神经网络的一些技巧
关于训练神经网路的诸多技巧Tricks(完全总结版)
fast ai 课程
1. 不平衡训练集
The Impact of Imbalanced Training Data for CNN
- 不平衡训练集会对结果造成很大的负面影响,而训练集在平衡的情况下,能够达到最好的performance,一个解决方法:oversampling是一个很好的效的方式来解决不平衡训练集的问题。
- oversampling:对于每一类,随机选出一些图片进行复制,直到该类图片数量与占最大比重的图片相等。
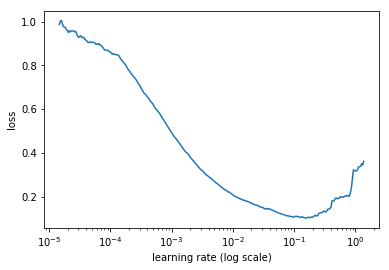
2. 寻找合适的lr!绘制loss-lr曲线,选取合适的lr!
torch.optim.lr_scheduler:调整学习率
神贴!find_lr
def find_lr(init_value = 1e-8, final_value=10., beta = 0.98):
num = len(trn_loader)-1
mult = (final_value / init_value) ** (1/num)
lr = init_value
optimizer.param_groups[0]['lr'] = lr
avg_loss = 0.
best_loss = 0.
batch_num = 0
losses = []
log_lrs = []
for data in trn_loader:
batch_num += 1
#As before, get the loss for this mini-batch of inputs/outputs
inputs,labels = data
inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
#Compute the smoothed loss
avg_loss = beta * avg_loss + (1-beta) *loss.data[0]
smoothed_loss = avg_loss / (1 - beta**batch_num)
#Stop if the loss is exploding
if batch_num > 1 and smoothed_loss > 4 * best_loss:
return log_lrs, losses
#Record the best loss
if smoothed_loss < best_loss or batch_num==1:
best_loss = smoothed_loss
#Store the values
losses.append(smoothed_loss)
log_lrs.append(math.log10(lr))
#Do the SGD step
loss.backward()
optimizer.step()
#Update the lr for the next step
lr *= mult
optimizer.param_groups[0]['lr'] = lr
return log_lrs, losses
net = SimpleNeuralNet(28*28,100,10)
optimizer = optim.SGD(net.parameters(),lr=1e-1)
criterion = F.nll_loss
logs,losses = find_lr()
plt.plot(logs[10:-5],losses[10:-5])
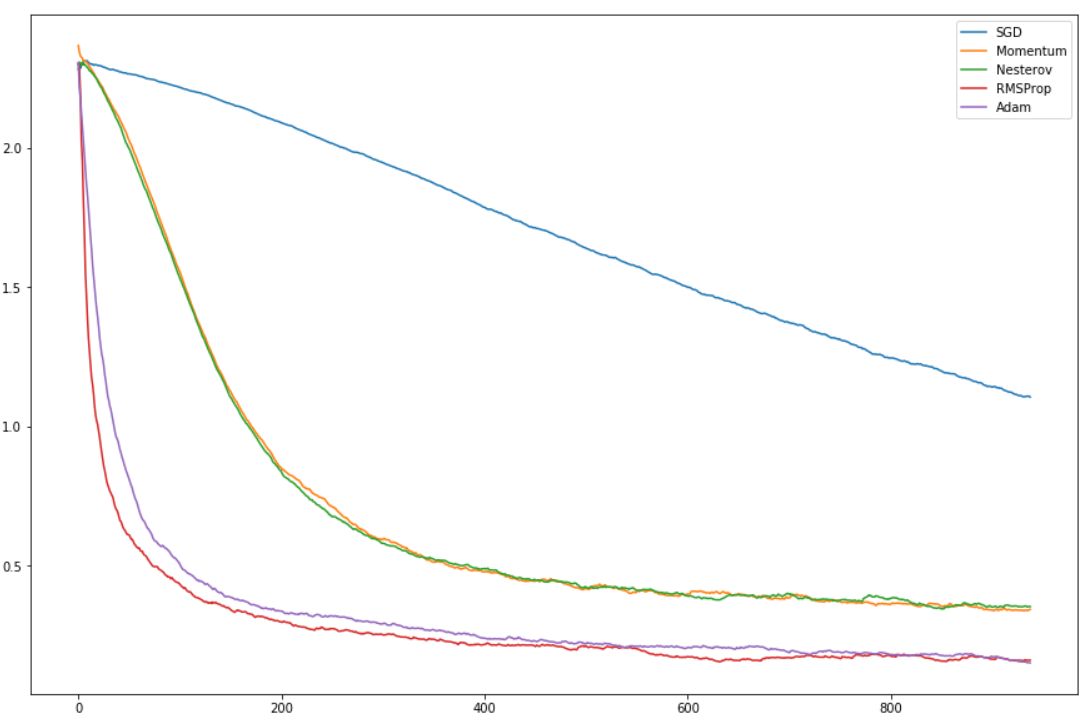
3. SGD 梯度下降的变种们:Momentum、Nesterov、RMS Prop、Adam
SGD Variants
用上面的find_lr对不同的优化器画图,可以看到不同优化器的效果~
4. 1cycle 策略!
- By training with high learning rates we can reach a model that gets 93% accuracy in 70 epochs which is less than 7k iterations (as opposed to the 64k iterations which made roughly 360 epochs in the original paper).
使用高学习率
- 之前我们说使用high learning rates,在训练之前使用find_lr绘制losses against the learning rates曲线,在loss到达最低点前选择一个lr。
- 1cycle 策略:用两个等长的步骤做一个循环,一个步骤从较低的学习率到较高的学习率,然后再回到最小学习率。最大值应该是刚刚使用“学习率查找器”选择的值,而较低的值可以低十倍。并且这个循环的长度应小于总共的epochs的数目,并且在第二个步骤的时候,我们允许lr比我们规定的最小值要小。
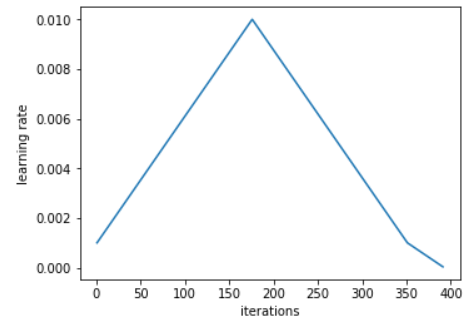
- starting slower 慢启动的想法就是如此,用一个较小的值去warm-up训练,和我们第一个步骤是一致的。不要直接用一个比较高的lr,应该线性缓慢的到达,并且用一样多的时间再下降。
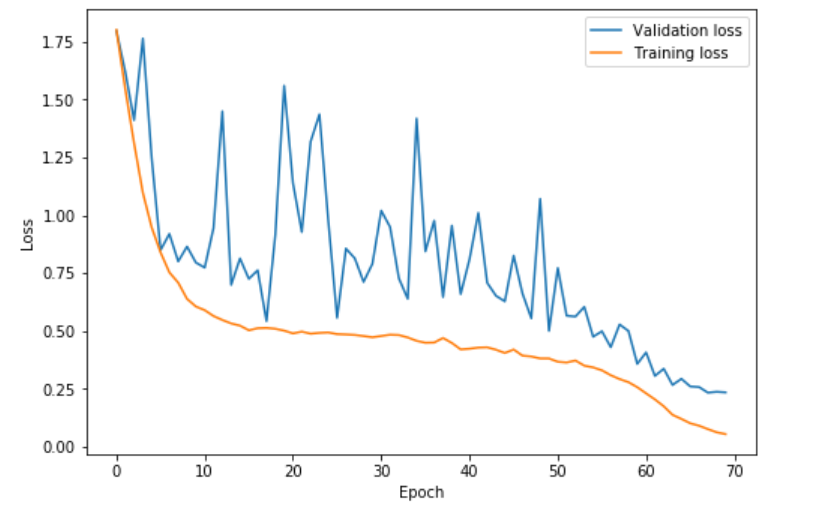
- 在循环的中间,高学习率将作为正则化方法,并防止网络过度拟合,它将防止模型落在损失函数的陡峭区域,而是希望找到更平坦的最小值。在获得高学习率的过程中,我们看不到损失或准确性方面的实质性改善,并且验证损失有时会非常高,但是当最终最终降低学习率时,我们看到了这样做的所有好处。
- 在上图中,学习率从第0到41阶段的0.08上升到0.8,在第41和82阶段之间回到0.08,然后在最后几个阶段达到0.08的百分之一。我们可以看到在循环的高学习率部分(主要是20到60阶段),验证损失变得更加不稳定,但重要的是平均而言,训练损失与验证损失之间的距离不会增加。当学习率消失时,我们才真正开始过拟合。
- 令人惊讶的是,应用此策略甚至允许我们选择更大的最大学习率,接近使用“学习率查找器”时绘制得到的最小值。
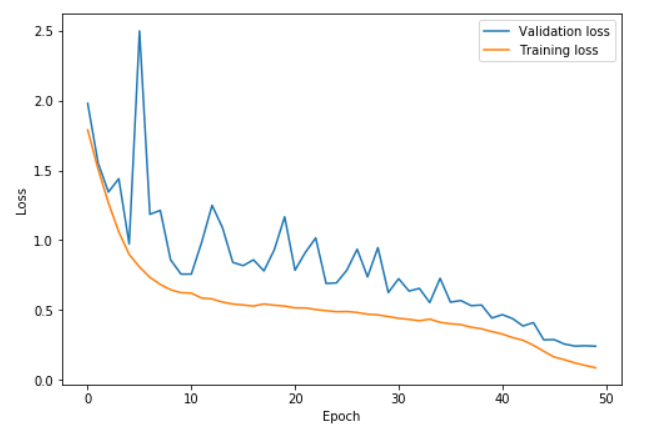
- 在此图中,学习率从第0阶段到22.5阶段从0.15上升到3,在第22.5到45阶段之间回到0.15,然后在最后几个阶段中降低到0.15的百分之一。有了很高的学习率,我们就可以更快地学习并防止过度拟合。直到我们学习率降为0之前,验证损失和训练损失之间的差异一直保持极低的水平。这就是“ super convergence” 超级收敛现象!
- 值得尝试较长的周期,然后再降低学习速度,因为长时间的热身似乎有帮助。使用这种技术,我们可以在cifar10上训练resnet-56仅用50个epoch就可以达到92.3%的准确度。如果循环为70个epoch的话,我们的准确率达到93%。
- 当然,如果我们的循环周期太短,annihilation 时间过长(lr循环完了后,lr都是一直在下降),如下图,我们的两个步骤在epoch 42结束,剩下的训练学习率逐渐降低。验证损失停止减少,导致越来越大的过拟合,并且准确性几乎没有提高。
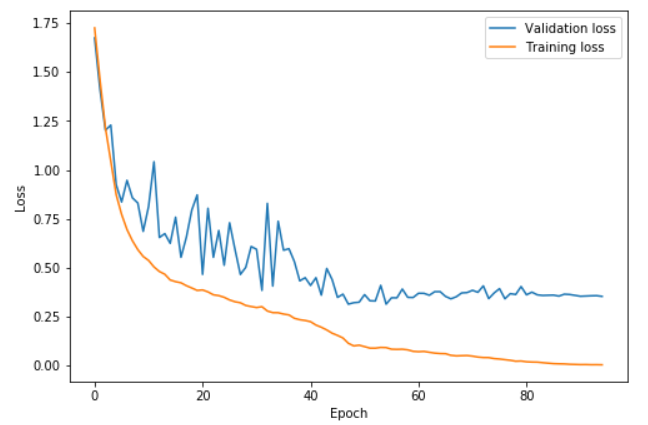
周期性动量
- 在实验中发现,随着学习率的提高,降低 momentum 可以带来更好的结果。这和直觉相符,即在第一部分训练中,我们希望SGD能够迅速朝新方向寻找平坦区域,因此需要给新梯度更大的权重。在实践中,他建议选择两个值,例如0.85和0.95,并在我们提高学习率时从较高的值减小到较低的值,然后在学习率下降时再返回较高的momentum 。
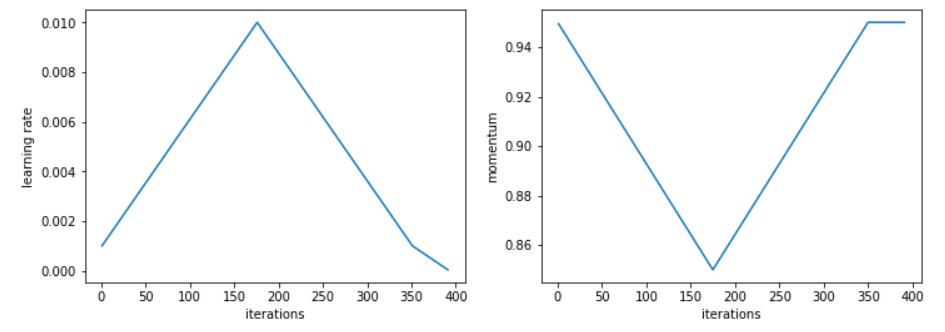
- 在整个训练过程中选择的固定的动量最佳值可以给我们相同的最终结果,但是使用周期性动量消除了尝试多个值并运行多个完整周期的麻烦,从而节省了宝贵的时间。
- 即使使用周期性动量总是可以得到更好的结果,但博客的作者没有发现使用恒定动量和周期性动量之间的差距。
所有其他参数都很重要
- 我们调整模型的所有其他超参数的方式将影响最佳学习率。这就是为什么当我们运行学习率查找器时,在与训练期间完全相同的条件下使用它非常重要。例如,不同的batch sizes or weight decays会影响结果:
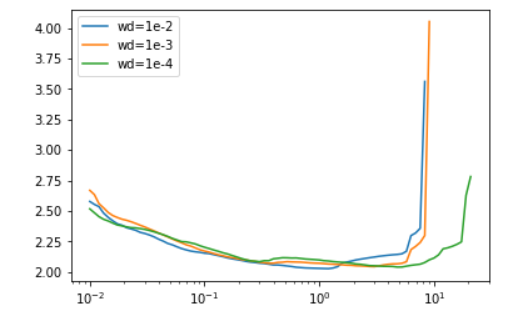
- 这对于设置某些超参数很有用。例如,对于weight decays,建议是针对少数几个weight decays值运行学习率查找器,并选择最大的可以让我们以较高的最大学习率进行训练。所以根据上图我们可以在实验中使用 1e−4。
- 作者认为,batch sizes应设置为最大可能值,以适合可用内存。然后,可以使用与weight decays相同的方式来调整我们可能具有的其他超参数(例如,dropout),或者仅通过尝试一个周期并查看它们给出的结果即可。唯一的事情是永远不要忘记重新运行学习率查找器,特别是在决定选择积极学习率接近最大可能值的策略时。唯一的事情是永远不要忘记重新运行学习率查找器,特别是在决定选择学习率接近最大可能值的策略时。
- 以高学习率使用1cycle策略进行训练本身就是一种正则化方法,因此,如果我们不得不减少以前使用的其他形式的正则化,那么我们就不会感到惊讶。但是,由于我们可以以较高的学习率进行长时间的训练,因此效率更高。
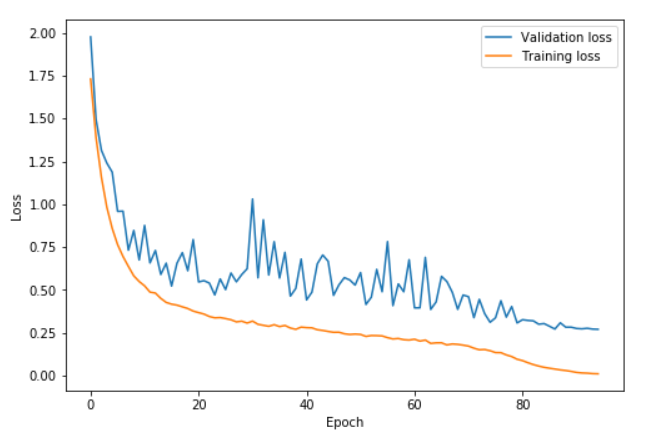
5.绘制loss可视化!
fig,ax = plt.subplots(2,1,figsize=(8,12))
ax[0].plot(list(range(70)),learn.sched.val_losses, label='Validation loss')
ax[0].plot(list(range(70)),[learn.sched.losses[i] for i in range(97,70*98,98)], label='Training loss')
ax[0].set_xlabel('Epoch')
ax[0].set_ylabel('Loss')
ax[0].legend(loc='upper right')
ax[1].plot(list(range(70)),learn.sched.rec_metrics)
ax[1].set_xlabel('Epoch')
ax[1].set_ylabel('Accuracy')
6. 尝试过拟合一个小数据集
这是一个经典的小trick了,但是很多人并不这样做,可以尝试一下。
关闭正则化/随机失活/数据扩充,使用训练集的一小部分,让神经网络训练几个周期。确保可以实现零损失,如果没有,那么很可能什么地方出错了。
7. 关于数据集
- 如果数据集极其不平衡,假如我们有个检测船只的任务,在100000图中只有30000张图中含有船只,其余图像都是不含船只的图像,这时候如果对此直接进行训练效果应该会很差。为此,首先可以挑选出只有船只的图像集合进行初步训练。其次,使用训练好的模型去检测没有训练的部分(不含船只),挑选出检测失败的false positive(也就是在没有船的图像集中检测出船只了)加入之前的训练集再次进行训练。
