007 Python网络爬虫与信息提取 中国大学排名爬虫
[A] 中国大学排名定向爬虫实例介绍
功能描述
输入:大学排名URL链接
输出:大学排名信息的屏幕输出(排名,大学名称,总分)
技术路线:request,bs4
定向爬虫:仅对输入URL进行爬取,不拓展爬取
程序的结构设计:
步骤1:从网络上获取大学排名网页内容
定义函数:getHTMLText()
步骤2:提取网页内容中信息到合适的额数据结构
定义函数:fillUnivList()
步骤3:利用数据结构展示并输出结果
定义函数:printUnivList()
[B] 中国大学排名定向爬虫实例编写
定义了三个函数,分别用来 1. 获取,2. 保存 和 3. 展示所爬取的结果


import requests from bs4 import BeautifulSoup import bs4 # 中国大学排名 # 1. 从url中获取所需html代码并返回 def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return '' # 2. 从获取到的html代码中解析出所需要的的数据保存在列表中并返回 def fillUnivList(html): ulist = [] sublist = [] soup = BeautifulSoup(html, 'html.parser') text = soup.tbody for tr in soup.find('tbody').children: tds = tr('td') for item in tds: sublist.append(item.string) ulist.append(sublist) sublist = [] return ulist # 3. 根据输入的信息,按要求打印出相应数据 def printUnivList(ulist, start, end): print('{:^10}{:^12}{:^15}'.format('排名', '学校名称', '分数')) for i in range(start, end+1): print('{:^10}{:^12}{:^15}'.format(ulist[i][0], ulist[i][1], ulist[i][2])) # 主程序 def main(): url = 'http://www.gaosan.com/gaokao/299262.html' html = getHTMLText(url) uinfor = fillUnivList(html) printUnivList(uinfor, 5, 30) # 运行主程序 main()
运行结果:
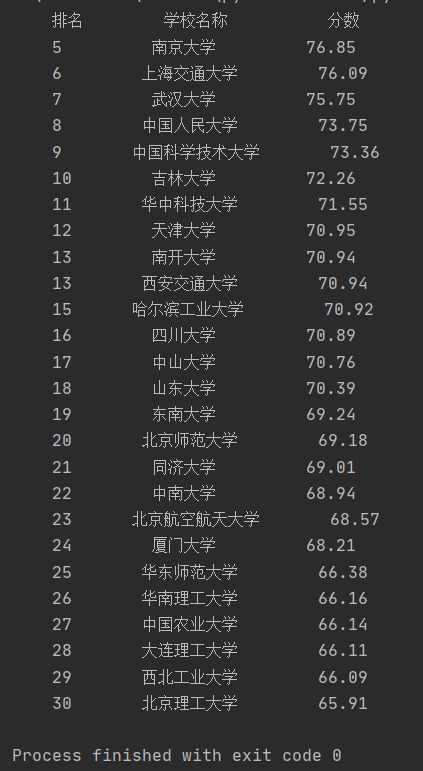
[C] 中国大学排名定向爬虫实例优化
从运行结果可以看出,每行打印的时候虽然都是点击的 tab键 来空格,但是依然没有对齐,这点需要优化
tplt = '{:^10}\t{:^12}\t{:^15}'.format('排名', '学校名称', '分数'))
中文对齐问题的原因:
1. 对齐格式为:
| : | 填充 | 对齐 | 宽度 | , | 精度 | 类型 |
| 引导符号 |
用于填充的单个字符 |
<左对齐>右对齐^居中对齐 |
槽的设定输出宽度 |
数字的千分位分隔符适用于整数和浮点数 |
浮点数小数部分的精度或字符串的最大输出长度 |
证书类型,c,d,o,x,X浮点数类型e,E,f,% |
2. 当中文字符宽度不够时,此阿勇希文字符填充,而中西文字符所占用宽度不同
中文对齐问题的解决:
采用中文字符的空格填充 chr(12288)
tplt = '{0:^10}\t{1:{3}^12}\t{2:^15}'.format('排名', '学校名称', '分数', chr(12288)))
这里{3}^12表示用第三个字符(即中文字符代码)进行填充
改进后的代码:
import requests from bs4 import BeautifulSoup import bs4 # 中国大学排名 # 1. 从url中获取所需html代码并返回 def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return '' # 2. 从获取到的html代码中解析出所需要的的数据保存在列表中并返回 def fillUnivList(html): ulist = [] sublist = [] soup = BeautifulSoup(html, 'html.parser') text = soup.tbody for tr in soup.find('tbody').children: tds = tr('td') for item in tds: sublist.append(item.string) ulist.append(sublist) sublist = [] return ulist # 3. 根据输入的信息,按要求打印出相应数据 def printUnivList(ulist, start, end): tplt = '{0:^10}\t{1:{3}^12}\t{2:^15}' print(tplt.format('排名', '学校名称', '分数', chr(12288))) for i in range(start, end+1): print(tplt.format(ulist[i][0], ulist[i][1], ulist[i][2], chr(12288))) # 主程序 def main(): url = 'http://www.gaosan.com/gaokao/299262.html' html = getHTMLText(url) uinfor = fillUnivList(html) printUnivList(uinfor, 5, 30) # 运行主程序 main()
输出结果:
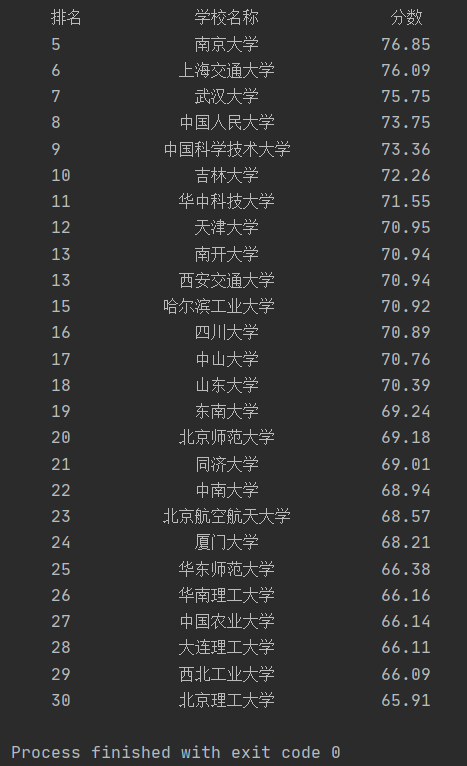

 浙公网安备 33010602011771号
浙公网安备 33010602011771号