流式训练数据-logq纠偏
读透Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations
谷歌最新双塔DNN召回模型——应用于YouTube大规模视频推荐场景
- 当视频素材库的视频数量巨大时(M非常大),计算softmax函数是十分低效且不太现实的,所以一个常用的方法就是对全量的视频集合进行采样,传统的做法是训练所需的负样本从固定的集合中采样得到,但是论文中的做法是对实时流中的数据采样出一个batch,训练的负样本即这个batch中的负样本,但是这样就会引入偏差,即热门的一些视频有更大的可能成为负样本,所以文章对上文中两个embedding向量计算得到的内积进行了logQ修正。
- "但是这样就会引入偏差,即热门的一些视频有更大的可能成为负样本",这句话来解释为什么要做sampling frequency estimation是错误的。 热门的视频本就应该更可能成为负样本(参考importance sampling原理),再看文中的公式,其实是采样的时间间隔小(热门)的样本概率更大。 文中提出这个方法的原因是因为batch方式采样下,item集合和分布是实时随batch变动的,光在单个batch内统计容易引入bias,于是想出了这么个通过时间间隔估计概率的办法,\(p_j\) 是视频 \(j\) 被采样的概率。也就是对热门的样本的相似度加上一个比较小的值,对不热门的相似度加上一个比较大的值(item在batch内出现的概率越高,softmax的输入会在原来的基础上越小,从而降低高频item的预估概率,即热门Item高频出现,需降低对模型的影响)
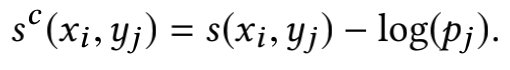
- 核心思想是假设某视频连续两次被采样的平均间隔为B,那么该视频的采样概率即为1/B,如果该商品上一次被采样的时刻为A的话,那么当该商品在时刻t被采样时,可以得到的本次时间间隔就是(t-A),文章提出的算法利用A辅助更新B(之前的平均间隔,和本次间隔做一个加权)
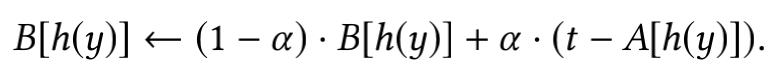

- 文章这里给出的是矩阵的形式,可以认为上式中的函数h()是一个hash函数,他将某个视频的id映射到具体的索引上,然后利用该索引从矩阵B和矩阵A中分别得到该商品对应的平均采样间隔和上一次该商品被采样的时刻,从而进行梯度更新。当B更新完之后,需要对A进行更新(将时刻t赋值给A)。
- Eg, 利用Global step,估计一个Item被两个batch连续命中的平均Step间隔。例如,Item \(i\)在step t, t+10, t+20, t+30命中,则平均每隔10个step命中Item i 一次,即其采样频率为 \(\frac{1}{10}\)。
- 论文中通过一系列推导表明,当t趋于无穷时,估计采样间隔无限趋向于真实采样间隔,数组A/B要保存在Parameter Servers上,随神经网络的异步随机梯度下降训练一起更新,效率高。
# Identify duplicate gids product_id
fc_gids = FeatureColumnDense('fc_line_id_gid', 1, tf.int64) # [bs, 1]
gids = fc_gids.get_tensor()
g_duplicate_matrix = tf.equal(gids, tf.transpose(gids)) # [bs, bs], 如果第i个样本和第j个样本是一样的gid(product_id)就是true
g_duplicate_cnts = tf.reduce_sum(tf.cast(g_duplicate_matrix, tf.float32), axis=1, keepdims=True) # 每个样本在同batch内有多少一样的
# 这样统计会有重复的,a样本和b样本的会重复记录,但
tf.summary.histogram("duplicate_groups_per_row", g_duplicate_cnts - 1.0) # 减去自己本身
tf.summary.scalar("duplicate_groups_mean", tf.reduce_mean(g_duplicate_cnts) - 1.0)
# Identify duplicate users
fc_uids = FeatureColumnDense('fc_line_id_uid', 1, tf.int64)
uids = fc_uids.get_tensor()
u_duplicate_matrix = tf.equal(uids, tf.transpose(uids))
u_duplicate_cnts = tf.reduce_sum(tf.cast(u_duplicate_matrix, tf.float32), axis=1, keepdims=True)
tf.summary.histogram("duplicate_quries_per_row", u_duplicate_cnts - 1.0)
tf.summary.scalar("duplicate_quries_mean", tf.reduce_mean(u_duplicate_cnts) - 1.0)
pid_emb = fc_vec_dict['fc_ecom_video_product_ids'] # MID的emb, [bs, 64]
pid_emb = tf.nn.l2_normalize(pid_emb,axis=-1)
pid_mask = tf.matmul(pid_emb, pid_emb,transpose_b=True) # [bs, bs]
pid_mask = tf.cast(pid_mask > 0.999, tf.float32) # [bs, bs] 是1就代表是正样本,是0代表不是
p_duplicate_cnts = tf.reduce_sum(tf.cast(pid_mask, tf.float32), axis=1, keepdims=True) # 每个样本在同batch内有多少一样的
# 这样统计会有重复的,a样本和b样本的会重复记录,但
tf.summary.histogram("duplicate_product_per_row", p_duplicate_cnts - 1.0) # 减去自己本身
tf.summary.scalar("duplicate_product_mean", tf.reduce_mean(p_duplicate_cnts) - 1.0)
is_ecom_video_from_sort = fc_vec_dict['fc_is_ecom_video_from_sort_dense']
is_have_video = tf.reduce_sum(is_ecom_video_from_sort, axis=1, keepdims=True) # 是否有视频
vid_emb = fc_vec_dict[2] # MID的emb, [bs, 64]
vid_emb = tf.nn.l2_normalize(vid_emb,axis=-1)
vid_mask = tf.matmul(vid_emb, vid_emb,transpose_b=True) # [bs, bs]
vid_mask = tf.cast(vid_mask > 0.999, tf.float32) # [bs, bs] 是1就代表是正样本,是0代表不是
v_duplicate_cnts = tf.reduce_sum(tf.cast(vid_mask, tf.float32), axis=1, keepdims=True) # 每个样本在同batch内有多少一样的
# 这样统计会有重复的,a样本和b样本的会重复记录,但
tf.summary.histogram("duplicate_videos_per_row", v_duplicate_cnts - is_have_video) # 减去自己本身
tf.summary.scalar("duplicate_videos_mean", tf.reduce_mean(v_duplicate_cnts - is_have_video))
## Add streaming frequence estimation
assign_optimizer_hit = optimizers.Assign(low=-1.0, high=-1.0)
assign_optimizer_delta = optimizers.Assign(low=config.MAX_DELTA, high=config.MAX_DELTA)
product_slot_id = VEC_FC_V2_NAME['fc_ecom_video_product_ids']
# 对product进行纠偏,我们的2是video_id, 我们应该换成fc_ecom_video_product_ids
last_hit_slice = fc_dict['fc_ecom_video_product_ids'].feature_slot.add_slice(1, optimizer=assign_optimizer_hit)
last_hit = fc_dict['fc_ecom_video_product_ids'].get_vector(last_hit_slice) # 上次采样时刻 A
delta_slice = fc_dict['fc_ecom_video_product_ids'].feature_slot.add_slice(1, optimizer=assign_optimizer_delta)
delta = fc_dict['fc_ecom_video_product_ids'].get_vector(delta_slice) # 平均采样间隔 B
# Add monitoring stats
tf.summary.histogram('last_hit_histogram', last_hit)
tf.summary.scalar('last_hit_mean', tf.reduce_mean(last_hit))
tf.summary.histogram('delta_histogram', delta)
tf.summary.scalar('delta_mean', tf.reduce_mean(delta))
new_last_hit = tf.ones_like(last_hit)
new_delta = delta
item_weights = tf.ones_like(delta) # 纠偏概率,log(delta)=log(B)
@tf.custom_gradient
def update_value_and_gradient(x, y): # 自定义的梯度, 两个返回值,一个是正向传播过程中函数的输出值,另一个是反向传播过程中的梯度值。
def grad(dy):
return y, None
return y, grad # 也就是调用update_value_and_gradient的时候,正向返回值是y,对x进行的梯度更新值也是y,对y的梯度更新值是0
if S.is_compiling_training():
new_last_hit = new_last_hit * tf.cast(M.get_global_step(), tf.float32) # 当前全局步数 t
recent_delta = new_last_hit - last_hit # 减去上次的步数 A ,得 t-A,本次的时间间隔
if config.COUNT_DUPLICATE_HITS: # 因为一个物品在一个batch中可能出现多次,就会在一个时间t被多次更新,所以除一下,次数,多次更新就会被乘回来了
recent_delta = recent_delta / g_duplicate_cnts
is_sharp_change = tf.greater(recent_delta, config.SHARP_CHANGE_RATIO * delta) # 本次的时间间隔是否比 20倍的平均间隔还要大
recent_delta = tf.minimum(config.MAX_DELTA, tf.maximum(recent_delta, config.MIN_DELTA)) # 防止本次时间间隔太小+防止本次间隔太大
new_delta = tf.where(is_sharp_change, recent_delta, delta * (1.0 - config.LEARNING_RATE) + recent_delta * config.LEARNING_RATE) # 如果变化太大(太久没被点击了)就用本次的;否则就按照公式中的考虑过往平均进行加权 -> 得到新的平均时间间隔 B
new_delta = tf.minimum(config.MAX_DELTA, tf.maximum(new_delta, config.MIN_DELTA)) # 防止新的时间间隔太小 or 太大
new_last_hit = update_value_and_gradient(last_hit, new_last_hit) # 对上次采样时刻A更新: 梯度是此次时间步数
new_delta = update_value_and_gradient(delta, new_delta) # 对平均时间间隔B更新:梯度是此次的时间间隔
item_weights = tf.log(new_delta / config.MAX_DELTA) * config.EXPONENT # 根据新的时间间隔得到此次的纠偏权重 log(B)
## Add monitoring stats
tf.summary.histogram('new_delta_histogram', tf.minimum(new_delta, 6000.0))
tf.summary.histogram('in_batch_new_delta', recent_delta)
tf.summary.scalar('sail_global_step', M.get_global_step())
tf.summary.histogram('updated_hit_histogram', new_last_hit)
tf.summary.histogram('item_weights', item_weights)
