BERT家族-预训练模型 Q&A
BERT家族-预训练模型 Q&A
文章分为三个Q&A部分:
- 什么是 pre-train 模型?
- 如何 fine-tune?
- 如何 pre-train?
1. 什么是pre-train 模型
Q1:预训练模型有什么作用
- 为每个 token 都产生一个表示其信息的 embedding vector
Q2:之前获取 embedding vector 的方式及缺点
-
方法① 简单地 look-up tabel:Word2vec [Pennington, et al., EMNLP’14]、 Glove [Mikolov, et al., NIPS’13]
-
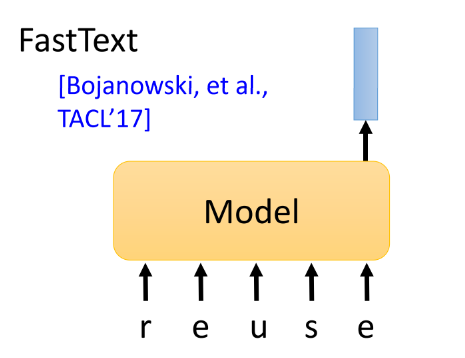
方法② FastText [Bojanowski, et al., TACL’17]:如果 token 是英文,我们知道英文的word 太多了,时时刻刻会产生一些新的word,如果是查表找对应的embedding 不太可行,这里就使用一个Model,读入一个单词的每个字符,然后产生其对应的 embedding。
-
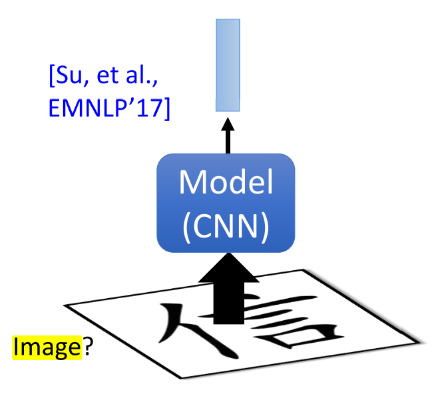
方法③ [Su, et al., EMNLP’17] :如果 token 是中文,因为其具有部首偏旁等信息,可以将一个字作为一张image输入到Model(CNN) 中,然后得到对对应的embedding。
-
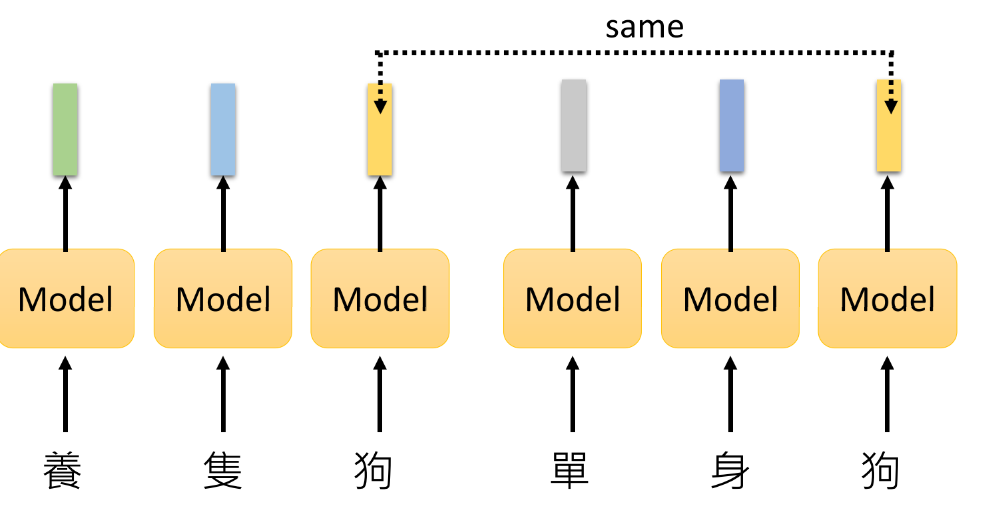
综上所说,以上获取embedding vector 的方式对于具有相同 type 的token 都会产生相同的 embedding。(eg:“单身狗”和“养只狗”中的“狗”是不同的 token,但是具有相同的type)

-
当然,你可能会想,如果把每个token都看作一个独立的type呢,给“狗”加个下标,变成“狗1”和“狗2”,这样两个token得到的embedding 不就不一样了。但是为什么不是“单身猫”、“单身龙”呢,两个“狗”之间肯定还有相近的意思在,所以也不能将其完全分隔开来。(况且难道“狗”每在一个语境中出现一个新的含义,我们就要存储一个新的含义吗,这个look-up table 也太大了,而且我们也很难在查表的时候知道我们该选择哪一个)
Q3:Contextualized Word Embedding 是什么
-
结合上下文去生成word embedding,即,过去获取 embedding 的方式都是,吃一个 token,输出一个embedding;现在,我们对 Model 输入一个句子,然后让模型把整个句子都看过了之后,再为句子中的每个token输出一个对应的embedding。
-
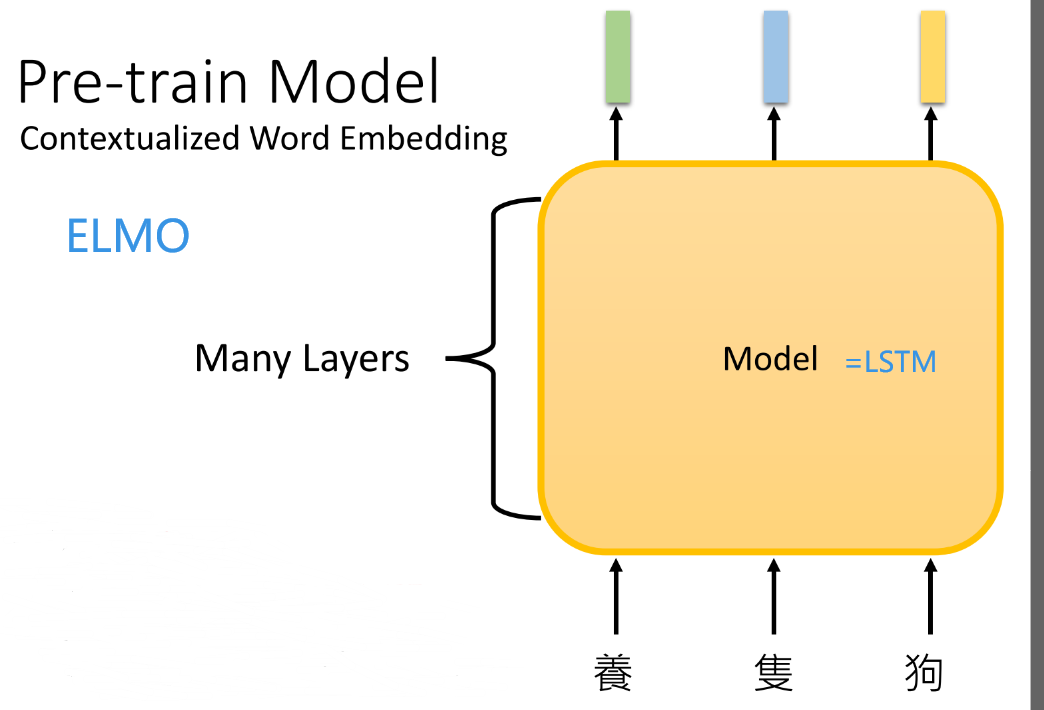
那么读入句子的模型都有什么类型的呢?
-
LSTM
-
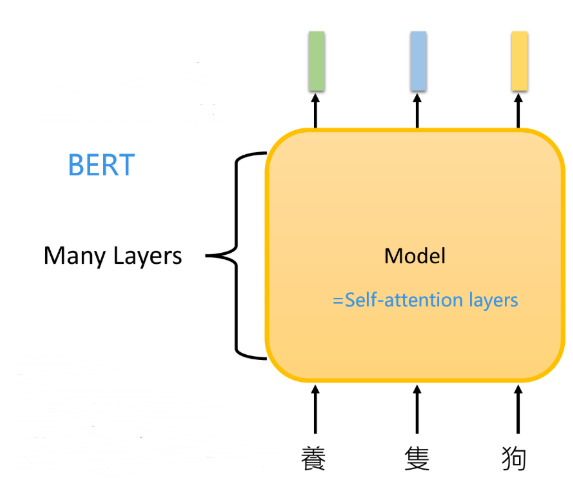
Self-attention layers
-
Tree-based model (?) Ref: https://youtu.be/z0uOq2wEGcc 利用树去获得的文法信息,但实际证明了在预训练模型上效果没有明显的优越性,应用解决输入数学公式得到答案这类问题会大大的好。
-
Q4:那么预训练模型会很大吗
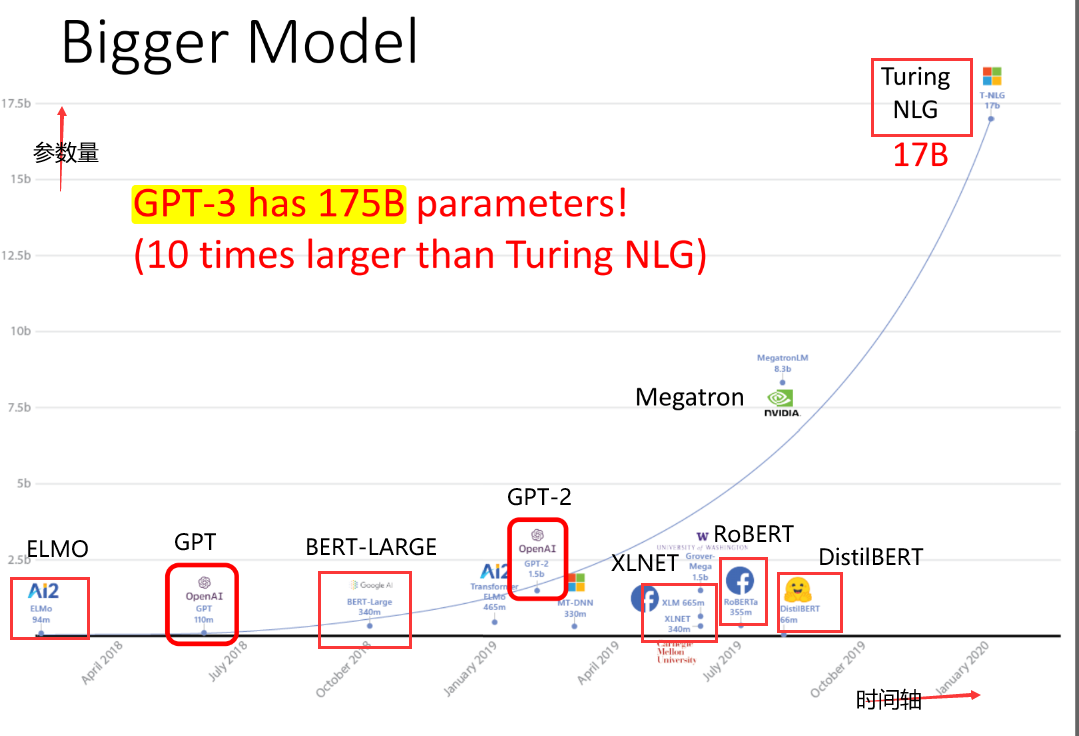
- 可以看出,确实我们的预训练模型越来越大(富人的游戏 o(╥﹏╥)o)
Q5:那么有没有穷人可以用的预训练模型
- 有很多工作研究得到更小的Model,如下:
- Distill BERT [Sanh, et al., NeurIPS workshop’19]
- Tiny BERT [Jian, et al., arXiv’19]
- Mobile BERT [Sun, et al., ACL’20]
- Q8BERT [Zafrir, et al., NeurIPS workshop 2019]
- ALBERT [Lan, et al., ICLR’20]:这个工作最为知名
Q6:那么怎么得到更小的模型呢
- 模型压缩(Network Compression) [视频链接](Ref: https://youtu.be/dPp8rCAnU_A) 、all-theways-to-compress-BERT
- ① Network Pruning
- ② Knowledge Distillation
- ③ Parameter Quantization
- ④ Architecture Design
Q7:可以读一本书长度的句子吗
以下工作的目标都是可以让model来读很长的句子,甚至是一本书的长度
- Transformer-XL: Segment-Level Recurrence with State Reuse [Dai, et al., ACL’19]
- Reformer [Kitaev, et al., ICLR’20]
- Longformer [Beltagy, et al., arXiv’20]:后两个工作都是减小self-attention中的复杂度,来使得我们在句子长度N很大的情况下,不会得到 \(O(N^2)\) 这样的self-attention的复杂度。
2. 如何利用pre-train
Contextualized Word Embedding
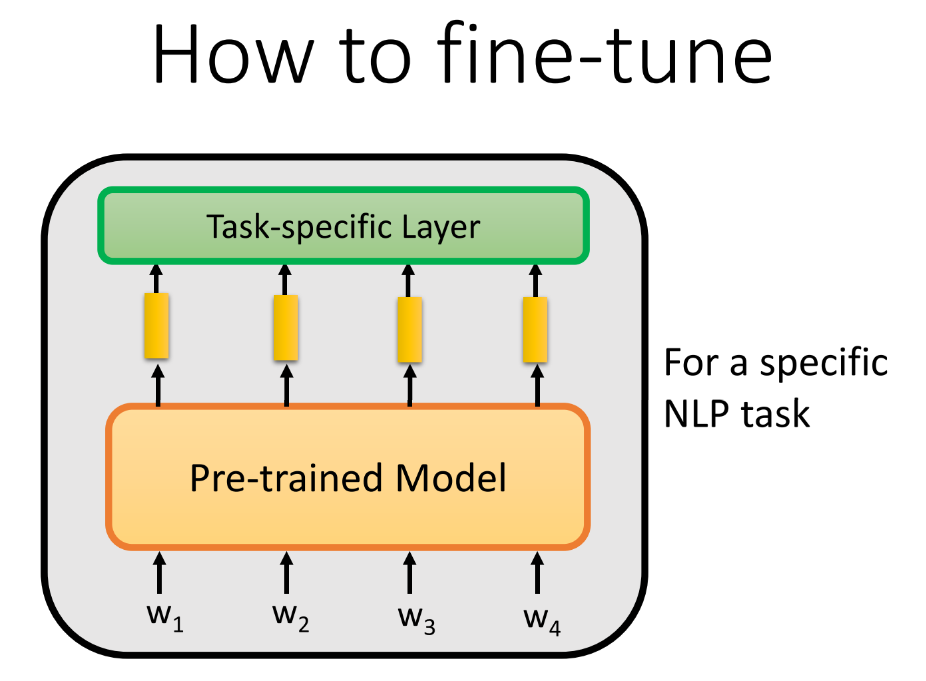
Q8:预训练模型可以完成所有NLP任务吗-8种
-
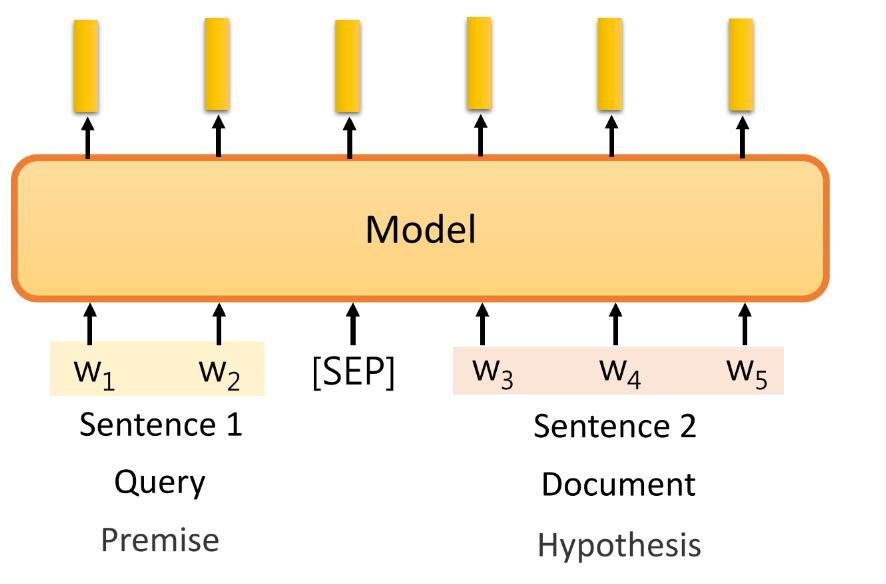
① 输入,多个句子:使用 [SEP] 分割两个句子
-
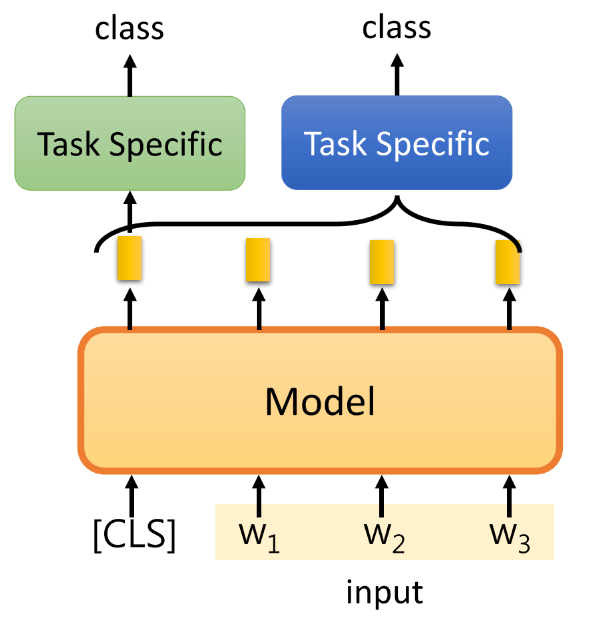
② 输出,一个类别:(1)告诉模型,[CLS] 对应的embedding 代表整个句子;(2)将各个token的embedding进行融合,使用模型或者pooling之类的。
-
③ 输出,为每个token都输出一个类别:eg,使用LSTM
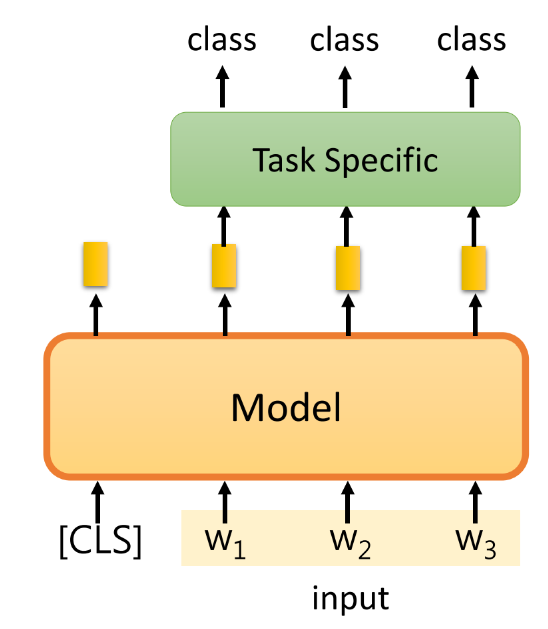
-
④ 输出,从输入中复制:eg,Extraction-based QA,输入一个 Document 和一个 Query,我们要是有一个QA Model 输出两个整数,(s,e),代表document 的第s个词和第e个词中间的内容是我们要的答案。最原始的Bert做法,使用两个向量分别通过点积来检测s和e出现在哪个位置最有可能。
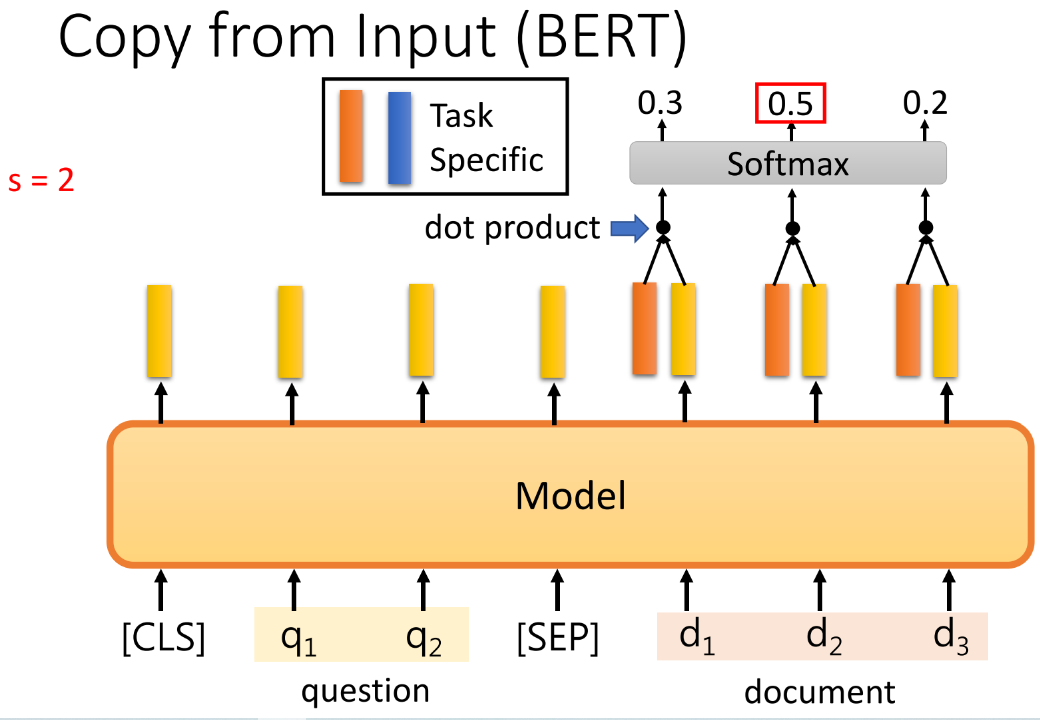
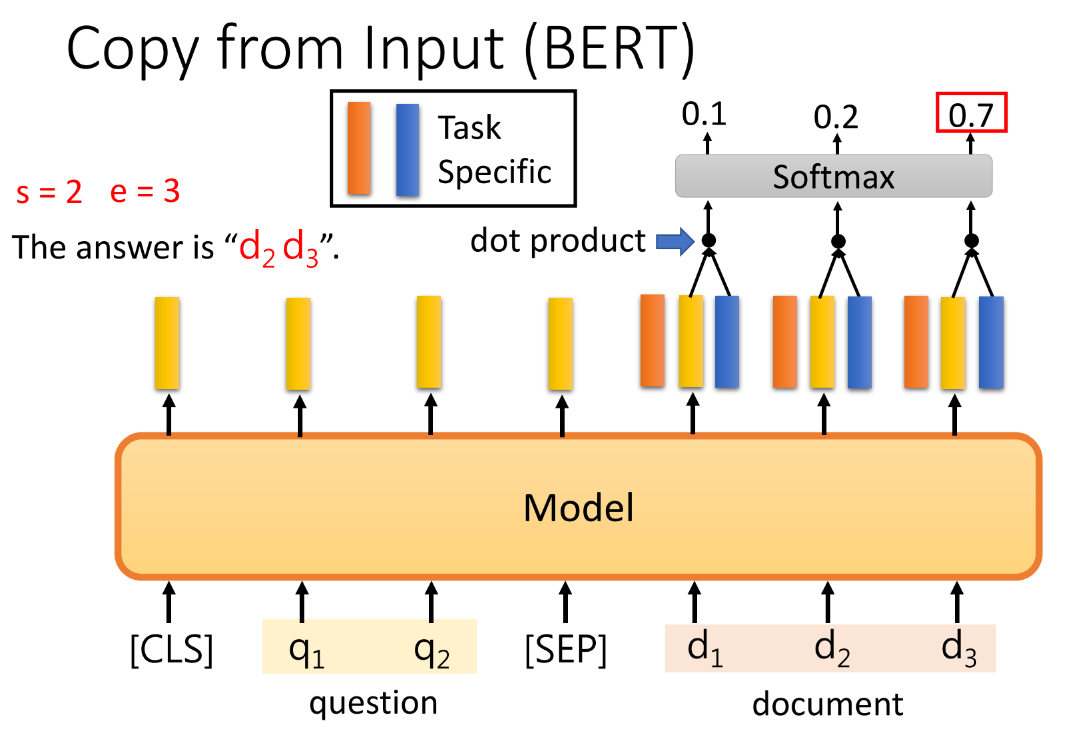
-
⑤ 输出,生成一般化的Sequence:
-
(1)将预训练模型作为seq2seq model 的encoder,针对我们的生成任务采用decoder,但是这样我们没有使用到预训练的decoder。
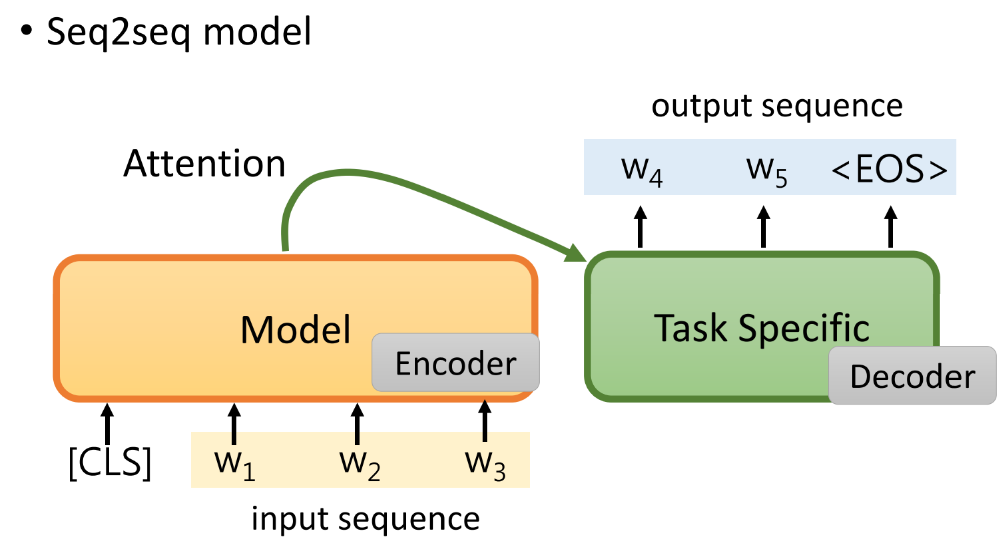
-
(2)在输入句子后面加入一个[SEP]特殊的token,根据它的embedding预测生成的第一个word,再把生成的word送到model输入,再生成下一个word… 这种做法在decoder端也可以使用到了预训练的模型。
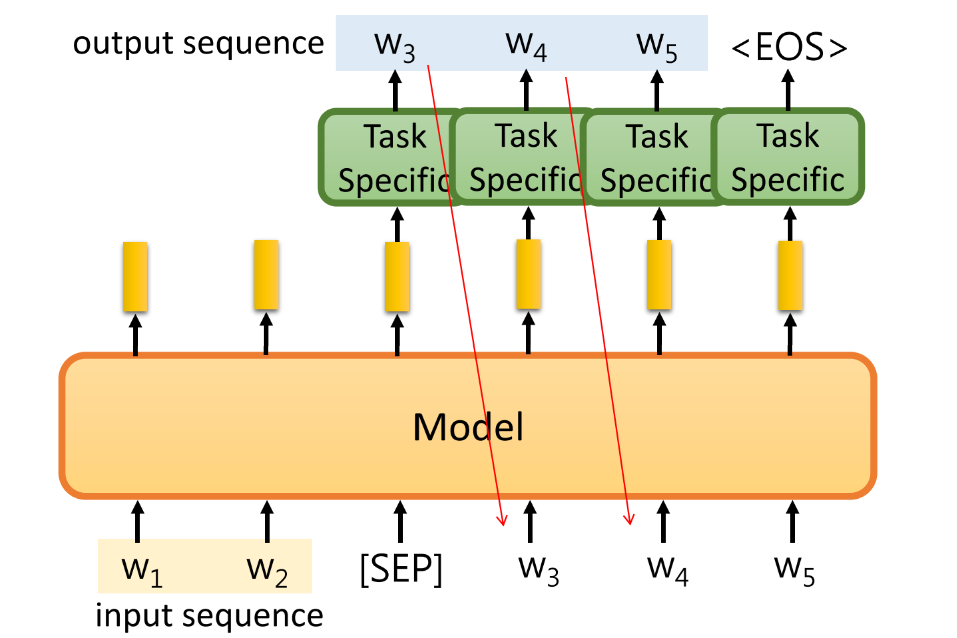
-
Q9: 那么怎么基于特定的任务fine-tune呢
-
① 当做固定的 Feature Extractor,只是对于 task-specific 进行微调
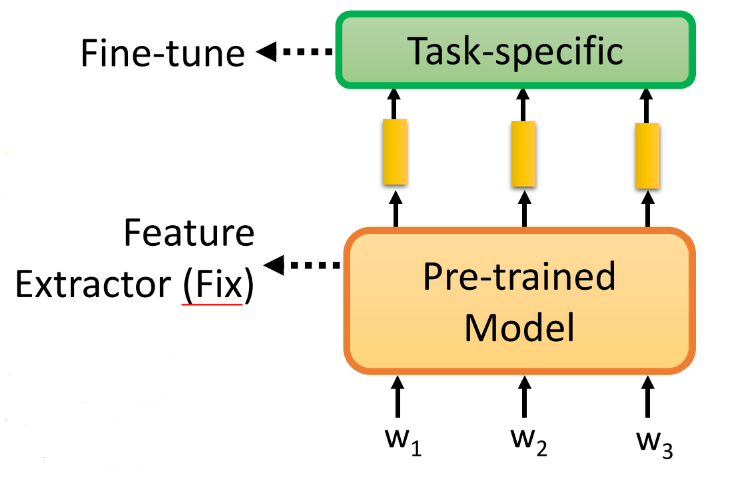
-
② 整体微调,因为主要的部分已经预训练过了,所以也不会过拟合,但是如果我们有很多个不同的任务,这种方式会使得我们需要很大的memory 去存储很多的模型
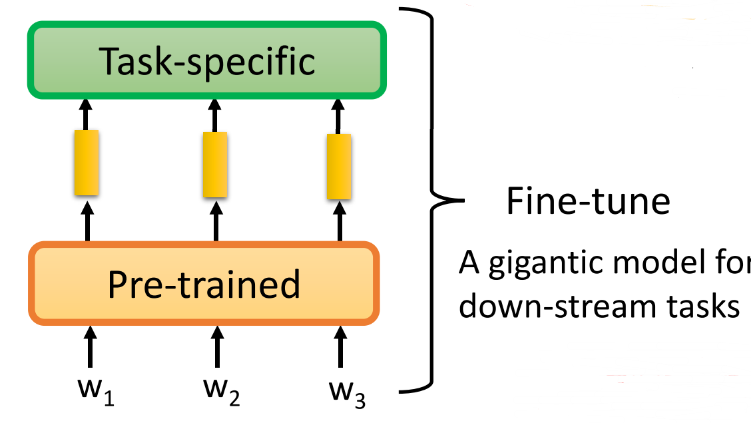
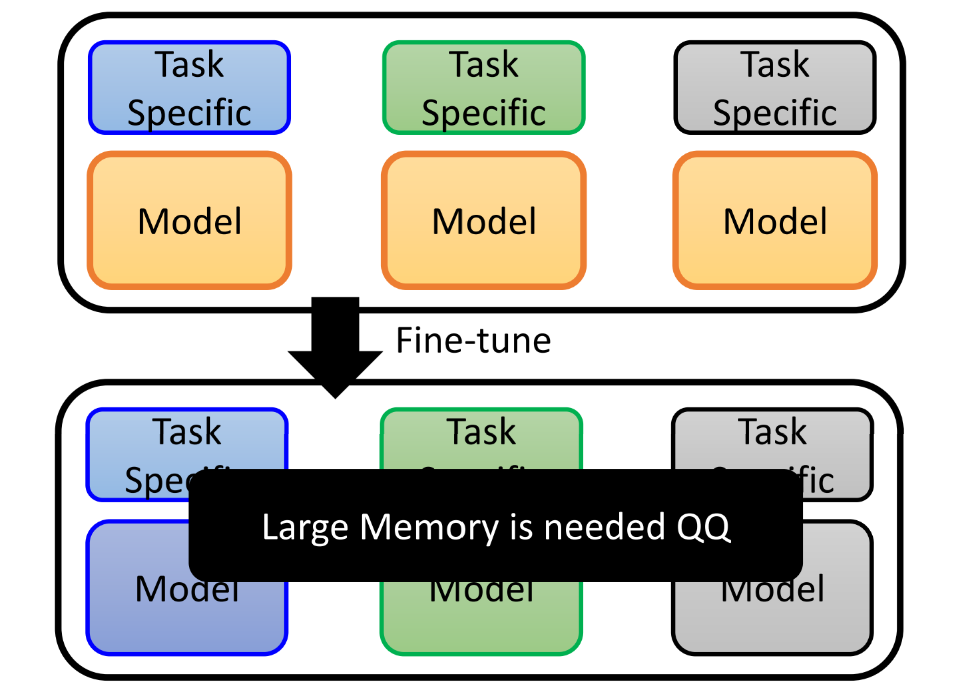
-
③ 使用adaptor,我们把adaptor嵌入到Pre-Model中,存储时需要存储的参数量会大大减小,也可以起到调整Pre-Model的作用。adaptor 有很多种设计方法,值得探索。
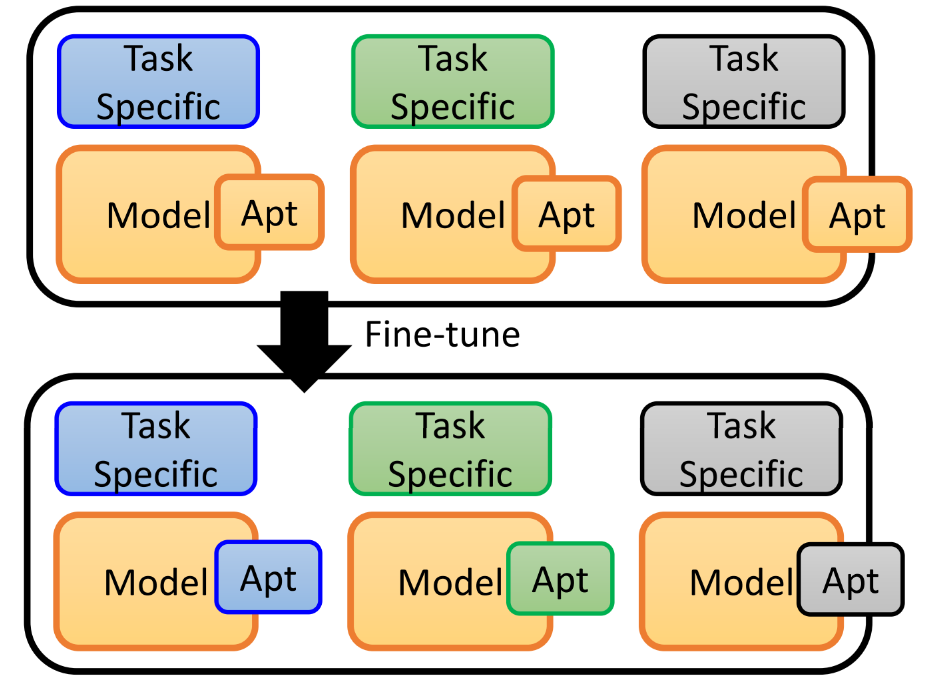
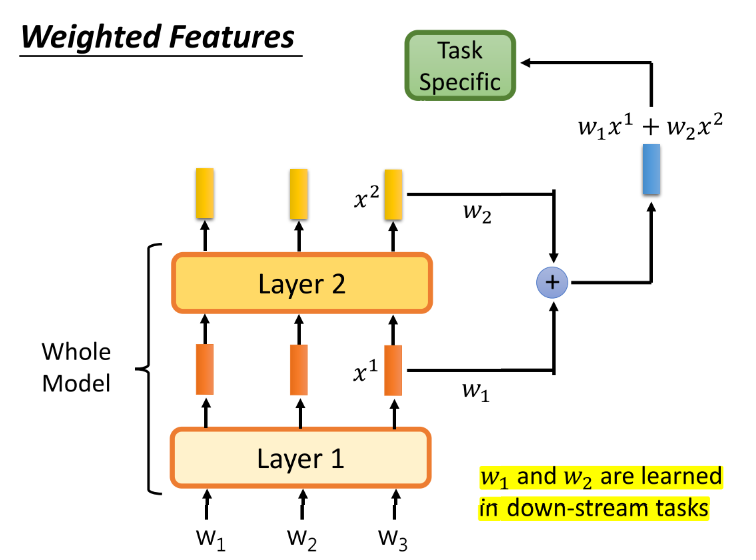
Q10:什么是weighted feature
-
我们在BERT中,是把模型最后一层的输出feature作为了各个token的embedding,但不同层学到的是不同的feature,不同的任务可能需要不同的侧重,所以可以对不同层的feature进行加权。
3. 如何去pre-train
3.1 可以通过翻译进行预训练吗
- 最早提取Contextualized Word Embedding 的方法,其实就是基于翻译的,其实像种关注于输入的每个token的任务都可以作为预训练任务,我们取模型中和输入的token串一一对应的embedding,就是我们要的Contextualized Word Embedding(结合上下文的词向量)。
- 但是像翻译任务虽然很好的关注了每个词,但是它有一个致命的缺点,需要有标注的数据进行训练,而我们预训练模型需要大量文本进行训练,这注定我们不能选择有监督的任务进行训练。
- 所以我们选作预训练模型的任务需要满足两个特征:
- ① 关注句子中的每一个词
- ② 不需要有监督的数据
3.2 什么叫 self-supervised learning
- 官方:In self-supervised learning, the system learns to predict part of ites input from other parts of it input.
- 也就是说,用一部分的输入去预测另一部分的输入。自我监督,自成轮回循环…
3.3 用LM进行预训练
-
很自然,我们就能想到 LM(language model)任务,它不就是为我们量身打造的,满足我们的两个特征要求。当然,在一个个词预测时,我们要盖住未来的词,不能让model一次性把句子中所有的词都读进去再预测偷看到答案了,就培养不成模型的学习能力啦~
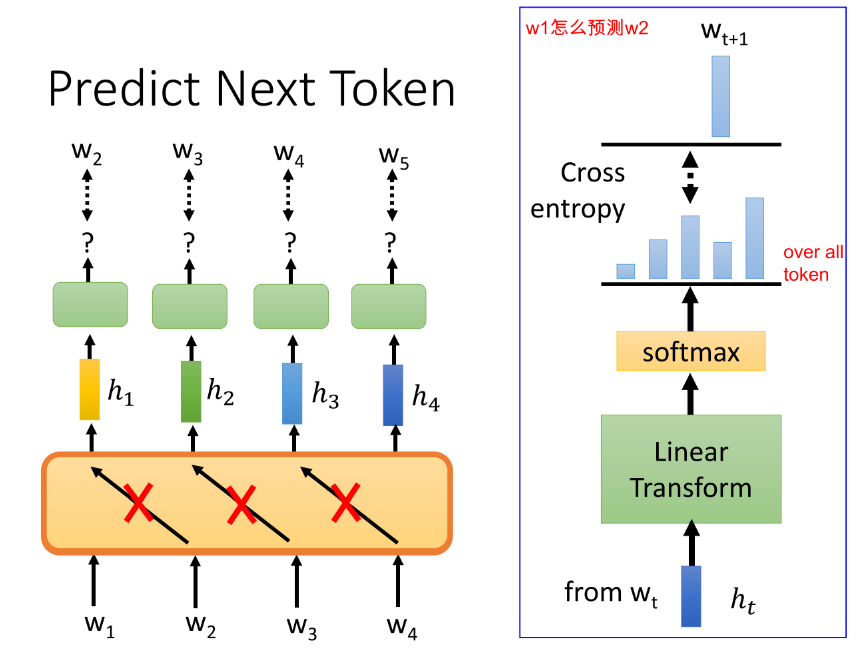
- ① 选择使用LSTM作为预测Model时,我们有了 Universal Language Model Fine-tuning (ULMFiT) [Howard, et al., ACL’18]、ELMo [Peters, et al., NAACL’18]
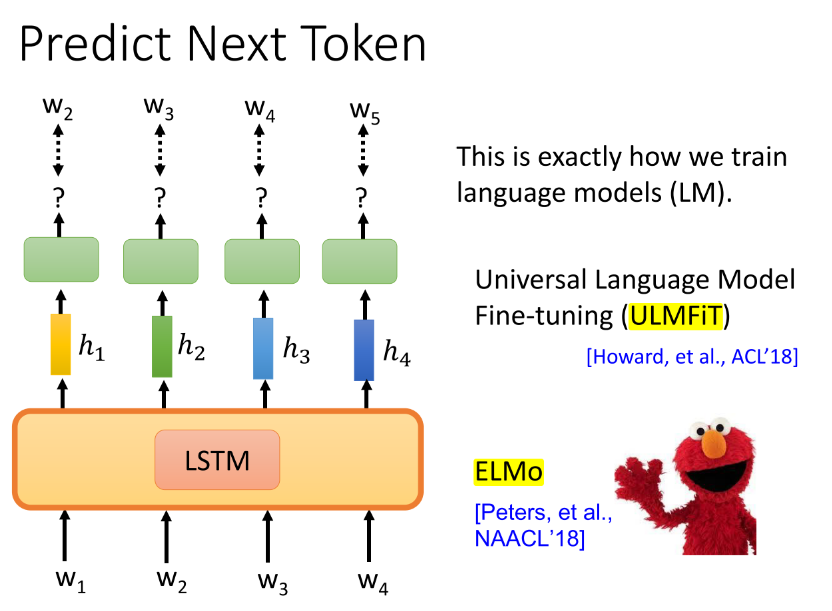
-
② 我们也可以使用self-attention作为预测的Model,但是使用attention怎么防止模型偷看答案呢(传统的self-attention layer 就是把整个句子都读进去,每个位置都可以attent到其他的位置),我们要对attention加一些constraint,限制它在预测w4时,只能 attent w1、w2、w3。于是便有了 GPT
[Alec, et al., 2018]、GPT-2 [Alec, et al., 2019]、Megatron [Shoeybi, et al., arXiv’19]、Turing NLG。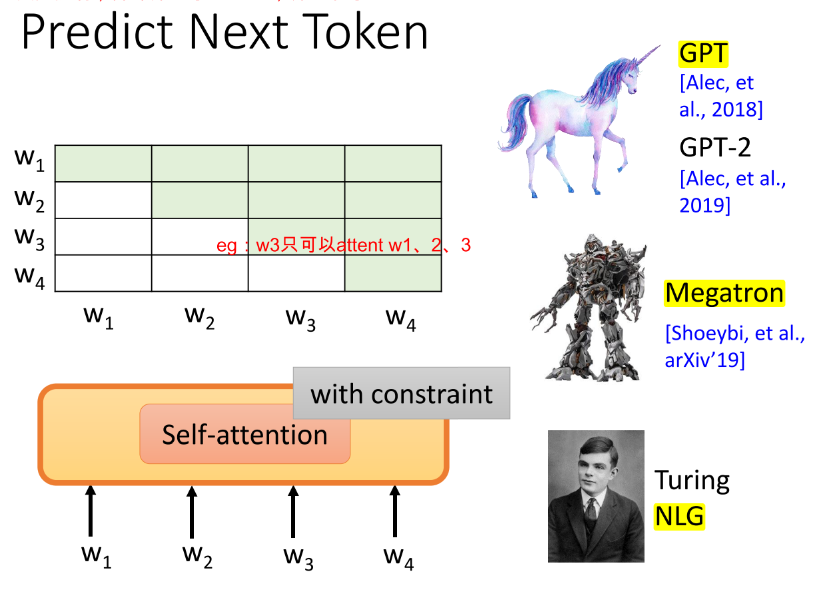
-
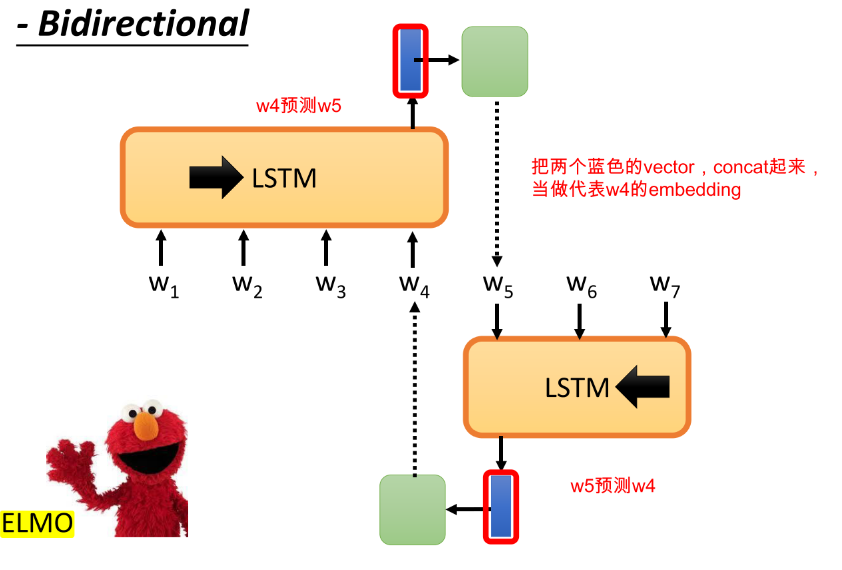
有人说,理解一个词最好的方法是看谁和它一起出现,那传统的LM只看了左边,它右边的好兄弟的价值我们为什么不发掘一下呢,于是 ELMO 又出现了!
-
-
有人可能说,LM不是顺序预测的每一个词,它是不是每个词预测的(关注的)难易程度会不一样(越靠前越难预测),那每个词学到的embedding 会一样好吗?所以聪明的Bert,随机mask掉任意位置的词,然后基于其他的词去预测,这样各个位置的embedding就可以保证一样好啦。而且这样也可以解决使用右兄弟的问题!,并且使用self-attention是没有限制的,因为直接盖掉啦(随机替换 or [MASK])
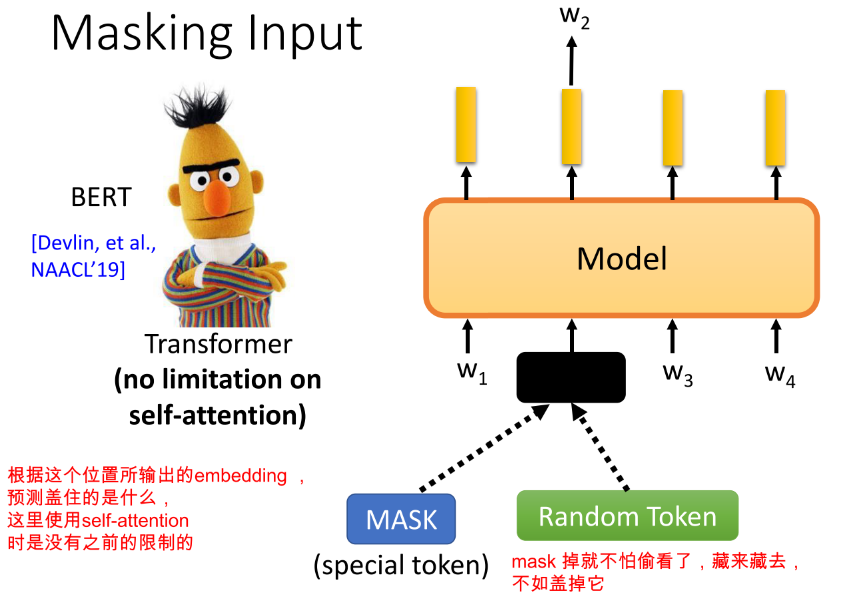
-
那么还可能有人问,那mask掉任意位置的词,那像"enjoyable"被subword后,"enjoy"、"##able" ,或者中文"黑龙江","黑"、"##龙"、"##江"中的"##龙"被mask掉,那属于同一个词的其他部分是不是也可以为被mask掉的subword提供信息,是的!所以,哈工大提出了WWM(whole word mask),把同一个词的subword,要mask就一起mask掉(要死一起死,我们是兄弟Hhhh)WWM参考链接
-
那么又有人会说,那我仅仅把属于同一个word的所有token要mask 都mask够吗,我不如把属于同一个短语 Phrase 或 属于同一个实体 Entity 的token,要mask就一起mask掉,让他们共同进退,所以有了 Enhanced Representation through Knowledge Integration (ERNIE) [Sun, et al., ACL’19]
-
又有甚者说了,那这么说共同进退的范围多了去了,我随便找个范围都可以发paper了,我不如以退为进,直接一盖盖一排的token,反正你无论是word还是phrase还是entity都是连续出现的token,我一次去预测这一排好了,所以有了 SpanBert [Joshi, et al., TACL’20] ,效果确实有了提升。
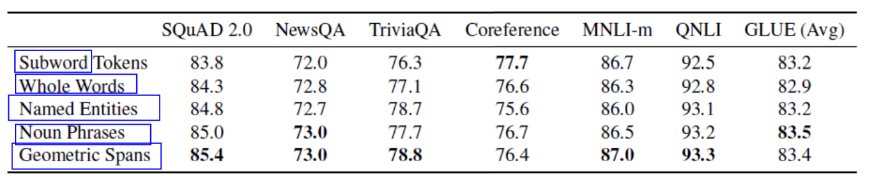
-
可以看到 SpanBert 在 coreference 任务上表现没有其他的那么好,因此,在SPanBert中提出了一种策略,在coreference中也许很有用——Span Boundary Objective (SBO),只用span左右两边的token的embedding。
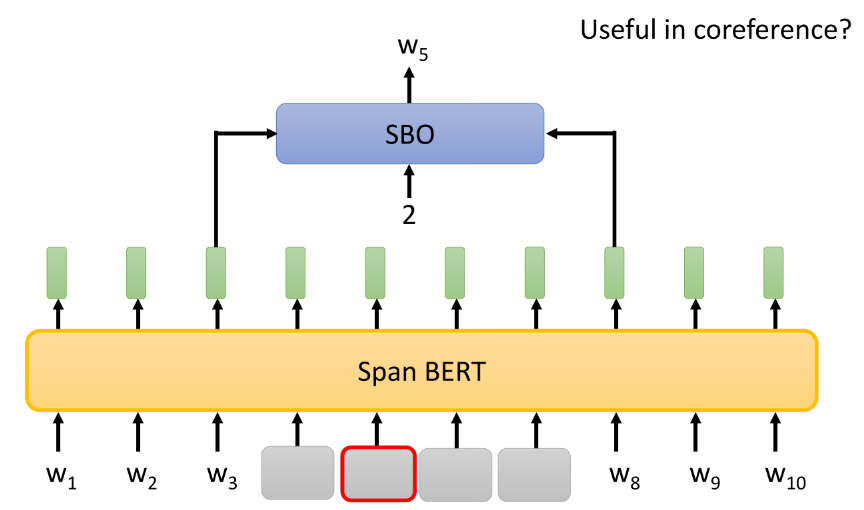
-
-
也有人说了,你现在越盖越多,那我不就学不到根据"黑"+"##江"去预测"##龙"的能力了,既然你想学到更多的资讯,干脆把输入随机打乱顺序,然后在使用传统的LM进行预测,这样可以就可以学到不同的预测能力了。于是有了,XLNet [Yang, et al., NeurIPS’19] 、Transformer-XL
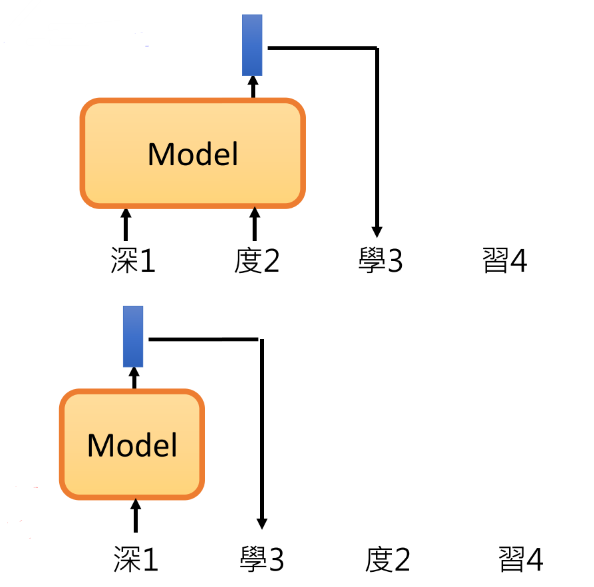
3.4 BERT 和 CBOW 有什么区别
可能有人说,Bert好熟悉,我们CBOW 不也是盖掉一个词,然后用周围的词去预测这个词吗
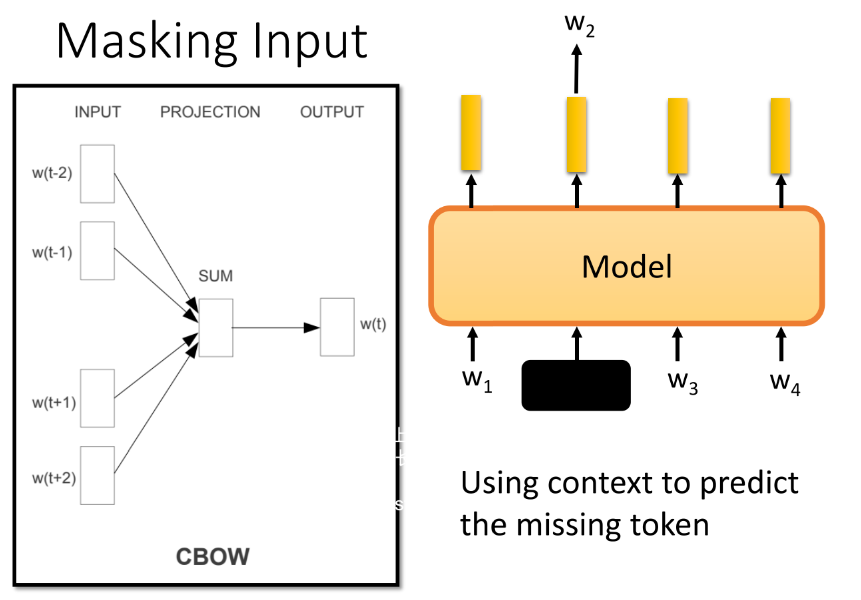
BERT 优越的地方:
- BERT 往左右想看多长看多长,因为是使用self-attention;而CBOW 是限定在了窗口的范围。
- BERT 很复杂,用神经网络,有很多层
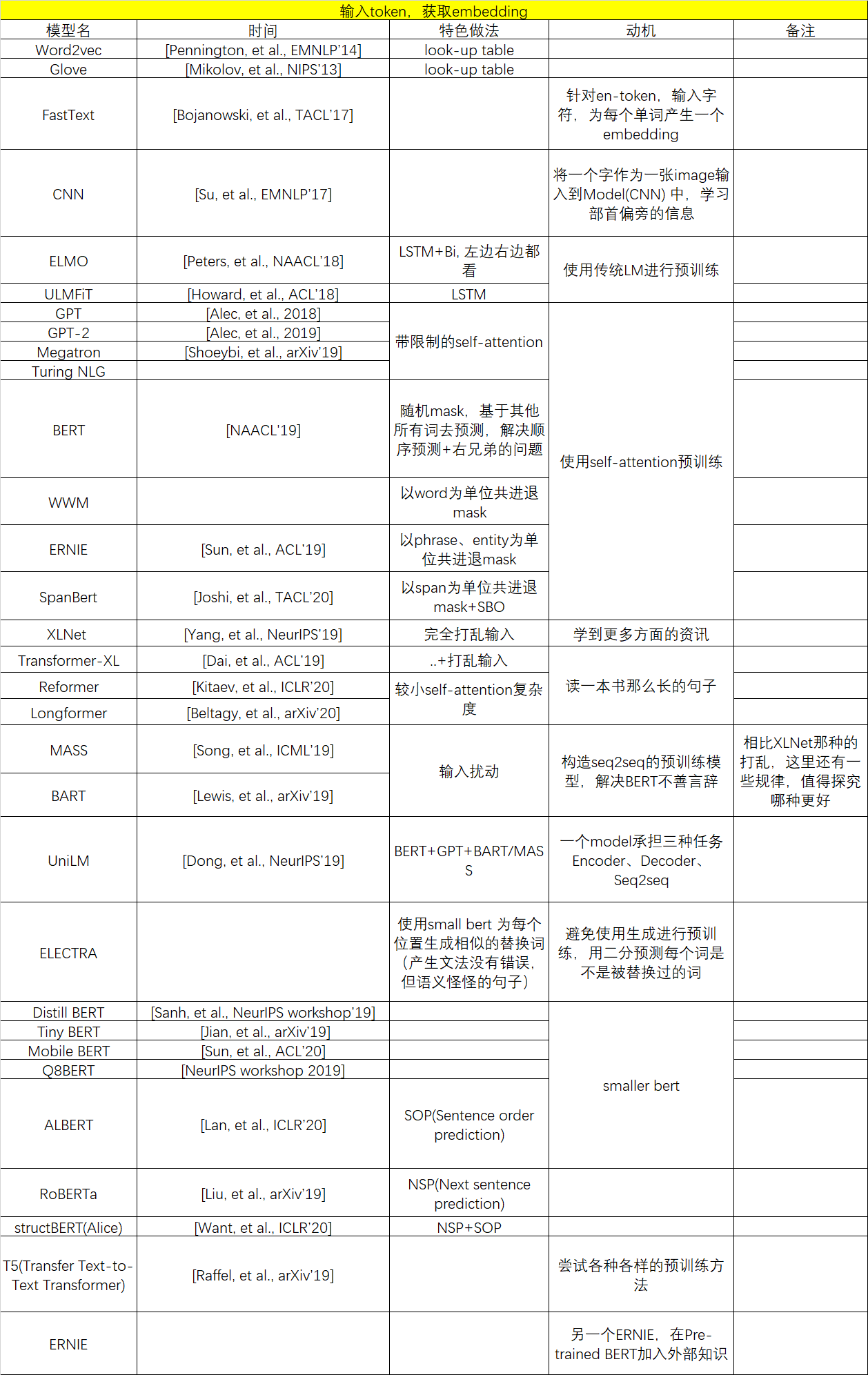
3.5 BERT 不善言辞?
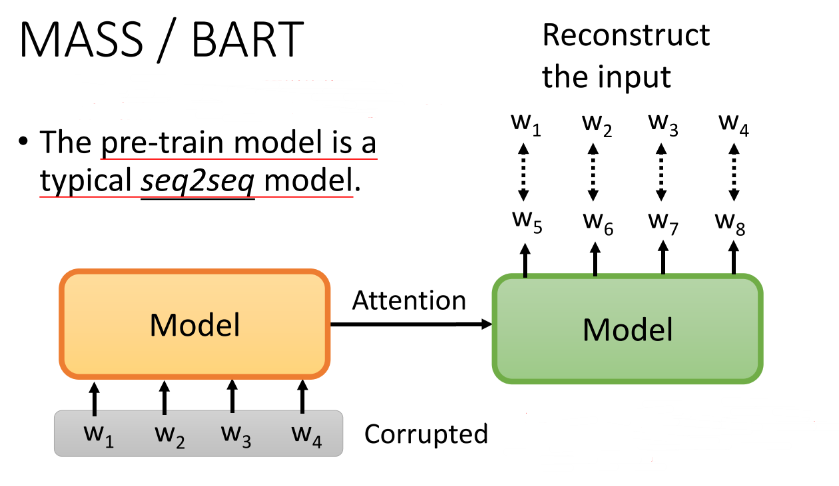
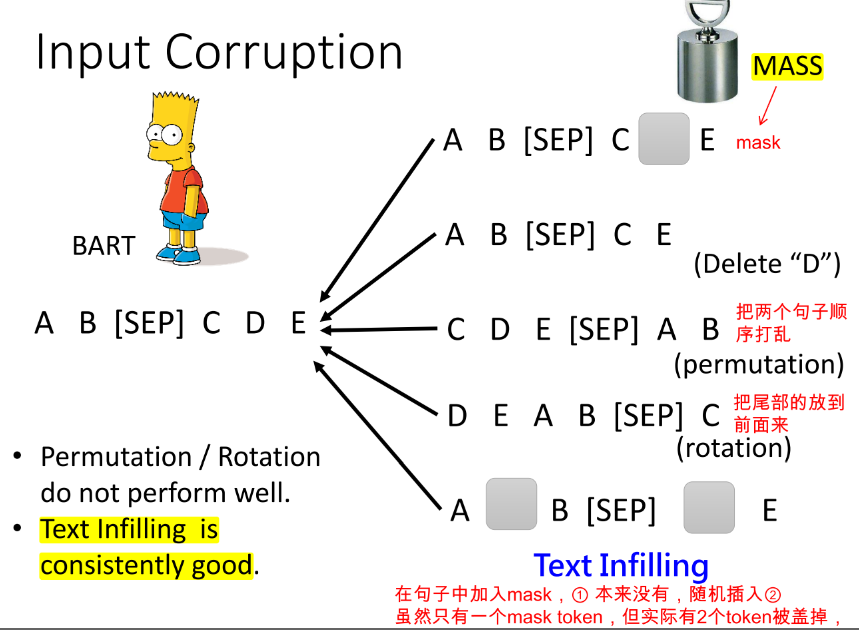
Limited to autoregressive model,BERT cannot talk? 有人说,我们生成文本是从左到右生成的,而Bert训练是看的完整的句子,那Bert是否在生成任务(seq2seq)上会表现的稍微逊色。那有什么办法让Bert学会说话吗,我们是否可以直接预训练一个seq2seq的模型?于是有了,MAsked Sequence to Sequence pre-training (MASS) [Song, et al., ICML’19]、Bidirectional and Auto-Regressive Transformers (BART) [Lewis, et al., arXiv’19]。当然,这种训练要对encoder的输入进行扰动,否则和我们单独的LM没有区别,decoder直接照搬embedding去预测生成的词。BART 中为我们分析了不同的输入扰动的方式,结果是 Text Infilling 的方式是最好的。