Notes on Weight Initialization for Deep Neural Networks
Notes on Weight Initialization for Deep Neural Networks
Motivation
神经网络通常会包含很多次连续的 matrix 和 vector 之间的乘法,即 \(a * x\) 。很多次连续的乘法后,会导致结果向量的值要么很大,要么被减小为0。我们可以通过除以了数值 \(a\) (也称 scaling_factor,缩放因子)来将结果向量的值缩放到一个正常的范围。
input = x
output = input
for layer in network_layers:
output = activation(output * layer.weights + layer.bias)
如上面的代码所示,在神经网络中的训练过程中,涉及很多操作,最常见的就是乘法。通常乘法发生在矩阵之间,在深度网络的情况下,我们要经过更长的此类乘法运算序列。
研究 Sequence of Multiplications
我们先随机初始化一个 input vector \(x\) 和一个随机矩阵 \(a\)。注意,随机初始化的值是都从正态分布(均值为0,方差为1)\(N(0,1)\) 中采样得到的。
我们将向量 \(x\) 和矩阵 \(a\) 相乘100次(模拟100层的神经网络),然后看看会发生什么。注意,为了简化,我们没有使用任何的激活函数。
x = torch.randn(512)
a = torch.randn(512, 512)
for i in range(100):
x = a @ x
x.mean(),x.std()
输出:
(tensor(nan), tensor(nan))
可以看到,x具有一个很大的数值维度,到达了nan!仿佛就像打雪仗一样,我们每乘以一个矩阵\(a\),\(x\)的数值维度就会增加,最终 \(a*x\) 的平均值超出了python中numbers的上限。
A first intuitive solution
直觉上来看,\(a\) 和 \(x\) 的乘积是变得越来越大的,那么也许我们在最开始减小矩阵 \(a\) 的数值维度是不是会有效果呢?如果 \(a\) 变小了,那么\(a * x\) 的数值维度也不会猛增了。
因此,我们对于矩阵 \(a\) 中的每一个元素都除以一个缩放因子 100,然后再重复我们的100次乘法。
scaling_factor = 100
x = torch.randn(512)
a = torch.randn(512,512) / scaling_factor
for i in range(100):
x = a @ x
x.mean(), x.std()
输出:
(tensor(0.), tensor(0.))
看起来我们确实解决了维度爆炸的问题,但是却引入了另一个问题:输出现在消失到 0 了 !
Xavier Initialization
我们看到缩放因子取值100,没能达到一个很好的效果。它将乘积的结果减小到了 0 。当然,如果不缩放,乘积结果是无穷,缩放100,乘积结果是0,看起来我们的缩放因子恰恰在0到100之间的某个值。这也是 Xavier initialization 做的事情:帮助我们找到了一个合适的缩放因子!
Xavier initialization 建议我们使用 \(\sqrt{n_{in}}\) 作为缩放因子,\(n_{in}\) 是矩阵输入的数量(或者是与矩阵相乘的向量的维度)。
在我们的例子中,矩阵 \(a\) 输入的数量是512,因此缩放因子我们选取\(\sqrt{512}\) 。换句话说,我们将矩阵 a 除以\(\sqrt{512}\) ,这样我们就不会看到数值爆炸或消失的情形了。
让我们看看Xavier init的效果吧!
import math
scaling_factor = math.sqrt(512)
x = torch.randn(512)
a = torch.randn(512,512) / scaling_factor
for i in range(100):
x = a @ x
x.mean(), x.std()
输出:
(tensor(0.0429), tensor(0.9888))
乘积的数值维度没有消失!事实上,我们的输出结果有一个很不错的mean(接近于0)和标准差(接近于1)。可以回想起,我们的输入向量 \(x\) 也是从这样一个分部采用得到的!也就是说,Xavier init的策略,可以使得我们维持 inputs 的分布!这是我们乐于看到的,这样的话,我们可以进行很长的乘法序列计算,也不会改变数据分布,这允许我们去训练真正的deep neural network。
注意,Xavier init 对于我们的case 来说是足够有效了,因为我们没有使用任何的激活函数,如果我们使用了像 ReLu 这样的激活函数,那么 Kaiming Initialization 会更加有效。
那么接下来我们来看一看\(\sqrt{512}\) 有什么特别的?
Why (√512)? | Intuition
我们着重关注我们实验代码中的这一行:
x = a @ x
可以看出,我们从头到尾都没有改变矩阵 \(a\),因此我们结果向量出现问题的导火索只能是一直被更新的 \(x\)。为了更清楚地解释这个现象,我们用 \(y\) 表示 \(a\) 和 \(x\) 的乘积。
在我们的实验中,\(a\) 是一个 512×512的矩阵,\(x\) 是一个512维的向量,因此 \(y\) 也是一个512维的向量。
向量 \(y\) 中的一个元素 \(y_i\) 计算公式如下:
即,向量 \(y\) 中的第 \(i\) 个元素是用向量 \(x\) 对矩阵\(a\) 中的第 \(i\) 行的各个元素进行计算加权和得到的。
我们 看出,为了计算 \(y\) 中的一个元素,我们把 \(a\) 中的一个元素和 \(x\) 中的一个元素的乘积结果进行了512次加法,这样一个元素的均值和方差是什么呢?
正如我们稍后证明的那样,只要 \(a\) 中的元素和 \(x\) 中的元素是独立的(就像在我们实验中的那样;一个不影响另一个),那么 \(y\) 中的每一个元素都是从 \(N(0, 512)\) 中采样得到的!这也可以从下面的实验中看到,为了避免one-off errors,我们重复了10000次实验,取 \(y_i\) 的均值。
mean, var = 0.0, 0.0
n_iter = 10000
n_dim = 512
ys = []
for i in range(n_iter):
# a_i * x
x = torch.randn(n_dim)
a = torch.randn(n_dim) #just like one row of a
y = a@x # y_i
mean += y.item()
ys.append(y.item())
mean/n_iter, torch.tensor(ys).var(), torch.tensor(ys).std()
# outputs:
# (-0.13198307995796205, tensor(513.4638), tensor(22.6597))
换而言之,\(y\) 中的每个元素都是从一个不稳定的分布中采样得到的,这之所以会发生,是因为我们相加了512个乘积结果,每个乘积结果都是两个从\(N(0,1)\) 采样的元素的乘积。我们如果继续将\(y\) 中的元素作为输入和矩阵\(a\)相乘,事情只会越来越糟。
现在,如果我们将权重矩阵\(a\)的值除以一个缩放因子,\(math.sqrt(512)\) ,那么相当于矩阵 \(a\) 中的每个元素是从分布 \(N(0, 1/512)\) 中采样得到的。
如此而来,我们的乘积结果 \(y\) 的分布就会变成和 \(x\) 一样的 \(N(0,1)\),这样我们进行多少次乘法都可以了~ 这和我们之前想的一样,对矩阵 \(a\) 进行缩放确实会解决我们的问题,Xavier initialization 帮我们找到了合适的缩放因子\(\sqrt{512}\) ,而不是我们最初使用的 100。
mean, var = 0.0, 0.0
n_iter = 10000
n_dim = 512
ys = []
for i in range(n_iter):
x = torch.randn(n_dim)
a = torch.randn(n_dim) / math.sqrt(n_dim) #just like one row of a
y = a@x
mean += y.item()
ys.append(y.item())
mean/n_iter, torch.tensor(ys).var(), torch.tensor(ys).std()
# outputs:
# (-0.00671036799326539, tensor(1.0186), tensor(1.0092))
# y 中的每个元素的均值是0,方差是1.
确实,each element of y (and y as a whole) now has mean 0 and variance/std 1. We can thus keep multiplying the output y with a repeatedly, without worrying about things changing a lot.
Why (√512)? | Proofs
在我们的实验代码中,\(y\) 中的元素计算公式如下:
1. Proof that Y∼N(0,512),不缩放时
我们令 \(A, X\) 和 \(Y\) 表示 \(a, x\) 和 \(y\) 采样的随机变量。我们知道 \(Y\) 中一个元素是通过将\(A\) 和 \(X\) 中的512个元素彼此相乘而得到的。即,我们从\(A\) 中采样512个元素,再从 \(X\) 中采样512个元素,逐元素相乘,再相加。
and \(Y=\sum_{k=0}^{511}{A*X}\)
让我们看看 \(Y\) 的均值是什么,是不是我们预想中的 0?
1.1 Expectation (Mean) of Y
(\(A\) 和 \(X\) 是独立的, 并且 \(E[A] = E[X] = 0\) )
性质:当 E(XY)=E(X)E(Y) 成立时,随机变量X和Y的协方差为0,又称它们不相关。特别的,当两个随机变量独立时,它们协方差(若存在)为0。
1.2 Variance of Y
(A and X are independent)
性质:Reference for the variance property
![]()
而 \(Y=\sum_{k=0}^{511}{A*X}\)
因此,
性质:注,因为 X 和 Y 独立,所以其协方差为0.
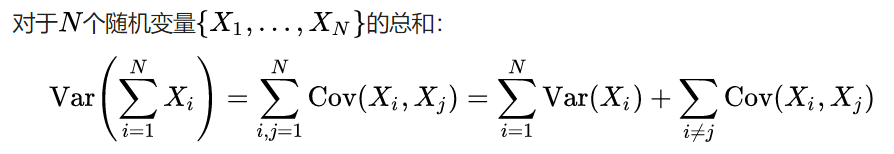
证明完毕,\(Y\) 确实是从 \(N(0, 512)\) 中采样得到,这是一件很糟糕的事情,因为\(Y\) 的变化太大了!下面复制了之前的实验结果以回顾
mean, var = 0.0, 0.0
n_iter = 10000
n_dim = 512
ys = []
for i in range(n_iter):
x = torch.randn(n_dim)
a = torch.randn(n_dim) #just like one row of a
y = a@x
mean += y.item()
ys.append(y.item())
mean/n_iter, torch.tensor(ys).var()
# (-0.10872242888212204, tensor(514.2963))
# 可以看出Y是服从N(0, 512)分布的~
2. Proof that Y is ∼N(0,1) when A∼N(0,1/512),缩放时
\(Y=\sum_{k=0}^{511}{A*X}\)
下面证明为什么当 A 除以一个缩放因子 \(\sqrt{512}\) 后,\(Y\) 就相当于从 \(N(0,1)\) 中采样了。
首先因为性质 \(Var(aX)=a^2 Var(X)\),所以 \(Var(A)=1/512\)。
2.1 Expectation (Mean) of Y
\(E(aX+bY)=aE(X)+bE(Y)\)
2.2 Variance of Y
而 \(Y=\sum_{k=0}^{511}{A*X}\)
因此,
即,\(Y \sim N(0,1)\) 得证!其实是 \(Y \sim N(0,Var(X))\),可以看到计算输出 Y 和输入 X 是一样的分布。
mean, var = 0.0, 0.0
n_iter = 10000
n_dim = 512
ys = []
for i in range(n_iter):
x = torch.randn(n_dim)
a = torch.randn(n_dim) / math.sqrt(n_dim) #just like one row of a
y = a@x
mean += y.item()
ys.append(y.item())
mean/n_iter, torch.tensor(ys).var(), torch.tensor(ys).std()
# (-0.008042885749042035, tensor(0.9856), tensor(0.9928))
# 可以看出,确实Y是服从N(0,1)分布的~
那么万事俱备!\(y\) 中的每个元素都是从一个很棒的分布中采样得到的,现在我们再复制一下我们最开始的代码:
scaling_factor = math.sqrt(512)
x = torch.randn(512)
a = torch.randn(512,512) / scaling_factor
for i in range(100):
x = a @ x
x.mean(), x.std()
# (tensor(0.0121), tensor(1.1693))
# 哪怕乘100次以后,我们的x依然还是服从N(0,1)分布!
Summary
长序列乘法是神经网络中的核心操作,我们可以看出,如果没有恰当的初始化,从一个很好的分布(\(N(0,1)\))中采样的输入将会消失或者爆炸。
通过对权重矩阵除以一个缩放因子 \(\sqrt{num_{inputs}}\),即Xavier Initialization,帮助我们确保连续乘法后的每一个输出元素依然服从一个很好的分布!
注意,虽然 Xavier 初始化使我们走上了正确的道路,但当使用 Relu 作为网络中乘法之间的激活(非线性)函数时,Kaiming Initialization 会提供最佳的缩放因子!
