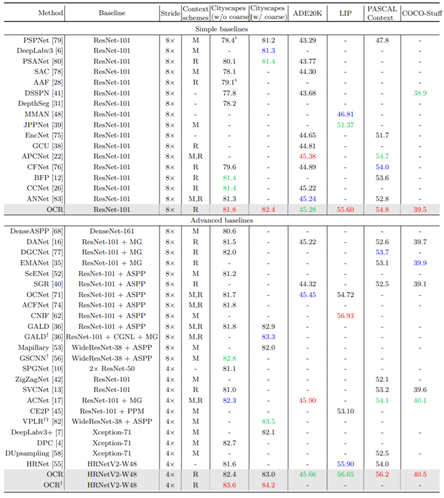
Comparison with state-of-the-art

 浙公网安备 33010602011771号
浙公网安备 33010602011771号