

yolo---参数解释之训练log中各参数
yolo---参数解释之训练log中各参数
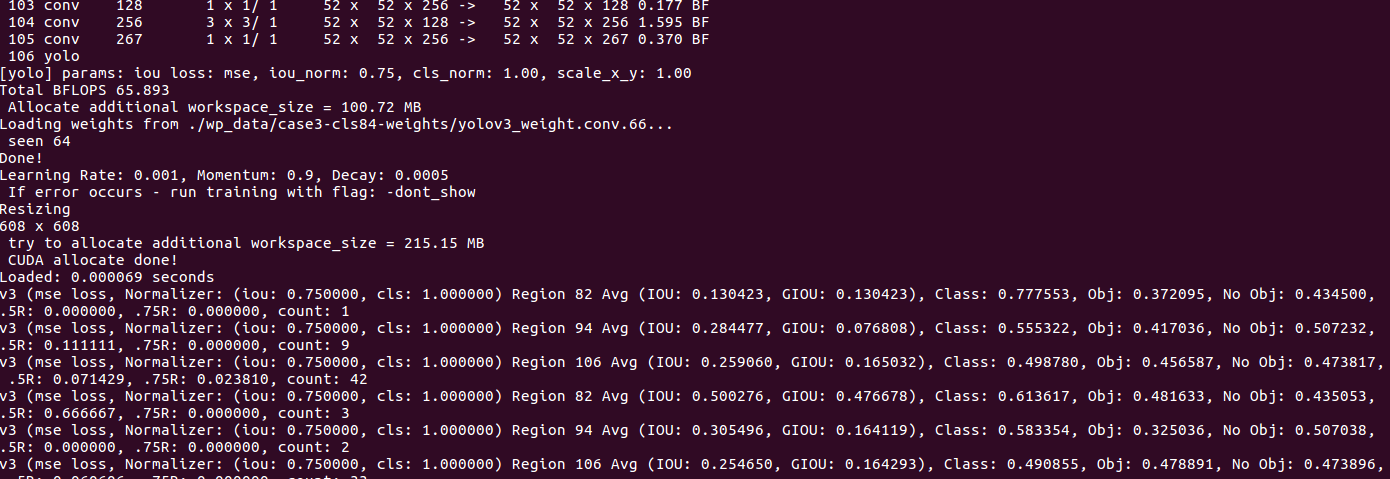
******训练log中各参数的意义************************************************************* yolov3-voc Learning Rate: 0.001, Momentum: 0.9, Decay: 0.0005 Resizing 384 Loaded: 0.000077 seconds Region 82 Avg IOU: 0.293486, Class: 0.443128, Obj: 0.680025, No Obj: 0.532993, .5R: 0.142857, .75R: 0.000000, count: 7 Region 94 Avg IOU: 0.203765, Class: 0.575399, Obj: 0.361495, No Obj: 0.513690, .5R: 0.000000, .75R: 0.000000, count: 4 Region 106 Avg IOU: 0.148327, Class: 0.769327, Obj: 0.539390, No Obj: 0.469288, .5R: 0.000000, .75R: 0.000000, count: 1 ... ... ... Region 82 Avg IOU: 0.257638, Class: 0.441840, Obj: 0.617525, No Obj: 0.531992, .5R: 0.071429, .75R: 0.000000, count: 14 Region 94 Avg IOU: 0.070440, Class: 0.604375, Obj: 0.246185, No Obj: 0.513274, .5R: 0.000000, .75R: 0.000000, count: 6 Region 106 Avg IOU: 0.072315, Class: 0.733155, Obj: 0.818539, No Obj: 0.469309, .5R: 0.000000, .75R: 0.000000, count: 1 156: 840.799866, 840.799866 avg, 0.000000 rate, 1.843955 seconds, 64 images
******************************************************************* 训练结果显示参数说明: (1)Learning Rate: 0.001, 学习率 . 学习率: 决定了参数移动到最优值的速度快慢. 如果学习率过大,很可能会越过最优值导致函数无法收敛,甚至发散;反之,如果学习率过小,优化的效率可能过低,算法长时间无法收敛,也易使算法陷入局部最优(非凸函数不能保证达到全局最优)。合适的学习率应该是在保证收敛的前提下,能尽快收敛。 设置较好的learning rate,需要不断尝试。在一开始的时候,可以将其设大一点,这样可以使weights快一点发生改变,在迭代一定的epochs之后人工减小学习率。 在yolo训练中,网络训练160epoches,初始学习率为0.001,在60和90epochs时将学习率除以10。 (2)Momentum: 0.9, 滑动平均模型 . 在训练的过程中不断地对参数求滑动平均,这样能够更有效地保持稳定性,使其对当前参数更新不敏感。例如加动量项的随机梯度下降法就是在学习率上应用滑动平均模型。,一般会选择0.9~0.95. (3)Decay: 0.0005, 权重衰减 . 使用的目的是防止过拟合,当网络逐渐过拟合时网络权值往往会变大,因此,为了避免过拟合,在每次迭代过程中以某个小因子降低每个权值,也等效于给误差函数添加一个惩罚项,常用的惩罚项是所有权重的平方乘以一个衰减常量之和。权值衰减惩罚项使得权值收敛到较小的绝对值。 (4)Region 82, Region 94, Region 106表示三个不同尺度(82,94,106)上预测到的不同大小的参数。 82 卷积层为最大的预测尺度, 使用较大的 mask, 但是可以预测出较小的物体; 94 卷积层为中间的预测尺度, 使用中等的 mask; 106卷积层为最小的预测尺度, 使用较小的 mask, 可以预测出较大的物体. @https://blog.csdn.net/xiao_lxl/article/details/85127959 (5)上述列举中,表示所有训练图片中的一个批次(batch) 批次大小的划分根据在cfg/yolov3.cfg中设定的, 批次大小的划分根据我们在 .cfg 文件中设置的subdivisions参数。 在当前使用的 .cfg 文件中 batch = 64 ,subdivision = 8,所以在训练输出中,训练迭代包含了8组(8组Region 82, Region 94, Region 106),每组又包含了8张图片,跟设定的batch和subdivision的值一致。 注: 也就是说每轮迭代会从所有训练集里随机抽取 batch = 64 个样本参与训练,所有这些 batch 个样本又被均分为 subdivision = 8 次送入网络参与训练,以减轻内存占用的压力) (6)观察某一个尺度上的参数, 下面以第一行 Region 82 分析: 【Region 82 Avg IOU: 0.293486, Class: 0.443128, Obj: 0.680025, No Obj: 0.532993, .5R: 0.142857, .75R: 0.000000, count: 7】 • Region Avg IOU:0.293486: 表示在当前 subdivision 内的图片的平均 IOU, 代表预测的矩形框和真实目标的交集与并集之比, 这里是 29.36%,由于刚开始训练,所以此模型的精度远远不够。 • Class: 0.443128: 标注物体分类的正确率, 期望该值趋近于1; • Obj: 0.680025: 越接近 1 越好; • No Obj:0.532993: 期望该值越来越小, 但不为零; • .5R: 0.142857: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本. 是在 recall/count 中定义的, 是当前模型在所有 subdivision 图片中检测出的正样本与实际的正样本的比值。全部的正样本被正确的检测到应该是1。 • .75R: 0.000000 : 以IOU=0.75为阈值时候的recall; • count: 7: 所有当前 subdivision 图片(本例中一共 8 张)中包含正样本的图片的数量。 在输出 log 中的其他行中, 可以看到其他subdivision 也有的只含有 6 或 1 个正样本, 说明在 subdivision 中含有不包含在检测对象 classes 中的图片 (7)批输出【 9798: 0.370096, 0.451929 avg, 0.001000 rate, 3.300000 seconds, 627072 images 】 • 9798: 指示当前训练的迭代次数 • 0.370096: 是总体的Loss(损失) • 0.451929 avg: 是平均Loss,这个数值应该越低越好,一般来说,一旦这个数值低于0.060730 avg就可以终止训练了。 • 0.001000 rate: 代表当前的学习率,是在.cfg文件中定义的。 • 3.300000 seconds: 表示当前批次训练花费的总时间。 • 627072 images: 这一行最后的这个数值是9798*64的大小,表示到目前为止,参与训练的图片的总量。 (8)分块输出【 Region Avg IOU: 0.326577,Class: 0.742537,Obj: 0.033966,No Obj: 0.000793,Avg Recall: 0.12500,count: 8 】 • Region Avg IOU: 0.326577: 表示在当前subdivision内的图片的平均IOU,代表预测的矩形框和真实目标的交集与并集之比,这里是32.66%,这个模型需要进一步的训练。 • Class: 0.742537: 标注物体分类的正确率,期望该值趋近于1。 • Obj: 0.033966: 越接近1越好。 • No Obj: 0.000793: 期望该值越来越小,但不为零。 • Avg Recall: 0.12500: 是在recall/count中定义的,是当前模型在所有subdivision图片中检测出的正样本与实际的正样本的比值。在本例中,只有八分之一的正样本被正确的检测到。(和最开始初定的阈值有关系) • count: 8:count后的值是所有的当前subdivision图片(本例中一共8张)中包含正样本的图片的数量。在输出log中的其他行中,可以看到其他subdivision也有的只含有6或7个正样本,说明在subdivision中含有不含检测对象的图片。 @https://blog.csdn.net/xiao_lxl/article/details/85127959
******************************************************************************************** ... ... ... Loading weights from ./wp_data/case3-cls84-weights/yolov3_weight.conv.66... seen 64 Done! Learning Rate: 0.001, Momentum: 0.9, Decay: 0.0005 If error occurs - run training with flag: -dont_show Resizing 608 x 608 try to allocate additional workspace_size = 215.15 MB CUDA allocate done! Loaded: 0.000069 seconds v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 82 Avg (IOU: 0.130423, GIOU: 0.130423), Class: 0.777553, Obj: 0.372095, No Obj: 0.434500, .5R: 0.000000, .75R: 0.000000, count: 1 ... ... v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 82 Avg (IOU: -nan, GIOU: -nan), Class: -nan, Obj: -nan, No Obj: 0.434966, .5R: -nan, .75R: -nan, count: 0 v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 94 Avg (IOU: 0.347062, GIOU: 0.260316), Class: 0.537231, Obj: 0.459746, No Obj: 0.507364, .5R: 0.142857, .75R: 0.000000, count: 14 ... ... v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 82 Avg (IOU: -nan, GIOU: -nan), Class: -nan, Obj: -nan, No Obj: 0.434781, .5R: -nan, .75R: -nan, count: 0 v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 94 Avg (IOU: 0.255715, GIOU: 0.049848), Class: 0.641193, Obj: 0.390348, No Obj: 0.507421, .5R: 0.000000, .75R: 0.000000, count: 7 ... ... v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 82 Avg (IOU: -nan, GIOU: -nan), Class: -nan, Obj: -nan, No Obj: 0.434521, .5R: -nan, .75R: -nan, count: 0 v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 94 Avg (IOU: 0.272013, GIOU: 0.236511), Class: 0.617063, Obj: 0.395308, No Obj: 0.507380, .5R: 0.000000, .75R: 0.000000, count: 4 ... ... v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 82 Avg (IOU: -nan, GIOU: -nan), Class: -nan, Obj: -nan, No Obj: 0.434870, .5R: -nan, .75R: -nan, count: 0 v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 94 Avg (IOU: 0.315608, GIOU: 0.164685), Class: 0.552984, Obj: 0.492209, No Obj: 0.507285, .5R: 0.142857, .75R: 0.000000, count: 14 v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 106 Avg (IOU: 0.249113, GIOU: 0.112020), Class: 0.505489, Obj: 0.479450, No Obj: 0.473681, .5R: 0.028571, .75R: 0.028571, count: 35 ... ... v3 (mse loss, Normalizer: (iou: 0.750000, cls: 1.000000) Region 106 Avg (IOU: 0.243135, GIOU: 0.081533), Class: 0.508788, Obj: 0.439726, No Obj: 0.473779, .5R: 0.076923, .75R: 0.000000, count: 52 1: 1974.407104, 1974.407104 avg loss, 0.000000 rate, 3.823940 seconds, 64 images Loaded: 0.000018 seconds
***说明:v3(mse loss, Normalizer :( iou :0.750000) cls:1.000000)这句话,心里就很忐忑,后来知道了可能是新版本ab优化后的,加了些超参
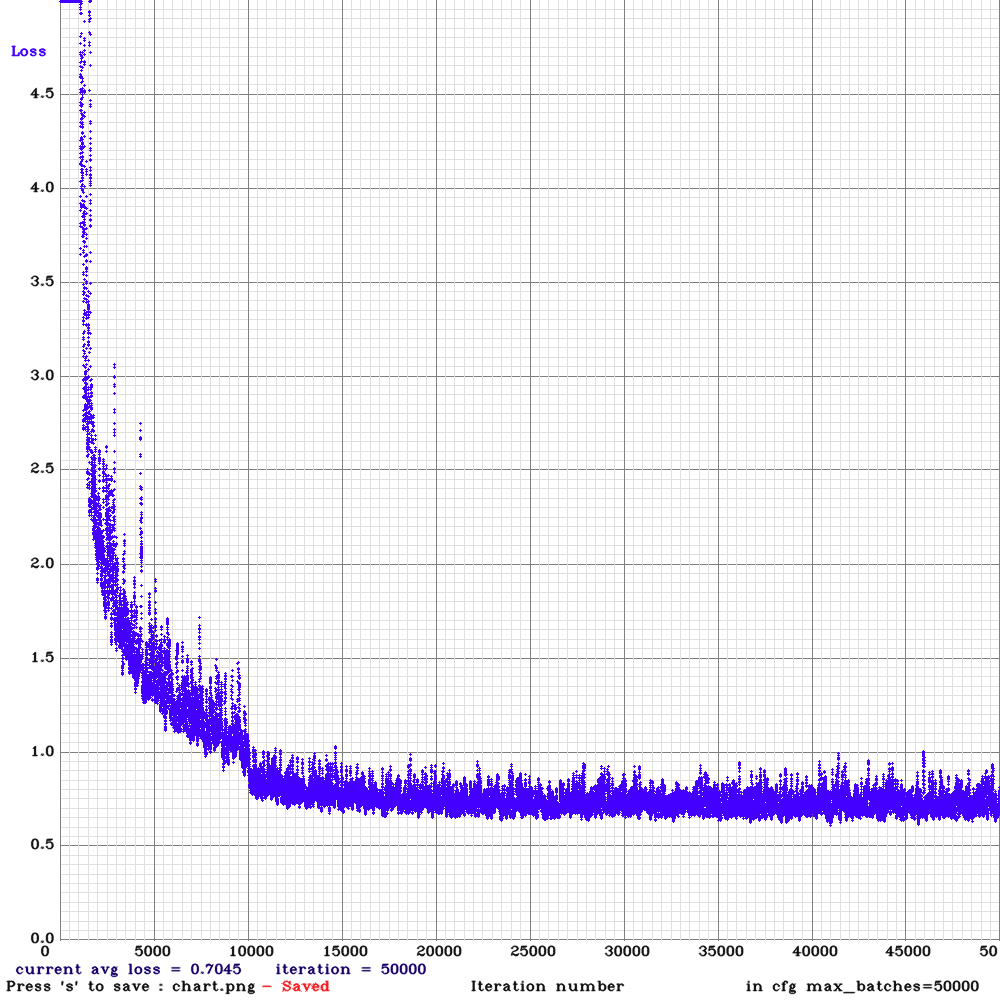
******************************************************************************************** 参考@https://www.cnblogs.com/hls91/p/10911997.html已实践了几次,正确性进一步尚待验证。简单说明: (1)如果看到avg loss =nan? 说明训练错误; 某一行的Class=-nan说明目标太大或者太小,某个尺度检测不到,属于正常 @https://zhuanlan.zhihu.com/p/25110930 @https://blog.csdn.net/maweifei/article/details/81148414 (2)什么时候应该停止训练? 当loss不在下降或者下降极慢的情况可以停止训练,一般loss=0.7左右就可以了 (3)在训练集上测试正确率很高,在其他测试集上测试效果很差? 说明过拟合了。解决,提前停止训练,或者增大样本数量训练 (4)如何提高目标检测正确率包括IOU,分类正确率? 设置yolo层 random =1,增加不同的分辨率。或者增大图片本身分辨率。或者根据你自定义的数据集去重新计算anchor尺寸(darknet.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416 then set the same 9 anchors in each of 3 [yolo]-layers in your cfg-file) (5)如何增加训练样本? 样本特点尽量多样化,亮度,旋转,背景,目标位置,尺寸. 添加没有标注框的图片和其空的txt文件,作为negative数据 (6)训练的图片较小,但是实际检测图片大,怎么检测小目标? 1.使在用416*416训练完之后,也可以在cfg文件中设置较大的width和height,增加网络对图像的分辨率,从而更可能检测出图像中的小目标,而不需要重新训练 2.set `[route] layers = -1, 11` set ` [upsample] stride=4` (7)网络模型耗费资源多大?(我用过就两个) [yolov3.cfg] [236MB COCO-91类] [4GB GPU-RAM] [yolov3.cfg] [194MB VOC-20类] [4GB GPU-RAM] [yolov3-tiny.cfg] [34MB COCO-91类] [1GB GPU-RAM] [yolov3-tiny.cfg] [26MB VOC-20类] [1GB GPU-RAM] (8)多GPU怎么训练? 首先用一个gpu训练1000次迭代后的网络,再用多gpu训练 darknet.exe detector train data/voc.data cfg/yolov3-voc.cfg /backup/yolov3-voc_1000.weights -gpus 0,1,2,3 (9)有哪些命令行来对神经网络进行训练和测试? 1.检测图片: build\darknet\x64\darknet.exe detector test data/coco.data cfg/yolov3.cfg yolov3.weights -thresh 0.25 xxx.jpg 2.检测视频:将test 改为 demo ; xxx.jpg 改为xxx.mp4 3.调用网络摄像头:将xxx.mp4 改为 http://192.168.0.80:8080/video?dummy=x.mjpg -i 0 4.批量检测:-dont_show -ext_output < data/train.txt > result.txt 5.手持端网络摄像头:下载mjpeg-stream 软件, xxx.jpg 改为 IP Webcam / Smart WebCam (10)如何评价模型好坏? build\darknet\x64\darknet.exe detector map data\defect.data cfg\yolov3.cfg backup\yolov3.weights 利用上面命令计算各权重文件,选择具有最高IoU(联合的交集)和mAP(平均精度)的权重文件 (11)如果测试时出现权重不能识别目标的情况? 很可能是因为yolov3.cfg文件开头的Traing下面两行没有注释掉,并且把Testing下面两行去掉注释就可以正常使用. (12)模型什么时候保存?如何更改? 迭代次数小于1000时,每100次保存一次,大于1000时,没10000次保存一次。 自己可以根据需求进行更改,然后重新编译即可[ 先 make clean ,然后再 make]。 代码位置: examples/detector.c line 138 (13)yolo v3 论文阅读 优点:速度快,精度提升,小目标检测有改善; 不足:中大目标有一定程度的削弱,遮挡漏检,速度稍慢于V2。 参考@https://www.cnblogs.com/hls91/p/10911997.html ,https://blog.csdn.net/lilai619/article/details/7969510
【. . . . . .本博客仅作个人生活、工作、学习等的日常记录。说明: (1) 内容有参考其他博主、网页等,有因“懒”直接粘贴来,会备注出处。若遇雷同,或忘备注,并无故意抄袭之意,请诸“原主”谅解,很感谢您的辛勤"笔记"可供本人参考学习。 (2) 如遇同行,有参考学习者,因个人学识有限,不保证所写内容完全正确。您对本博文有任何的意见或建议,欢迎留言,感谢指正。 (3) 若您认为本主的全博客还不错,可以点击关注,便于互相学习。 (4) 感谢您的阅读,希望对您有一定的帮助。欢迎转载或分享,但请注明出处,谢谢。. . . . . .】
【作者: Carole0904 ; 出处: https://www.cnblogs.com/carle-09/ 】

