信息检索中的神经排序模型研究
论文:《A Deep Look into Neural Ranking Models for Information Retrieval 》
论文时间:2019
零、与现有工作的不同之处
- 分析+对比+讨论。
- 从不同维度深入研究 neural ranking model(主要研究用于文本检索 textual retrieval 的神经排序模型),主要分析它们的基本假设(underlying assumptions)、主要设计原则(major design principles)和学习策略(learning strategies)。通过基准任务(benchmark tasks)对各种模型进行比较,以获得对现有技术的全面理解。以及最后的反思与展望。
一、相关名词解释 Q&A
-
IR (information retrieval) 信息检索是什么?
- 从大型集合中获取与信息需求相关的一些信息资源的活动,而后对得到的信息资源进行排序。(因此关于 ranking model 的研究是 IR 的核心问题)
-
neural ranking model 神经排序模型是什么?
- 将浅层或深层神经网络应用于IR中的排序问题。(applying shallow or deep neural networks to the ranking problem in IR)
-
neural ranking model 的强大之处?
- 能够从原始文本输入中学习排序问题,从而避免了手工特征(hand-crafted features)的诸多限制。
-
近些年被提出的排序模型(ranking models)?
- vector space models,probabilistic models,和 learning to rank (LTR) models
- 已存在的技术,特别是 LTR 模型,已经在诸如 Web 搜索引擎的许多 IR 应用中取得了巨大的成功,但是对于更复杂的检索任务,这些技术的有效性(effectiveness)依然存在很大的提升空间。
-
为什么要将 deep learning 用于排序模型?
- 深度学习已经在诸如语音识别、计算机视觉和 NLP 领域获得了激动人心的突破。从原始输入中学习抽象的表示(representations),并且模型具有足够的能力去解决困难的学习问题,这也是 IR 领域中排序模型(ranking models)所需要的。
- 此外,一方面,像 LTR 模型,依赖于手工提取的特征,这非常耗时且定义往往过于具体(不够抽象)。所以,如果排序模型可以自动学习有用的排序特征(ranking features)会有很大的价值。
- 另一方面,相关性(relevance),作为信息检索中一个重要的概念,其建立在复杂的人类认知过程之上,往往是定义模糊、难以估计的。而我们DL学习的抽象特征正可以更好的代表它。
-
信息检索中常提到 ad-hoc, routing 等术语是什么意思?参考
- 术语 ad-hoc:即这样一种场景(scenario),集合(collection)中的文档保持相对静态,而新的查询(queries)持续地提交给系统。主要研究任务包括对大数据库的索引查询、查询的扩展等等。
- 术语 routing:用户的查询要求相对稳定。在routing中,查询(query)常常称为 profile,也就是通常所说的兴趣,用户的兴趣在一段时间内是稳定不变的,但是数据库(更确切的说,是数据流)是不断变化的。主要任务不是索引,而是对用户兴趣的建模,即如何对用户兴趣建立合适的数学模型。
-
Community-based Question Answering (CQA) 基于社区论坛的问答?参考
- 主要包含两个问题,分别是 Question Semantic Matching 和 Question Answer Ranking and Retrieve.
- Question Semantic Matching:论坛的一个大问题,越来越多的问题使问题重复。进行检测以 ① 减少冗余,即如果一个人回答了这个问题一次,他不需要再回答。② 如果第一个问题有很多答案,并且询问其相似问题,那么答案可以返回给提问者。
- Question Answer Ranking and Retrieve:考虑到CQA网站接收的流量,在发布的众多答案中找到一个好答案的任务本身就是重要的。给定问题q和答案池a1…am,然后试着找到最好的候选答案。候选答案池可能包含也可能不包含多个 gold 标签。
-
什么是TREC?及相关名词 TREC 简介
- (1)TREC:text retrieval conference,文本检索会议
- (2)Track:TREC 的每个子任务 TREC-10 的所有Track ,eg:QA、Filtering、Web
- (3)Topic:预先确定的问题,用来向检索系统提问
- (4)Document:包括训练集和测试集合(TIPSTER&TREC CDs)
- (5)Relevance Judgments:相关性评估,人工或自动
- (6)Topic 的一般结构:① Title:标题,通常由几个单词构成,非常简短 ② Description:描述,一句话,比Title详细,包含了Title的所有单词 ③ Narrative:详述,更详细地介绍哪些文档是相关的
- (7)Filtering 任务:① 目标:对文档流中的每个文档,在当前的query下,确定是否要检出。② adaptive filtering:每个topic给出两个正例。 ③ batch filtering:每个topic给出 training set 中所有正例 ④ routing:同 batch filtering,但返回结果排序
- (8)QA 任务:① 目标:每个问题,不仅返回所在文档,而且要返回答案片段 ② main task:允许以“无答案”作为回答(500个问题)③ List Task:答案是列举性质的,比如,说出来自中国的10个明星?(25个问题) ④ Context Task:一组问题,其间有关联(10组)
- (9)web track 任务:① 目标:对每个topic,按相关性返回相关Web网页,测试link analysis的效果
-
closed domain 和 open domain:
- 封闭领域:系统对超出了设计的领域范围之外的,所有其它领域的信息都无能为力。
- 开放领域:所提出的问题并不局限于预定义好的领域和领域知识。在理想情况下,问答系统要有能力在很大规模的各个领域的文本中进行探索筛选,找到我们所需的答案。
-
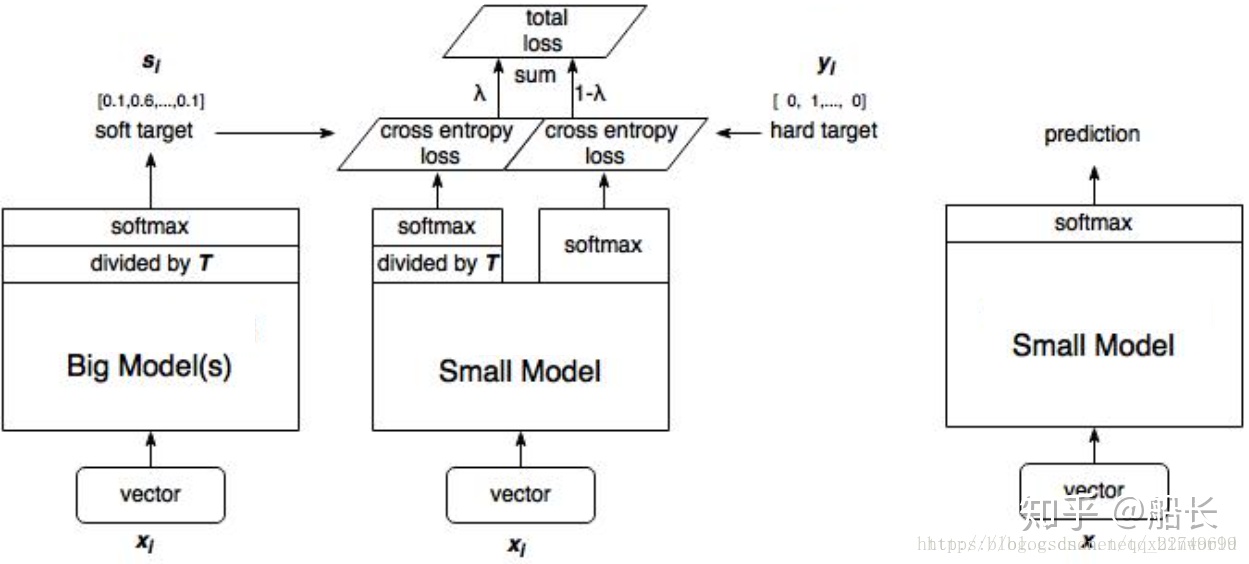
知识蒸馏 Knowledge Distillation: 知识蒸馏Knowledge Distillation
- 基本思路:一般来讲,越是复杂的网络,参数越多,计算量越大,其性能越好;越是小的网络,越难训练到大网络那么好的性能。
- 提升性能和落地部署不要用相同的模型:部署用的模型和训练提高性能用的模型,其实应用场合不一样,应该用不一样的模型!(训练用复杂大模型,目标为提高性能;而部署用小模型,目标是为了速度和节约资源)
- 知识蒸馏就是把大模型对样本输出的概率向量作为软目标“soft targets”,去让小模型的输出尽量去和这个软目标靠(原来是和One-hot编码上靠)
- 方法:引入温度参数T去放大(蒸馏出来)这些小概率值所携带的信息
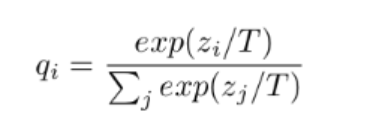
-
无偏学习和迁移学习:
- 无偏学习:如果你想做一件事,那么请直接开始做那件事
- 迁移学习:如果你无法直接做那件事,就先做些看起来有帮助的事
-
PRF 模型:pseudo-relevance feedback (PRF) models
二、神经排序模型处理的典型文本信息检索任务(textual IR tasks) Q&A
-
ad-hoc retrieval
- (1)定义:ad-hoc 检索是一个经典的检索任务,用户通过查询(query)指定他的信息需求,该query会发起一个,对可能与用户相关的文档(documents)的搜索。检索到的文档一般会通过一个 ranking model,作为一个 ranking list 返回,其中排名越靠前的文档越可能和用户查询相关。
- (2)异构性(heterogeneity):查询(query)和文档(documents)的异构性是 ad-hoc 检索的主要特征(即,查询来自搜索意图不明确的用户,且通常非常简单,几个单词到几个句子不等;而文档常来自于不同作者组,且文本长度较长,几个句子到几个段落不等。因此查询和文档结构的不同)。这种异构性导致了严重的“词汇不匹配问题”(vocabulary mismatch problem)和“不同的相关模式”(diverse relevance patterns)。
- 考虑短查询和长文档的匹配问题,提出了不同的假设(hypothesis)。eg,verbosity hypothesis(它假定文档的长度与其相关性间独立 assumes the independence of a document’s relevance of its length) 和 scope hypothesis(它假定文档的长度与其相关性间不独立).
- (3)相关性(relevance):ad-hoc 检索中的相关性本身定义模糊,并且高度依赖于用户,这使得 ad-hoc 检索中相关性评估(relevance assessment)是一个极具挑战的问题。
- (4)在 ad-hoc retrieval 任务中评估 neural ranking model 的数据集:Robust,ClueWeb,GOV2, Microblog,as well as logs such as the AOL log and the Bing Search log。以及最近的,NTCIR WWW Task。
-
Question Answering QA
- (1)定义:QA 是指根据一定的信息资源(information sources),自动回答用户通过自然语言提出的问题(question)。其中,question 可能来自 closed domain 或 open domain;information sources 可以从结构化数据(eg,knowledge base 知识库)变化到非结构化数据(eg,documents 或 文web pages)。
- (2)QA 不同的 task formats:① multiple-choice selection ② answer passage/sentence retrieval(之后的 QA 指这个特定的任务) ③ answer span locating ④ answer synthesizing from multiple sources(从多个来源合成答案)
- (3)异构性(heterogeneity):相比 ad-hoc retrieval,QA 中 ,the question 和 the answer passage/sentence 之间的异构性降低了。因为一方面,question 都使用自然语言来描述,这比关键词 query 更长,且意图描述更清楚。另一方面,the answer passage/sentence 通常比文档的文本跨度(text span)更短,这会使得 topics/semantics 更集中。
- (4)vocabulary mismatch 问题:词汇不匹配在 QA 中依然是一个 basic 的问题。
- (5)相关性(relevance):在 QA 中,相关性的概念相对清晰,即是否 target passage/sentence 回答了这个 question,但是评估(assessment)依然是具有挑战的。
- (6)评估 QA 任务的数据集:TREC QA,WikiQA,WebAP,InsuranceQA,WikiPassageQA 和 MS MARCO 等。
-
Community Question Answering CQA
- (1)定义:社区问答(CQA)旨在基于CQA网站上现有的QA资源找到用户问题的答案。eg,Yahoo! Answers,Stack Overflow,Zhihu
- (2)CQA 分类: ① 直接从答案池中检索答案,这类似于具有一些附加用户行为数据(例如,赞成/否决)的 QA 任务(根据用户的Q,找到A)。② 从问题库中检索相似的问题,假设相似问题的答案可以回答新问题。 本文将第二个任务格式称为 CQA 。
- (3)同构性(homogeneity):input question 和 target question 之间是同构性,这和前两个任务不同。
- (4)相关性(relevance):CQA 中的相关性是指语义对等/相似,在相关性定义中这两个问题是可以互换的,因此它是明确的和对称的。
- (5)vocabulary mismatch 问题:词汇不匹配仍然是具有挑战性的问题,因为这两个问题都很简短,而且对于相同的意图存在不同的表达方式。
- (6)评估 CQA 任务的数据集:eg,Quora Dataset,Yahoo! Answers Dataset,SemEval-2017 Task,CQADupStack8,ComQA9 和 LinkSO 等。
-
Automatic Conversation AC
- (1)定义:自动对话(AC)旨在创建一个自动的人机对话过程,用于question answer、task completion 和 social chat(即,chit-chat)。从信息检索角度,AC可以被表示为旨在对 dialog repository 中的适当 response 进行排序/选择的 IR 问题。( 本文限制 AC 为社交聊天任务 ,因为QA已经涵盖了问题回答,而 task completion 通常不会被视为 IR 问题。)
- (2)同构性(homogeneity):AC 也有和 CQA 一样的同构性,因为 input utterance 和 response 都是短的 natural language sentences.
- (3)相关性(relevance):AC 中的相关性指特定的语义对应(certain semantic correspondence),它的定义是宽泛的。
- (4)vocabulary mismatch 问题:词汇不匹配问题不再是 AC 的中心挑战,因为对于这个任务一个好的 response 不需要单词之间的语义匹配(semantic matching between the words)。然而,对一致性/连贯性建模变得至关重要,以避免一般琐碎的 response。
- (5)在 AC 任务中评估 neural ranking model 的数据集:eg,Ubuntu Dialog Corpus (UDC),Sina Weibo dataset ,MSDialog,”campaign” NTCIR STC 。
三、neural ranking model 的统一表示
-
符号定义:
- \(S\) 是广义查询集合(generalized query set,可以是 search queries, natural language questions 或 input utterances 的 set)
- \(T\) 是广义文档集合 (generalized document set,可以是 documents, answers 或 responses 的 set)
- \(Y = \{1,2,· · · , l\}\) 是标签集(label set, where labels represent grades)
- $s_i ∈ S $ 代表第i个query;$T_i = { t_{i,1}, t_{i,2}, ..., t_{i,n_i} } ∈ T $ 代表和 query \(s_i\) 相关的 documents 集合。
- \(y_i = \{y_{i,1}, y_{i,2}, ..., y_{i,n_i}\}\) 代表和query \(s_i\) 相关的labels集合,\(n_i\) 代表集合 \(T_i\) 的大小。
- \(y_{i,j}\) 代表了 \(t_{i,j}\) 相对于 \(s_i\) 的相关度(relevance degree)。
- \(F\) 是一个 function class,其中 \(f(s_i, t_{i,j}) ∈ F\) 是一个 ranking function,输入一个query-document pair,给出一个相关分数(relevance score)。
- \(L(f;s_i;t_{i,j},y_{i,j})\) 是一个loss function,定义在 \(f\) 基于query-document pair 给出的预测和他们对应的label之上。
-
泛化的 LTR 问题,就是在labeled dataset上去寻找最小化loss function的最优的 \(f*\) :
- ranking function \(f\) 可以进一步被抽象:
其中,s 和 t 是两个输入文本;\(\psi\) 和 \(\phi\) 是representation function,分别从 s 和 t 中提取 features;\(\eta\) 是从(s,t) pair 中提取 features 的交互函数(interaction function);\(g\) 是基于feature representations 计算相关性分数的评估函数(evaluation function)。
注:在neural ranking model中,我们认为输入可以是原始的文本,也可以是 word embeddings。也就是说,我们认为embedding mapping 是基本的输入层,不包含在 \(\psi, \phi\) 和 \(\eta\) 中。
四、model architecture
4.1 对称架构(Symmetric)与非对称架构(Asymmetric)
- 对称架构:输入文本 s 和 t 是同构的(with the underlying homogeneous assumption),所以可以 apply 对称的网络结构作用于 inputs 。即,输入s和t可以在不影响最终输出的情况下。交换它们在输入层中的位置。两类典型的对称结构:
- siamese networks:字面意思是网络结构中的对称结构。代表模型,DSSM、CLSM 和 LSTM-RNN 。(猜测大多的交互函数 \(\eta\) 是非对称的,所以这类中不使用 \(\eta\))
- symmetric interaction networks: 采用对称的交互函数 \(\eta\) (a symmetric interaction function)来表示输入。代表模型,DeepMatch、Arc-II、atchPyramid 和 Match-SRNN 。
注:因为对称架构基于同构假设,因此可以很好的适合 CQA 和 QA 任务(它们的 s 和 t 通常具有相似的长度和相似的形式)。
- 非对称架构:输入 s 和 t 是异构的(heterogeneous),因此应该在输入上应用非对称的网络结构。即,如果我们改变输入s和t在输入层中的位置,我们将得到完全不同的输出。非对称结构中使用了三种主要策略来处理查询和文档之间的异构性:
- Query split:假设 ad-hoc retrieval 中的大多数 query 是基于 keyword 的,可以将 query 拆分成词条(term),与 document 进行匹配。基于该策略的模型代表,DRMM、KNRM等。
- Document split:假设在作用域假设(scope hypothesis)下,长文档可能与查询部分相关。所以拆分文档以捕获细粒度交互信号,而不是将其作为一个整体对待。基于该策略的模型代表,HiNT。
- Joint split:同时使用查询拆分和文档拆分的假设。基于该策略的模型代表,DeepRank和PACRR。
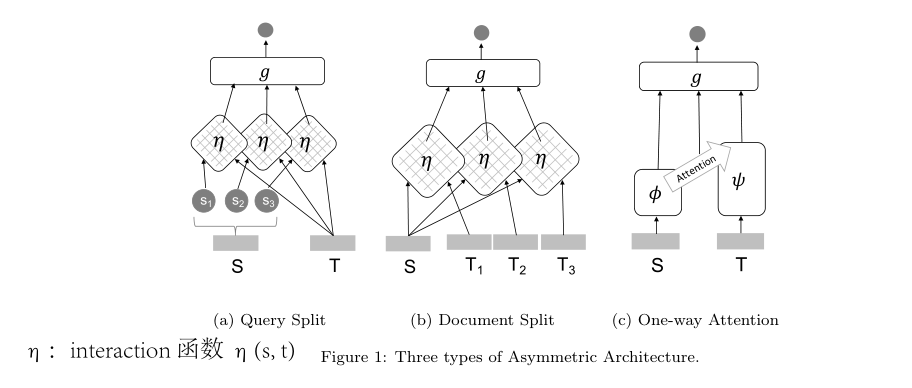
注:因为query 和 document 之间的异构性,非对称网络主要用于 ad-hoc 检索任务。也可以用于 QA 任务,其中 answer passages 被相对于 natural language questions 进行排序。
4.2 Representation-focused 与 Interaction-focused 架构
- 基于对relevance evaluation的,不同的关于features的假设进行分类。
-
Representation-focused architecture:
- 这种结构的基本假设是关联性取决于输入文本(input texts)的构成意义(compositional meaning)。
- 这类模型通常定义复杂的representation function \(\psi, \phi\)(即,deep neural networks,eg,FCNN、CNN或RNN),但是没有 interaction function \(\eta\) ,并且使用简单的 evaluation function \(g\)(例如,cosine function 或 MLP)去产生最后的 relevance score。
- ① representation-focused architecture 可以更好地将任务与全局匹配(global matching)的需求相匹配。② 更适合短输入文本的任务,因为对于长文本而言,很难获得好的高层表示。eg,CQA 和 AC 就有这样的特征。③ 此外,这类模型对于在线计算很有效,一旦预先学习了\(\psi\) 和 \(\phi\),就可以离线预先计算文本的表示。
-
Interaction-focused Architecture:
- 这类架构的基本假设是,相关性(relevance)本质上是输入文本间的关系(relation)。
- 因此,这类模型定义了复杂的interaction function \(\eta\),没有定义 representation function \(\psi\) 和 \(\phi\),同时使用了复杂的 evaluation function \(g\) 对 interaction 进行抽象,并产生最后的 relevance score。
- 对于已经被提出的 interaction function,可以分为两类:
- ① Non-parametric interaction functions:没有可学习的参数。eg,一些是基于每对儿 input word vectors 定义的;一些是基于一个 word vector 和一组 word vectors 之间关系定义的。
- ② parametric interaction functions:从数据中学习相似度/距离函数。当有足够的训练数据时可以采用参数交互函数,因为它们以更大的模型复杂度为代价带来了模型灵活性。
- ① 将evaluation relevance 直接定义在 interactions上,这类模型可以满足大多数的IR任务。② 此外,通过使用详细的交互信号而不是单个文本的高级表示,该结构可以更好地适合需要特定匹配模式(例如,exact word matching)和不同的匹配要求的任务,eg,ad-hoc retrieval 任务。③ 该结构可以更好地拟合异构输入的任务,eg,ad-hoc retrieval 和 QA 任务,因为避开了对于长文本的编码过程。 ④ 但是该类模型对于在线计算不是很有效,因为交互函数 \(\eta\) 不能被提前计算,只有看到了输入对\((s,t)\) 后才可以。
4.3 Single-granularity 与 Multi-granularity 架构
- evaluation function \(g\), 根据对相关性估计过程(the estimation process for relevance)的不同假设,将现有的神经网络排序模型分为单粒度模型和多粒度模型。
-
Single-granularity 架构:单粒度体系结构的基本假设是,可以基于\(φ\),\(ψ\)和\(η\)从单格式文本输入中提取的高层特征来评估相关性。这种假设下,\(φ\), \(ψ\) 和 \(η\) 实际上被视为评估函数 \(g\) 的黑盒。同时,输入s和t被简单地视为 words 或 word embeddings的集合/序列(set/sequence),没有任何附加的语言结构。eg,DSSM、MatchPyramid、DRMM、HiNT、ARC-I、MV-LSTM、K-NRM、Match-SRNN等。
-
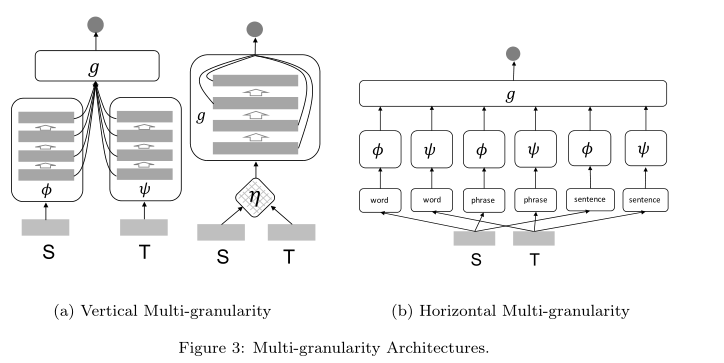
Multi-granularity 架构:多粒度架构的基本假设是相关性估计(relevance estimation)需要多粒度的特征,要么来自不同级别的特征抽象(feature abstraction),要么基于输入的不同类型的语言单元(different types of language units)。在此假设下,表示函数φ,ψ和交互函数η不再是g的黑盒,我们考虑s和t中的语言结构,可以识别出两种基本的多粒度类型,即垂直多粒度(vertical multi-granularity)和水平多粒度(horizontal multi-granularity)。
- 垂直多粒度:利用了深层网络的分层性质,使得评估函数g可以利用特征的不同级别抽象来进行相关性估计。
- 水平多粒度:通过将输入从单词(words)扩展到短语/n元串(phrases/n-grams)或句子(sentences)来增强输入,在每个输入形式上应用特定的单粒度体系结构,并聚合最终相关性输出的所有粒度。
- 通过提取多粒度特征,该类别的模型可以更好地拟合需要细粒度匹配信号进行相关性计算的任务,eg,ad-hoc retrieval 和 QA。当然,增强的模型能力通常是以更大的模型复杂性为代价的。
五、Model Learning
5.1 学习目标 Learning objective
5.1.1. Pointwise Ranking Objective 逐点学习
- 定义:给定一组查询文档对 \((s_i, t_{i,j})\) 及其对应的relevance annotation \((y_{i,j})\),pointwise ranking objective 试图通过要求排名模型直接预测 \(y_{i,j}\)for \((s_i,t_{i,j})\)来优化排名模型。换言之,pointwise ranking objective 的损失函数是基于每个\((s,t)\)对儿独立计算的。
- eg, cross entropy 交叉熵损失函数—最流行的pointwise loss function 之一。(如果是数值labels,MSE 均方误差)
-
优点:① pointwise ranking objectives 基于每个query-document pair \((s_i, t_{i,j})\) 分别计算,这使得它很简单且易于扩展。 ②以 pointwise loss function 作为损失函数的 neural model 的输出往往在实际中有真实的含义和价值。
-
缺点:一般而言,按点排序目标在排序任务中被认为效率较低。因为逐点损失函数不考虑文档偏好或排序信息,因此它们不能保证在模型损失达到全局最小值时可以生成最佳的排序列表。
5.1.2. Pairwise Ranking Objective
- 定义:成对排序目标侧重于优化文档之间的相对偏好,而不是它们的标签。其基于所有可能的文档对的排列来计算成对损失函数。
其中,\(t_{i,j}\) 和 \(t_{i,k}\) 是和query \(s_i\) 相关的两个文档,其中,\(t_{i,j}\) 比 \(t_{i,k}\) 更可取(即,$ y_{i,j} \succ y_{i,k}$)。
- eg,一个著名的pairwise loss function 是 Hingle loss:
- eg,另一个流行的pairwise 损失函数是pairwise cross entropy:
其中,\(\sigma\) 是sigmoid 函数。
-
优点:理想情况下,当成对排序损失最小化时,文档之间的所有偏好关系都应该得到满足,并且模型将为每个查询生成最优结果列表。这使 pairwise ranking objectives 在根据相关文档的排序来评估性能的许多任务中有效。
-
缺点:然而,在实践中,由于以下两个原因,在 pairwise 方法中优化文档偏好并不总是导致最终ranking metrics 的改进:
- ① 开发一个在所有情况下都能正确预测文档偏好的排序模型是不可能的。
- ② 在大多数现有排名度量的计算中,并不是所有的文档对都同等重要。
5.1.3. Listwise Ranking Objective
- 定义:主要思想是构造直接反映模型最终排序性能的损失函数。不再是每次比较两个文档,listwise loss function 一起计算每个查询及其候选文档列表的 ranking loss。
其中,\(T_i\) 是 query \(s_i\) 的候选文档集合。\(L\) 定义为按\(y_{i,j}\) 排序的文档列表(称为\(π_i\))和按\(f(s_i, t_{i,j})\) 排序的文档列表的函数。
-
eg,ListMLE、Attention Rank function(函数见论文23页)
-
优点:① 当我们在无偏学习框架下用用户行为数据(例如,点击)训练神经排序模型时,它特别有用。② 它们适用于对一小部分候选文档的重新排序阶段(re-ranking phase)。由于许多实用的搜索系统现在使用神经模型进行文档重新排序,因此 Listwise Ranking Objective 在神经排序框架中变得越来越流行。
-
缺点:虽然列表排序目标通常比成对排序目标更有效,但其高昂的计算成本往往限制了它们的应用。
5.1.4. Multi-task Learning Objective
- 定义:在某些情况下,神经排序模型的优化可能包括同时学习多个排序或非排序目标。这种方法背后的动机是使用来自一个领域的信息来帮助理解来自其他领域的信息。
- 一般而言,现有的多任务学习算法最常用的方法是构造对多个任务或域中的排序普遍有效的共享表示。
5.2 训练策略 Training Strategies
- Supervised learning:监督学习是指对查询-文档对进行标记的最常见的学习策略。数据可以由专家、众包来标记,或者可以从用户与搜索引擎的交互中收集,作为隐式反馈。在该训练策略中,假设有足够数量的标记训练数据可用。然而,由于通常是“数据饥渴”的,标注的数据有限,在这种训练模式下只能学习参数空间受限的模型。
- Weakly supervised learning:弱监督学习指的是使用诸如BM25的现有检索模型自动生成查询文档标签的学习策略。该学习策略不需要带标签的训练数据。除了 ranking 之外,弱监督已经在其他信息检索任务中显示出成功的结果,eg,query performance prediction 、learning relevance-based
word embedding 和 efficient learning to rank 等。 - Semi-supervised learning:半监督学习指的是一种学习策略,它利用一小组已标记的query-document pair 加上一大组未标记的数据。
六、模型比较
-
在 ad-hoc retrieval 任务上的比较
- ① 概率模型(即QL和BM25)虽然简单,但已经可以达到相当好的性能。具有人为设计特征的传统PRF模型(RM3)和LTR模型(RankSVM和LambdaMart)是强基线,其性能是大多数基于原始文本的神经排序模型难以比拟的。然而,PRF技术也可以用来增强神经排序模型,而人类设计的LRT特征可以集成到神经排序模型中以提高排序性能。
- ② 随着时间的推移,该任务中的 neural ranking model architecture 似乎从对称到不对称,从以表示为中心到以交互为中心的范式发生转变。的确,不对称和以交互为中心的结构可能更适合表现出异构性的ad-hoc检索任务。
- ③ 在不同数量的查询和标签方面具有更大的数据量的神经模型更有可能获得更大的性能改进。(与非神经模型相比)
- ④ 观察到,通常情况下,非对称的、关注交互的、多粒度的架构可以在ad-hoc检索任务中工作得更好。
-
在 QA 任务上的比较
- ① 可能因为问题和答案之间的同构性的增加,对称(symmetric)结构在 QA 任务中得到了更广泛的采用。
- ② 在QA任务中,以表示为中心的架构和以交互为中心的架构没有一个明显的胜者。在 short answer sentence retrieval 数据集(即TREC QA和WikiQA)上更多地采用了以表示为中心的架构,而在longer answer passage retrieval 数据集(例如Yahoo!)上更多地采用了以交互为中心的架构。
- ③ 与ad-hoc检索类似,在较大的数据集上,神经模型比非神经模型更有可能获得更大的性能改进。
七、未来可能的趋势
- Indexing: from Re-ranking to Ranking
- Learning with External Knowledge
- Learning with Visualized Technology
- Learning with Context
- Neural Ranking Model Understanding
- ……
需要查询的问题
- learning to rank(LTR)模型 参考资料
- 可以看下这篇 paper Mitra and Craswell [41] gave an introduction to neural information retrieval.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号