胶囊网络是什么
胶囊和神经元
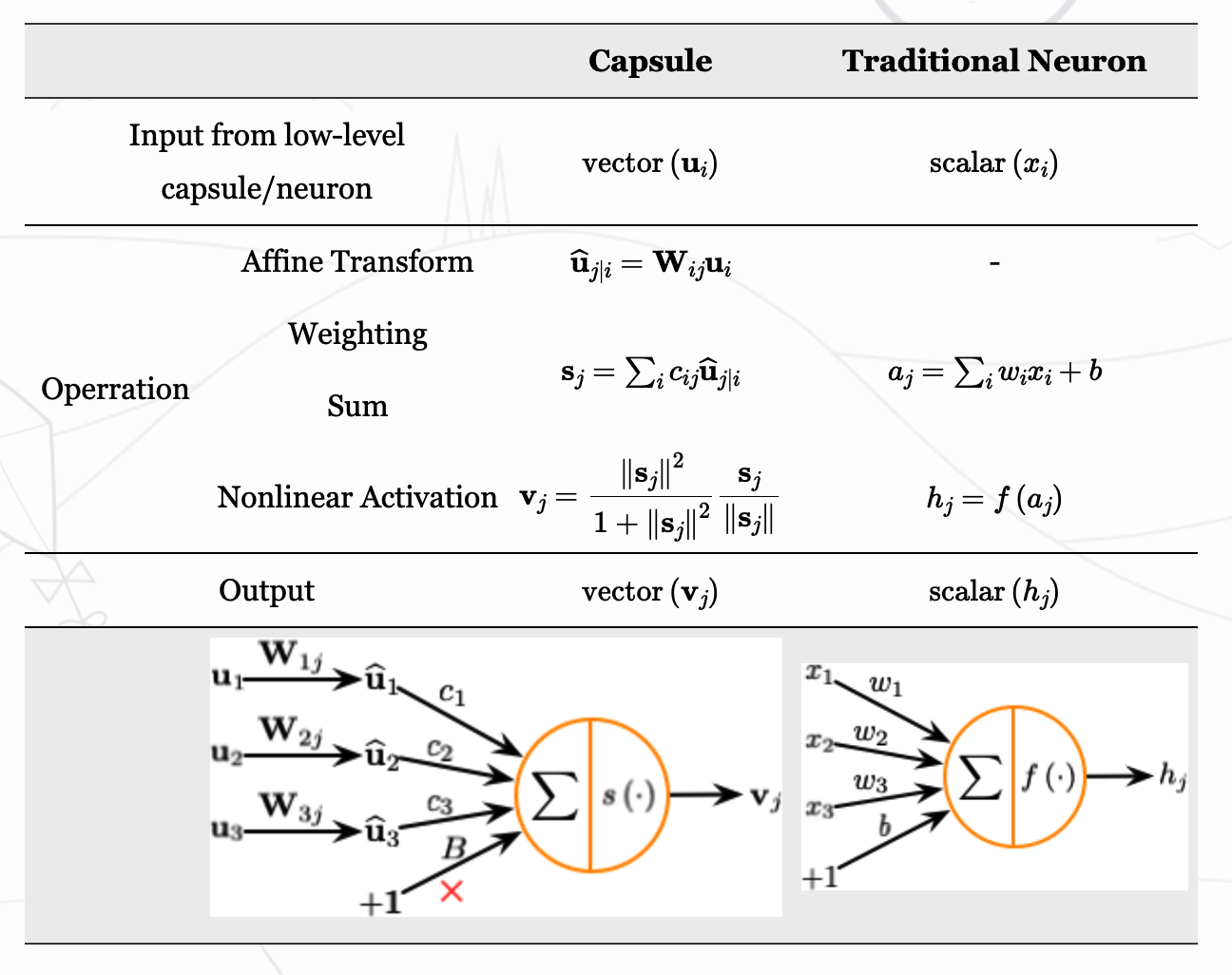
首先总结下胶囊和神经元的不同:
- 人工神经元的计算包括三步:
- (1) 输入标量加权
- (2) 加权后的标量相加
- (3) 求和得到的标量到输出标量的非线性变换
- 胶囊可以理解为这三个步骤的向量版本,同时增加了对输入的仿射变换
- (1) 输入向量的矩阵乘法:胶囊接受的输入向量编码了低层胶囊检测出的相应对象的概率,向量的方向编码了检测出的对象的一些内部状态。接着将这些向量乘以相应的权重矩阵,编码了低层特征(例如:眼睛、嘴巴和鼻子)和高层特征(例如:面部)之间的空间关系和其他重要关系。
- (2) 对向量进行加权:这个步骤同人造神经元对应的步骤(1)类似,但神经元的权重是通过反向传播学习的,而胶囊则使用动态路由。
- (3) 加权后的向量相加:这个步骤同人造神经元对应的步骤(2)类似。
- (4) 求和得到的向量到输出向量的非线性变换:胶囊神经网络的非线性激活函数接受一个向量,然后在不改变方向的前提下,将其长度压缩到 1 以下。右边的部分将向量缩小(scale)成单位长度,左边的部分是进一步缩小(个人觉得可以解释为加入非线性),采用这个函数的目的是为了激活这个胶囊。之前神经元输出是一个标量,一个值,所以用sigmoid或者tanh来做非线性化很好实现,而胶囊网络输出是一个向量,因此需要用一个处理向量的函数来激活。输出可以被解释为给定特征被识别到的概率。
这些向量我们用权值矩阵W来编码底层特征之间重要的空间以及其他关系。举例来说,矩阵W3j有可能编码鼻子和脸的关系:鼻子在脸的中央,脸的大小是鼻子的10倍并且脸的朝向等于鼻子的朝向,因为他们在同一平面上。W1j和W2j同理。在和这些矩阵相乘后,我们得到的是高层信息中的位置信息。具体来说,u1(hat)代表由眼睛位置得知的脸的位置,u2(hat)代表通过嘴巴位置得知的脸的位置,u3(hat)代表由鼻子位置得知的脸的位置。如果三个低层特征预测出的脸都在相同位置,那这里一定是有一张脸。

动态路由
胶囊网络使用动态路由算法进行训练,也就是上述的第(2)(3)(4)步,算法过程如下:

- 第1行表示算法的输入:低层中所有胶囊的输出(经过仿射变换) ,以及路由的迭代次数 。
- 第2行的是一个临时变量,其值在迭代过程中更新,算法运行完毕后其值被保存在中。
- 第3行表示如下步骤将会被重复次。
- 第4行,利用计算低层胶囊的权重向量。 确保了所有权重为非负数,且和为一,。第一次迭代后,所有系数的值相等,随着算法的继续,这些均匀分布将发生改变。
- 第 5 行计算经前一步确定的路由系数加权后的输入向量的线性组合。该步缩小输入向量并将他们相加,得到输出向量。
- 第 6 行对前一步的输出向量应用非线性函数。这确保了向量的方向被保留下来,而长度被限制在 1 以下。
- 第 7 行通过观测低层和高层的胶囊,根据公式更新相应的权重。胶囊的当前输出与从低层胶囊处接收到的输入进行点积,再加上旧的权重作为新的权重。点积检测胶囊输入和输出之间的相似性,即如果两个向量是同方向得到的内积就是正数,增加,如果是反方向的2个向量,内积结果为负数,减小。
- 重复次,计算出所有高层胶囊的输出,并确立路由权重。之后正向传导就可以推进到更高层的网络。
也可以借助K-means的思想让大家更好的理解动态路由,直接将动态路由理解为一个软化的k-means,在K-means中直接将点划分到最近的簇,而动态路由里面则是通过softmax获取相似度,成比例地将这点分到各个簇中(line4、5)。假设低层的胶囊输出为,高层的胶囊输出为,如果按上面的思路,初始的时候会对进行平均来获取初始的,这样的话所有的是一样的,这显然不合理。其实动态路由可以看作是卷积+K-means,这里说卷积并不是指卷积操作,而是CNN中通过卷积来获取某个特征。
动态路由中有一步 ,有个,引入 后可以这么看动态路由和K-means:(1)K-means中开始时随机初始化聚类中心来代表不同的簇,而动态路由随机初始化来代表不同的特征;(2)K-means是直接将一个样本划分到某个簇中,而动态路由是获取在不同特征上的投影。
也可以理解动态路由是一种和attention机制很像的算法,都是对输入向量进行加权,得到一堆输出向量。不同之处在于,动态路由是非监督自适应的过程,并且是直接和输出进行对比。我个人认为动态路由是attention机制的另一种实现方式,并且更加适合用于胶囊网络。
注意:动态路由并不能完全替代反向传播。转换矩阵W仍然使用成本函数通过反向传播训练。我们只是使用动态路由来计算胶囊的输出。通过计算cij来量化胶囊与其父胶囊之间的连接。这个值很重要,但生命周期很短暂。对于每一个数据点,在进行动态路由计算之前,我们都将它重新初始化为0。在计算胶囊输出时,无论是训练或测试,都需要重新做动态路由计算。
胶囊网络整体结构
结合二者去看~
初探胶囊网络(Capsule Network)四:胶囊网络结构
胶囊网络 (Capsule Network)
感觉capsule还是在CNN基础上的一个改进,只是将max pooling换成了动态寻路这种相对而言更合理的方法(减少参数),CNN中的最大池化处理了平移变化。如果一个特征稍微移动一下,只要它仍然在池化窗口中,就依然可以被检测到。然而,这种方法只保留最大的特征(最主要的)并且丢弃其他的特征,而胶囊则保留前一层的特征加权总和。因此,它更适合于检测重叠特征。例如,在手写字体中检测多个重叠的数字。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!