FCN与ParseNet
Fully Convolutional Networks for Semantic Segmentation
1 问题描述
本文是将CNN应用到语义分割任务并得到显著结果的开山之作。以往的用于语义分割的CNN,是对候选区域进行特征提取,不能达到像素级别的精度。本文设计了FCN(全卷积网络),将网络中的全连接层替换为卷积层,输入任意尺寸,通过学习生成对应尺寸的输出。
其主要贡献在于:
(1) FCN(全卷积网络)将分类网络中的全连接层替换为卷积层,可以输入任意尺寸,再通过上采样生成对应尺寸的输出。
(2) 使用迁移学习的方法进行 finetune
(3) 使用跳跃结构使得,使得深的粗的语义信息可以结合浅的细的表征信息,产生准确和精细的分割。实验证明了经过端到端、像素到像素训练的卷积网络取得了当前语义分割中的最佳结果。
2 内容介绍
2.1 全卷积网络
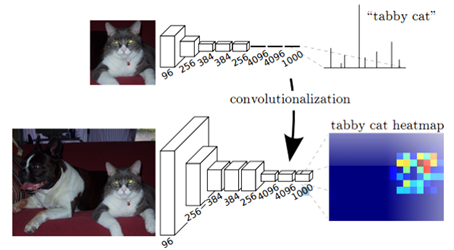
图1 全卷积网络得到heatmap
如图1所示,FCN将AlexNet最后三个全连接层改为卷积层,经过卷积操作得到特征图称之为heatmap。
2.2 上采样
后续的操作为:在上图的基础上,对heatmap 不断upsampling到原始图片大小。比如最后输出的是21张heatmap经过upsampling变为原图大小的图片,最终通过计算在21个通道中每个像素所在位置的最大数值作为该像素的分类结果,实现对原图的语义分割。
为得到dense prediction,作者采用上采样(upsampling) 放大原图像,得到更高分辨率。图像放大几乎都是采用内插值方法,如线性插值、双线性插值等,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素。
2.2.1 双线性插值
双线性插值是有两个变量的插值函数的线性插值扩展,其核心思想是在两个方向分别进行一次线性插值。具体过程如图2所示
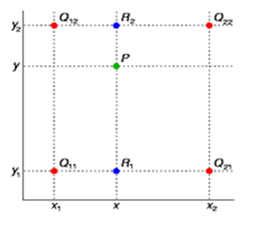
图2 双性插值
假如我们想得到未知函数 f 在点 P = (x, y) 的值,假设我们已知函数 f 在 Q11 = (x1, y1)、Q12 = (x1, y2), Q21 = (x2, y1) 以及 Q22 = (x2, y2) 四个点的值。最常见的情况,f就是一个像素点的像素值。首先在 x 方向进行线性插值,得到
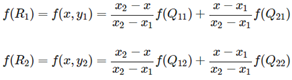
然后在 y 方向进行线性插值,得到
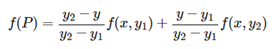
综合起来就是双线性插值最后的结果。
2.2.2 shift-and-stitch
设网络只有一个2x2的max-pooling且stride=2,故下采样因子f=2。如图3所示,左边矩阵为平移因子,经过四次移位得到4个output,分别为图右上处的3*3。接下来,将原始感受野的中心填上来自output的的pixel值,作为网络对原始图片像素类别的prediction,以红色的1为例,它对应(0,0)we位置处的第一个output,最终结果如右下图,完成了较为精准的分类预测。但该方法在实验过程中具有较大的计算开销,作者并未采用。
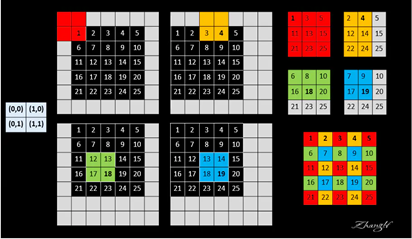
图3 shift and stitch 原理图
注:该部分内容参考自:https://www.jianshu.com/p/e534e2be5d7d
2.3 分割结构
作者设计了FCN-32s,FCN-16s, FCN-8s,且在模型中定义了 “skip” 结构,将深的粗糙的信息与浅的精细的信息相结合,产生准确和精细的分割。如图4所示
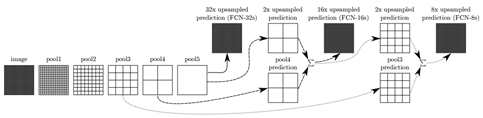
图4 分割架构
以FCN-16s为例:第二行的pool4是在第一行pool4上增加一个1x1的卷积层使其产生一个额外的分类预测,通道数和pool5相同。之后将pool5进行两倍的上采样(双线性插值)。然后将第二行的pool4与2x pool5相加,进行16倍的上采样得到FCN-16s。
3 参数设置
通过动量为0.9的SGD(随机梯度下降)学习网络权重,mini-batch=20,固定学习速率为10-3,10-4和5-5用于FCN-AlexNet, FCN-VGG16,和FCN-GoogLeNet。使用零初始化,但采用的随机初始化既不能产生更好的表现也没有更快的收敛。Dropout应用于原始分类的网络中。最终通过反向传播微调整个网络的所有层。
4 实验分析
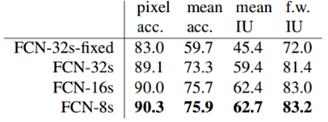
表1 FCNs在PASCAL VOC2011验证集上的结果对比
实验证明:FCN-8s的效果最好;当上采样的步长降低到8,效果提升已经不是很明显了。即收益递减,可以不用融合更多的浅层特征。
ParseNet: Looking Wider to See Better
1. 问题描述
FCN的缺点在于:速度不够快,无法进行实时推理,不能有效地考虑全局上下文信息,而且不容易转换成三维图像。因此本文提出了加入全局信息解决该问题,取得了优于FCN的效果。另外,文章通过实验证明了神经网络实际的感受野要远小于其理论上的感受野,并不足以捕捉到全局语义信息。
2. 内容介绍
模型中用于获取全局语义信息的架构设置如下图5,可直接对网络中任一层进行全局池化得到高维特征图,并利用这个特征图进行分割。
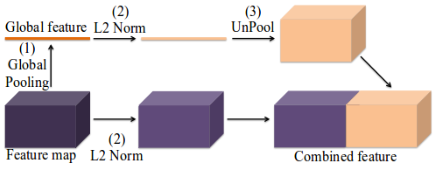
图5 parsenet上下文模块设计
在融合方式上,作者采用了early fusion,早融合的意思是将经过全局池化的全局特征进行反池化(UnPool),得到和原特征图同样大小的特征,进行通道的叠加。另外还有一种融合方式late fusion,将两部分的分类结果以某种方式融合起来,如加权求和。
采用L2 Norm进行正则化处理,是为了解决不同层融合时尺度不同的问题,通常在处理后加入一个scale参数,使用scale控制归一化后特征向量的大小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号