文本语义匹配模型
- 现有的文本语义匹配模型
a. Cross-encoder类模型(例如 BERT)将两段文本concat,通过BERT直接输出相似度;优点是简单,可以实现文本深交互,缺点是由于计算量太大,无法在召回阶段使用;
b. Bi-encoder类模型(例如 DPR)将两段文本分别通过模型获得文本表征,最后再通过一个相关性判别函数计算两个文本表征之间的相似度;因为在最后的相关性判别函数时才发生交互,所以可以离线计算候选集合的文本表征,非常适合在工业场景落地,匹配效率极高,缺点是忽略了两个文本之间细粒度的交互特征,匹配质量不佳;
c. Late Interaction类模型(例如 ColBERT)在Bi-encoder的基础上,在最后阶段同时进行了细粒度的表征交互,获得最终的相似度;由于两个塔仍然是分离的,所以计算量很小的同时,还可以获得更准确的相似度,但是由于使用后交互sum操作,无法直接使用ANN进行检索;
d. Attention-based Aggregator类模型(例如 PolyEncoder)每个检索词产生多个不同的表征,再根据检索结果动态地将多个表征集成为最终的检索词表征 ,最后再次计算二者的匹配度。优点是非静态化的表征提升了模型准确率,但是增加了额外运算需要多轮计算。
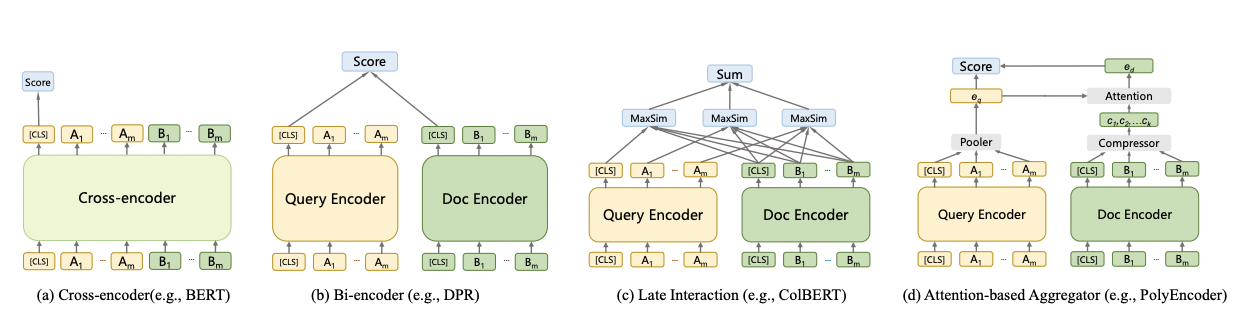
-
什么是poly encoder?基于表征(Representation)文本匹配、信息检索、向量召回的方法总结(用于召回、或者粗排)
a. 动机:介于bi-encoder和cross-encoder之间,在保证了运行时间的情况下,还可以获得更准确的相似度。
i. 基于表示的模型查询和文档缺乏交互,导致语义漂移,推理精度不足
ii. 基于交互的模型不能预计算缓存document编码,推理速率较低
b. step1:传统的 poly encoder 对doc emb采样正常的方法进行落emb,每当来了一个query以后,会对其中每个token都得到一个编码后的表示,假设有N个token,就有N个表示。这里设定一个超参数m,会一开始随机初始化m个向量,c1...cm,对于每个向量ci,和N个token emb做内积然后算softmax,得到N个分数,对N个token emb 加权求和,得到在ci这个角度下的query表示,y_ctxt_i。如此,对于m个ci,我们可以得到m个不同角度的query向量y_ctxt_i,这时候需要将其变为一个向量。
c. step2:上述的步骤不需要doc emb的参与,当计算一个doc和当前query的相关性的时候,使用 doc emb作为attention中的Q,分别和第一步计算出得m个query向量进行内积,经过softmax,得到m个分数,根据这个分数,对第一步的m个query向量y_ctxt_i加权,得到一个结合doc emb注意力获取得到的query emb向量。【同一个query和不同doc计算相似度的时候,使用的query编码是不同的】
d. 得到query向量和doc向量后,正常计算相似度即可。 -
poly encoder比colbert的优势在哪
a. colbert 对于每个query token emb都和每个 doc token emb计算相似度,然后取最大的那个相似度,所以说有n个query token,就会得到n个最大相似度得分,对其相加,作为query和doc的相似分数。
b. 二者都是在基于表示的模型中增加了query和doc的弱交互,增加模型表示能力且不会有太大计算量,且doc端依旧可以预先计算,保证了在线运行的速度。
c. poly encoder更侧重对query emb生成的时候考虑了候选doc的全局语义信息,对于候选doc emb是静态生成的。
d. colbert提出的Late Interaction策略,在编码时不直接生成query和doc的最终表示,而是保存较低层次的序列编码emb,在模型推理的后期,直接在query特征序列和document特征序列上进行MaxSim相似度计算,这样就实现了功能强大且代价极低的细粒度相似性建模。
