Never-Ending Study
Never-Ending Study
0. 一些定义
- nerver-ending learning:另一种机器学习范式,更接近于模拟人类学习的多样性(diversity)、能力(competence)和累积性(cumulative)。
- NELL:never-Ending language learner
- 理想中的 NELL 具备的四大特性:
- 学到许多不同类型的 knowledge 或 functions。
- 从多年 diverse,大多数是 self-supervised 的 experience 中学习。
- in a staged curricular fashion,以前学到的知识使得可以在将来学习到更多类型的知识。
- 自我反省(self-reflection)、表达新的 representations 和新的学习任务的能力,使得 learner 能够避免性能停滞不前。
1. 动机
- 之前的机器学习系统往往是从单个的 dataset 中学习到单个的 function 或 data model.
- 而 NELL 可以从 web 中 read beliefs(eg,servedWith(tea,biscuits)),还可以从已有的beliefs 中推理出新的 beliefs,通过合成新的关系谓词(relational predicates)来扩展其本体(ontology)。
2. Never-Ending Learning
-
never-ending learning agent:是一个系统,它像人一样,学习许多种类型的知识,从多年的、主要是自监督的经验(experience)中,使用从前学到的知识来改善随后的学习,并伴随着足够的自我反省(self-reflection)能力来避免达到性能的平台期。
-
never-ending learning agent 面临的问题:由一组 learning tasks 和将它们的 solutions 耦合在一起的约束条件(constraints)组成。
-
Never-Ending learning problem \(\zeta=(L,C)\)
-
① 学习任务 (learning task) 集合 \(L=\{L_i\}\) 。第 \(i\) 个学习任务 \(L_i = <T_i, P_i, E_i>\) ,\(P_i\) 是度量指标(metric),\(T_i\) 是给定的性能任务,\(E_i\) 是给定类型的经验(experience)。
- 每个性能任务(performance task)\(T_i\) 是 \(<X_i, Y_i>\) ,定义了要被学习的域和函数 \(f_i^*: X_i → Y_i\)
- \(P_i\) 性能度量定义了对于第 \(i\) 个学习任务来说,最优的学习到的函数 \(f_i^* = arg\,\max_{f∈F_i}P_i(f)\),其中\(F_i\) 是从 \(X_i\) 到 \(Y_i\) 所有可能的 function 集合。
-
② 耦合的约束条件集合(coupled constraints set) \(C=\{<\Phi_k, V_k>\}\) 。\(\Phi_k\) 是关于多个学习任务的实值函数,指定了约束(constraint)的满足程度。\(V_k\) 是一个学习任务上的索引向量,是指定 \(\Phi_k\) 的自变量。
\[\zeta = (L, C), \]\[L=\{<T_i, P_i, E_i>\} \]\[C=\{<\Phi_k, V_k>\} \]
-
-
Never-Ending learning problem \(\zeta=(L,C)\) (和理想中 NELL 四大特性对应)
- 学到许多不同类型的 knowledge 或 functions。即,\(L\) 包括很多的学习任务。
- 从多年 diverse,大多数是 self-supervised 的 experience 中学习。即,学习所基于的经验 \(\{E_i\}\) 实际上是多样化的,并且很大程度由系统本身提供。
- in a staged curricular fashion,以前学到的知识使得可以在将来学习到更多类型的知识。即,不同的学习任务 \(\{L_i\}\) 不需要被同时解决,解决一个有助于解决下一个。
- 自我反省(self-reflection)、表达新的 representations 和新的学习任务的能力,使得 learner 能够避免性能停滞不前。即,learner 自己可以给自己添加新的学习任务和新的耦合约束,以帮助自己解决给定的学习问题 \(\zeta\) 。
3. Case Study:never ending language learner
-
给定:
- ① 定义 categories (eg,Sport, Athlete)和 binary relations (eg,AthletePlaysSport(x,y))的初始本体(ontology)。
- ② 针对每个 category 和 relation 的各大概12个训练样例(eg, examples of Sport might include the noun phrases “baseball” and “soccer”)?????什么样的训练样例呢
- ③ Web (ClueWeb2009年集合中最初的5亿个网页,以及每天100,000个Google API访问的 search queries )
- ④ 偶尔和人类的交互(eg,通过NELL官网 http://rtw.ml.cmu.edu)
-
Do:24小时全天候运行
- ① 从网络中阅读(提取)更多的 beliefs,删除原先不正确的beliefs,以扩充不断增长的知识库(knowledge base)。在KB 中针对每一个 belief 都把包含一个 confidence(信息) 和 provenance(起源)。
- ② 学着比前一天 read better。
-
NELL 中的学习任务 \(L\):
- ① Category Classification :通过 semantic category 对 noun phrases 进行分类的函数。(例如,对任何给定的名词短语是否涉及 food 进行分类的 boolean functions) 。Nell 为其本体中的280个类别中每一个都学习了不同的布尔函数,对于每个category \(Y_i\) ,NELL 基于 5 个不同的noun phrase views 进行预测:
- <1> Character string features of the noun phrase (e.g.,
whether the noun phrase ends with the character string “...burgh”). - <2> The distribution of text contexts found around this noun phrase in 500M English web pages (e.g., how frequently the noun phrase N occurs in the context “mayor of N”)
- <3> The distribution of text contexts found around this noun phrase through active web search.(与第2个view相同,只不过是使用实时的网络搜索)
- <4> HTML structure of web pages containing the noun
phrase (e.g., 名词短语是否与其他已知城市一起出现在HTML列表中)。 - <5> Visual images associated with this noun phrase, when the noun phrase is given to an image search engine. (仅适用于Nell的本体类别的子集)
- <1> Character string features of the noun phrase (e.g.,
- ② Relation Classification:对各名词短语对儿是否满足给定关系(relation)进行分类的函数。(e.g., classifying whether the pair <“Pittsburgh”,”U.S.”> satisfies the relation “CityLocatedInCountry(x,y)”).
- ③ Entity Resolution:Functions that classify noun phrase
pairs 是否是同义的(synonyms)。(e.g., whether “NYC” and “Big Apple” can refer to the same entity) - ④ Inference Rules among belief triples:Functions that map from NELL’s current KB, to new beliefs it should add to its KB. (根据现有KB ,推理可以被添加进 KB 的新的beliefs)
- ① Category Classification :通过 semantic category 对 noun phrases 进行分类的函数。(例如,对任何给定的名词短语是否涉及 food 进行分类的 boolean functions) 。Nell 为其本体中的280个类别中每一个都学习了不同的布尔函数,对于每个category \(Y_i\) ,NELL 基于 5 个不同的noun phrase views 进行预测:
-
注,NELL 中的 \(P_i\) 和 \(E_i\):
- the performance metric \(P_i\) :就是学习到的 function 的 accuracy。
- the experience \(E_i\) :human-labeled 的训练样本、NELL 自标记的训练样本和大量未标注的网页文本的组合。
-
NELL 中的耦合约束(coupling constraints)$C $:
-
① Multi-view co-training coupling:多个视角对于同一输入预测的特征应该保持一致,应该提供一个自然的联合训练环境,哪怕是基于不同的名词短语特征,就预测的标签也应该达成一致。
-
② Subset/superset coupling(子集/超集耦合): When category C1 is added as a subset of category C2, NELL uses the coupling constraint that (∀x)C1(x) → C2(x).
-
③ Multi-label mutual exclusion coupling(多标签互斥耦合):When category C1 is declared to be mutually exclusive with C2, NELL adopts the constraint that (∀x)C1(x) → ¬C2(x)。
-
④ Coupling relations to their argument types(与参数类型的耦合关系): (e.g., “zooInCity(x,y)” requires arguments of types “Zoo” and “City” respectively)
-
⑤ Horn clause coupling :例如,当 NELL 以 probability p 学到了如下形式的规则 (∀x, y, z) R1(x, y) ∧ R2(y, z) → R3(x, z) 时,该规则也作为对于学习关系R1,R2 和 R3 的函数上的新的概率耦合约束(probabilistic coupling constraint)。
-
4. NELL ’s Learning Methods and Architecture
- NELL 的结构图
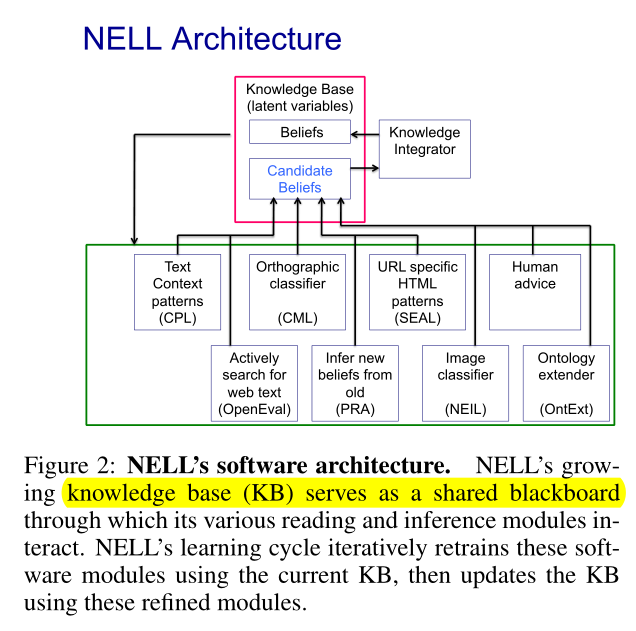
- NELL 中的学习可以看作 EM 算法的近似:
- 在类似 E 步的步骤中,每个 reading 和 inference module 对 KB 的更新提出建议。Knowledge Integrator (KI) 记录这些单独的建议,并针对分配给每个KB 潜在的belief 多少 confidence 做出最后的决定。
- 在类似 M 步 中,经过调整的 KB 被用于对各个 software modules 进行再训练。
5. Empirical Evaluation
- results:
- Nell 的知识库明显在增长,尽管其 high confidence beliefs 的增长速度慢于其全部 beliefs 的增长速度。
- 随着时间的推移,Nell 的阅读能力(reading competence)确实在提高。
- ......
- 几个未来的机会
- add a self-reflection capability to NELL
- broaden the scope of data
- expand NELL’s ontology dramatically
- add a new generation of ”micro-reading” methods to NELL
- NELL 还有一些限制
- Self reflection and an explicit agenda of learning subgoals:它没有尝试将其学习努力分配给将特别有生产力的任务。
- Pervasive plasticity(无处不在的可塑性):NELL的很多行为都是一成不变的,不可修改。要使其行为的尽可能多方面都是可塑性的,即开放学习。
- Representation and reasoning(表现力和推理力):Nell的能力已经受到部分限制,因为它缺乏更强大的推理组件:目前缺乏关于时间和空间的表示和推理方法。
