scrapy爬虫基础及简单使用
https://docs.scrapy.org/
scrapy介绍
Scrapy 是一个用于抓取网站和提取结构化数据的应用程序框架,可用于各种有用的应用程序,如数据挖掘、信息处理或历史档案。
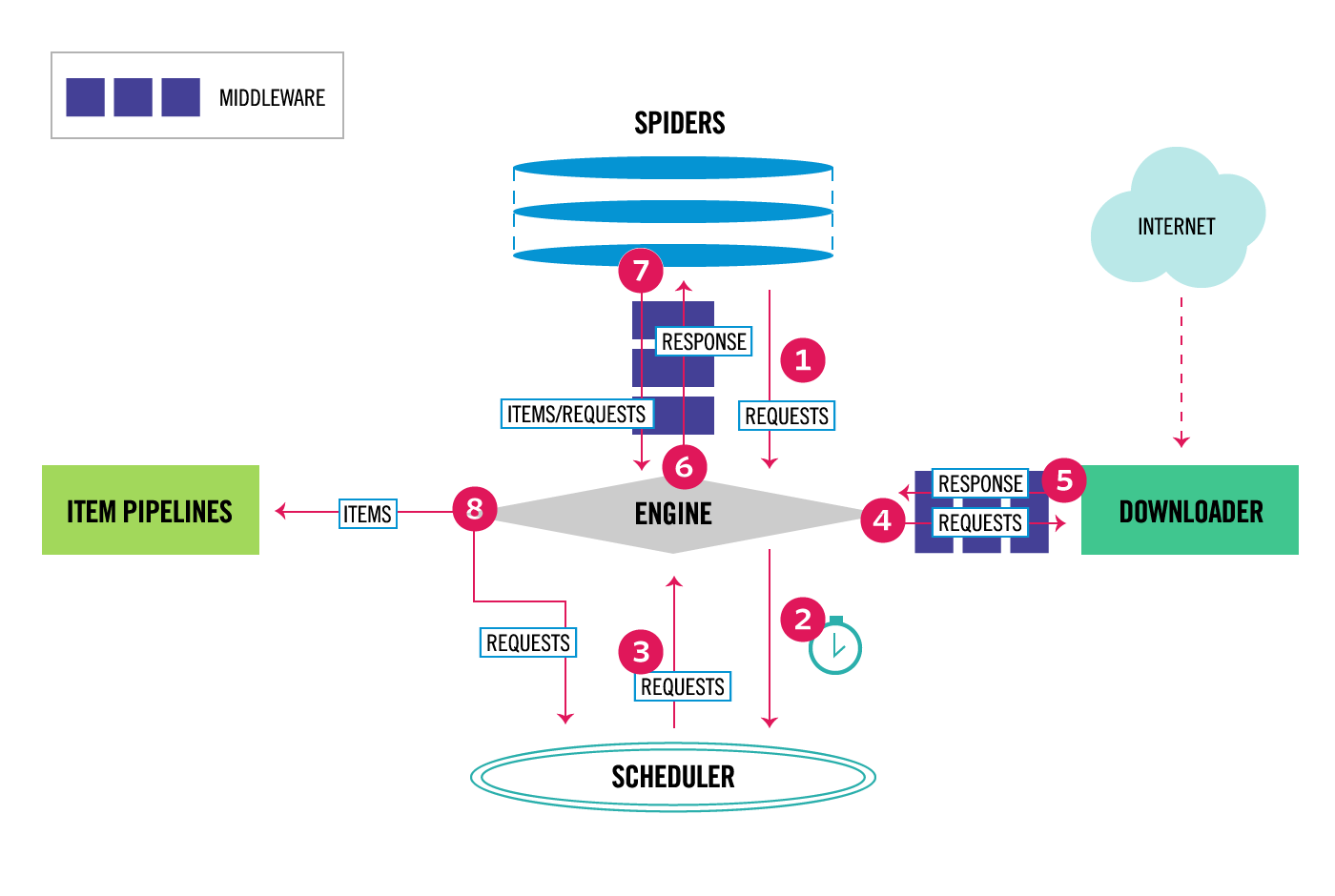
Scrapy 中的数据流由执行引擎控制,如下所示:
1 引擎从 Spider 获取初始爬行请求。
2 引擎在调度器中调度请求,并要求抓取下一个请求。
3 调度器将下一个请求返回给引擎。
4 引擎通过下载器中间件将请求发送到下载器。
5 一旦页面完成下载,下载器就会生成一个响应并将其通过下载器中间件发送到引擎。
6 引擎从下载器接收响应,并将其通过 Spider 中间件发送到 Spider 进行处理。
7 Spider 处理响应,并通过 Spider 中间件将抓取的项目和新的请求返回给引擎。
8 引擎将已处理的项目发送到项目管道,然后将处理后的请求发送到调度器,并要求可能的下一个请求进行爬取。
9 该过程重复(从步骤 3 开始),直到调度器没有更多请求为止。
Scrapy 引擎
引擎负责控制系统所有组件之间的数据流,并在发生某些操作时触发事件。
调度器
调度器从引擎接收请求,并将其排队,以便稍后在引擎请求时将其提供给引擎。
下载器
下载器负责获取网页并将其提供给引擎,引擎又将其提供给与蜘蛛。
蜘蛛
Spider 是由 Scrapy 用户编写的自定义类,用于解析响应并从中提取项目或后续的其他请求。
项目管道
项目管道负责在蜘蛛提取项目后对其进行处理。典型的任务包括清理、验证和持久化(如将项目存储在数据库中)。
下载器中间件
下载器中间件是位于引擎和下载器之间的特定钩子,当请求从引擎传递到下载器时,它会处理请求,并将响应从下载器传递到引擎。
如果需要执行以下操作之一,请使用 Downloader 中间件:
在请求发送到下载器之前(即在 Scrapy 将请求发送到网站之前)处理请求;
在将收到的响应传递给蜘蛛之前对其进行更改;
发送新的请求,而不是将收到的响应传递给蜘蛛;
将响应传递给蜘蛛,而不获取网页;
默默地放弃一些请求。
蜘蛛中间件
Spider 中间件是位于引擎和 Spider 之间的特定钩子,能够处理 Spider 输入(响应)和输出(项目和请求)。
如果需要,请使用 Spider 中间件:
蜘蛛回调的后处理输出-更改/添加/删除请求或项目;
后处理 start_requests;
处理蜘蛛异常;
根据响应内容,对某些请求调用 errback 而不是回调。
命令行
#获取版本
scrapy version [-v]
#创建新项目
scrapy startproject <project_name> [project_dir]
scrapy startproject myproject
#查看预定义的蜘蛛模板
scrapy genspider -l
#创建新的蜘蛛
scrapy genspider [-t template] <name> <domain or URL>
scrapy genspider mydomain mydomain.com
scrapy genspider -t crawl scrapyorg scrapy.org
#爬取页面
scrapy crawl <spider>
scrapy crawl myspider
scrapy crawl -o myfile:csv myspider
scrapy crawl -O myfile:json myspider
scrapy crawl -o myfile -t csv myspider
#运行蜘蛛检查
scrapy check [-l] <spider>
scrapy check
#查看蜘蛛列表
scrapy list
#下载页面
scrapy fetch <url>
scrapy fetch --nolog http://www.example.com/some/page.html
scrapy fetch --nolog --headers http://www.example.com/
#以蜘蛛的角度在浏览器中打开页面
scrapy view <url>
scrapy view http://www.example.com/some/page.html
#用于蜘蛛调试
scrapy shell [url]
scrapy shell http://www.example.com/some/page.html
scrapy shell --nolog http://www.example.com/ -c '(response.status, response.url)'
#用于蜘蛛调试
scrapy parse <url> [options]
scrapy parse http://www.example.com/ -c parse_item
#获取设置项
scrapy settings [options]
scrapy settings --get BOT_NAME
scrapy settings --get DOWNLOAD_DELAY选择器
xpath 选择器
response.xpath("//title/text()").getall()
response.xpath("//title/text()").get()
response.xpath('//div[@id="images"]/a/text()').get()
response.xpath('//div[@id="not-exists"]/text()').get(default="not-found")
response.xpath("//base/@href").get()
response.xpath('//a[contains(@href, "image")]/@href').getall()
response.xpath('//a[contains(@href, "image")]')[0].xpath("img/@src").get()
response.xpath('//a[contains(@href, "image")]/text()').re(r"Name:\s*(.*)")
response.xpath('//a[contains(@href, "image")]/text()').re_first(r"Name:\s*(.*)")
response.xpath('//li[1]').getall()
response.xpath('(//li)[1]').getall()
response.xpath("string(//a[1]//text())").getall()
response.xpath("//div[@id=$val]/a/text()", val="images").get()
response.xpath('//li[re:test(@class, "item-\d$")]//@href').getall()
response.xpath('//p[has-class("foo")]')
response.xpath('//p[has-class("foo", "bar-baz")]')
css 选择器
response.css("title::text").get()
response.css("img").attrib["src"]
response.css("base").attrib["href"]
response.css("base::attr(href)").get()
response.css("a[href*=image]::attr(href)").getall()
response.css("#images *::text").getall()
response.css("img::text").get(default="")
response.css("a::attr(href)").getall()
response.css("a::attr(href)").extract_first()
response.css("a::attr(href)").extract()
混用
response.css("img").xpath("@src").getall()
response.css(".shout").xpath("./time/@datetime").getall()AutoThrottle 扩展
用于根据 Scrapy 服务器和正在爬行的网站的负载自动限制爬行速度。
设计目标:
对网站更友好,而不是使用默认的零下载延迟
自动将 Scrapy 调整到最佳爬行速度,这样用户就不必调整下载延迟来找到最佳延迟。用户只需要指定它允许的最大并发请求数,其余的由扩展完成。
AutoThrottle 扩展动态调整下载延迟,使蜘蛛平均向每个远程网站发送 AUTOTHROTTLE_TARGET_CONCURRENCY 并发请求。
它使用下载延迟来计算延迟。主要思想如下:如果服务器需要延迟秒来响应,客户端应该每延迟/N 秒发送一个请求,以并行处理 N 个请求。
设置一个小的固定下载延迟,并使用 CONCURRENT_REQUESTS_PER_DOMAIN 或 CONCURRENT-REQUESTS_PER_IP 选项对并发性施加硬限制。它将提供类似的效果,但有一些重要的区别:
因为下载延迟很小,所以偶尔会出现突发请求;
通常,非 200(错误)响应的返回速度比常规响应快,因此,当服务器开始返回错误时,具有较小的下载延迟和硬并发限制的爬虫将更快地向服务器发送请求。但这与爬虫应该做的相反——在发生错误的情况下,放慢速度更有意义:这些错误可能是由高请求率引起的。
AutoThrottle 没有这些问题。
节流算法
AutoThrottle 算法根据以下规则调整下载延迟:
蜘蛛总是以 AUTOTHROTTLE_START_DELAY 的下载延迟开始;
当收到响应时,目标下载延迟计算为 latency/N,其中 latency 是响应的延迟,N 是 AUTOTHROTTLE_TARGE_CONCURRENCY。
将下一个请求的下载延迟设置为先前下载延迟和目标下载延迟的平均值;
不允许非 200 个响应的延迟来减少延迟;
下载延迟不能小于 DOWNLOAD_DELAY 或大于 AUTOTHROTTLE_MAX_DELAY
注:
AutoThrottle 扩展支持并发性和延迟的标准 Scrapy 设置。这意味着它将尊重 CONCURRENT_REQUESTS_PER_DOMAIN 和 CONCURRENTREQUESTS_PER_IP 选项,并且永远不会将下载延迟设置为低于 DOWNLOAD_DELAY
在 Scrapy 中,下载延迟是通过建立 TCP 连接和接收 HTTP 标头之间经过的时间来衡量的。
请注意,在协作多任务环境中,这些延迟很难准确测量,因为例如,Scrapy 可能正忙于处理蜘蛛回调,无法参加下载。然而,这些延迟仍然可以合理地估计 Scrapy(最终是服务器)的繁忙程度,而这个扩展就是建立在这个前提之上的。
AUTOTHROTTLE_ENABLED
默认值:False
启用 AutoThrottle 扩展。
AUTOTHROTTLE_START_DELAY
默认值:5.0
初始下载延迟(秒)。
AUTOTHROTTLE_MAX_DELAY
默认值:60.0
在高延迟的情况下设置的最大下载延迟(秒)。
AUTOTHROTTLE_TARGET_CONCURRENCY
默认值:1.0
Scrapy 应并行发送到远程网站的平均请求数。
默认情况下,AutoThrottle 会调整延迟,以便向每个远程网站发送单个并发请求。将此选项设置为更高的值(例如 2.0),以增加远程服务器上的吞吐量和负载。较低的 AUTOTHROTTLE_TARGET_CONCURRENCY 值(例如 0.5)会使爬虫更加保守和礼貌。
请注意,启用 AutoThrottle 扩展时,CONCURRENT_REQUESTS_PER_DOMAIN 和 CONCURRENT_REQUESTS_PER_IP 选项仍然受到尊重。这意味着,如果将 AUTOTHROTTLE_TARGET_CONCURRENCY 设置为高于 CONCURRENT_REQUESTS_PER_DOMAIN 或 CONCURRENT-REQUESTS_PER_IP 的值,则爬虫将无法达到此数量的并发请求。
在每个给定的时间点,Scrapy 可以发送比 AUTOTHROTTLE_TARGET_CONCURRENCY 更多或更少的并发请求;这是爬虫试图接近的建议值,而不是硬限制。
AUTOTHROTTLE_DEBUG
默认值:False
启用自动节流调试模式,该模式将显示收到的每个响应的统计数据,以便您可以实时查看节流参数是如何调整的。简单使用
命令行生成项目目录,并创建需要的蜘蛛
scrapy startproject zi
cd zi
scrapy genspider quotes
scrapy genspider author
scrapy genspider doc为蜘蛛创建各自的Item和项目管道用于数据的持久化
items.py
import scrapy
class DocItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
class AuthorItem(scrapy.Item):
name = scrapy.Field()
birthdate = scrapy.Field()
desc = scrapy.Field()
class QuotesItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()pipelines.py
from itemadapter import ItemAdapter
class DocPipeline:
def __init__(self) -> None:
self.f = None
def open_spider(self, spider):
self.f = open("./doc.txt", "w+", encoding="utf-8-sig")
def process_item(self, item, spider):
self.f.write("title:{} | url:{}\n".format(item["title"], item["url"]))
return item
def close_spider(self, spider):
self.f.close()
class AuthorPipeline:
def __init__(self) -> None:
self.f = None
def open_spider(self, spider):
self.f = open("./author.txt", "w+", encoding="utf-8-sig")
def process_item(self, item, spider):
self.f.write("name:{} | birthdate:{} | desc:{}\n".format(item["name"], item["birthdate"], item["desc"]))
return item
def close_spider(self, spider):
self.f.close()
class QuotesPipeline:
def __init__(self) -> None:
self.f = None
def open_spider(self, spider):
self.f = open("./quotes.txt", "w+", encoding="utf-8-sig")
def process_item(self, item, spider):
self.f.write("content:{} | author:{} | tages:{}\n".format(item["text"], item["author"], item["tags"]))
return item
def close_spider(self, spider):
self.f.close()spiders/DocSpider.py
import scrapy, re
from scrapy.http import Response
from ..items import DocItem
class DocSpider(scrapy.Spider):
name = "doc"
custom_settings = {
"ITEM_PIPELINES": {
"zi.pipelines.DocPipeline": 300,
}
}
start_urls = ["https://www.learnpython.cn/python-tutorial/begin-runenv.html"]
def parse(self, response):
titles_exc = []
for l1 in response.css("li.toctree-l1"):
titles_exc.append(l1.css("a.reference.internal::text").get().strip())
for l2 in response.css("li.toctree-l2"):
titles_exc.append(l2.css("a.reference.internal::text").get().strip())
for t in response.css("a.reference.internal"):
title = re.sub(r"\s+", "", t.xpath(".//text()").get())
if title in titles_exc:
url = ""
else:
url = t.attrib["href"]
yield {"title": title, "url": url}spiders/AuthorSpider.py
import scrapy
from ..items import AuthorItem
class AuthorSpider(scrapy.Spider):
name = "author"
custom_settings = {
"ITEM_PIPELINES": {
"zi.pipelines.AuthorPipeline": 300,
}
}
start_urls = ["http://quotes.toscrape.com/"]
def parse(self, response):
# for href in response.css(".author + a::attr(href)"):
# yield response.follow(href, self.parse_author)
# for href in response.css("li.next a::attr(href)"):
# yield response.follow(href, self.parse)
for href in response.xpath("//*[@class='author']/following-sibling::a/@href"):
yield response.follow(href, self.parse_author)
for href in response.xpath("//li[@class='next']/a/@href"):
yield response.follow(href, self.parse)
def parse_author(self, response):
# def extract_with_css(query):
# return response.css(query).get(default="").strip()
# yield {
# "name": extract_with_css("h3.author-title::text"),
# "birthdate": extract_with_css(".author-born-date::text"),
# "bio": extract_with_css(".author-description::text"),
# }
def extract_with_xpath(query):
return response.xpath(query).get(default="").strip()
yield {
"name": extract_with_xpath("//h3[@class='author-title']/text()"),
"birthdate": extract_with_xpath("//*[@class='author-born-date']/text()"),
"desc": extract_with_xpath("//*[@class='author-description']/text()"),
}spiders/QuotesSpider.py
import scrapy
from scrapy.http import Response
from ..items import QuotesItem
class QuotesSpider(scrapy.Spider):
name = "quotes"
custom_settings = {
"ITEM_PIPELINES": {
"zi.pipelines.QuotesPipeline": 300,
}
}
# start_urls = ["http://quotes.toscrape.com/page/1/"]
def start_requests(self):
url = "http://quotes.toscrape.com/"
tag = getattr(self, "tag", None)
if tag is not None:
url = url + "tag/" + tag
yield scrapy.Request(url, self.parse)
def parse(self, response):
# for quote in response.css("div.quote"):
# yield {
# "text": quote.css("span.text::text").get(),
# "author": quote.css("small.author::text").get(),
# "tags": quote.css("div.tags a.tag::text").getall(),
# }
# next_page = response.css("li.next a::attr(href)").get()
# if next_page is not None:
# yield response.follow(next_page, self.parse)
for quote in response.xpath("//div[@class='quote']"):
yield {
"text": quote.xpath("span[@class='text']/text()").get(),
"author": quote.xpath("small[@class='author']/text()").get(),
"tags": quote.xpath("div[@class='tags']/a[@class='tag']/text()").getall(),
}
next_page = response.xpath("//li[@class='next']/a/@href").get()
self.logger.warning("next_page: %s", next_page)
if next_page is not None:
yield response.follow(next_page, self.parse)所有蜘蛛放在一起运行 scrapy.cfg同级目录建立run.py
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
process = CrawlerProcess(get_project_settings())
process.crawl("doc")
process.crawl("author")
process.crawl("quotes")
process.start()
 浙公网安备 33010602011771号
浙公网安备 33010602011771号