


python---类的定义和使用
# 一般,使用 class 语句来创建一个新类,class之后为类的名称(通常首字母大写)并以冒号结尾,例如: # 类中可以定义所使用的方法,类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self; # init()方法是一种特殊的方法,被称为类的初始化方法,当创建这个类的实例时就会调用该方法; # self 代表类的实例,self 在定义类的方法时是必须有的,虽然在调用时不必传入相应的参数; # 类的定义 class Ticket(): def __init__(self,checi,fstation,tstation,fdate,ftime,ttime): self.checi=checi self.fstation=fstation self.tstation=tstation self.fdate=fdate self.ftime=ftime self.ttime=ttime def printinfo(self): print("车次:",self.checi) print("出发站:", self.fstation) print("到达站:", self.tstation) print("出发时间:", self.fdate) #类的对象的创建: #创建a1对象 a1=Ticket("G2020","shenyang","shandong",'2020-03-31','15:00','18:00') #创建a2对象 a2=Ticket("T2019","wuhan","chongqing",'2020-03-30','13:00','19:00') #最后是对象属性的访问: a1.printinfo() a2.printinfo()
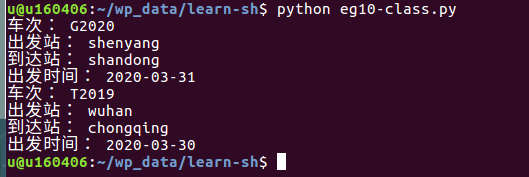
# eg9-train-val-txt.py
# _*_ coding:utf8 _*_ ################################################################### ## 定义一个类,这个类将用于批量处理图像,包括若干功能: ## (1)统一图像的格式为jpg。 ## (2)将多个图片文件夹构造成一个用于图像分类的数据集,产生txt文件,每一行的格式为:图片路径 标签 ## (3)txt文件按照7:3的比例分为训练集和测试集,并随机打乱顺序 ################################################################### import os import sys import shutil import cv2 import random # 类的定义 class GeneDataset(): def __init__(self, rootdir): self.rootdir = rootdir self.subdirs = [] self.subdirimages = [] self.numclasses = 0 self.lines = [] def looksubdir(self): list_dirs = os.walk(self.rootdir) for root, dirs, files in list_dirs: for d in dirs: self.subdirs.append(os.path.join(root,d)) print( "subdir=",os.path.join(root,d) ) #print "subdir=",os.path.join(root,d) self.numclasses = self.numclasses + 1 def reformat(self): label = 0 for subdir in self.subdirs: list_dirs = os.walk(subdir) for root, dirs, files in list_dirs: for f in files: srcname = os.path.join(root,f) print( "srcname",srcname ) #print "srcname",srcname srcformat = srcname.split('.')[-1] if srcformat is not ".jpg": img = cv2.imread(srcname) newname = srcname.replace(srcformat,'jpg') print( "newname=",newname ) #print "newname=",newname cv2.imwrite(newname,img) self.lines.append(newname+' '+str(label)+'\n') os.remove(srcname) label = label + 1 def split_train_val(self,trainfile,testfile): if len(self.lines): random.shuffle(self.lines) ftrainfile = open(trainfile,'w') ftestfile = open(testfile,'w') trainlength = int(0.7*len(self.lines)) for i in range(0,trainlength): ftrainfile.write(self.lines[i]) for i in range(trainlength,len(self.lines)): ftestfile.write(self.lines[i]) # 类的创建和使用 #myclassdataset = GeneDataset(sys.argv[1]) myclassdataset = GeneDataset("/home/u/wp_data/learn-sh/新图像/") myclassdataset.looksubdir() myclassdataset.reformat() myclassdataset.split_train_val('train.txt','test.txt')
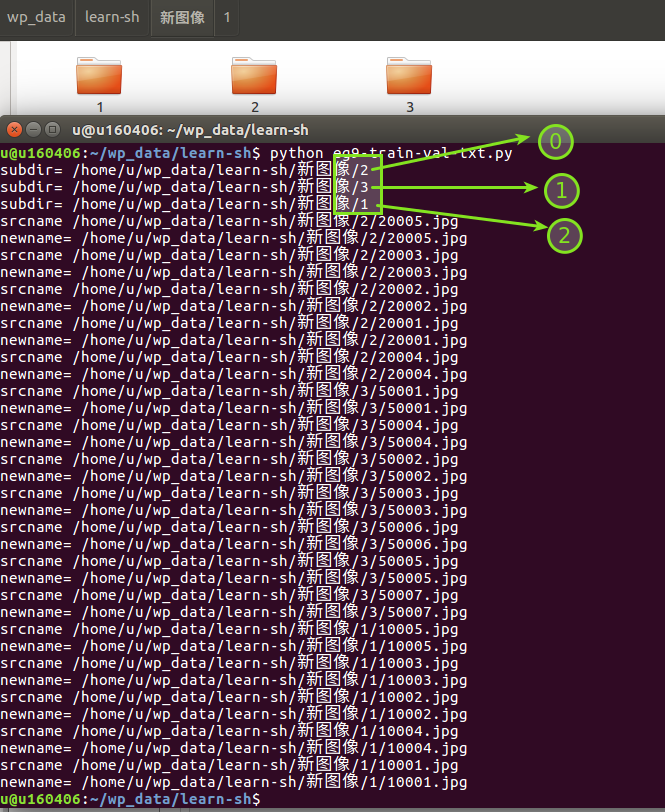
# train.txt /home/u/wp_data/learn-sh/新图像/2/20001.jpg 0 /home/u/wp_data/learn-sh/新图像/3/50006.jpg 1 /home/u/wp_data/learn-sh/新图像/2/20003.jpg 0 /home/u/wp_data/learn-sh/新图像/3/50004.jpg 1 /home/u/wp_data/learn-sh/新图像/3/50007.jpg 1 /home/u/wp_data/learn-sh/新图像/2/20004.jpg 0 /home/u/wp_data/learn-sh/新图像/3/50005.jpg 1 /home/u/wp_data/learn-sh/新图像/1/10005.jpg 2 /home/u/wp_data/learn-sh/新图像/2/20002.jpg 0 /home/u/wp_data/learn-sh/新图像/1/10001.jpg 2 /home/u/wp_data/learn-sh/新图像/3/50001.jpg 1 # test.txt /home/u/wp_data/learn-sh/新图像/1/10002.jpg 2 /home/u/wp_data/learn-sh/新图像/3/50003.jpg 1 /home/u/wp_data/learn-sh/新图像/1/10003.jpg 2 /home/u/wp_data/learn-sh/新图像/3/50002.jpg 1 /home/u/wp_data/learn-sh/新图像/1/10004.jpg 2 /home/u/wp_data/learn-sh/新图像/2/20005.jpg 0
【. . . . . .本博客仅作个人生活、工作、学习等的日常记录。说明: (1) 内容有参考其他博主、网页等,有因“懒”直接粘贴来,会备注出处。若遇雷同,或忘备注,并无故意抄袭之意,请诸“原主”谅解,很感谢您的辛勤"笔记"可供本人参考学习。 (2) 如遇同行,有参考学习者,因个人学识有限,不保证所写内容完全正确。您对本博文有任何的意见或建议,欢迎留言,感谢指正。 (3) 若您认为本主的全博客还不错,可以点击关注,便于互相学习。 (4) 感谢您的阅读,希望对您有一定的帮助。欢迎转载或分享,但请注明出处,谢谢。. . . . . .】
【作者: Carole0904 ; 出处: https://www.cnblogs.com/carle-09/ 】
